文章目录
- 引言
- 设计说明
- 原理方案
-
- [Advisor 优先级机制](#Advisor 优先级机制)
- [Advisor 之间的通信](#Advisor 之间的通信)
- [Document.source 元数据](#Document.source 元数据)
- 代码解析
-
- [MetadataAwareQuestionAnswerAdvisor 完整实现](#MetadataAwareQuestionAnswerAdvisor 完整实现)
- [注册到 ChatClient](#注册到 ChatClient)
- [调用时传入 userMessage 参数](#调用时传入 userMessage 参数)
- [System Prompt 模板设计](#System Prompt 模板设计)
- 验证结果
- 进阶方案
- 常见坑
-
- [Order 设错导致拿不到文档](#Order 设错导致拿不到文档)
- [userMessage 取不到](#userMessage 取不到)
- [Tika 没注入 source](#Tika 没注入 source)
- [默认 Advisor 与请求级 Advisor 的混用](#默认 Advisor 与请求级 Advisor 的混用)
- 小结
引言
"AI 说的对吗?我能在哪里查证?"------这是知识库系统用户最常问的两个问题。一个回答如果没有来源,就只能算大模型的"自由发挥",可信度大打折扣。
来源追溯(Source Citation)让 AI 在回答时附上具体引用了哪个文件、哪一段,是企业级 RAG 必不可少的能力。本篇将深入解析项目中通过自定义 BaseAdvisor 实现来源追溯的完整方案。
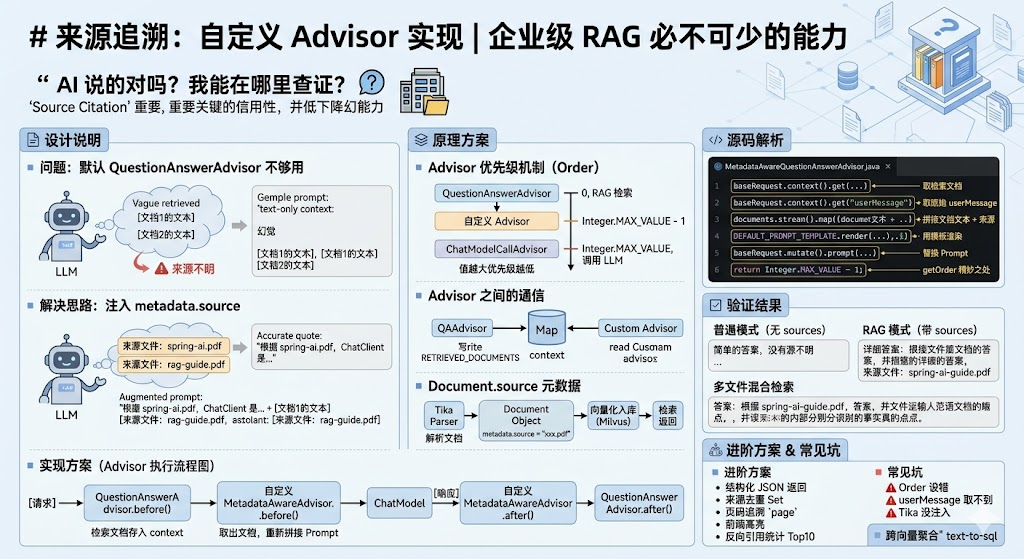
设计说明
为什么默认的 QuestionAnswerAdvisor 不够用?
QuestionAnswerAdvisor 在检索后会把文档拼接到 Prompt 中,但默认拼接的只有 text 字段:
java
Context information is below.
---------------------
[文档1的文本]
[文档2的文本]
---------------------大模型看到这些文本,根本不知道它们来自哪个文件。即使在 System Prompt 里要求"请提供来源",AI 也只能瞎编(典型的"幻觉")。
解决思路
要让 AI 知道每段文本的来源,必须把 Document 的 metadata.source 字段也传给它:
java
[文档1的文本]
来源文件:spring-ai.pdf
[文档2的文本]
来源文件:rag-guide.pdf这样 AI 就能在回答中准确引用,比如:
"根据 spring-ai.pdf,ChatClient 是..."
