目录
查看客户端连接情况
相关命令:
sql
show processlist;实操:

库的操作
创建数据库
相关命令:
sql
create database [if not exists] [数据库名] [character set {字符集名}] [collate {字符校验规则}]
/*
[数据库名]:指明要创建的数据库的名字,必须
[if not exists]:加上这个字段表明只有要创建的数据库不存在的时候才会创建该数据库,非必须
[character set {字符集名}]:指明该数据库用的字符集,show charset可以查看mysql支持的字符集种类,非必须
[collate {字符校验规则}]:指明该数据库用的字符校验规则,show collation 可以查看mysql支持的校验规则种类,非必须
*/实操:

字符集:
字符集决定了这个数据库如何把二进制解释成字符以及如何把字符翻译成二进制,只有两个系统字符集一样才能正确通信。
字符校验规则:
就是说在该数据库的表中在查找或者排序的时候,要不要把大写字母和小写字母看成一回事,上面实操中的"utf8mb4_general_ci"就是表明不区分大小写,而"utf8_bin"表明要严格区分大小写。
查看已存在的数据库
相关命令:
sql
show databases;显示数据库的信息
相关命令:
sql
show create database [数据库名]实操:

使用数据库
相关命令:
sql
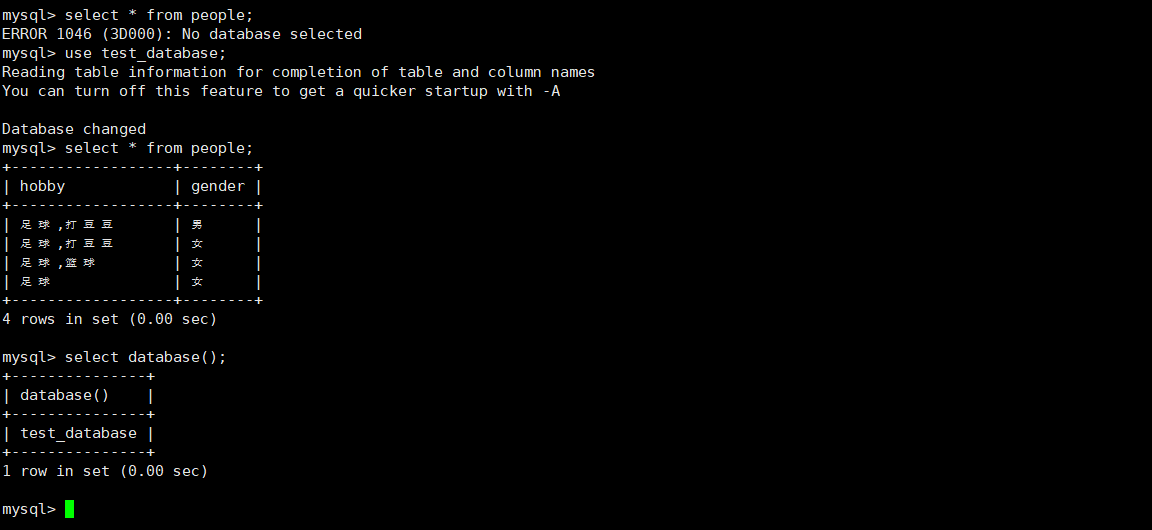
#使用数据库
use [数据库名];
#查看当前所在数据库
select database();选中数据库后,才能对其中的表结构进行操作,下面是例子:
修改数据库
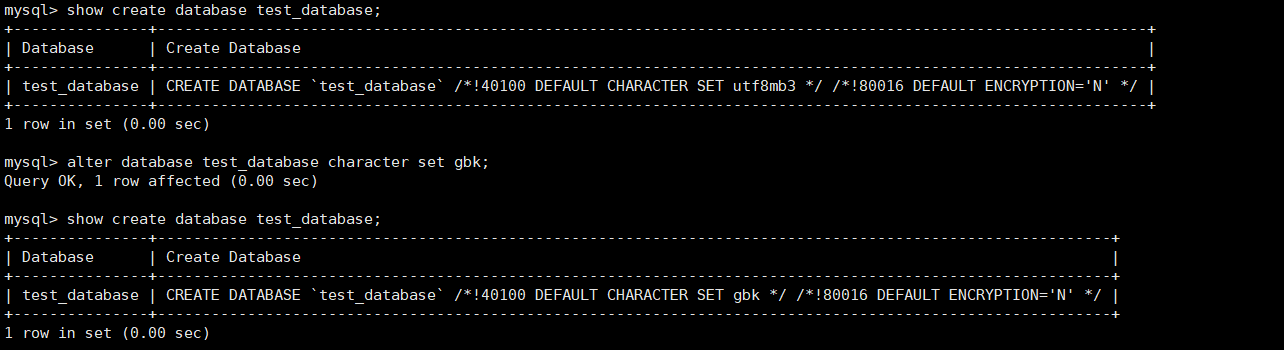
主要是修改字符集和校验规则
相关命令:
sql
