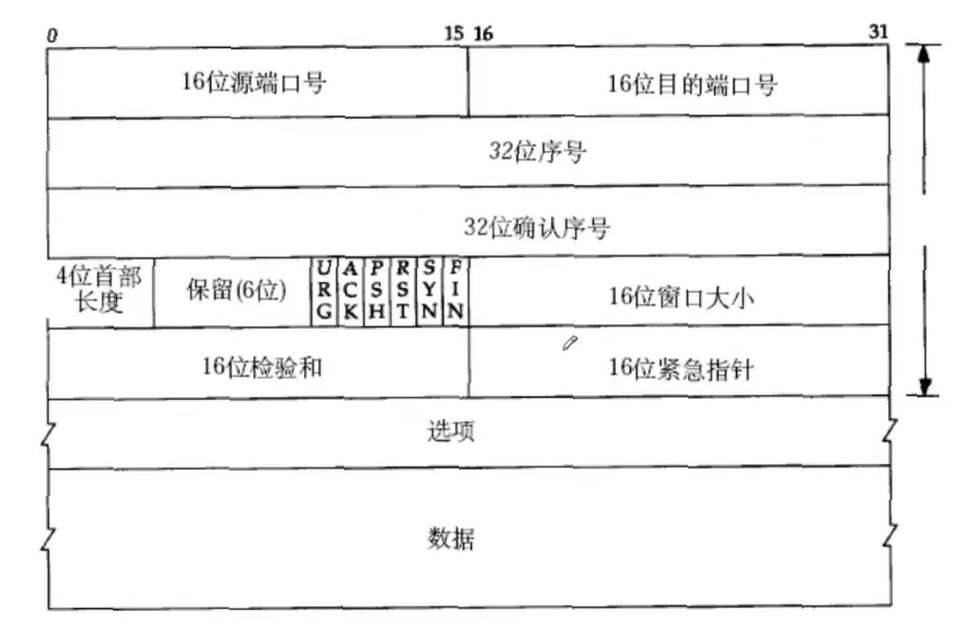
1.滑动窗口
当对端的接收缓冲区窗口大小为0的时候,发送端会发送一个窗口探测的包,不携带数据的一个裸的报头就叫做窗口探测,询问接收端"你好了没";而当接收端的缓冲区即窗口大小更新之后也会给发送端发送窗口更新通知;
下图是发送缓冲区的抽象图:
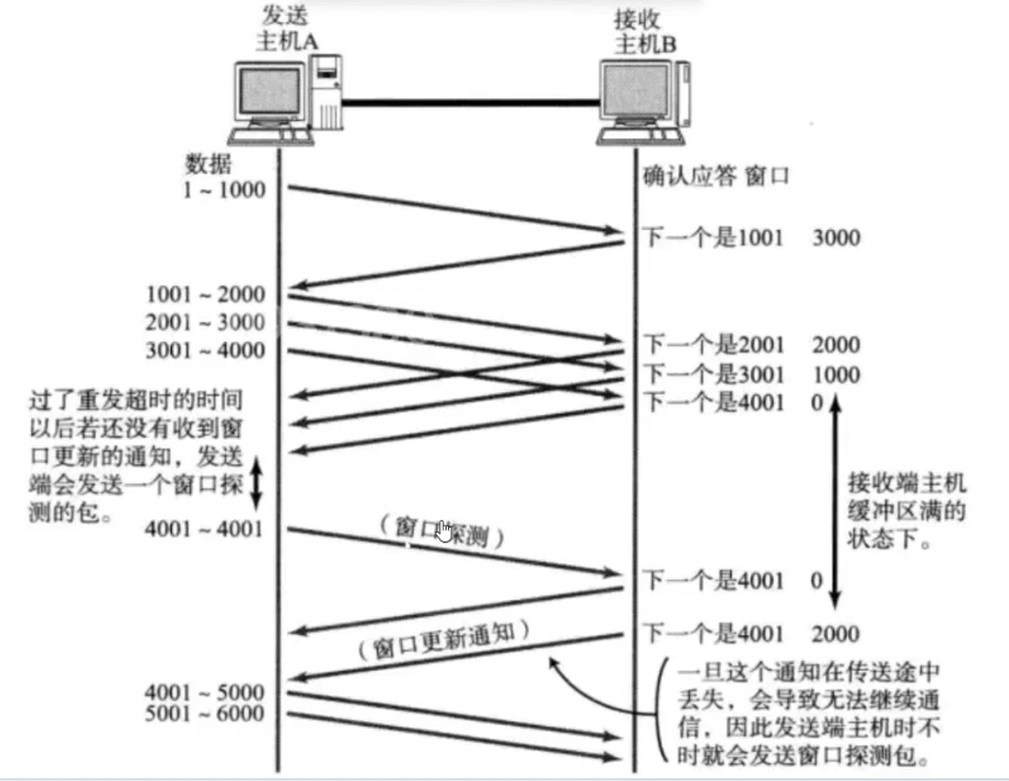
1.1滑动窗口的本质是什么呢?