实现方案
Spring AI 的 Advisor 链是有顺序的,可以在 QuestionAnswerAdvisor 之后挂一个自定义 Advisor,专门做这件事:
java
[请求] → QuestionAnswerAdvisor.before() // 检索文档存入 context
→ 自定义 MetadataAwareAdvisor.before() // 取出文档,重新拼接 Prompt
→ ChatModel
[响应] → 自定义 MetadataAwareAdvisor.after()
→ QuestionAnswerAdvisor.after()关键是控制 Advisor 的执行顺序------必须保证检索完成后,自定义 Advisor 才能拿到文档。
原理方案
Advisor 优先级机制
Spring AI 的 Advisor 通过 getOrder() 方法决定执行顺序,值越大优先级越低(执行越靠后):
| Advisor | 默认 Order | 说明 |
|---|---|---|
| QuestionAnswerAdvisor | 0 | RAG 检索 |
| ChatModelCallAdvisor | Integer.MAX_VALUE | 实际调用 LLM 的终点 |
自定义 Advisor 想在 QuestionAnswerAdvisor 之后、ChatModelCallAdvisor 之前执行,order 应该设为 Integer.MAX_VALUE - 1:
java
@Override
public int getOrder() {
return Integer.MAX_VALUE - 1;
}Advisor 之间的通信
每个 Advisor 共享一个 Map<String, Object> context,可以通过它传递数据:
java
// QuestionAnswerAdvisor 写入
context.put(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS, documents);
// 自定义 Advisor 读取
List<Document> documents = (List<Document>) context.get(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS);这是 Spring AI 推荐的 Advisor 协作方式。
Document.source 元数据
Tika 解析时会自动在每个 Document 的 metadata 中写入 source 字段,值为原始文件名:
java
Document doc = ...
String source = (String) doc.getMetadata().get("source");
// 例如: "spring-ai-guide.pdf"向量化入库后,metadata 会被 Milvus 一并存储。检索时也会原样返回。
代码解析
MetadataAwareQuestionAnswerAdvisor 完整实现
java
public class MetadataAwareQuestionAnswerAdvisor implements BaseAdvisor {
private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate("""
{query}
Context information is below, surrounded by ---------------------
---------------------
{question_answer_context}
---------------------
Given the context and provided history information and not prior knowledge,
reply to the user comment. If the answer is not in the context, inform
the user that you can't answer the question.
""");
@Override
public ChatClientRequest before(ChatClientRequest baseRequest, AdvisorChain advisorChain) {
// 1. 从 context 中取出已检索的文档
List<Document> documents = (List<Document>) baseRequest.context()
.get(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS);
// 2. 取出原始 user message(需要在请求时显式 param 传入)
String userMessage = (String) baseRequest.context().get("userMessage");
if (!CollectionUtils.isEmpty(documents)) {
// 3. 拼接文档文本 + source 元数据
String documentContext = documents.stream()
.map(doc -> doc.getText() + "\n来源文件:"
+ doc.getMetadata().getOrDefault("source", "unknown").toString())
.collect(Collectors.joining(System.lineSeparator()));
// 4. 用模板渲染新的 user message
String augmentedUserText = DEFAULT_PROMPT_TEMPLATE.render(Map.of(
"query", userMessage,
"question_answer_context", documentContext
));
// 5. 替换原 user message
return baseRequest.mutate()
.prompt(baseRequest.prompt().augmentUserMessage(augmentedUserText))
.build();
} else {
return baseRequest;
}
}
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
return chatClientResponse;
}
@Override
public int getOrder() {
// 优先级最低、因为要保证 QuestionAnswerAdvisor 执行完才能拿到文档信息
// 不直接设置 MAX_VALUE,是因为 ChatModelCallAdvisor 也用了 MAX_VALUE,
// 如果在它之后就拿不到机会执行
return Integer.MAX_VALUE - 1;
}
}逐步解析:
- 取检索结果 :
QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS是个常量,值为"qa_retrieved_documents"。QuestionAnswerAdvisor会自动把检索结果存到这个 key 下 - 取原始 user message:因为 user message 在 QuestionAnswerAdvisor 处理后已经被拼接修改过,需要从外部 param 传入原始 message
- 拼接 source :每个文档的文本后追加