alter database [数据库名] [character set {字符集名}] [collate {字符校验规则}] 实操:
数据库删除
数据库一旦被删,里面表的内容都一起删除
相关命令:
sql
DROP DATABASE [IF EXISTS] [数据库名];
/*
[IF EXISTS]:加上这个字段表明只有数据库存在才执行删除语句
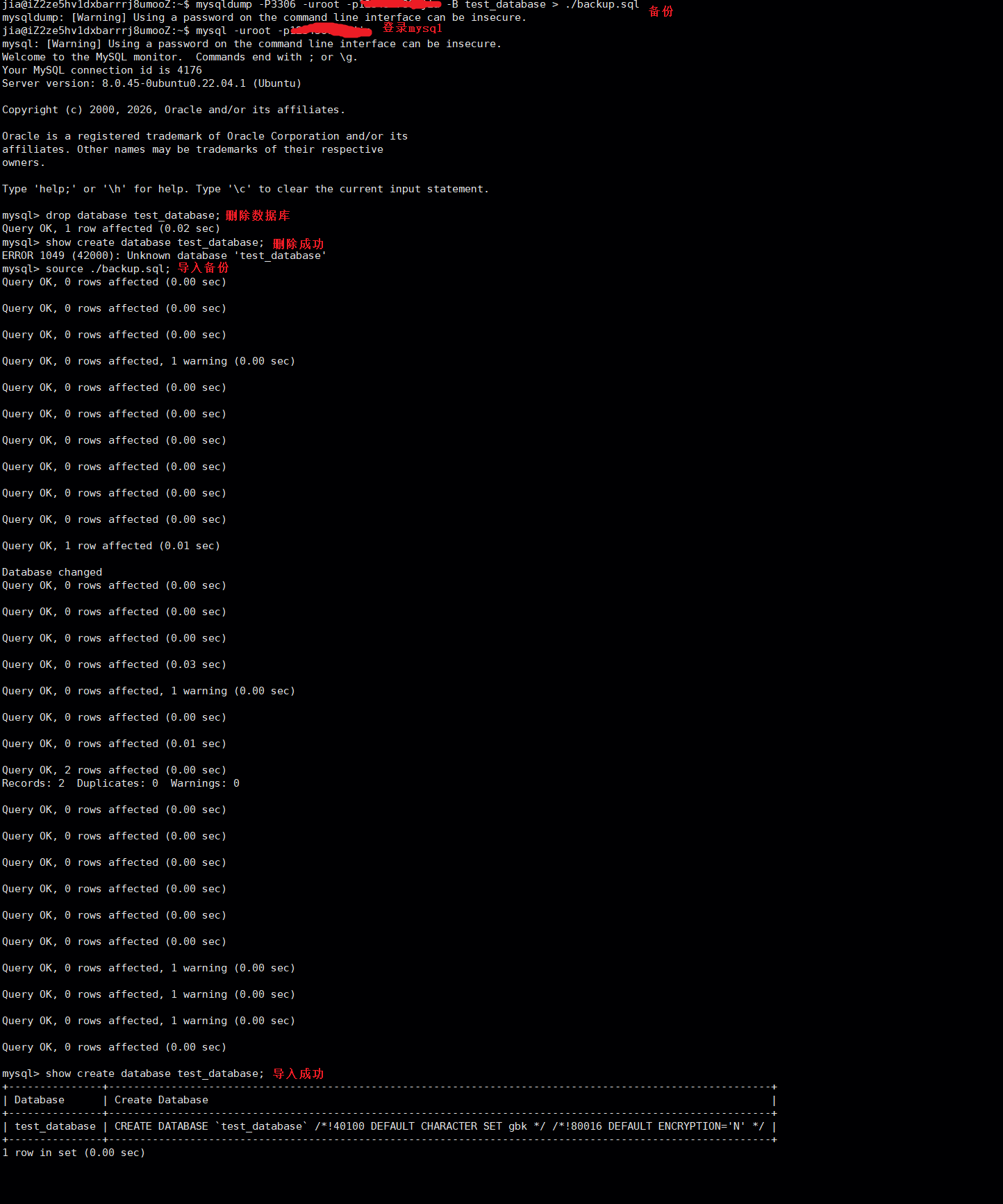
*/数据库备份
备份要在xshell命令行进行,复原要在mysql客户端内进行
相关命令:
bash
#把数据库的内容备份到一个.sql文件
mysqldump -P[mysql服务的端口号] -u[用户名] -p[密码] -B [要备份的数据库名,多个数据库用空格隔开] > [要把备份保存在哪个文件里,文件名后缀为sql,要指明路径];
#把备份的内容还原
source [文件名,要带路径]实操:
如果要备份的是表而不是整个库:
sql
mysqldump -u[用户名] -p[密码] -B [数据库名] [表名,多个表名用空格隔开] > [要把备份保存在哪个文件里,文件名后缀为sql,要指明路径]如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据****库,然后再使用source来还原
表的操作
创建表
相关命令:
sql
CREATE TABLE [if not exists] table_name (
field1 datatype,
field2 datatype,
field3 datatype
) [character set {字符集}] [collate {校验规则}] [engine 存储引擎];
#表也可以单独设置字符集和校验规则
#创建表的时候可以选择存储引擎
#创建一个和旧表一样的新表,数据不复制
create table [新表名] like [旧表名]实操:

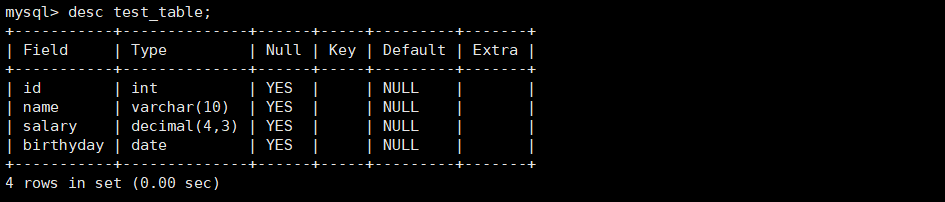