我们之前说过发送缓冲区和接收缓冲区本质上是一个char bufferN的数组,所以我们的滑动窗口就是一个由数组下标作为start和end的区间,而滑动窗口的大小其实也就是对方可以接收数据的缓冲区的大小;
既然滑动窗口的大小就是对方可以接收数据的最大容量,呢我们为什么不能直接一次性将滑动窗口中的数据全部发送呢?为什么还要一千一千的发送呢?这其实是由传输层的下一层数据链路层决定的,数据链路层规定了每次发送的数据不能超过1500个字节;
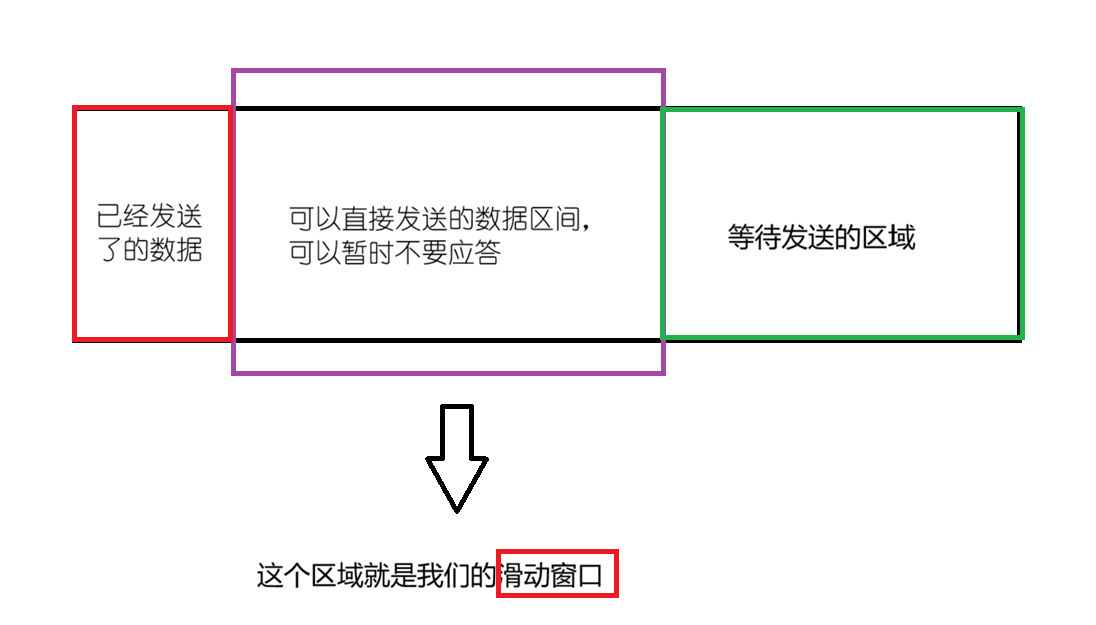
1.2滑动窗口怎么滑动呢?

