内容概览
-
开场:Rust 的承诺到底是什么
Rust 不只是"更安全的 C++",它真正承诺的是:让程序员把意图写进类型和函数签名里。
-
从一个简单例子开始:为什么
String不能随便传两次通过
i64和String的区别解释Copy、移动语义和显式clone。 -
JavaScript 和 Go 的困境:函数会不会改我的数据,很难从签名看出来
对比对象、指针、浅拷贝、深拷贝,以及运行时检查的局限。
-
C/C++ 的
const为什么不够可靠
const可以表达约束,但语言本身允许绕开它,安全边界不够清晰。 -
Rust 的核心设计:所有权、共享引用、独占引用
Rust 用
T、&T、&mut T把"拿走、只读、可写"三种关系写进代码。 -
Unsafe Rust:不是随便危险,而是明确标记"编译器不再替你检查"
unsafe是边界,不是逃避责任的通行证。 -
Aliasing XOR Mutability:要么共享,要么修改,不能同时发生
解释 Rust 借用检查器最核心的约束。
-
结尾:Rust 的承诺不是让写代码更轻松,而是让错误更早暴露
本内容是对The promise of Rust的翻译与整理,有一定删减。
Rust 的承诺:不是没有复杂性,而是把复杂性放到你能看见的地方
很多人第一次接触 Rust,会被它的所有权、借用、生命周期劝退。
为什么一个字符串传给函数之后就不能再用了?
为什么读数据要写 &T,改数据要写 &mut T?
为什么明明我知道这段代码没问题,编译器却说不行?
fasterthanlime 的文章《The promise of Rust》讲的正是这个问题:Rust 最吓人的地方,恰恰也是它最有价值的地方。
Rust 的承诺不是"写起来永远简单",也不是"编译器永远懂你"。它真正承诺的是:
尽可能让程序的内存安全、可变性和资源所有权,在编译期被检查出来。
这篇文章我们就顺着原文的思路,聊聊 Rust 到底承诺了什么。
一、从一个最普通的函数开始
先看一个简单函数:
rust
fn show(n: i64) {
println!("n = {n}");
}
fn main() {
let n = 42;
show(n);
show(n);
}这段代码完全没问题。i64 是一个整数,复制它的成本很低,Rust 允许它被直接复制。也就是说,第一次 show(n) 并不会让 n 消失。
但如果把 i64 换成 String:
rust
fn show(s: String) {
println!("s = {s}");
}
fn main() {
let s = String::from("hello");
show(s);
show(s);
}第二次调用就会报错。
原因是:String 拥有堆上的内存。把它传给 show 时,所有权被移动进函数里。第一次调用后,main 里的 s 已经不再拥有那块字符串数据,所以不能再用一次。
这就是 Rust 的移动语义。
对于整数这种类型,复制只是寄存器之间搬一下值。
对于 String,复制可能意味着堆分配、内存拷贝、allocator 调度,成本不再微不足道。
所以 Rust 不会偷偷帮你复制。
如果你确实想复制,需要明确写出来:
rust
show(s.clone());
show(s);这就是 Rust 的一个基本态度:昂贵的事情不要隐式发生。
二、如果函数只是看一眼,就不要拿走所有权
如果 show 只是打印字符串,并不需要拥有它,那更合理的写法是借用:
rust
fn show(s: &String) {
println!("s = {s}");
}
fn main() {
let s = String::from("hello");
show(&s);
show(&s);
}这里的 &String 表示共享引用,也就是"我只是借来看一下"。
这个区别非常关键:
rust
fn consume(s: String) // 拿走所有权
fn read(s: &String) // 只读借用
fn update(s: &mut String) // 可变借用在 Rust 里,函数签名不是装饰品。
它直接告诉你:这个函数会不会拿走你的数据,会不会修改你的数据。
这就是 Rust 相比很多语言更"诚实"的地方。
三、JavaScript 的问题:对象到底会不会被改,很难从函数签名看出来
在 JavaScript 里,原始类型通常按值传递:
js
function inc(x) {
x += 1;
}
let x = 0;
inc(x);
console.log(x); // 还是 0但对象不是这样:
js
function inc(o) {
o.value += 1;
}
let o = { value: 0 };
inc(o);
console.log(o.value); // 变成 1问题在于:从函数签名 inc(o) 本身,你看不出它会不会修改对象。
如果你不希望原对象被改,可能会选择 clone:
js
inc({ ...o });但这只是浅拷贝。如果对象里面还有对象,内部那层仍然可能被改。
于是你可能会做深拷贝,比如很多人用过的:
js
JSON.parse(JSON.stringify(o))这又会带来新问题:循环引用怎么办?日期、Map、自定义类型怎么办?性能怎么办?