查看表结构
相关命令:
sql
desc [表名];实操:
修改表
sql
ALTER TABLE [表名] ADD [新增字段名 字段类型等修饰] [after 已有字段名];
#[after 已有字段名] 可以指定新增字段跟在谁后面,不必须
ALTER TABLE [表名] MODIfy [要修改的字段名 字段类型等修饰]
AlTER TABLE DROP [要删除的字段名]
alter table [旧的表名] rename to [新的表名];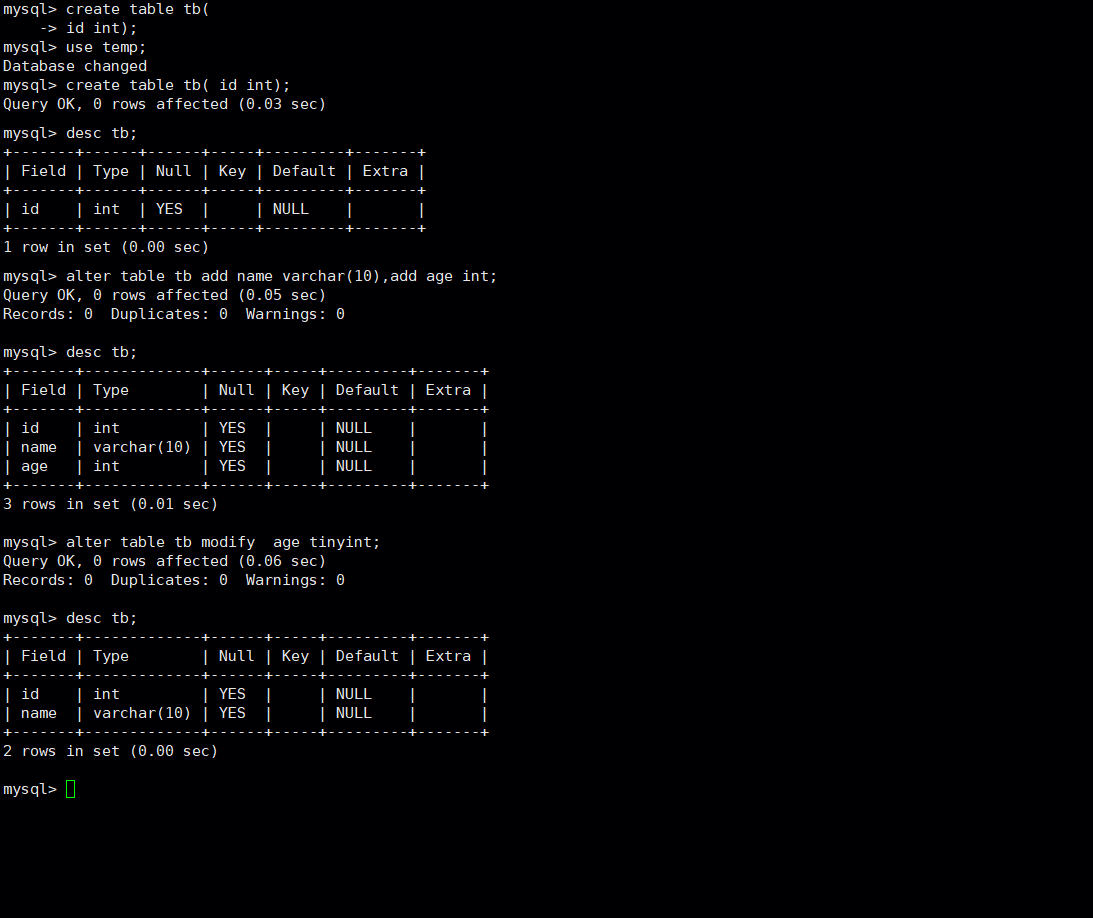
删除表
相关命令:
sql
DROP TABLE [IF EXISTS] tbl_name;表的基本增删改查
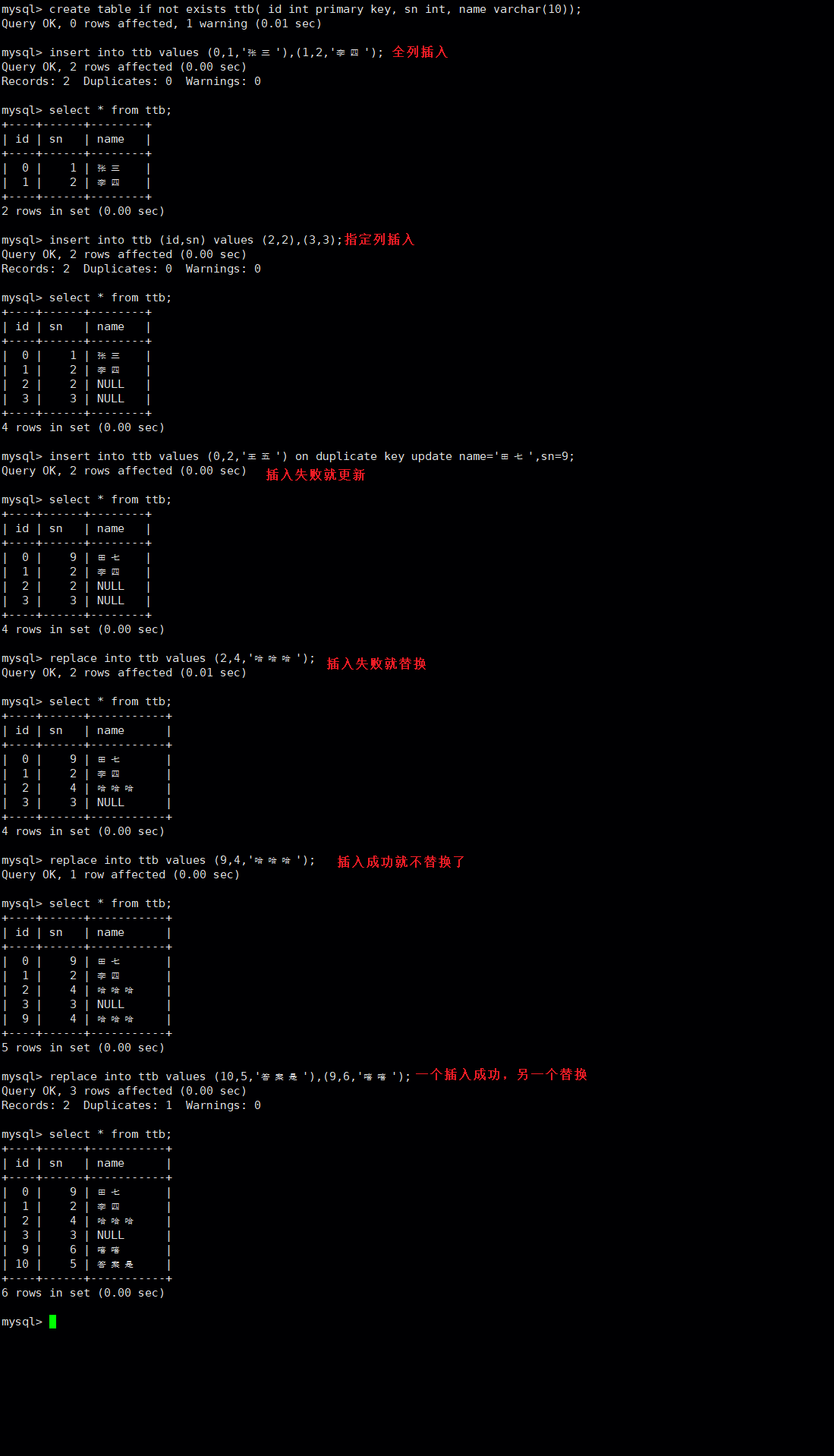
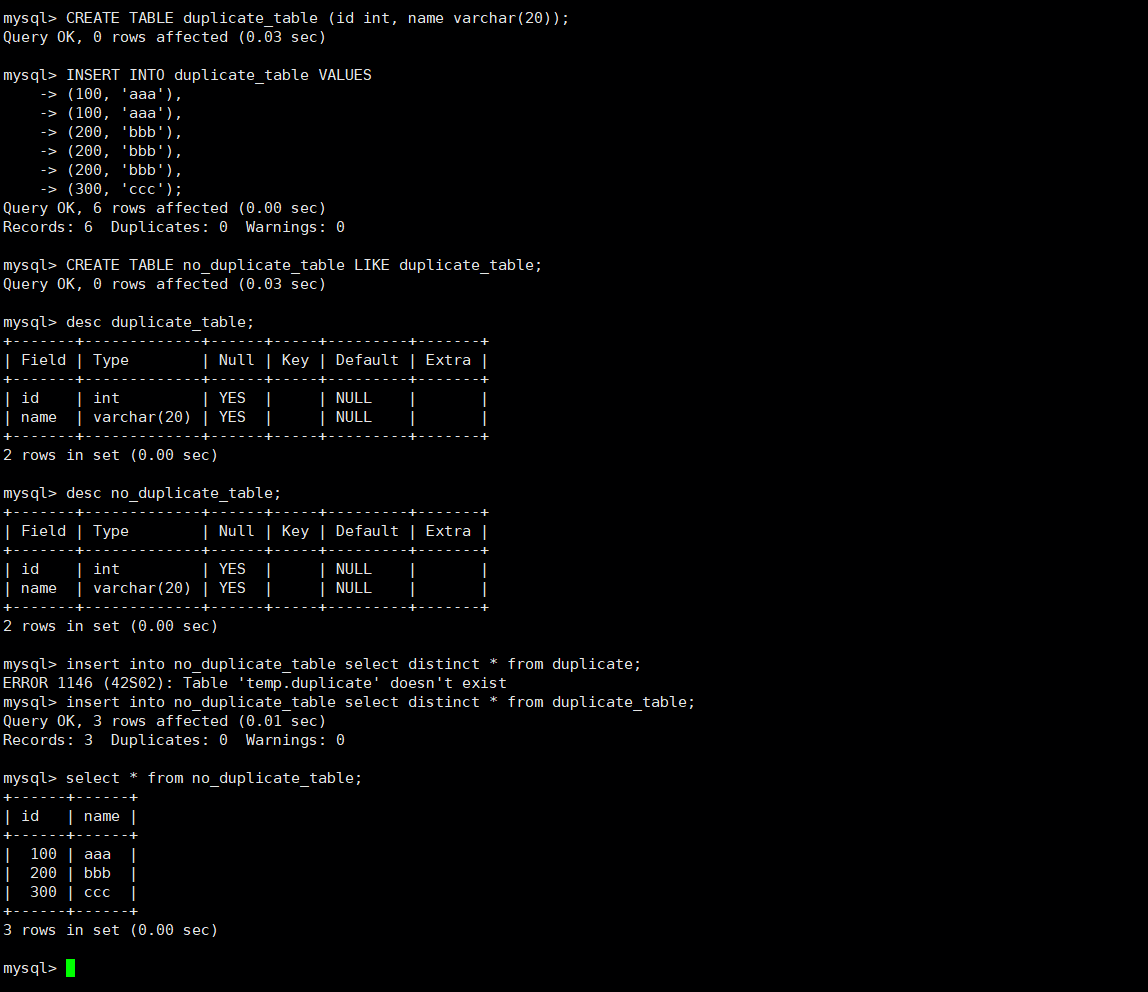
插入
相关命令:
sql
#全列插入(可一次性插入多行数据)
insert into [表名] values ([第一列的值,第二列的值,... ...]),([第一列的值,第二列的值,... ...]),... ...
#指定列插入(可一次性插入多行数据)
insert into [表名] (指定列1,指定列2... ...) values ([第一列的值,第二列的值,... ...]),([第一列的值,第二列的值,... ...]),... ...
#尝试插入,如果因为主键或者唯一键重复而插入失败就更新
[插入语句] on duplicate key update [字段={新的值},字段={新的值}... ...]
#尝试插入,如果因为主键或者唯一键重复而插入失败就删除原有数据在插入(可以一次性插入或删除后插入多行)
replace into [表名] values ([第一列的值,第二列的值,... ...]),([第一列的值,第二列的值,... ...]),... ...