总的来说就是根据32位确认序号作为滑动窗口的start,以接收缓冲区可接受的最大大小+32位确认序号作为滑动窗口的end,这样就实现了滑动窗口的滑动;
1.3滑动窗口的大小是否会变化
滑动窗口的大小=接收方接收缓冲区的大小,这就决定了滑动窗口的大小应该会跟着对方的接收缓冲区的大小的改变而改变,对方将数据收走的多了,滑动窗口的大小变大,对方的收走的数据少了,滑动窗口的就会变小;滑动窗口也可能会变为0,这个时候就会发生我们前面说的窗口探测和窗口更新通知了;
1.4滑动窗口一直移动会不会越界
我们发现如果我们的发送缓冲区一直向后移动肯定要发生越界啊,但是滑动窗口怎么可能向左移动呢?其实是这样的,发送缓冲区是一个是环形结构的,这样就不可能会越界了;而我们之前说的缓冲区中的已发送已确认区域的本质就是数据已经被删除了,所以未来是可以被覆盖掉的;
1.5 理解滑动窗口的异常丢包问题
①最左侧丢失
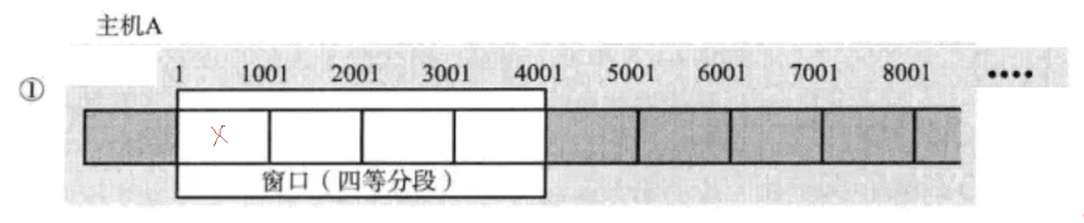
 确认序号返回的是1,发送主机就知道了至少1-1000的数据没有发送成功,就会进行补发,不要忘记了确认序号的含义是x之前的数据已经收到了,但是返回的是1,我们就能知道自己发送的数据没有被接收成功,丢包了;所以不用担心窗口会跳过最左侧的问题;因为发出去的数据可能会发生丢包问题这就决定了要将发出去的数据先缓存下来,以防不时之需,这些被缓存的数据被保存在滑动窗口内部;
确认序号返回的是1,发送主机就知道了至少1-1000的数据没有发送成功,就会进行补发,不要忘记了确认序号的含义是x之前的数据已经收到了,但是返回的是1,我们就能知道自己发送的数据没有被接收成功,丢包了;所以不用担心窗口会跳过最左侧的问题;因为发出去的数据可能会发生丢包问题这就决定了要将发出去的数据先缓存下来,以防不时之需,这些被缓存的数据被保存在滑动窗口内部;
②中间的丢失

