一、RAG 检索增强生成
二、工具调用FunctionCalling与ReAct
ReAct 循环(思考-行动-观察)
- 思考: 大模型思考需要调用什么工具
- 行动: agent调用工具api
- 观察: 大模型观察工具结果能否直接得出结论,或是继续返回FunctionCalling工具调用
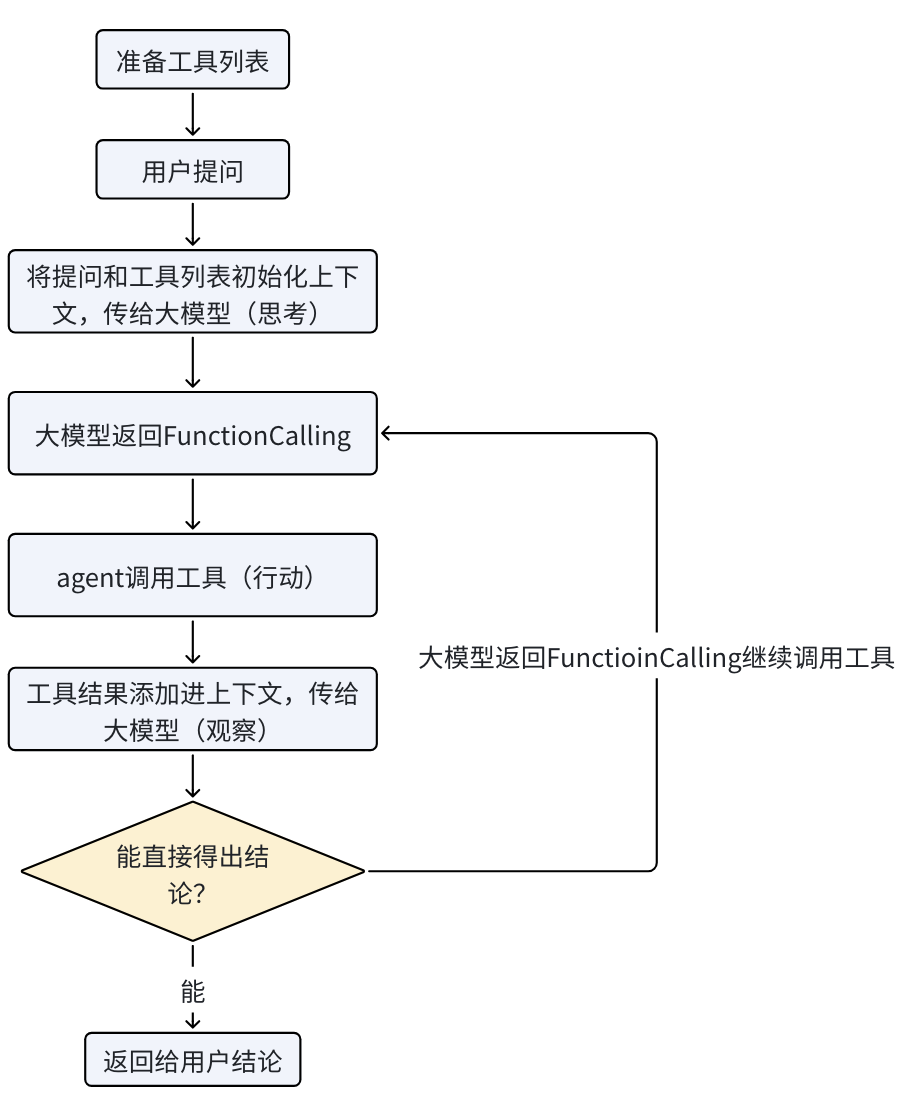
FunctionCalling具体流程
- 准备阶段:定义任务系统提示词,和工具列表,并给出大模型需要返回的经典范例
- 定义任务上下文:你是一个智能助理的路由模块,你的任务是根据用户的请求,从下面的工具列表中选择最合适的工具来解决问题,并给出出入参数
- 用户提问添加上下文
- 返回函数名,参数等json