原文的重点不是说 JavaScript 不好,而是指出一个事实:
在 JavaScript 里,很多"会不会修改数据"的约束无法可靠地表达在函数签名里,只能靠约定、文档、测试和运行时行为。
四、Go 的问题:指针能表达可变性,但不能表达"只读指针"
Go 里,结构体默认按值传递:
go
type Obj struct {
value int
}
func inc(o Obj) {
o.value += 1
}这里修改的是副本,不会影响原值。
如果要修改原对象,就传指针:
go
func inc(o *Obj) {
o.value += 1
}这比 JavaScript 明确一些。看到 *Obj,你知道函数拿到了地址。
但问题也在这里:
如果一个函数接收 *Obj,它可能只是读取,也可能修改。调用方无法从类型上要求"你只能读,不能改"。
如果你想防止它修改,只能拷贝一份再传进去。
但和 JavaScript 一样,拷贝也有浅拷贝、深拷贝、循环引用、特殊类型这些问题。
原文用这个对比引出 Rust 的核心优势:
Rust 不只是区分"值"和"指针",它还能区分"共享引用"和"独占引用"。
五、C/C++ 的 const:看起来有约束,但边界不够硬
C 和 C++ 有 const。这似乎可以表达"我不会修改它"。
比如 C++ 里:
cpp
void read(const S& s) {
// 看起来不能修改 s
}但 C/C++ 的问题是,语言允许你通过类型转换绕过 const。
这意味着 const 更像是一种约定,而不是绝对可靠的安全边界。
在大型代码库里,你不能指望每个调用链、每个第三方库、每个宏、每个 unsafe-ish 技巧都遵守这层约定。
原文里有一句很强烈的判断:C 和 C++ 本质上过于宽松。你可以继续用工具、规范、审查、静态分析去补洞,但语言本身没有把安全边界封死。
这也是 Rust 想改变的地方。
六、Rust 的表达方式:拿走、只读、可写
Rust 用三种常见参数形式表达三种不同意图。
1. T:拿走所有权
rust
struct Conn;
fn close(conn: Conn) {
// 关闭连接,释放资源
}
fn main() {
let conn = Conn;
close(conn);
close(conn); // 编译错误
}如果 close 接收的是 Conn,就表示调用者把连接交出去了。
交出去之后,不能再用。
这可以防止"双重关闭"这类资源管理错误。

2. &T:共享引用,只读
rust
struct Conn {
name: String,
}
fn name(conn: &Conn) -> &str {
&conn.name
}这里函数只是读取连接名。
它不能修改 conn.name,编译器会阻止。
更重要的是,这种不可变性是传递的。
就算字段里还有字段,也不能通过共享引用一路钻进去修改内部数据。
3. &mut T:独占引用,可以修改
rust
fn rename(conn: &mut Conn) {
conn.name = String::from("new-name");
}如果函数要修改数据,签名必须写 &mut Conn。
调用方也必须显式传入:
rust
let mut conn = Conn {
name: String::from("old-name"),
};
rename(&mut conn);这里有两个显式动作:
let mut conn:这个绑定允许被修改&mut conn:把它作为可变引用借出去
Rust 不会让"可变性"悄悄发生。
七、Unsafe Rust:不是没有危险,而是危险被圈起来了
Rust 并不是完全禁止底层操作。
你仍然可以使用裸指针,也可以写 unsafe。
但 Rust 的关键区别是:危险区域必须被显式标记。
比如你可以把共享引用转成裸指针,再转成可变裸指针。
但当你真的要解引用裸指针并写入时,编译器会要求你进入 unsafe 块。
rust
unsafe {
// 编译器不再替你证明这里安全
}这并不表示 unsafe 里面的代码一定错。
它表示:这里有些事情编译器无法自动验证,程序员必须自己保证不破坏 Rust 的内存安全规则。
原文还提到 Miri。Miri 是 Rust 官方项目中的解释器工具,可以帮助发现某些未定义行为。它不能替代审查,但能让很多隐藏问题更早暴露。
这就是 Rust 的工程哲学:
不是假装底层复杂性不存在,而是把它隔离到明确边界里。
八、Rust 的核心规则:Aliasing XOR Mutability
原文后半部分讲了一个非常重要的概念:Aliasing XOR Mutability,简称 AXM。
可以简单理解成:
要么多个地方共享读取同一份数据,要么只有一个地方能修改它。不能既共享又修改。
多个共享引用是允许的:
rust
let conn = Conn;
let a = &conn;
let b = &conn;
let c = &conn;但多个可变引用不允许:
rust
let mut conn = Conn;
let a = &mut conn;
let b = &mut conn; // 编译错误为什么这么严格?