#插入查询结果
insert into [表名] [查询语句];实操:
查询
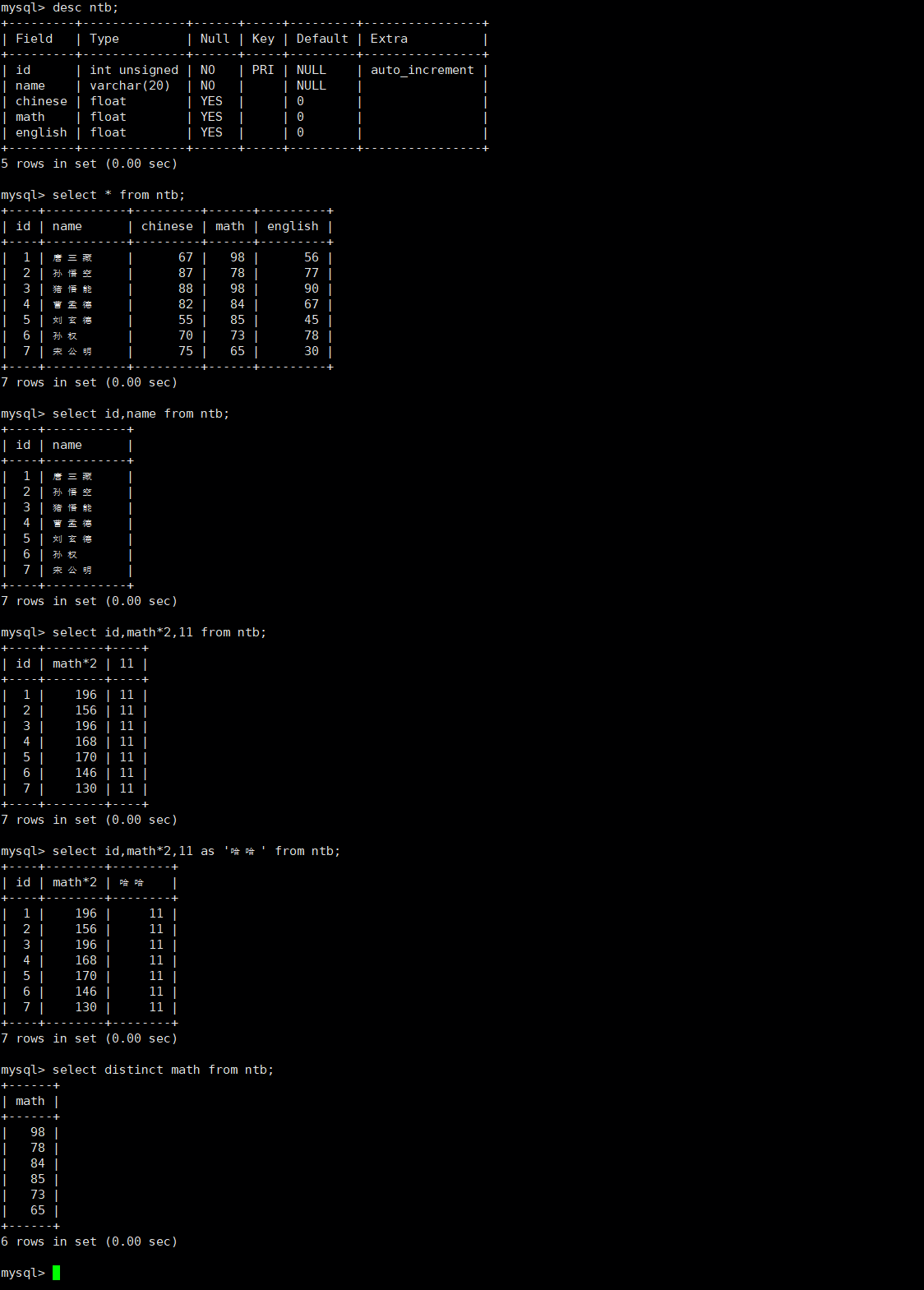
普通查询
相关命令:
sql
#标准查询语句
select [表示要查询哪些字段的内容,多个字段用','隔开,*表示全部字段] from [表名];
#查询内容包含表达式
select [eg: 字段名+10、字段名*字段名、5、mysql内置函数] from [表名];
#为查询结果指定别名
select [字段名 as {别名},字段名 as {别名}... ...] FROM [表名];
#对查询出来的结果去重
select distinct [表示要查询哪些字段的内容,多个字段用','隔开,*表示全部字段] FROM [表名];实操:
条件查询
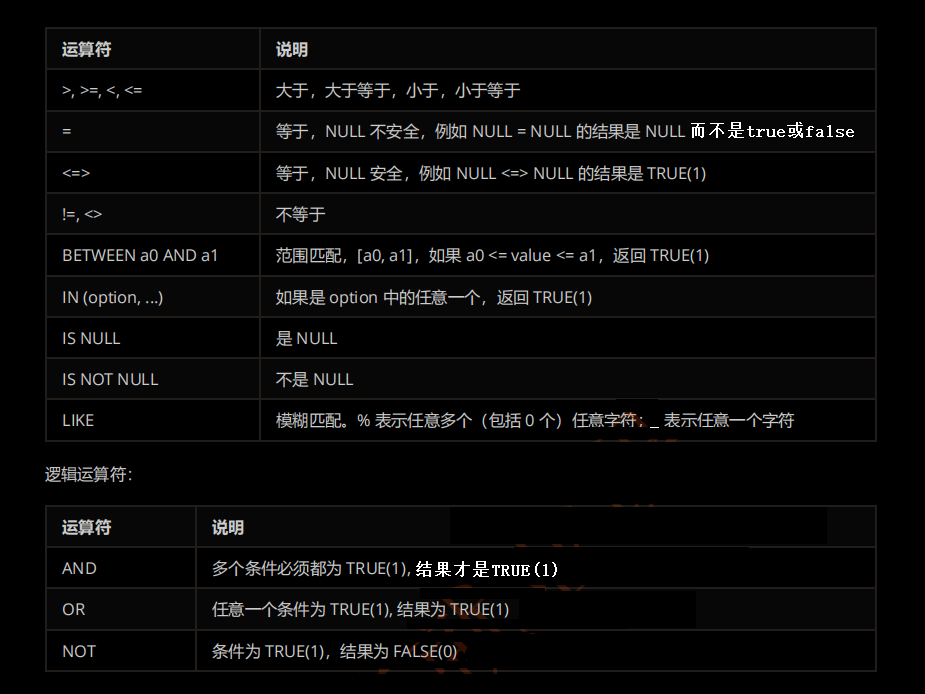
相关命令:
sql
#标准查询语句
select [表示要查询哪些字段的内容,多个字段用','隔开,*表示全部字段] from [表名] where [条件];实操:
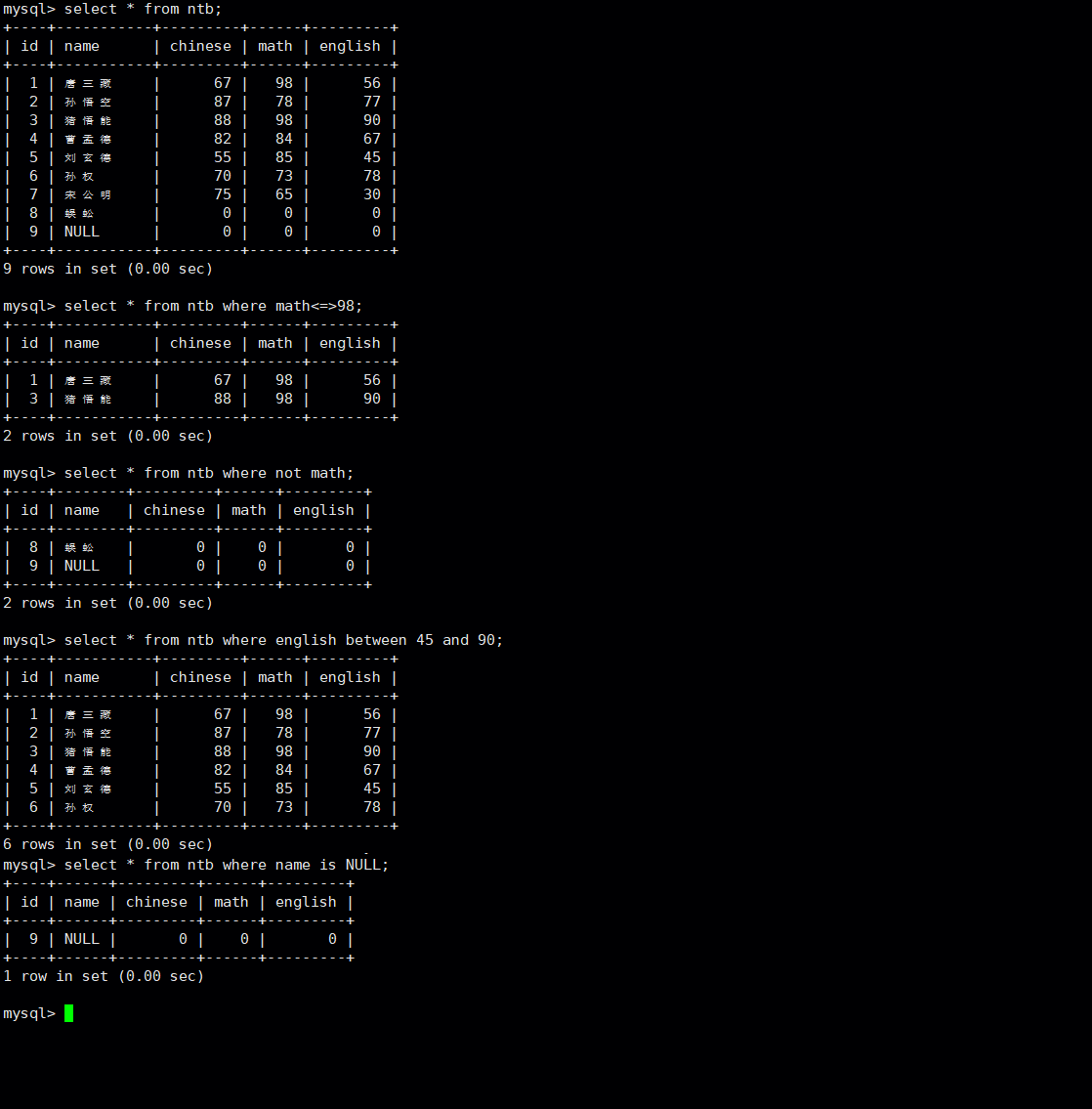
排序查询
相关命令:
sql
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