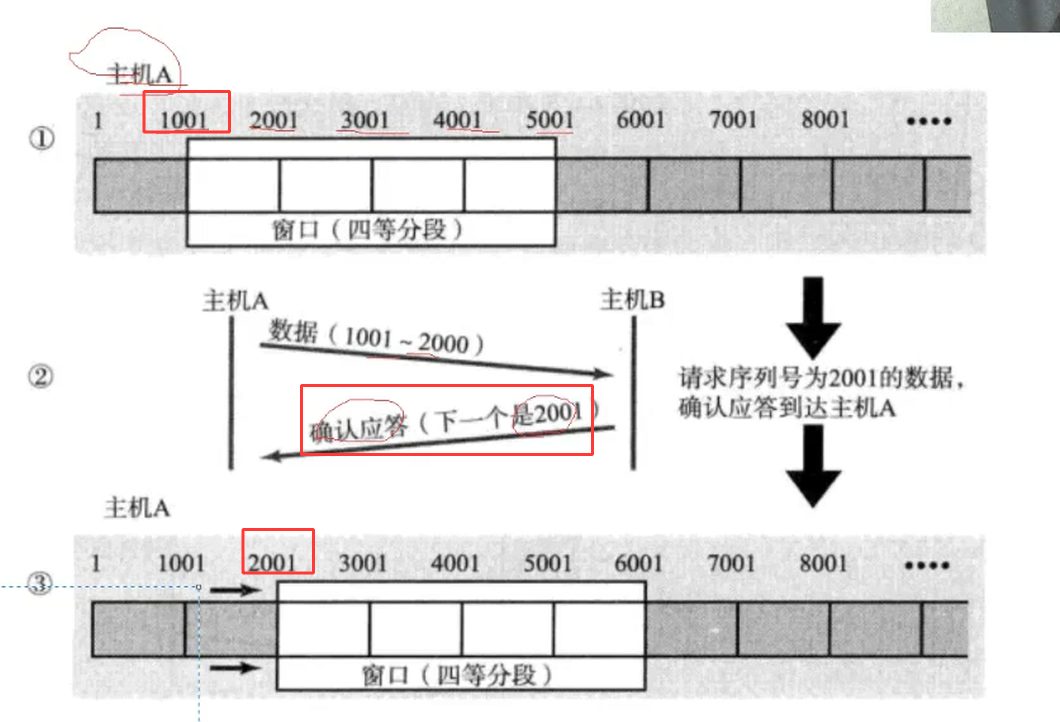
当1001-2001的数据丢失之后,1-1001的报文返回的是1001,1001-2001的确认序号返回的还是1001,因为确认序号的含义是表明当前序号之前的全部数据已经收到,这个时候只有1001之前的数据被收到了,因此返回的是还是1001,而2001-3001,返回的还是1001,3001-4001返回的确认序号还是1001,这个时候主机A就知道了之后1-1001的数据发送成功了,但是1001-2001肯定没有被收到,因为如果收到肯定返回的是2001,所以主机会立马给对方补发1001-2001的数据
③ 最右侧丢失
3001-4001丢失则不会返回4001,还是转换成了最左侧问题,滑动窗口也会移动到3001开始;
补发工作可以高频的一直工作;
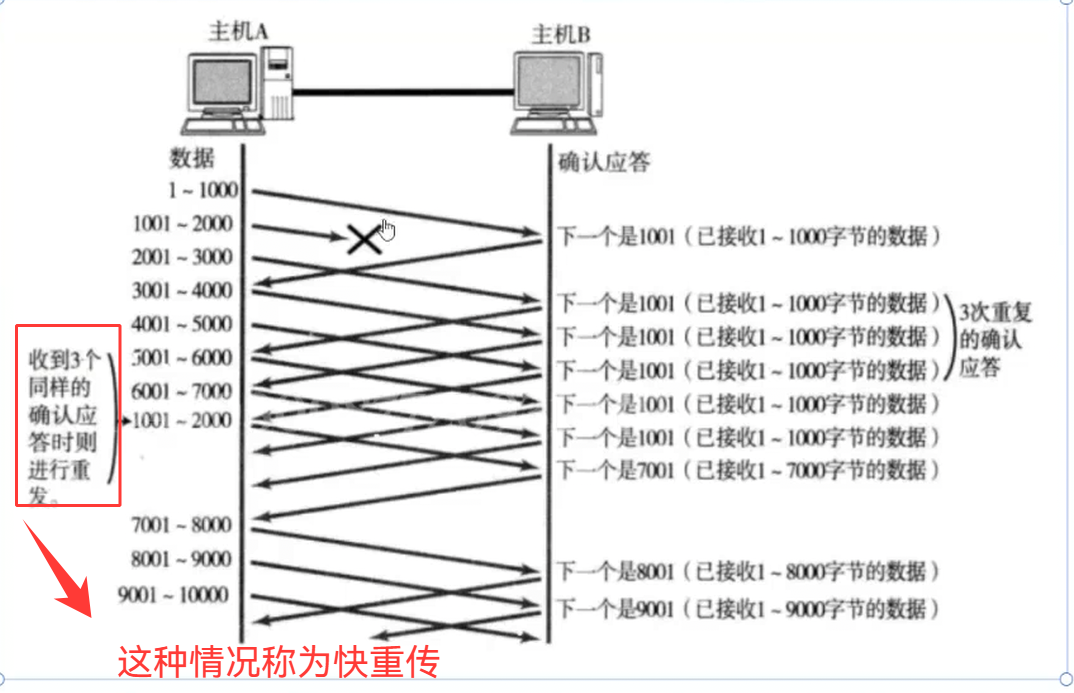
④ 快重传
报文段丢失后,发送端会持续收到内容为1001的确认应答,代表接收方希望接收序号为1001的数据。当发送端连续三次收到相同的1001确认应答时,便会重新发送1001至2000这段丢失的数据。由于接收方早已收到2001到7000的数据并存放至内核接收缓冲区,在成功收到重传的1001序号数据后,会直接回复7001的确认应答。该传输控制机制就是快重传,也叫作高速重发控制。
2.PSH、RST、URG标记位
PSH标记位:push
在对方接受区满的时候或者发送端觉得自己的数据重要,希望可以尽快向上交付;发送端将自己的PSH标记为置为1,然后向主机端发送窗口探测,告诉对方,请尽快将你的缓冲区的数据上交给上层,如果一直不上交我就要断开连接了;
RET标记位:reset
一般用于客户端和服务器建立好了连接,但是服务器用为种种原因,如没有接收到客户端三次握手的最后一次ack,或者服务器因为网络原因挂掉了,但是客户端还认为自己和服务器是建立好链接的,给服务器发送消息,这个时候就会收到服务器将RET标记位置为1的包,表示请求重新建立连接;