因为如果多个地方都能同时修改同一份数据,尤其是在多线程环境里,就可能出现数据竞争。数据竞争不是"业务逻辑 bug"那么简单,它可能导致内存破坏,甚至成为安全漏洞。
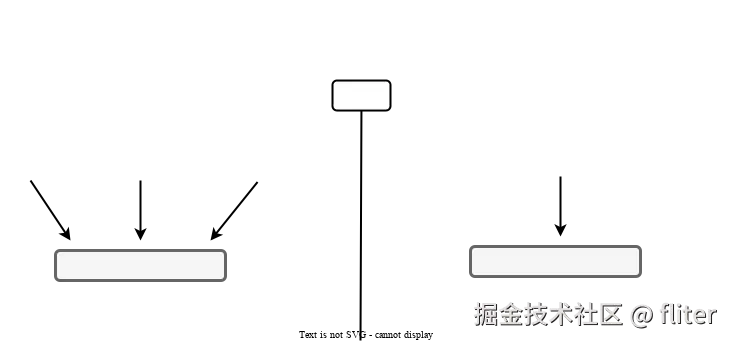
Rust 的借用检查器就是在维护这条规则。
当然,借用检查器并不完美。
有些程序在逻辑上是安全的,但编译器无法证明,于是会拒绝它。
这也是 Rust 学习曲线陡峭的原因之一:你不只是在写程序,还在学习如何把程序结构写成编译器能理解的形状。
九、当借用检查器太严格怎么办
Rust 不是只给你一条路。
如果你确实需要更灵活的共享和修改关系,可以把部分检查推迟到运行时。
单线程里常见组合是:
rust
Rc<RefCell<T>>多线程里常见组合是:
rust
Arc<Mutex<T>>RefCell 允许在运行时检查借用规则。
Mutex 允许多线程场景下通过加锁来保护数据。
这不是"绕过 Rust",而是用 Rust 提供的抽象选择不同的成本模型:
- 编译期检查:更严格,零运行时成本
- 运行时检查:更灵活,但有额外成本
unsafe:最灵活,但需要人工保证安全
Rust 并没有消灭复杂性。
它只是让你明确选择把复杂性放在哪里。
十、Rust 的承诺到底是什么
Rust 的承诺不是:
- 写代码更短
- 永远不用思考内存
- 编译器永远接受你认为正确的代码
- 所有复杂性自动消失
Rust 的承诺更接近于:
- 资源所有权可以被类型系统表达
- 函数能不能修改参数可以从签名看出来
- 很多内存错误会在编译期暴露
- 不安全代码有明确边界
- 程序结构会被迫更诚实
这也是为什么很多人刚开始写 Rust 会觉得痛苦,但一旦"开窍",又很难回到以前的模式。
因为你会开始习惯这样的确定性:
rust
fn read(x: &T)只读。
rust
fn write(x: &mut T)可写,但必须独占。
rust
fn consume(x: T)拿走,之后不能再用。
这种表达力,就是 Rust 最吸引人的地方。
结语:Rust 让你更早面对真实问题
JavaScript 和 Go 往往把很多问题留到运行时。
C 和 C++ 允许你表达很多东西,但也允许你轻易绕过安全边界。
Rust 则选择在编译期尽可能多地拒绝不确定性。
这会让开发过程更慢一点,也会让初学者更容易受挫。
但它换来的是另一种确定感:当代码通过编译时,你知道很多低层风险已经被系统性排除。
Rust 的承诺,不是让编程变得轻松。
而是让那些原本隐藏在运行时、测试覆盖之外、代码审查盲区里的问题,尽可能提前出现在你面前。
当类型系统从敌人变成队友时,你写出来的程序不只是"能跑",而是更接近"结构上不容易错"。
这就是 Rust 的承诺。