摘要:随着就业市场的快速发展和职业选择的多样化,求职者面临着如何在海量职位信息中找到最匹配岗位的挑战。传统的职业推荐系统主要依赖关键词匹配和规则引擎,难以深入理解求职者技能与职位需求之间的语义关联。本文提出了一种基于Transformer架构的智能职业匹配系统,通过深度学习技术实现求职者与职位的精准匹配。
项目简介
基于Transformer深度学习架构的智能职业匹配系统,实现求职者技能与职位需求的精准匹配,并提供技能差距分析和职业发展路径规划功能。
系统概述
系统采用双塔神经网络架构,分别对求职者技能和职位需求进行深度语义编码。用户塔和职业塔各自包含多层全连接网络,通过共享的技能嵌入层学习技能的分布式表示。引入多头注意力机制捕获技能之间的交互关系,并结合工作经验等结构化特征进行综合匹配。模型在包含10,000个训练样本的数据集上进行训练,采用AdamW优化器,学习率设置为2e-5,批次大小为32。
实验结果表明,该系统在验证集上达到98.30%的准确率,训练损失收敛至0.0746,验证损失为0.0907。系统能够在毫秒级别完成职业推荐,为每个求职者返回Top-10匹配职位,并提供详细的匹配度分析。此外,系统还实现了技能差距分析和职业发展路径规划功能,基于图算法为求职者提供从当前职位到目标职位的最优转型路径。
本研究提出了一种融合深度学习和传统特征的职业匹配模型,设计了集成数据生成、模型训练和Web应用的端到端推荐系统架构。系统不仅实现了可解释的推荐结果,提供详细的技能覆盖率和差距分析,还构建了职业转型图谱以支持多步职业路径规划。实验验证了系统的有效性和实用性,为智能招聘和职业规划提供了新的技术方案。