URG标记位:
比如我们在现实生活中上传某个数据但是在上传一半的时候想要撤销,这个时候其实就是将URG标记位置为1,对端的接收缓冲区看到urg置为1的数据就会先让这个报文被优先读取;16位紧急指针是一个偏移量,表示了我们的需要撤销的数据在有效载荷的偏移量,但是这个数据的有多少个呢?紧急数据只能占一个字节;
该如何发和读紧急数据呢?更改recv的flag的值;
3.拥塞控制
 我们在实际发送数据的时候不能只考虑接收方接收数据的能力,还要考虑网络的情况;当主机A给主机B发送数据的时候只有少量数据发生丢失,主机A会认为是网络抖动然后进行重发,但是如果有大量数据发生了丢失,主机A就得考虑是不是网络的问题了,判定网络出现网络拥塞问题;为了解决这个问题是否可以使用快重传呢?不可以 ,因为网络已经出现了拥塞,这个时候还发送很多报文会使得网络更加拥塞,因为同一时刻向服务器发送数据的主机并不一定只有一台主机,所以我们使用的是"慢启动";
我们在实际发送数据的时候不能只考虑接收方接收数据的能力,还要考虑网络的情况;当主机A给主机B发送数据的时候只有少量数据发生丢失,主机A会认为是网络抖动然后进行重发,但是如果有大量数据发生了丢失,主机A就得考虑是不是网络的问题了,判定网络出现网络拥塞问题;为了解决这个问题是否可以使用快重传呢?不可以 ,因为网络已经出现了拥塞,这个时候还发送很多报文会使得网络更加拥塞,因为同一时刻向服务器发送数据的主机并不一定只有一台主机,所以我们使用的是"慢启动";
TCP引入慢启动 机制, 先发少量的数据, 探探路, 摸清当前的⽹络拥堵状态, 再决定按照多大的速度传输 ;
但是我们之前不是说使用的是滑动窗口来控制是否可以发送吗?其实发送数据不仅仅受对方的接收能力控制,应该还要受网络的的拥塞窗口的大小限制,即发送端能发送多少数据却决于对方的就收缓冲区的拥塞窗口大小中的较小值控制;所以慢启动发送1个,2个,3个报文使用的就是将调节拥塞窗口即可;