select ... from [表名] order by [字段名 排序规则,字段名 排序规则... ...];实操:
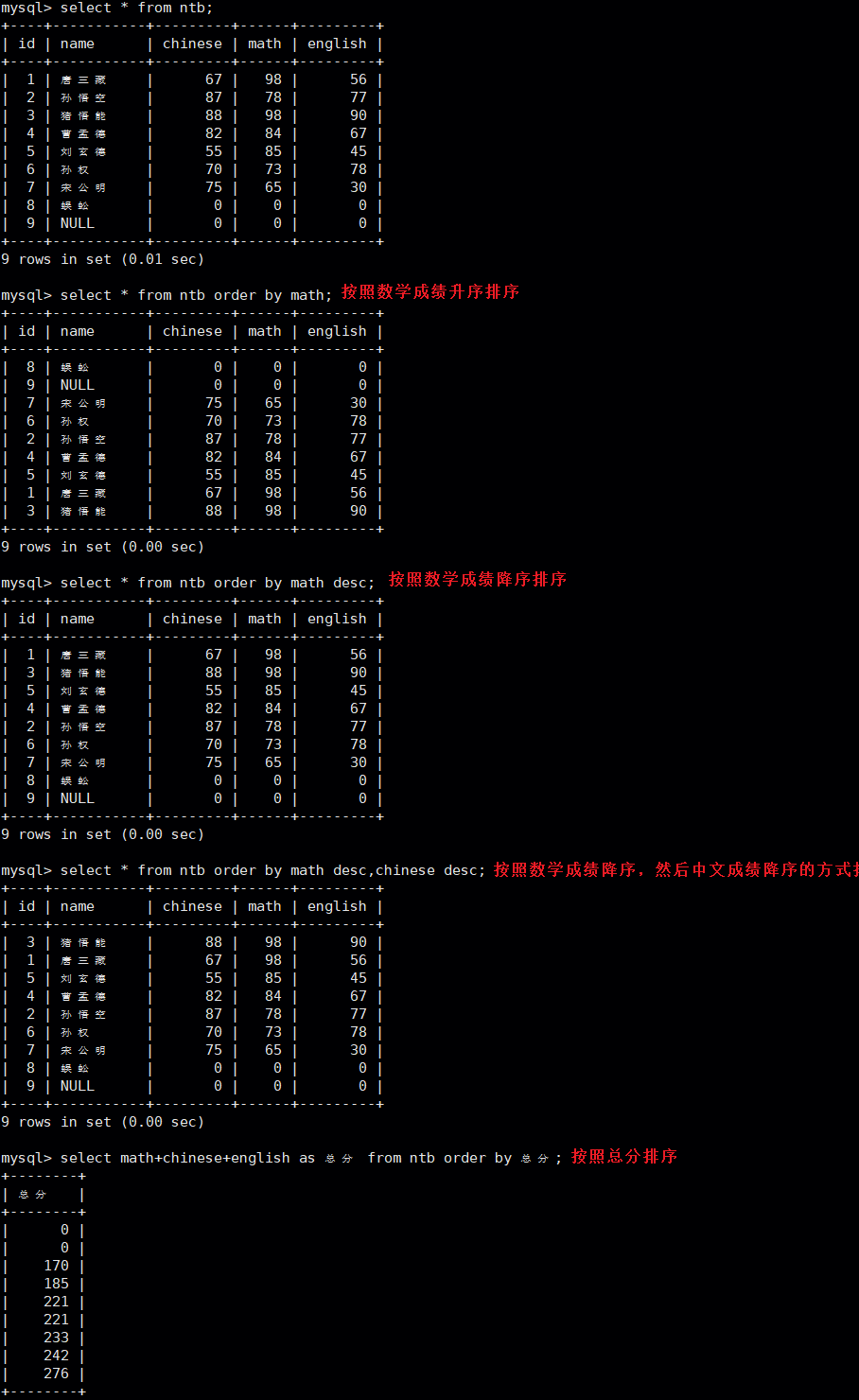

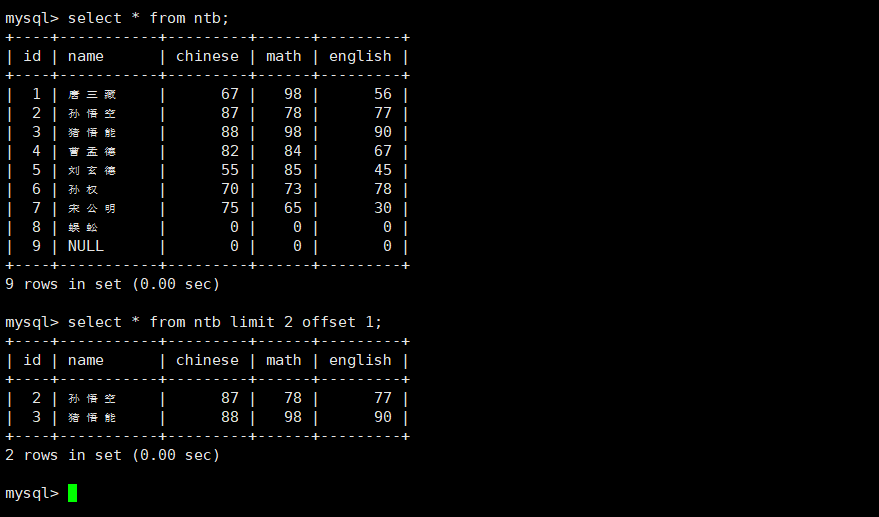
分页查询
相关命令:
sql
#显示从距离表头若干偏移量的位置开始的若干行
select ... from [表名] limit [要显示的行数] offset [偏移量];实操:
分组查询
相关命令:
sql
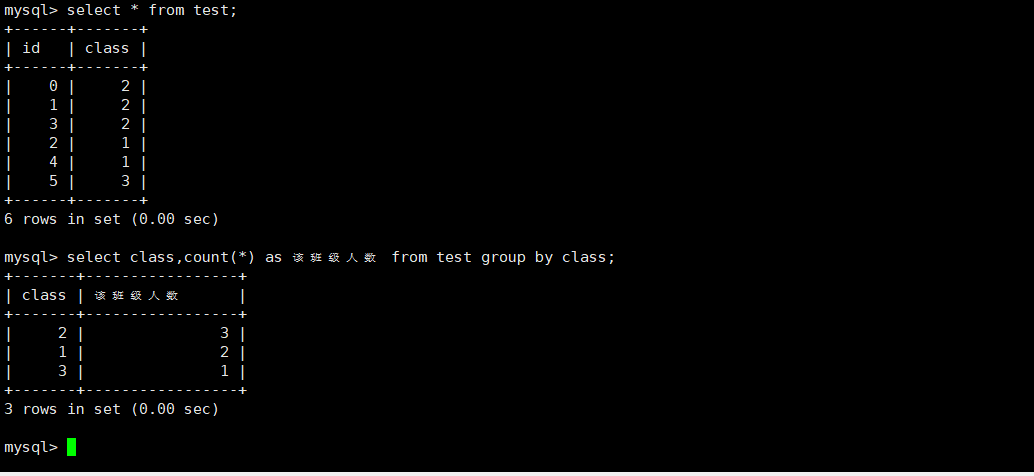
#首先是把表根据字段分成若干组,可以显示这个组的聚合结果,以及这个组的共有的用于分组的字段,其他字#段不能显示,因为组内的各个行的其他字段不一定都一样,该显示谁就会产生歧义
select [只能显示用于分组的字段以及聚合函数] from [表名] group by [字段名,字段名... ...];
#常用聚合函数
COUNT([DISTINCT] expr) 返回查询到的数据的数量
SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义
#加distinct表示先去重再统计
#count(*)表示的是行数
#count(字段名)不会统计值为NULL的一行。实操:
注意:
以上的查询关键词比如:where,distinct,limit等都可以组合使用