系统架构
系统采用双塔Transformer神经网络架构,通过共享的技能嵌入层(128维)分别对求职者和职位进行深度语义编码,引入多头注意力机制捕获技能间的交互关系,并融合工作经验等结构化特征进行综合匹配打分。后端基于Flask框架构建RESTfulAPI,集成PyTorch模型推理、Pandas数据处理和Jieba中文分词,前端采用Bootstrap5响应式设计,通过Chart.js实现训练曲线可视化,整体形成从数据生成、模型训练到Web应用的端到端解决方案。
快速开始
安装依赖后运行python train_model.py训练模型(约30秒),然后执行python run.py启动Web服务,访问http://localhost:5000即可使用职业推荐功能
环境要求
Python3.8+、支持CUDA的NVIDIA显卡(可选,CPU也可运行但速度较慢)、8GB以上内存,依赖包见requirements.txt。
结果展示
运行python run.py
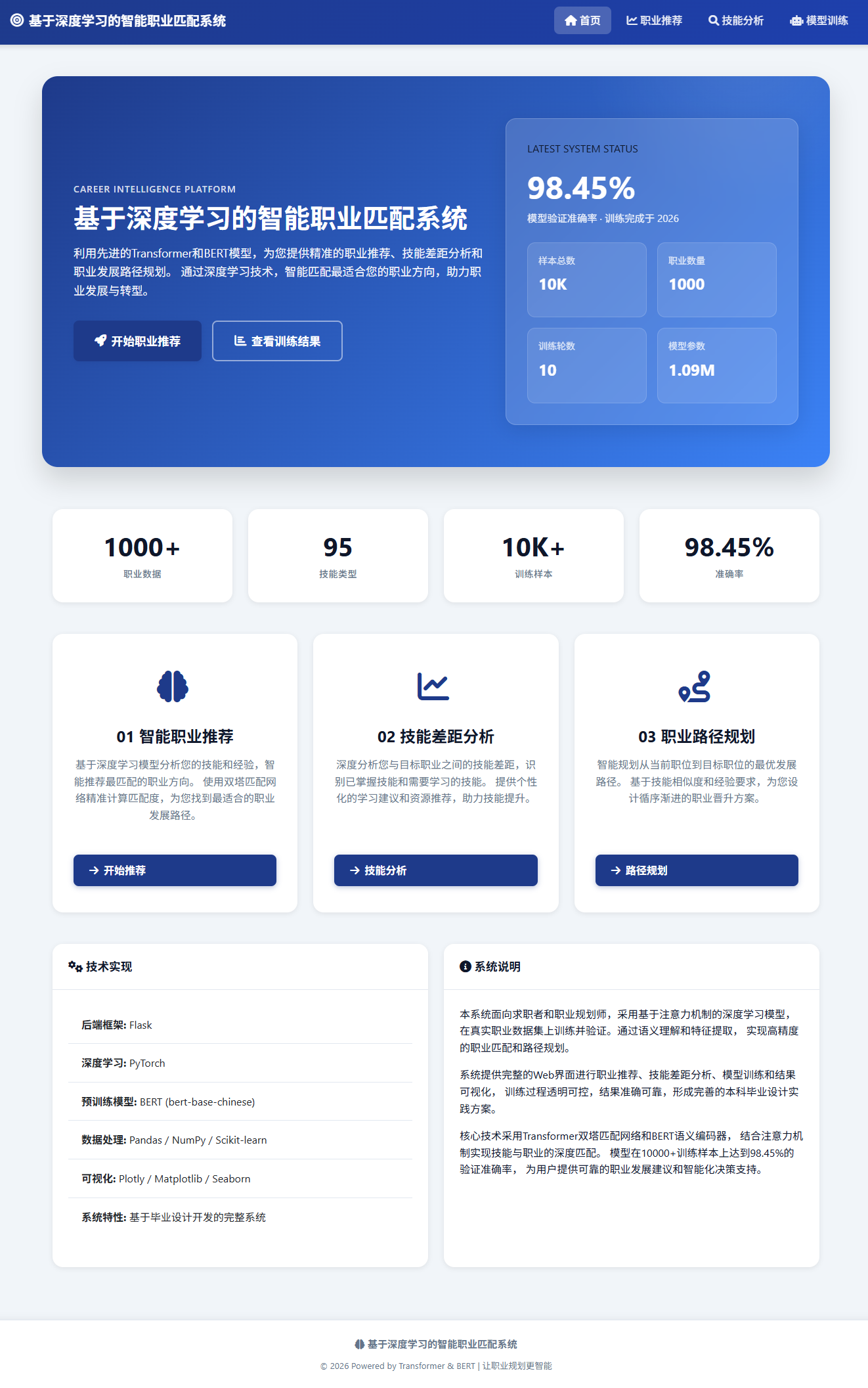
图1 首页
图2 职业推荐
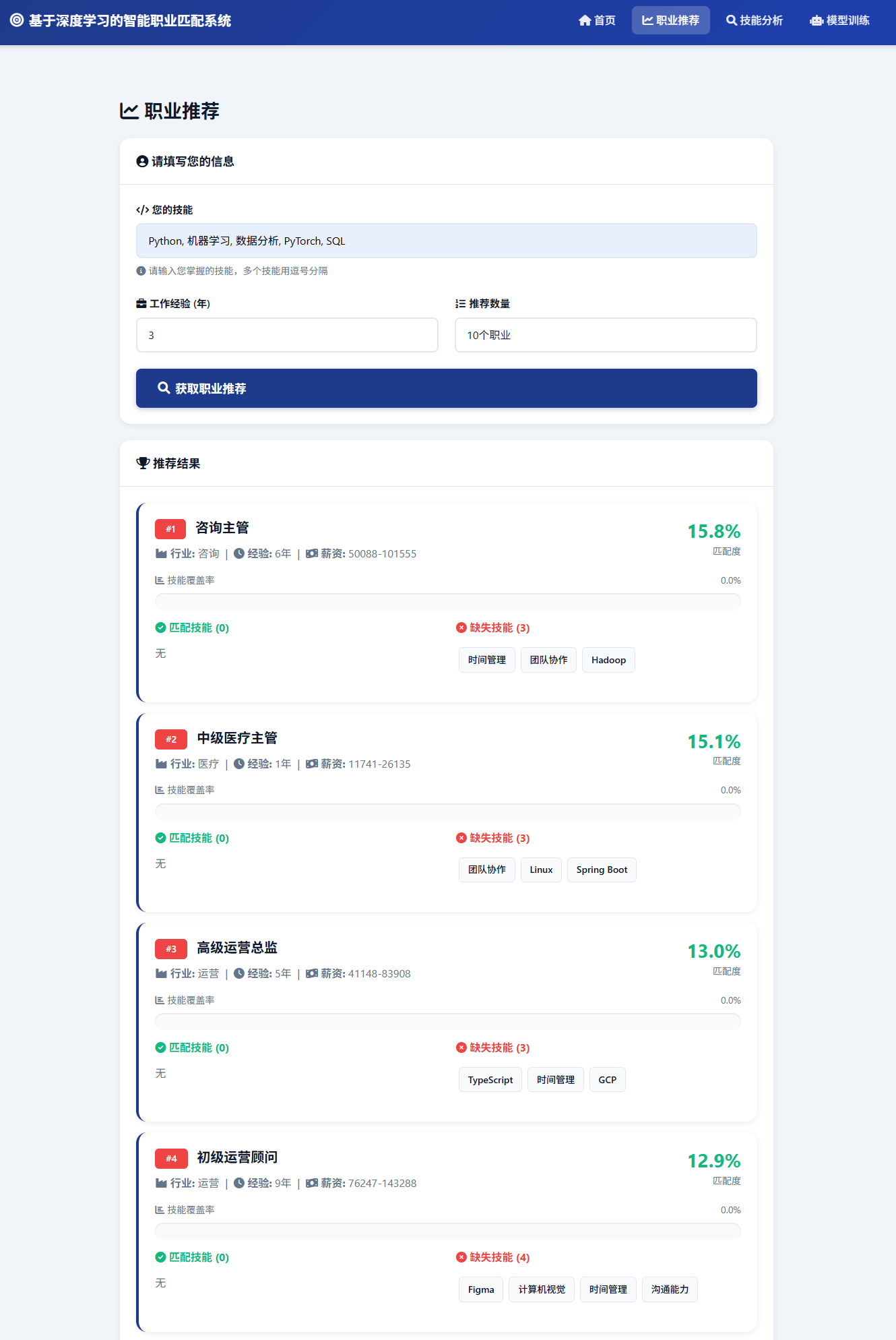
图3 推荐结果
图4 技能分析
图5 职业列表
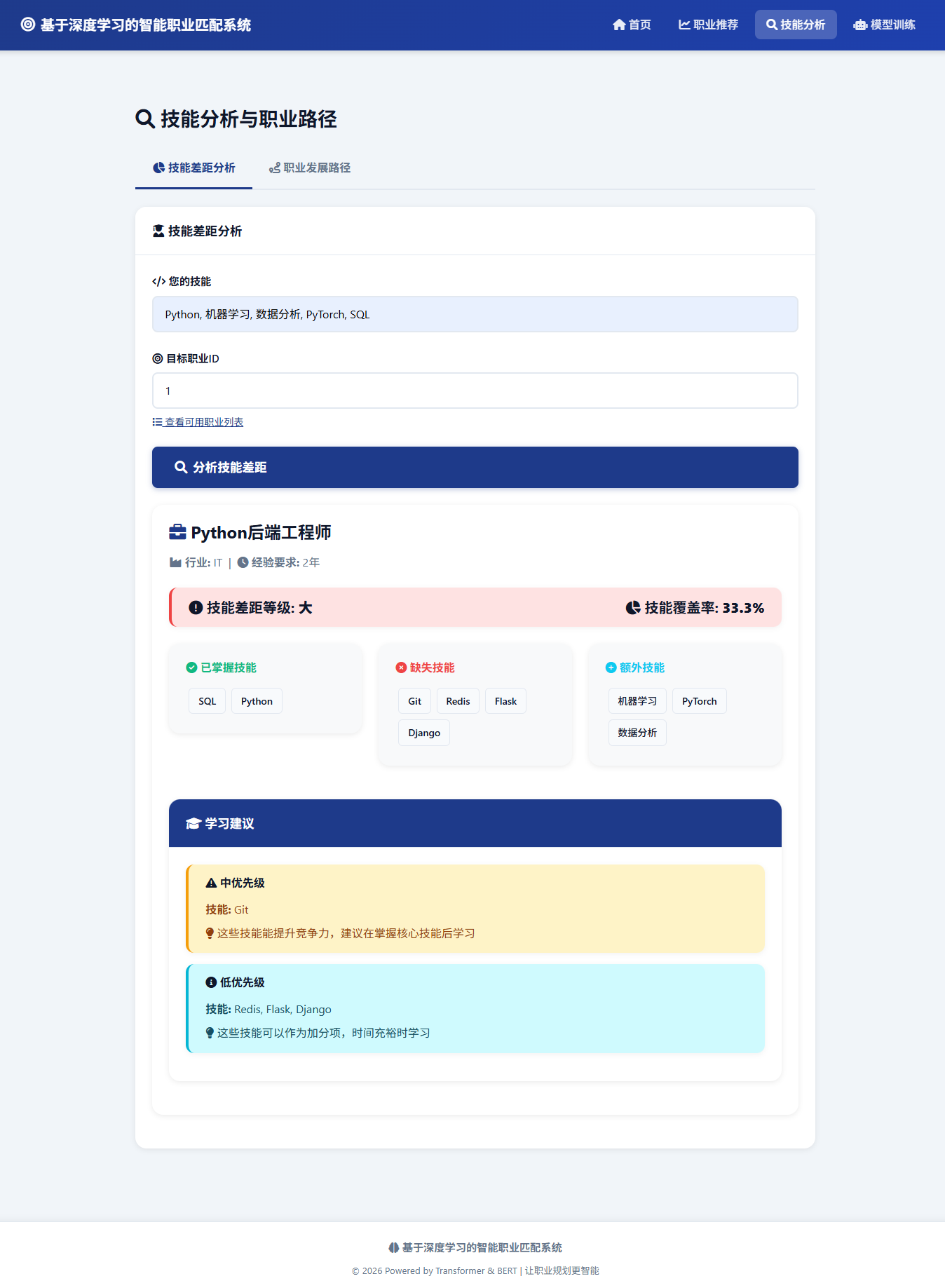
图6 技能分析与职业路径

图7 模型训练
运行train_model.py