什么是拥塞窗口呢?
 拥塞窗口由发送端操作系统内核TCP层自动设定并动态调整,用于根据网络拥堵情况控制发送数据量,网络顺畅时增大、出现拥塞时缩小,它会与接收方的接收窗口配合,发送数据时取二者中更小的值来确定实际发送流量,以此避免网络发生拥塞。和发送数据量使用的是指数性增长,即前期慢,后期快,完美符合网络需求;但是也不能让一直指数增长啊,这样也太快了,我们的接受方怎么能cover的住呢,其实我们的最后理想的情况是到达慢启动阈值,到达慢启动阈值的时候开始线性增长,而这个时候如果在出现网络堵塞,下一次的慢启动阈值就等于上一次的最大值/2,这叫做乘法减小;
拥塞窗口由发送端操作系统内核TCP层自动设定并动态调整,用于根据网络拥堵情况控制发送数据量,网络顺畅时增大、出现拥塞时缩小,它会与接收方的接收窗口配合,发送数据时取二者中更小的值来确定实际发送流量,以此避免网络发生拥塞。和发送数据量使用的是指数性增长,即前期慢,后期快,完美符合网络需求;但是也不能让一直指数增长啊,这样也太快了,我们的接受方怎么能cover的住呢,其实我们的最后理想的情况是到达慢启动阈值,到达慢启动阈值的时候开始线性增长,而这个时候如果在出现网络堵塞,下一次的慢启动阈值就等于上一次的最大值/2,这叫做乘法减小;
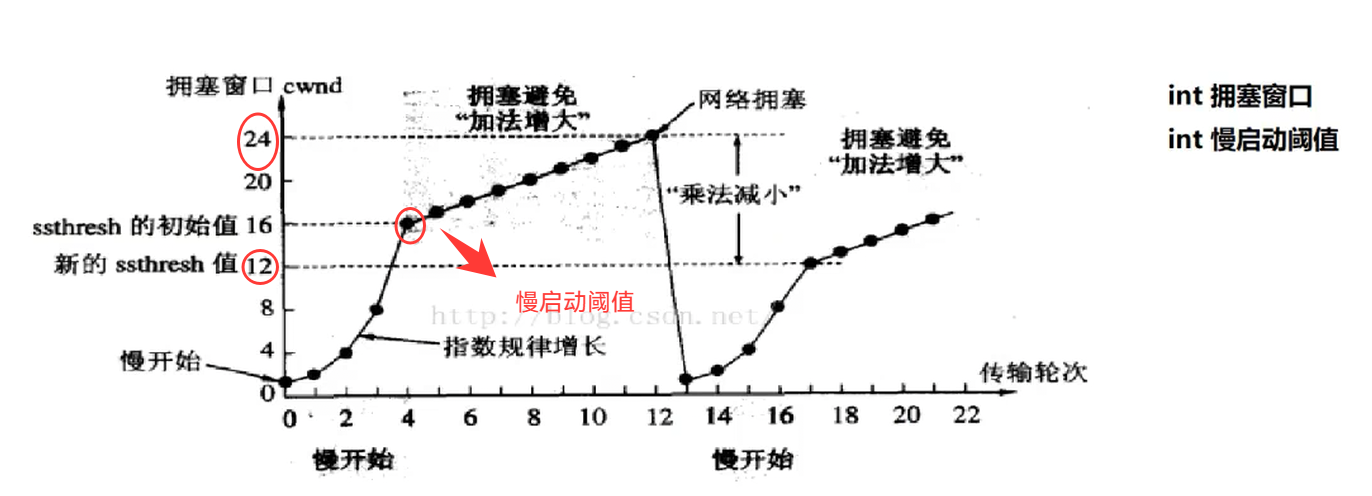
因为网络的情况是一直变化的,这就要求我们的发送端要不断的评估网络健康情况,从而改变拥塞窗口的大小;
4.延迟应答
TCP延时应答是接收方收到发送方发来的数据报文后,不立即回复确认应答,而是短暂等待一小段时间,在此期间若能收到后续连续数据,就将多个数据确认合并为一个ACK报文进行回复,即隔包应答,如下图该机制可以减少网络里冗余的确认报文,节约网络带宽资源,同时还能在应答报文中捎带上接收方自身要向外发送的数据,实现双向数据一并传输,有效提升整体的数据传输效率。