\n来源文件:xxx,让大模型知道来源 - 渲染模板:用 PromptTemplate 重新组装 Prompt
- 替换 user message :
augmentUserMessage方法用新文本替换原 user message - getOrder 的精妙之处 :
Integer.MAX_VALUE - 1保证执行顺序在所有检索类 Advisor 之后,但又在 ChatModelCallAdvisor(实际调 LLM)之前
注册到 ChatClient
java
public AiRagController(ChatModel chatModel, ChatMemory chatMemory,
VectorStore vectorStore, RagTool ragTool) {
this.chatModel = chatModel;
this.chatClient = ChatClient.builder(chatModel)
.defaultSystem(DEFAULT_SYSTEM_PROMPT)
.defaultSystem(p -> p.param("rag_message", ""))
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build(),
SimpleLoggerAdvisor.builder().build(),
new MetadataAwareQuestionAnswerAdvisor() // 注册自定义 Advisor
)
.defaultTools(ragTool)
.build();
this.vectorStore = vectorStore;
}关键点:
MetadataAwareQuestionAnswerAdvisor作为 default advisor 注册,每次调用都生效- 与
PromptChatMemoryAdvisor等其他 Advisor 共存,互不干扰
调用时传入 userMessage 参数
java
private Flux<String> processNormalRagQuery(List<String> sources, String message) {
Long userId = BaseContext.getCurrentId();
ChatClient.ChatClientRequestSpec clientRequestSpec = chatClient.prompt()
.user(message)
.system(a -> a.param("current_data", LocalDate.now().toString()))
// 传入原始 message 给 MetadataAwareQuestionAnswerAdvisor
.advisors(a -> a.param("userMessage", message))
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId));
if (sources != null && !sources.isEmpty()) {
SearchRequest.Builder searchRequestBuilder = SearchRequest.builder()
.query(message)
.similarityThreshold(0.1)
.topK(5)
.filterExpression("source in " + JSON.toJSONString(sources));
clientRequestSpec = clientRequestSpec
.system(a -> a.param("rag_message", """
如果涉及RAG,请提供文件来源,我会提供给你文件来源,
请严格基于知识库内容回答用户问题,
不要添加任何知识库之外的信息。如果知识库内容不完整,
仅需基于已有信息作答,不要自行补充。
"""))
.advisors(QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(searchRequestBuilder.build())
.build());
}
return clientRequestSpec.stream().content();
}几个细节:
.advisors(a -> a.param("userMessage", message))------ 把原始 message 通过 param 传给后续 Advisor- System Prompt 强调来源 ------
rag_message中明确要求 AI 提供文件来源 - filter expression 限定范围 ------
source in [...]让检索只在用户选定的文件中进行
System Prompt 模板设计
java
private static final String DEFAULT_SYSTEM_PROMPT = """
你是知识库系统的对话助手,请以乐于助人的方式进行对话,
{rag_message}
今天的日期:{current_data}
""";{rag_message} 是个占位符,根据请求是否带 sources 动态填充:
- 不带 sources(普通对话):
rag_message为空字符串 - 带 sources(RAG 模式):
rag_message填入"必须基于知识库回答"的指令
这种"按需注入"的方式让同一个 ChatClient 实例既能做普通对话也能做 RAG 问答。
验证结果
普通模式(无 sources)
请求:
java
POST /api/v1/ai/rag?message=你好响应:
java
你好!我是知识库系统的对话助手,很高兴为您服务...不会触发 RAG 检索,回答中也没有来源引用。
RAG 模式(带 sources)
前置 :上传了 spring-ai-guide.pdf,包含 ChatClient 的介绍。
请求:
java
POST /api/v1/ai/rag?sources=spring-ai-guide.pdf&message=ChatClient怎么用?响应:
java
ChatClient 是 Spring AI 提供的高级抽象,用于简化与大语言模型的交互。
你可以通过 ChatClient.builder(chatModel).build() 创建实例,然后通过链式
调用 .prompt().user(...).call().content() 完成对话。
来源文件:spring-ai-guide.pdfAI 在回答末尾明确给出了来源。
多文件混合检索
请求:
java
POST /api/v1/ai/rag?sources=spring-ai-guide.pdf&sources=rag-guide.pdf&message=如何实现RAG?响应:
java
要实现 RAG,主要分两个阶段:
1. 文档入库阶段:将文档上传、解析、切分、向量化、存入向量库。
(来源:rag-guide.pdf)
2. 问答阶段:用户提问后,先检索向量库召回相关文档,
再让大模型基于这些文档生成回答。
(来源:rag-guide.pdf)
Spring AI 提供了 QuestionAnswerAdvisor 来简化这一流程,
你只需要把它挂到 ChatClient 的 advisor 链上即可。
(来源:spring-ai-guide.pdf)AI 准确区分了不同来源,并在每个事实点后注明出处。
调试日志
开启 SimpleLoggerAdvisor 后,可以看到拼接后的完整 Prompt:
java
==> Request:
User: ChatClient怎么用?