- agent参数校验大模型返回是否符合json规范,不符合则将json反序列化异常追加上下文,重试大模型返回
MCP协议工具解耦
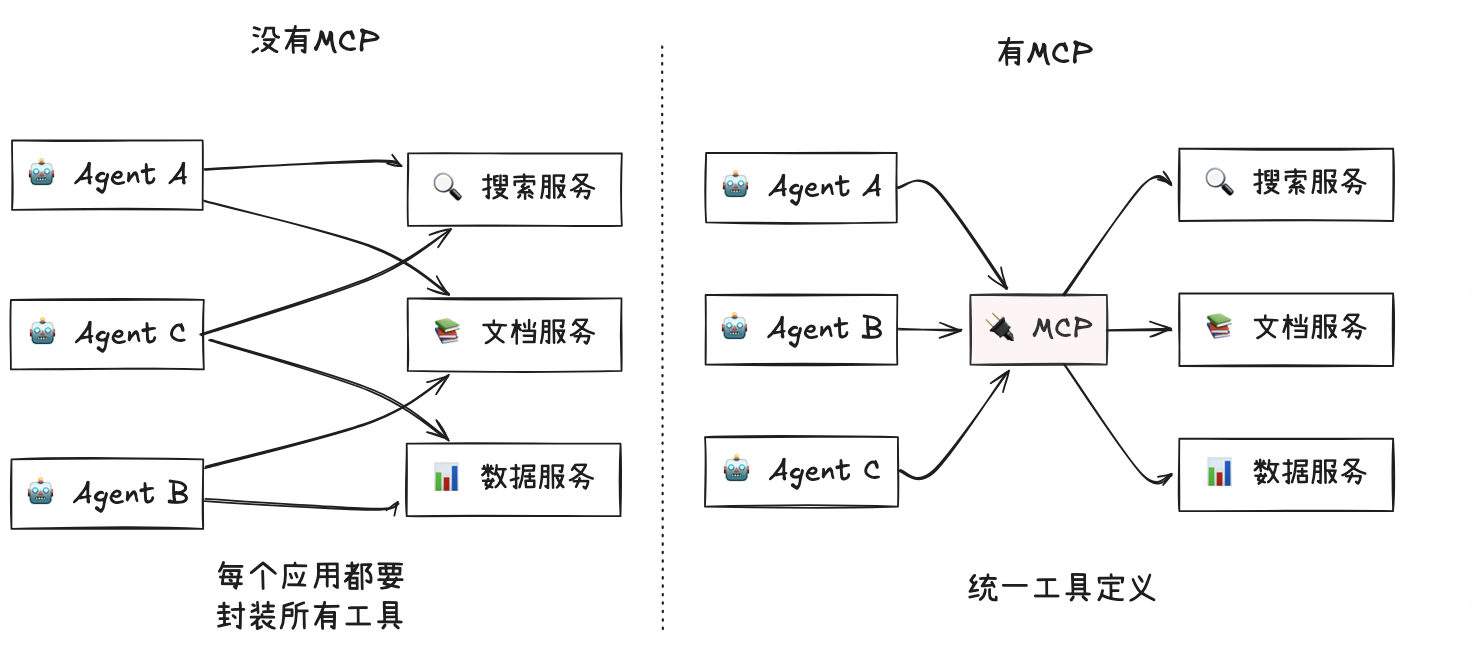
- 主要将工具集和agent解耦,避免在agent强耦合定义工具的schema Json,做到工具的注册与发现
- agent启动,MCP-Client向MCP-Server拉取工具列表
三、agent规划与执行
大模型幻觉 :如果大模型缺乏相关知识训练,会返回错误答案,每次调用大模型修正,都会引入新的问题
大模型反思: 让大模型返回输出前自己检查一遍
自我反馈:
- 单步指令式反思: 反思和生成绑定在一起,调用大模型时,设置合理的提示词,让大模型反思,优点减少大模型来回调用开销,缺点大模型容易自我错误验证反思发现不了问题