修改
相关命令:
sql
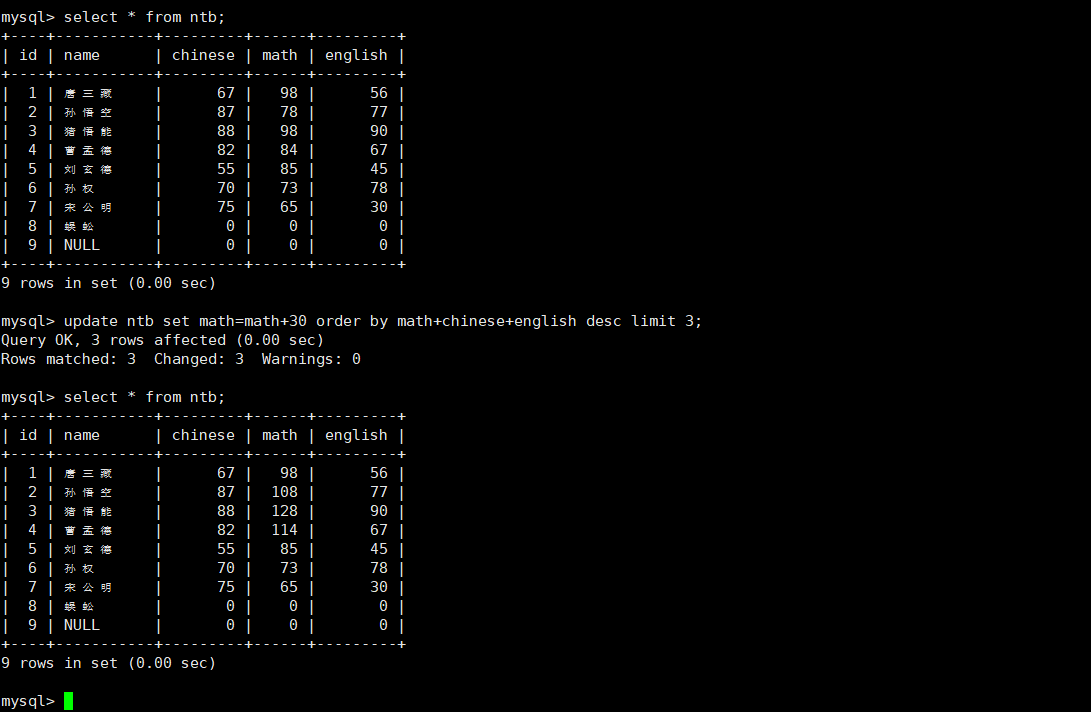
#对查询到的若干行数据更新他们的若干个字段的数据
UPDATE [表名] SET [字段名=值,字段名=值... ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]实操:
删除
相关命令:
sql
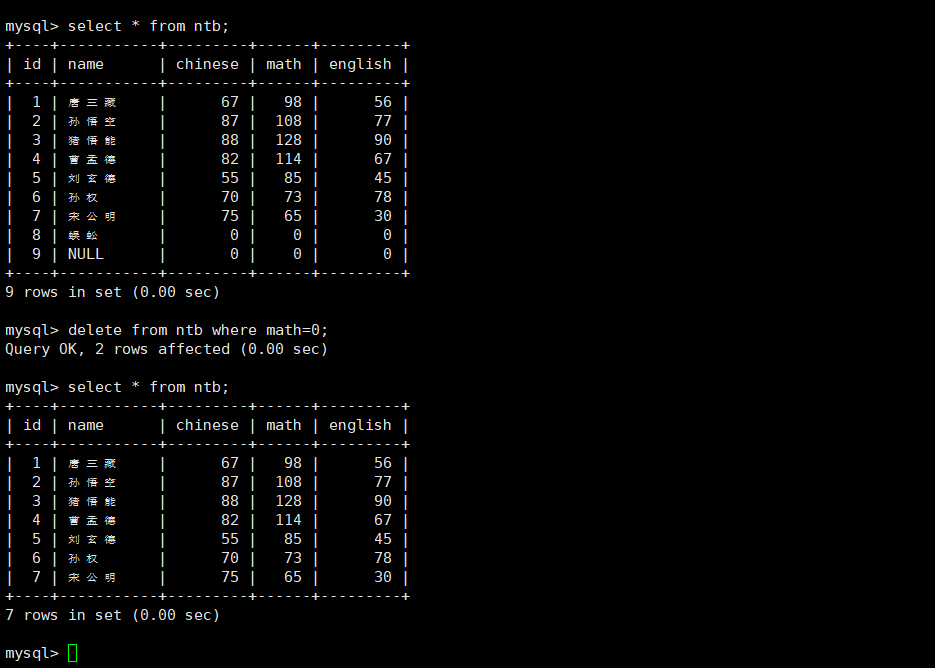
#删除筛选出来的若干行。如果没条件就是删除所有行,删除所有行后重新插入数据自增ID不会重置
delete from [表名] [where ...] [order by ...] [limit ...];
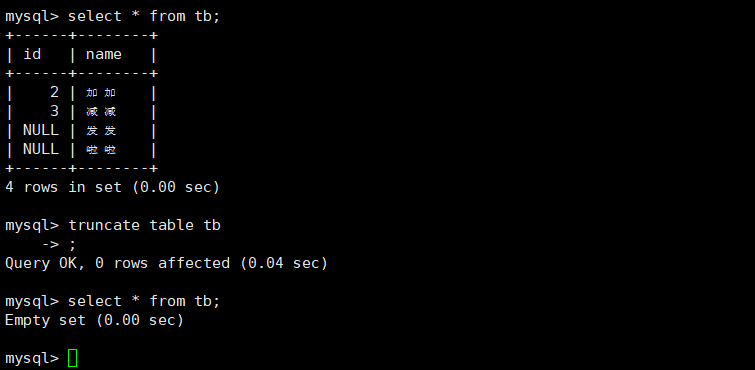
#清空表中的所有内容,重新插入数据自增ID会重置。该操作无法回滚!
truncate table [表名]实操:
复合查询
多表查询
相关命令:
sql
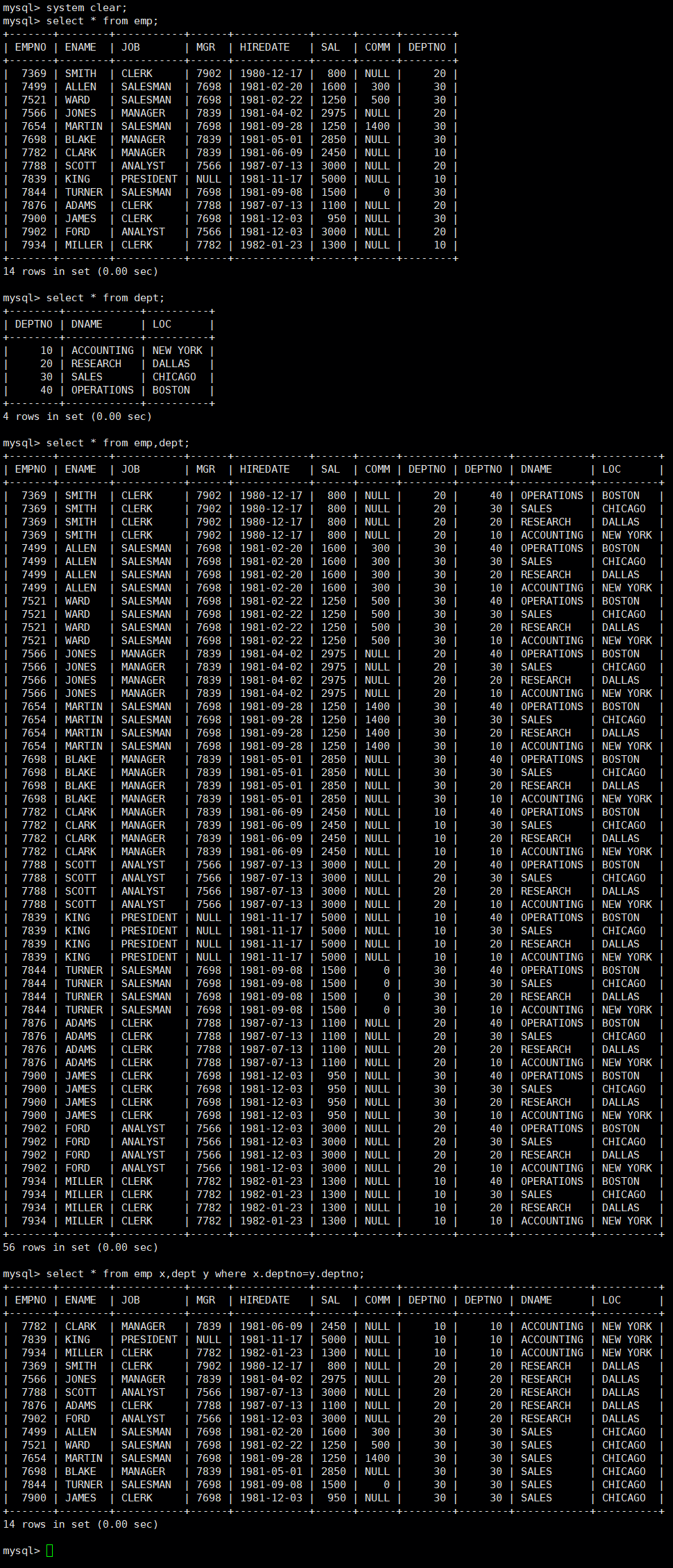
#将若干个表组合成一张新的表并进行查询,新表包含若干个旧表的所有字段
#组合方式是笛卡尔积。比如表A和表B进行组合,那么表A的第一项和表B中的所有项分别组合形成若干个新表项,表A的第二项和表B中的所有项分别组合形成若干个新表项... ...
