GAN的基本原理
GAN(生成对抗网络)
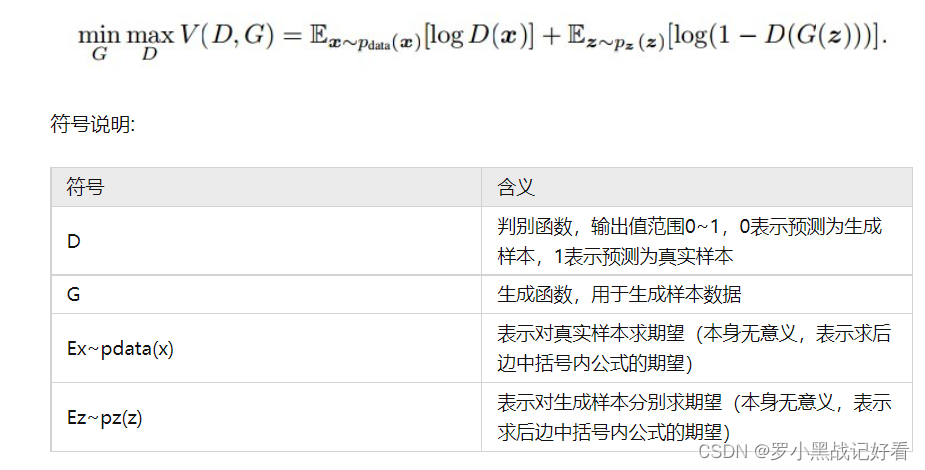
- 目标是 想让生成的假数据Pz都分布跟真实数据Pdata的分布一致
- 做法是 用判别器D判断真数据是真是假 也要判断假数据是真是假
- 但判别式D如果本身就分不出真假也不行【欢喜冤家嘛,D判别不出来好坏,说明G生成得好,以假乱真;G生成完了让D检查,能把真的识别成真,把假的识别成假,说明D判别得好】
- 训练GAN时并不是同时训练D和G,而是在固定一个网络的同时训练另一种
- 判断用的公式里用到了 真数据集及其判断为真的概率 和 生成的假数据集及其判断为真的概率【由于假数据判断为真是不希望发生的,所以用1-来取补集,这样就能以 希望整条公式的输出值最高 为评判标准】【最大值是逼近0,判别效果变差会迅速往负数下降】
- 由于数据集在评判阶段不会改变,所以视为常数,故对公式里的概率D(x)求导,得出判别式需要调节的x来使概率D(x)最大的条件下使整个公式达到判断正确的最大值。
- 在确定了最优的判别式D之后,再把D看作常数,找 能使公式达成最小值【让判断错误率比较高】的生成函数G
#深度解析# GAN(生成对抗神经网络)
GAN公式简明原理
GAN的系列
GAN令人头疼之处主要在于训练不稳定、收敛困难、难以精准控制生成内容,因此各种各样的网络结构、损失函数、加入条件监督信息技巧和各种约束手段被提出。
在19年对GAN的综述
历史最全GAN网络及其各种变体整理(附论文及代码实现)
VQGAN
计算机视觉Paper 讲VQGAN的
如何构建 AI 生成艺术图片
WGAN
WGAN 中的判别网络和生成网络不再使用同一个损失函数,因此不再存在零和博弈的限制
交叉熵、相对熵(KL散度)、JS散度和Wasserstein距离(推土机距离)
令人拍案叫绝的Wasserstein GAN
GAN在Tensorflow2.0里的实现
GAN新手入门指南+keras&TensorFlow代码详解(WIN10)
tensorflow.keras搭建gan神经网络,可直接运行
Tensorflow2.0实现对抗生成网络(GAN)
tf.keras搭建gan网络大致步骤
- 把输入的图像数据的格式转换为tensorflow提供的tfrecords的格式。
- 把tfrecords格式的源数据做成数据集。
- 搭建生成器
- 搭建判别器
- 开始交错进行训练
- 保存网络
输入数据
如果有现成的数据集,读入就好了
python
#读取mnist数据库
(train_images, train_labels), (_, _) = keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images-127.5)/127.5 #这是归一化?
BATCH_SIZE = 256
BUFFER_SIZE = 60000
#建立数据集
datasets = tf.data.Dataset.from_tensor_slices(train_images)#为什么不用(train_images, train_labels)
datasets = datasets.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)如果要自己做数据集就比较麻烦了
python
# 设置标签
objects = ['cat','dog']#'cat'0,'dog'1
# 读取文件
filename_train="./data/train.tfrecords"
writer_train= tf.python_io.TFRecordWriter(filename_train)
tf.app.flags.DEFINE_string(
'data', 'None', 'where the datas?.')
FLAGS = tf.app.flags.FLAGS
if(FLAGS.data == None):
os._exit(0)
# FLAGS读取成功了
dim = (224,224)
object_path = FLAGS.data
total = os.listdir(object_path)
for index in total:
img_path=os.path.join(object_path,index)# 文件路径+图片编号,真方便啊,我在qt就得自己搞字符串相加
img=Image.open(img_path)
img=img.resize(dim)
img_raw=img.tobytes()# to bytes格式
for i in range(len(objects)):
if objects[i] in index:
value = i
else:
continue
example = tf.train.Example(features=tf.train.Features(feature={
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[value])),
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw]))
}))
print([index,value])
writer_train.write(example.SerializeToString()) #序列化为字符串
writer_train.close()搭建生成器和判别器
【keras.models.Sequential()是TF的写法,keras.Sequential()是TF2的写法
总之就是往Sequential里填层,随便填,毁灭吧。
默认情况下GradientTape的资源在调用gradient函数后就被释放,再次调用就无法计算了。所以如果需要多次计算梯度,需要开启persistent=True属性
python
x = tf.constant(3.0)
with tf.GradientTape(persistent=True) as g:
g.watch(x)
y = x * x
z = y * y
dz_dx = g.gradient(z, x) # z = y^2 = x^4, z' = 4*x^3 = 4*3^3
dy_dx = g.gradient(y, x) # y' = 2*x = 2*3 = 6
del g # 手动删除