Context information is below, surrounded by ---------------------
---------------------
ChatClient 是 Spring AI 的高级抽象...
来源文件:spring-ai-guide.pdf
通过 ChatClient.builder() 可以构建实例...
来源文件:spring-ai-guide.pdf
---------------------
Given the context and provided history information and not prior knowledge,
reply to the user comment...可以清楚看到每段文本都被附上了来源。
进阶方案
结构化的来源返回
让 AI 同时返回结构化数据,便于前端展示:
java
String augmentedUserText = DEFAULT_PROMPT_TEMPLATE.render(Map.of(
"query", userMessage,
"question_answer_context", documentContext,
"instruction", "请在回答末尾以 JSON 数组形式列出所有引用的来源:[{\"source\":\"xxx.pdf\",\"page\":1}]"
));前端可以解析出来源,渲染为可点击的引用链接。
来源去重
同一个文件可能被切成多个 chunk,多次出现在 context 中。可以去重:
java
String documentContext = documents.stream()
.map(doc -> doc.getText() + "\n来源文件:"
+ doc.getMetadata().getOrDefault("source", "unknown"))
.collect(Collectors.joining(System.lineSeparator()));
// 收集去重后的来源列表
Set<String> uniqueSources = documents.stream()
.map(doc -> (String) doc.getMetadata().getOrDefault("source", "unknown"))
.collect(Collectors.toSet());
// 在 Prompt 末尾追加 "已检索的文件列表"
String augmentedUserText = ...;
augmentedUserText += "\n\n本次检索的文件:" + String.join(", ", uniqueSources);页码与位置追溯
如果 Reader 支持,metadata 中还可以有 page、paragraph 等字段:
java
String source = doc.getMetadata().get("source") + " 第"
+ doc.getMetadata().getOrDefault("page", "?") + "页";让来源精确到具体段落,便于用户复核。
来源高亮显示
前端拿到回答后,可以做关键词匹配:
- 在原文档中高亮回答用到的句子
- 点击来源跳转到 OSS 中的原文件预览
- 同步展示文档的具体位置(书签、滚动到段落)
反向引用统计
记录每次回答用到了哪些文档,做"被引用 Top10"统计:
java
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
List<Document> docs = (List<Document>) response.context().get(RETRIEVED_DOCUMENTS);
docs.forEach(d -> citationService.recordCitation(d.getMetadata().get("source")));
return response;
}可以基于此分析哪些文档对用户最有价值。
常见坑
Order 设错导致拿不到文档
如果把自定义 Advisor 的 getOrder 设为 0 或负数,会在 QuestionAnswerAdvisor 之前执行,那时 context 中还没有 RETRIEVED_DOCUMENTS。
正确做法 :设为 Integer.MAX_VALUE - 1,确保排在所有检索之后。
userMessage 取不到
MetadataAwareAdvisor 内部用 context.get("userMessage") 取原始消息。如果调用时没传 param("userMessage", ...),会得到 null。
正确做法 :每次调用都加 .advisors(a -> a.param("userMessage", message))。
Tika 没注入 source
如果用了非 Tika 的 Reader(比如 TextReader),可能没有自动注入 source 字段。
正确做法:手动补充:
java
documents.forEach(doc -> doc.getMetadata().put("source", originalFilename));默认 Advisor 与请求级 Advisor 的混用
如果 MetadataAwareAdvisor 注册为 default,但同一请求又通过 .advisors(...) 添加了 QuestionAnswerAdvisor,需要保证两者都执行。Spring AI 会合并 default + 请求级 advisor 列表,按 order 排序执行。
小结
本篇通过自定义 Advisor 完整实现了 RAG 的来源追溯:
- 利用
BaseAdvisor接口扩展 ChatClient - 通过
getOrder()控制执行顺序,保证拿到检索结果 - 通过
context在 Advisor 之间传递数据 - 在 Prompt 中注入 source 元数据,引导 AI 准确引用
- System Prompt 强化来源要求,进一步降低幻觉
下一篇将进入更挑战性的话题------跨向量聚合,看看 Text-to-SQL 如何解决 Top-K 检索的天花板。