#如果两个表有冲突的字段名,用 表名.字段名 加以区分
#表的别名可以不写
select ... from [表名1 表的别名,表名2 表的别名... ...] ...实操:
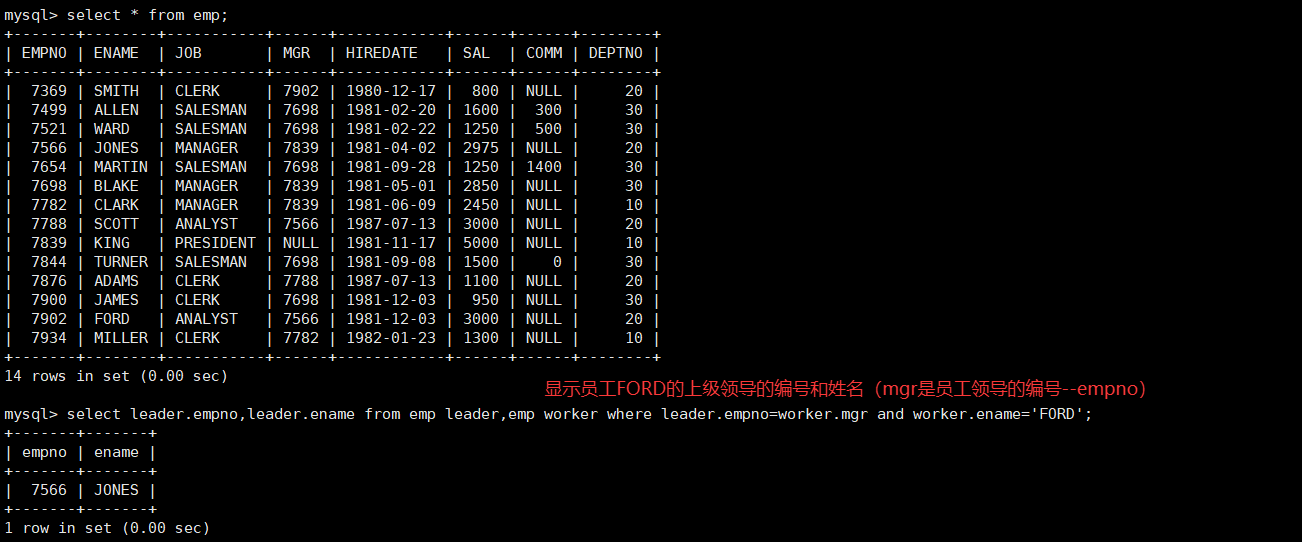
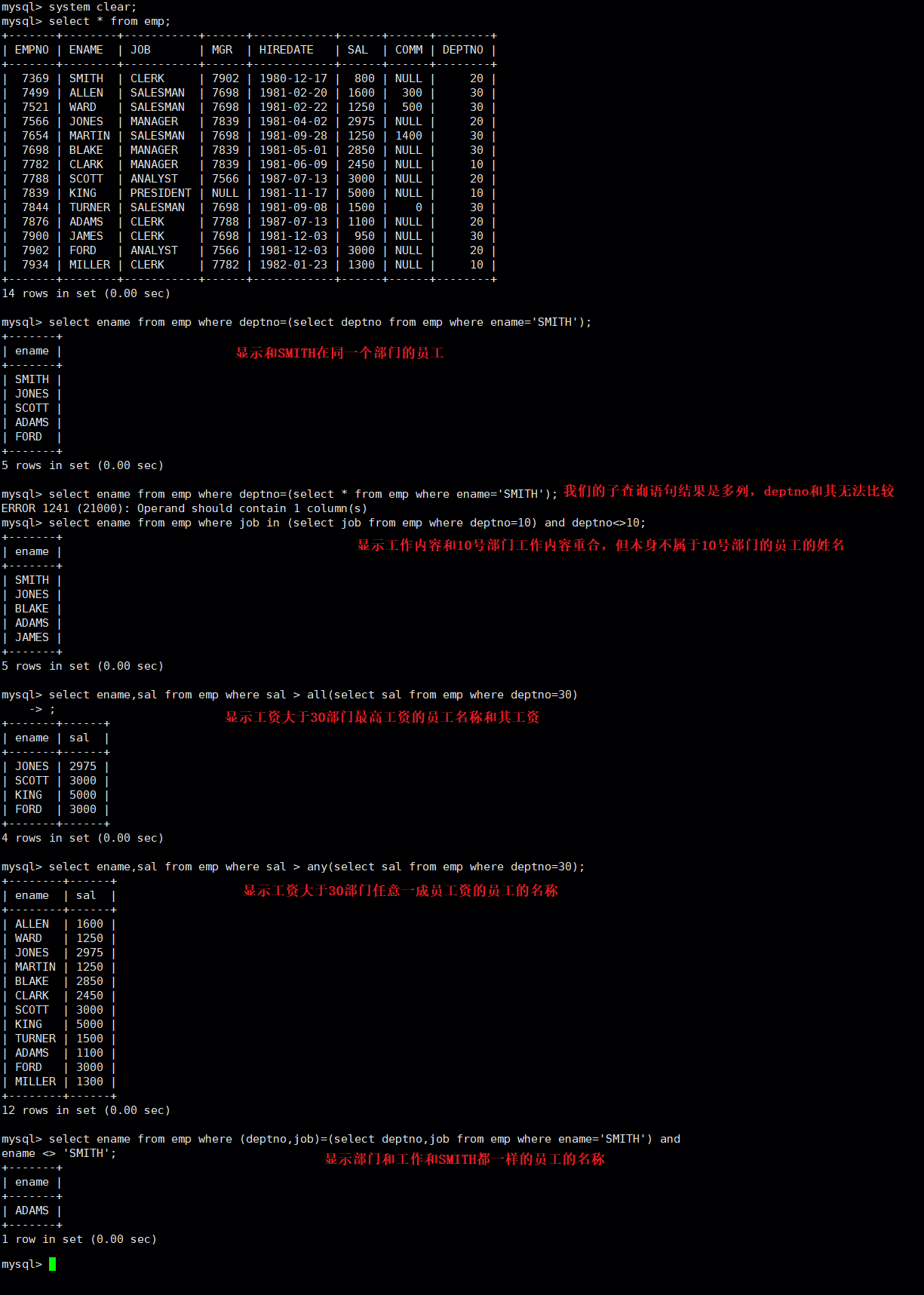
子查询
相关命令:
sql
#子查询就是在查询语句中嵌套查询语句,直接例子说明实操:

合并查询
相关命令:
sql
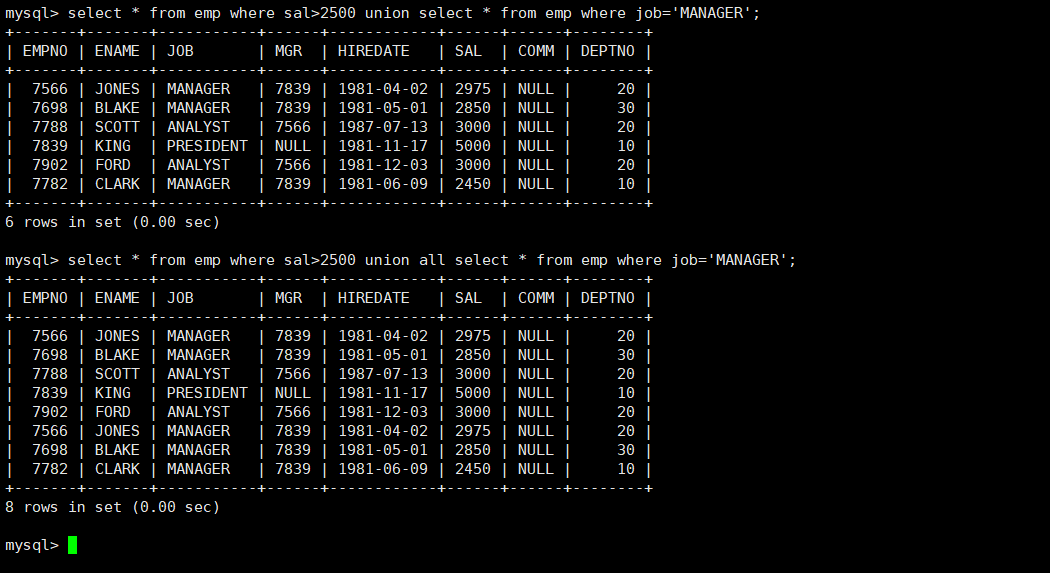
#将两张表的内容合并到一起,并去除重复内容
查询语句 union 查询语句
#将两张表的内容合并到一起,不去除重复内容
查询语句 union all 查询语句实操:
内外连接
在 MySQL 中,内连接 和外连接 的核心区别在于:多个表连接后如何处理不满足连接条件的行。
-
内连接 :只返回两个表中完全匹配的行,不匹配的会被丢弃。
-
外连接 :会保留一个或两个表的所有行 ,即使没有匹配,也会用
NULL填充缺失的部分。
内连接
相关命令:
sql
#这个其实就是多表查询的平替,将多个表连接