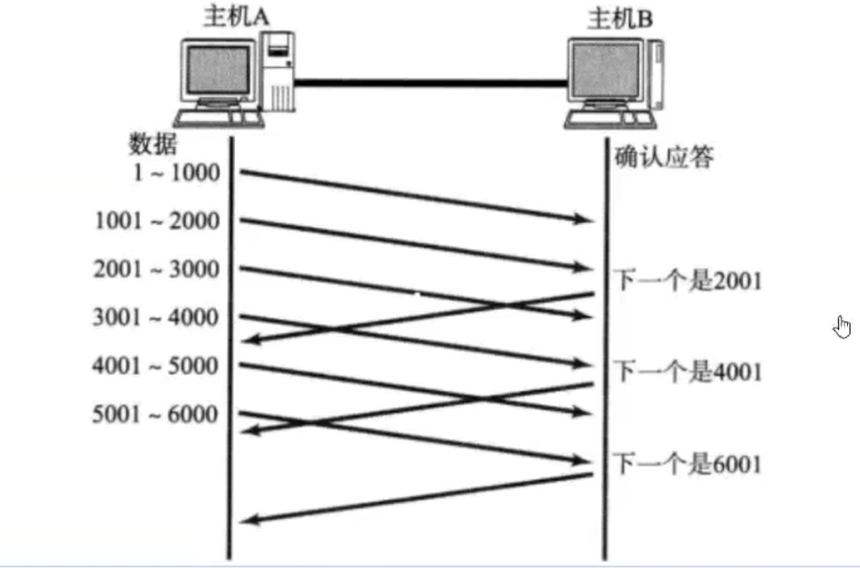
所以不一定所有报文都有应答;
虽然不一定能真的提升效率,但是只要能有用就很好;
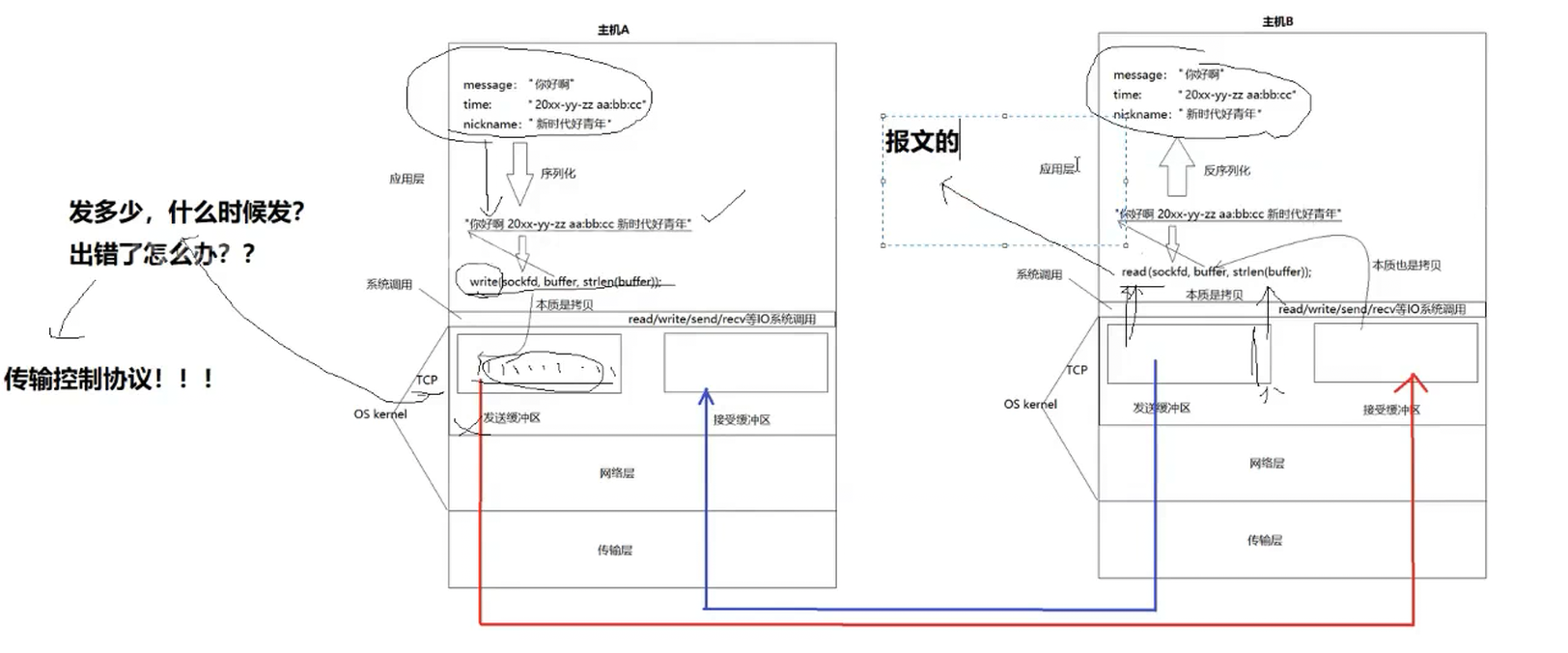
5.什么叫做面向字节流
创建一个TCP的socket(应用层和网络层进行通信的接口),同时在内核中创建一个发送缓冲区和一个接收缓冲区; 调用write时,数据会先写入发送缓冲区中;
如果发送的字节数太长,会被拆分成多个TCP的数据包发出; 如果发送的字节数太短,就会先在缓冲区里等待,等到缓冲区长度差不多了,或者其他合适的时机发送出去; 接收数据的时候,数据也是从网卡驱动程序到达内核的接收缓冲区; 然后应用程序可以调用read从接收缓冲区拿数据; 另一方面,TCP的一个连接,既有发送缓冲区,也有接收缓冲区,那么对于这一个连接,既可以读数据,也可以写数据,这个概念叫做全双工。
由于缓冲区的存在,TCP程序的读和写不需要一一匹配,例如: 写100个字节数据时,可以调用一次write写100个字节,也可以调用100次write,每次写一个字节; 读100个字节数据时,也完全不需要考虑写的时候是怎么写的,既可以一次read 100个字节,也可以一次read一个字节,重复100次。报文的完整性需要对端应用层自己决定;
6.粘包问题
TCP粘包就是因为TCP是流式传输,没有明确数据边界,加上内核缓冲区缓存、Nagle算法延时发送等原因,发送方多次发送的独立数据,在接收端缓冲区里粘连在一起,应用层可能读了半个,也可能就收一个半,使得接收方无法准确拆分出原本独立的数据包,分不清数据起止位置的现象。
粘包问题只会出现在TCP中,不会出现在UDP中;
如何解决粘包问题?

