一、导数和偏导数
在大模型的底层也就是机器学习和深度学习中,经常会遇到损失函数和代价函数的参数调整的问题(不清楚的可以看前面的文章)。也就是说如何调整参数可以让损失函数尽快的达到最小,即尽量吻合实际的目标值。这也意味着模型的训练达到了目的。
那么怎么调整参数呢?是随便拍拍脑袋就定下来,还是有什么规律可循呢?这就需要一点点数学知识了。回顾一下高数中的最基础的导数部分(现在高中已经学习了),"一元函数 f(x),其导数f′(x)表示函数在x处的变化率(切线斜率)。即如果自变量增加一个微小量dx,函数值大约变化f′(x)dx"。但实际情况往往是一个复杂的多参数影响的过程,这也就必须提到第二概念"偏导数","对于多元函数 f(x1,x2,...,xn),偏导数∂f/∂xi将其他变量视为常数,只对 xi求导。即只对函数沿第i个坐标轴方向的变化率"。这样说可能不好理解,其实就是视非求导的变量为无物(常量求导为0)。举个简单例子,买菜时更关心如果是菜的新鲜度,则忽略价格等其它因素。
二、几何分析
对于一元函数来说,在平面直角坐标中,很明显可以看出,切线的斜率(导数)越大,代表着x变化引起y变化的幅度越大。以爬山来说,越陡峭代表高度变化越剧烈。反之亦然。
而对于偏导数来说,可以先从三维坐标来看,x,y,z三个方向中,某两个方向组成一个共同的方向,如果用复数形式来看就是求模的方向,是不是有点熟悉?对,向量。推广开来,如果高维空间呢?四维五维等等。如果把这些组成一个向量,求它的模,是不是就可以代表多维的空间内沿某个方向的变化最大?
三、梯度
从上面的几何分析,其实就得到梯度的概念描述。梯度是一个向量,是由与损失函数的相关偏导数组成的即:
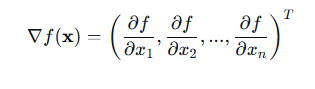
其中x =(x1,x2,...,xn)。对于梯度来说它有两个关键的性质即首先在方向上,是函数在该点处上升最快的方向(极值方向),这也意味着反方向是下降最快的方向;另外一个是在大小上,梯度的模长等于该方向上的方向导数(变化率最大)。
三、梯度下降
既然明白了梯度的方向就明白了梯度下降。即反方向的梯度就是损失函数参数更新的最优的方向。也就是求损失函数的最小值的方法。其核心就是沿着负梯度方向(变化最快)不断的小步幅调整,最终达到损失函数的极小值点。其描述公式为:
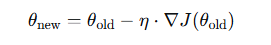
θ:当前位置
∇J(θold):函数在θ处的梯度(指向上升最快方向)
−∇J(θold):下降最快方向
η:学习率(步长),控制每次移动的距离
之所以有一个负值就是通过负梯度来寻找最快的下降方向,而学习率的目的是为了防止过大的步幅导致越过极小值。也就是让学习收敛的速度达到一个均衡的值。
用刚刚爬山的例子来说,就是下山的的路最短。但也要小心一些局部性最短,比如半山有一个山谷,虽然这部分最短,但到真正到达山脚,反而还要重新爬高才能下去。
四、大模型中的应用
在大模型的底层应用中,训练线性回归、神经网络等模型时,通过定义损失函数(如均方误差等),然后利用梯度下降不断更新参数权重,让损失函数达到最小值,即达到模型预测最优值。
在实际的应用中,梯度下降的学习率参数是一个非常关键的参数。过大时可能导致极值的消失甚至不减反增;而过小时,可能收敛速度太慢,导致一直停留在鞍占平坦区域。所以在不同的场景下如何选择学习率既是一个经验值又是一个实验值。
需要提醒的是,在实际的工程中,可能梯度下降找到的为局部最小值,从而导致模型的训练的不准确;也可能梯度虽然为零,但并非一个极值点(鞍点),还有可能进入了平坦区域,始终梯度无变化。另外也有可能多个参数间的梯度间的向量值变化剧烈,导致损失函数的结果异常。这些都需要在实践中密切关注。
四、梯度下降的种类和优化器
梯度下降可以分为三类:
- 批量梯度下降
就是对全部训练样本进行梯度计算,不过大数据量时,成本很高 - 随机梯度下降
随机选取一个样子,计算梯度来更新损失函数的参数,但收敛时可能会引发震荡 - 小批量梯度下降
这种其实就是综合了上面两种的特点进行的平衡,找一个小组形成小批量的梯度计算进行参数的更新
而在面对梯度下降出现的一系列问题时,可以采用下面的优化器进行处理:
- 动量法(Momentum):积累历史梯度方向,加速收敛并抑制振荡
- AdaGrad:为每个参数自动维护独立的学习率,在处理稀疏数据时比较合适
- RMSProp:改进版AdaGrad,对近期的梯度变化敏感,避免学习率降到零。
- Nesterov加速梯度(NAG):在动量中预先看到"未来"梯度
- Adam:结合动量(方向加速)和RMSProp(自适应步幅),附带偏差修正,是深度学习默认选择
六、总结
从本文看,在不涉及底层真正的技术情况下,还是引入了一些数学的知识。所以还是希望有志于搞大模型开发和应用的对数学知识还是有一点基础的。至少这样在和别人沟通时,不会两眼一瞪,不知所云。