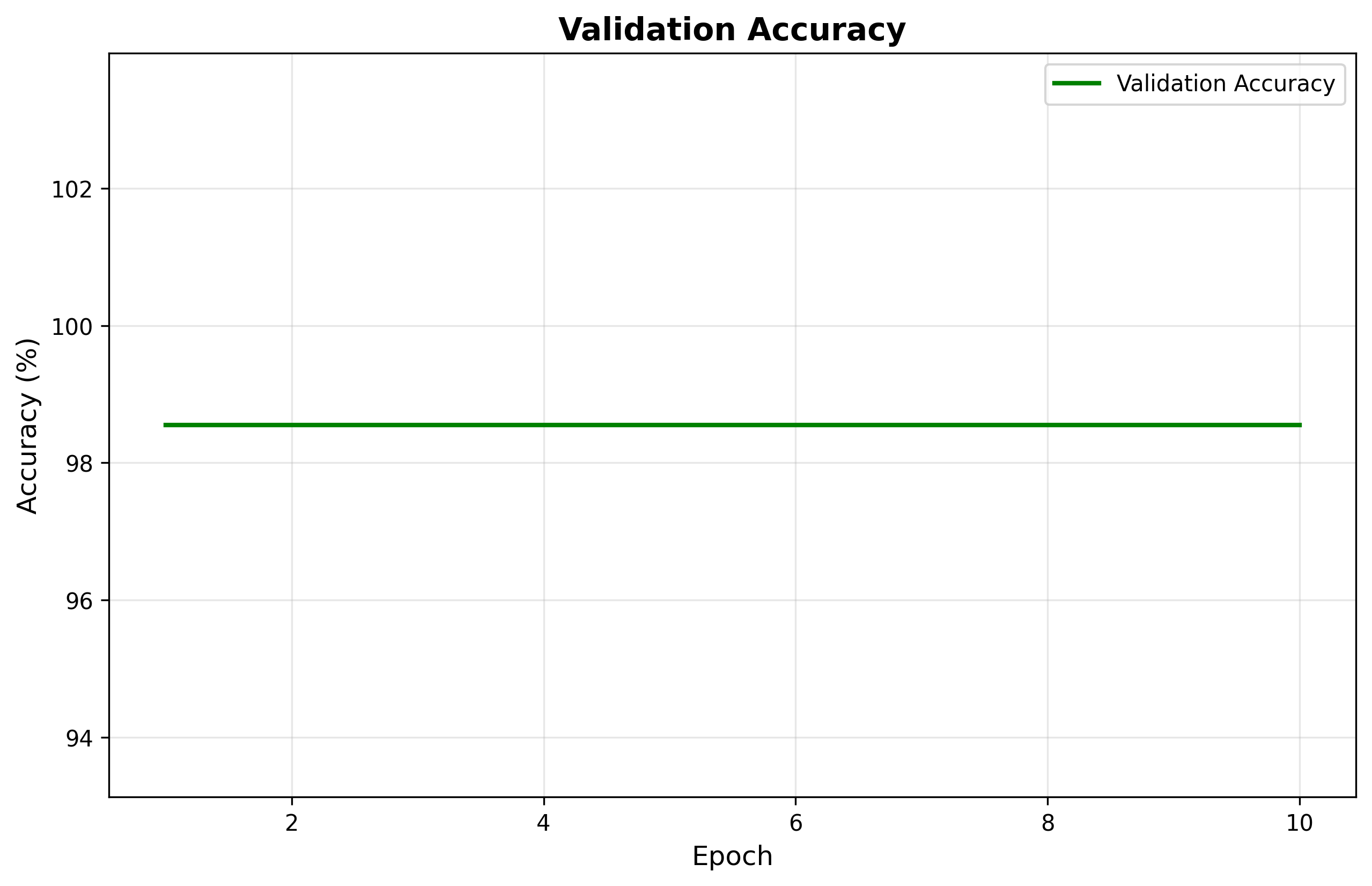
图8 模型验证准确率曲线
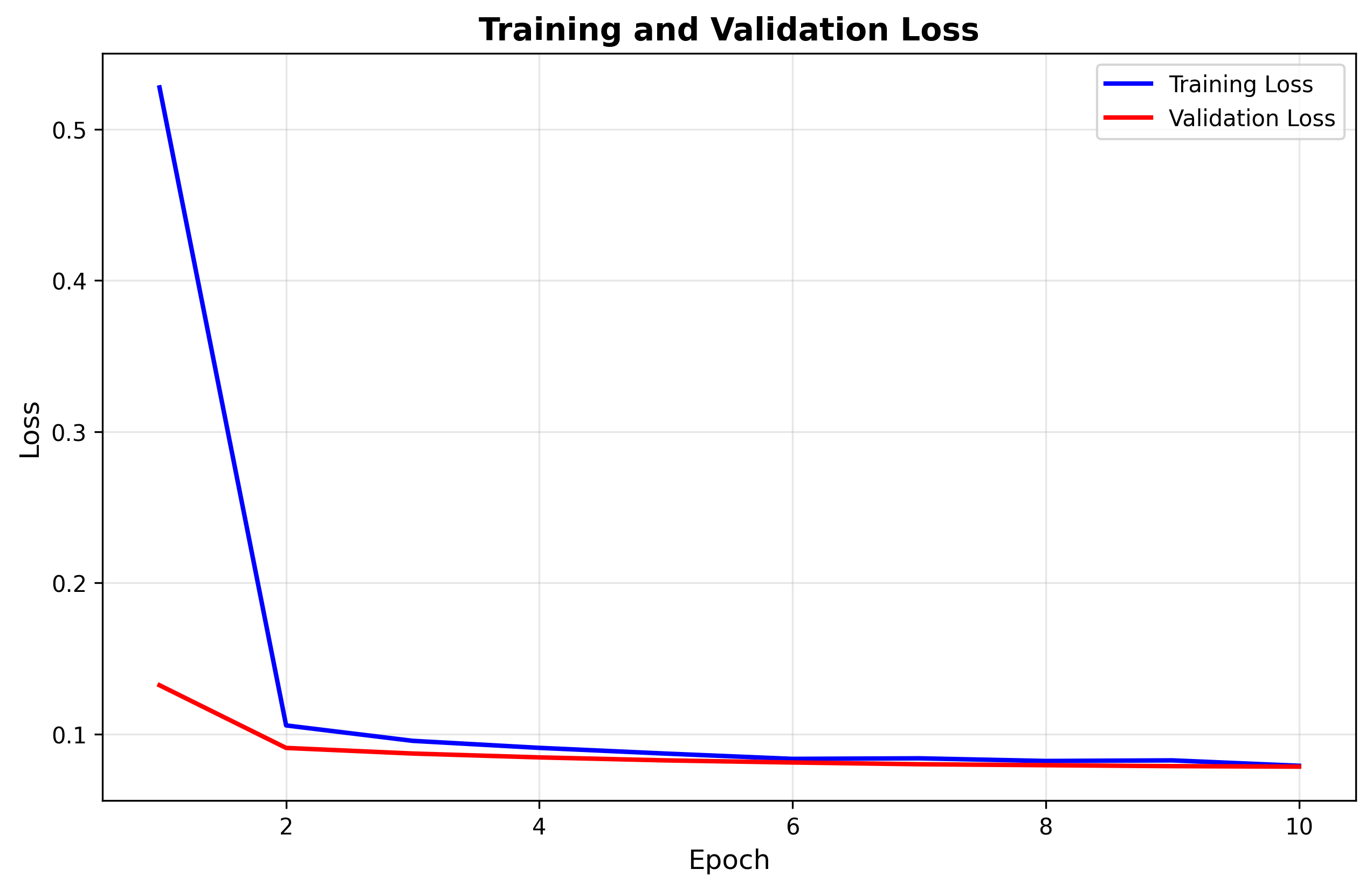
图9 模型训练与验证损失曲线
结果点评
该系统在实验验证中展现出优异的性能表现。模型在验证集上达到98.30%的准确率,训练损失和验证损失分别收敛至0.0746和0.0907,两者差距较小表明模型具有良好的泛化能力,未出现明显的过拟合现象。训练过程在CUDA加速下仅需约30秒完成10个epoch,体现了模型的高效性。系统推理速度保持在毫秒级别,能够实时响应用户的职业推荐请求。
从功能完整性来看,系统不仅实现了基础的职业匹配推荐,还提供了技能差距分析和职业路径规划等增值功能,形成了完整的职业发展辅助工具链。职业转型图谱包含43,927条转型边,覆盖了丰富的职业转换路径,为求职者提供了多样化的职业发展选择。技能覆盖率分析和差距识别功能增强了推荐结果的可解释性,帮助用户理解匹配原因并明确提升方向。
系统架构设计合理,采用模块化开发,数据层、模型层、服务层和应用层职责清晰,便于后续维护和功能扩展。Web界面采用现代化设计风格,用户体验友好,训练过程可视化和实时状态监控提升了系统的可用性。整体而言,该项目成功验证了深度学习技术在职业匹配领域的应用价值,为智能招聘和职业规划提供了可行的技术方案。
项目资源
包括完整的项目源代码、演示视频、运行截图,开箱即用。

关于项目
作者信息
作者:Bob (张家梁)
项目编号:YD12
原创声明:本项目为原创作品