select 字段 from 表1 inner join 表2 on 连接条件 inner join 表3 on 连接条件;实操:
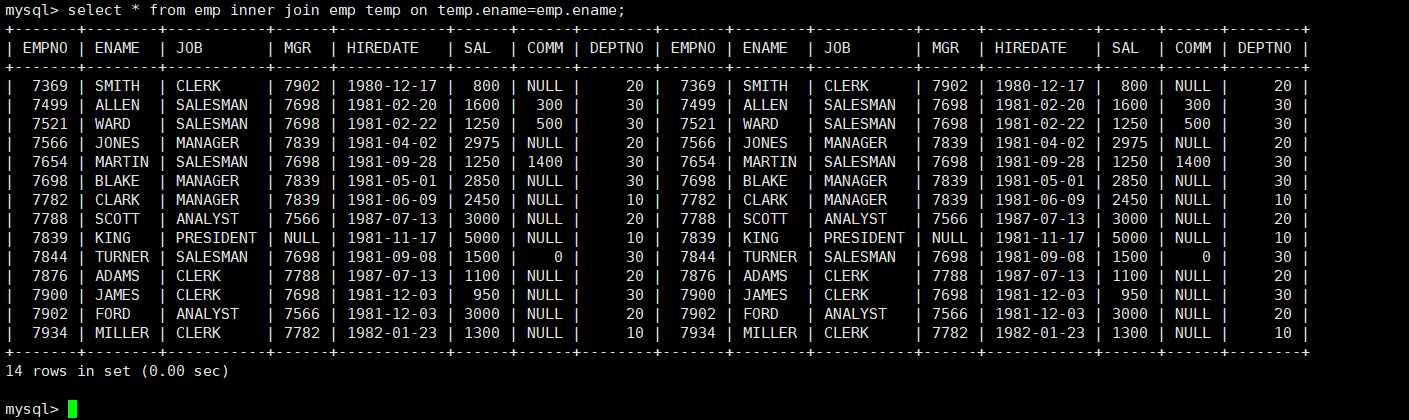
外连接
相关命令:
sql
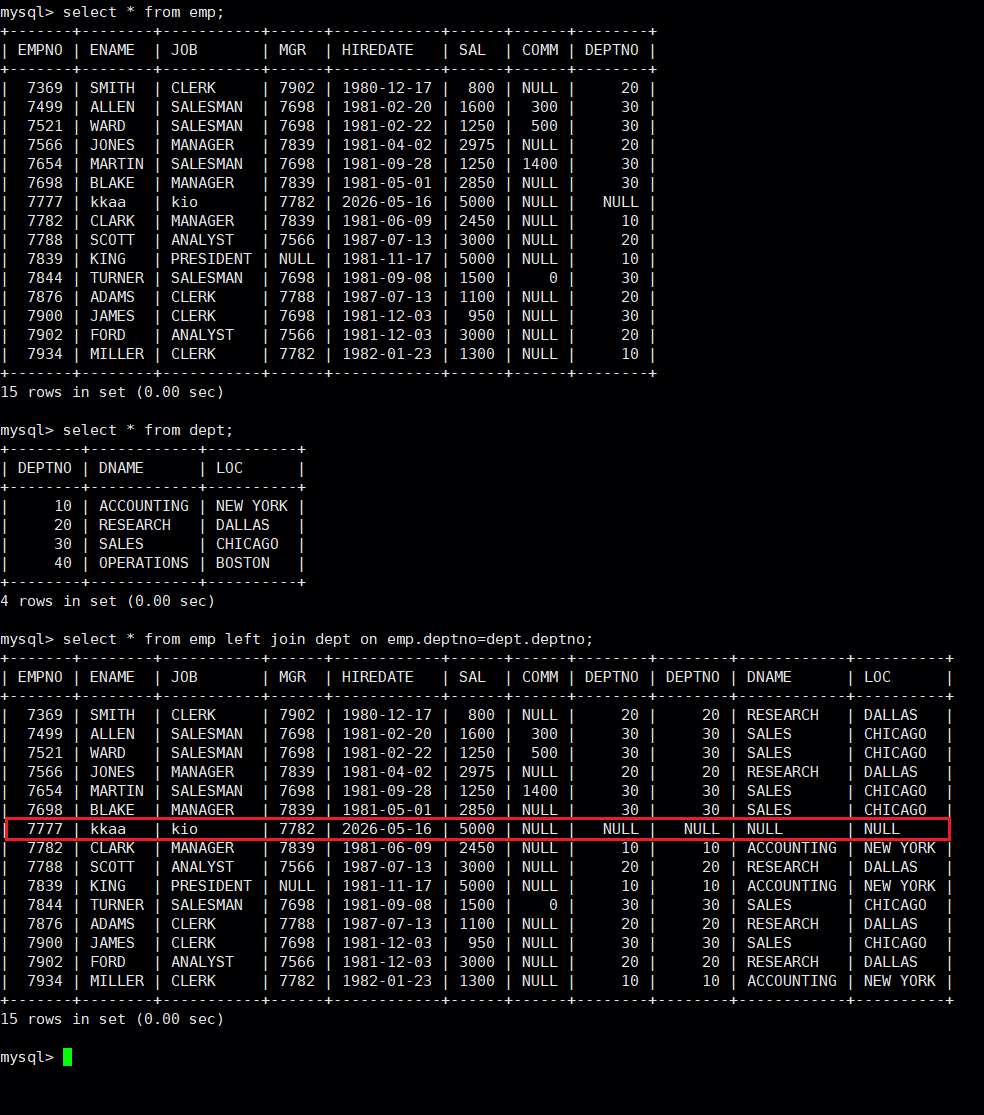
#如果两行不匹配,属于左边的表的那一行总是被保留,多余的属于右边的表的字段被置NULL
select 字段名 from 表名1 left join 表名2 on 连接条件
#如果两行不匹配,属于右边的表的那一行总是被保留,多余的属于左边的表的字段被置NULL
select 字段名 from 表名1 right join 表名2 on 连接条件实操:
查询的关键字执行优先级
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select> distinct > order by > limit
其中,having和where作用一样,但是他两优先级不一样having用于分组后的查询,where用于分组前的筛选。having关键字永远在group by后面,where关键字永远在group by前面