明确报文边界也就是解决粘包问题,一定是我们程序员自己来解决的;
7.异常处理
7.1 服务器挂掉回发生什么?

服务器挂掉之后其实也就是服务器的进程退出,而文件的生命周期是随进程的,而服务器创建的套接字本质上也是文件,当服务器的套接字都关闭了,呢服务器和客户端之间建立的连接也会由双发的操作系统正常的进行四次挥手;
7.2 客户端机器重启
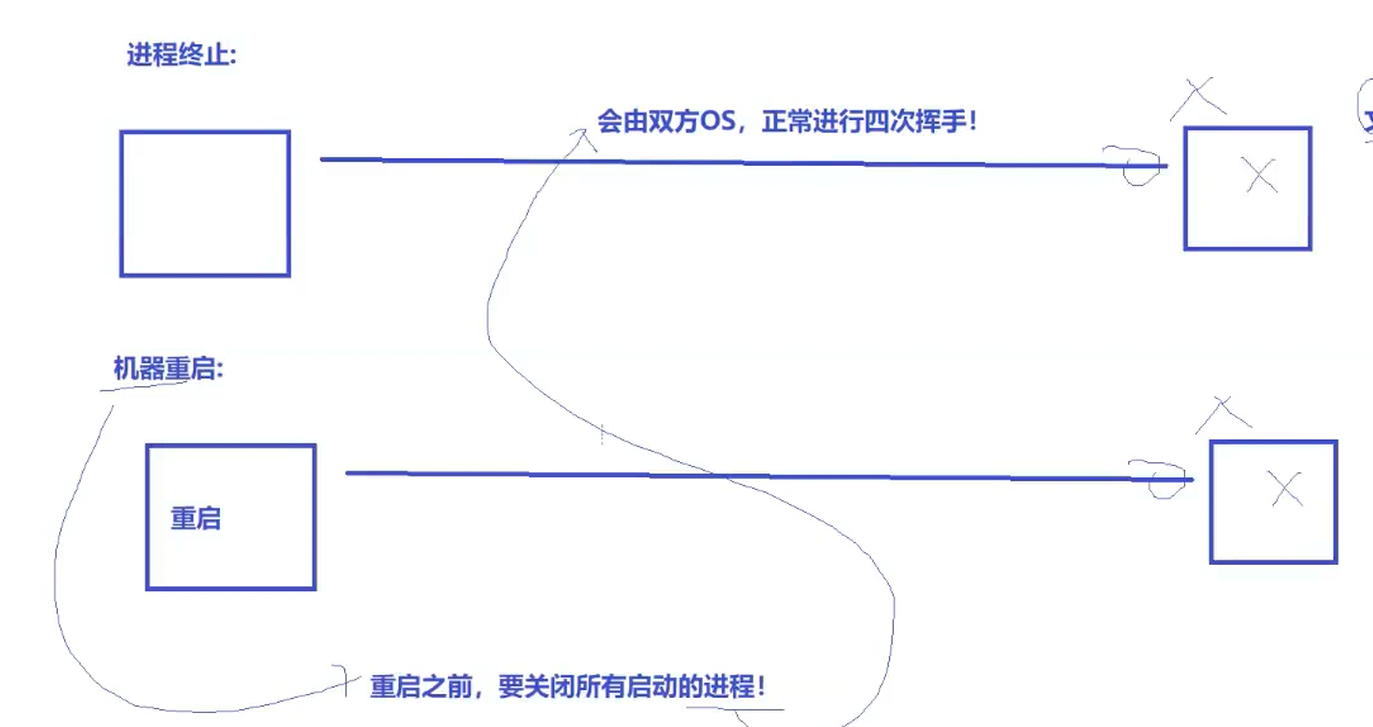
7.3 机器掉线或者网线断开
当我们的客户端或者是服务器的网线突然拔了之后,对端其实会单起一个进程进行连接保活,即每隔一段时间向对端发送消息询问对方是否上线;达到一定的时间如果对方还是没有回应,才会真的断开连接。这种过程叫做"连接保活",一般由应用层设计;这是一个保活计时器;
8.UDP如何提升自己的可靠性
可以设计超时重传机制,确认应答,等TCP设计的保证可靠性的机制;