- 两步式生成反馈
一个agent负责生成回答,专门的agent负责进行验证反思
大模型处理复杂任务流程就像让一个实习生同时接四个电话------总有一个会出问题。这是因为大语言模型在生成回复时,对不同位置信息的"注意力"是不均等的。流程越往后,注意力权重会被稀释容易出错。
可以将复杂任务拆解 让不同的agent各自负责一部分
固定工作流和自主规划
四、多智能体协作
分层规划模式: LeaderAgent负责接受用户任务,并进行拆解分配给各个MemberAgent,接收各个成员返回,整合统一返回
共创协作模式: 去中心化,多个智能体用共享空间一起头脑风暴,专门一个秘书agent作为共享空间观察者记录会议纪要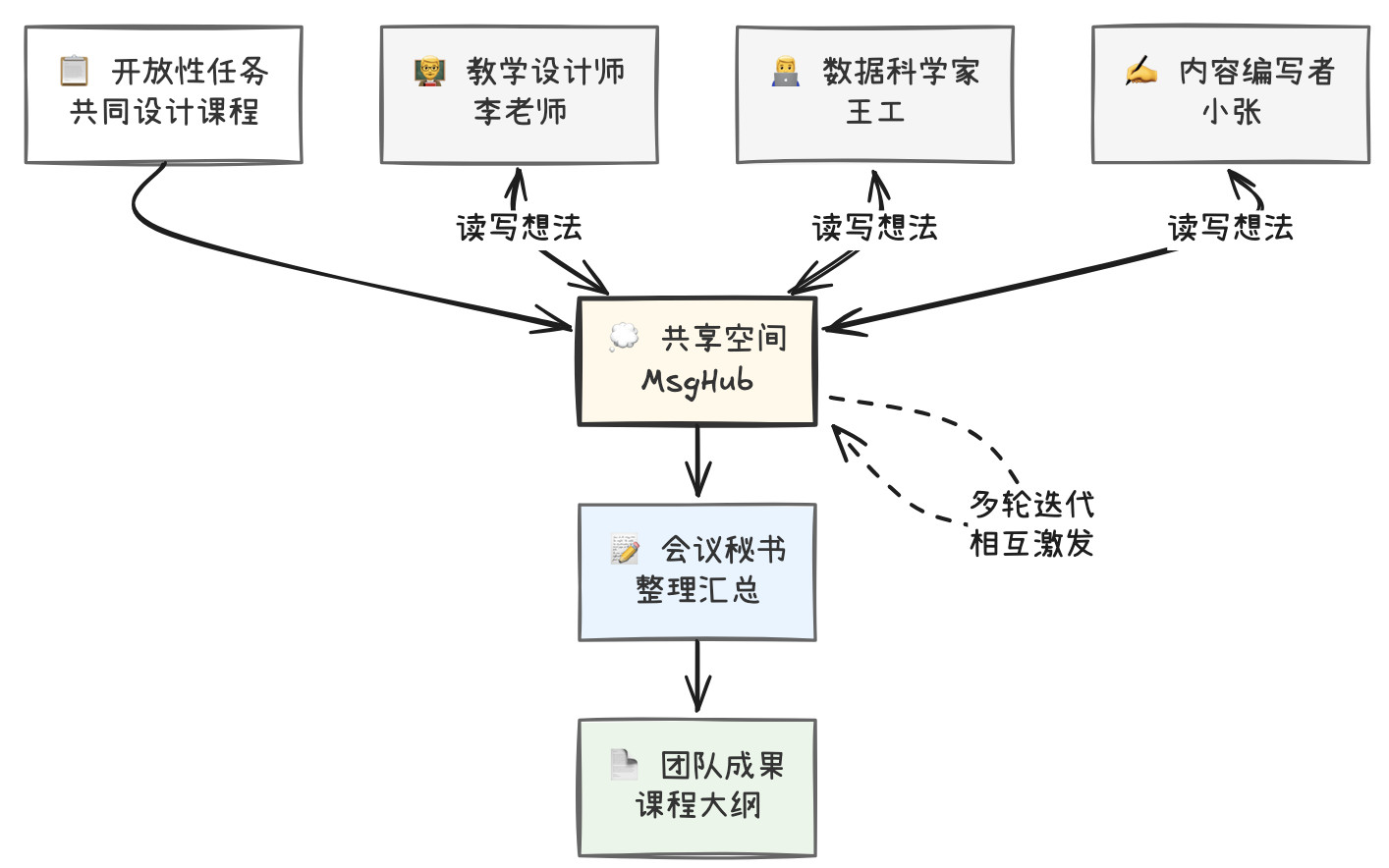
五、Agent记忆
- 建立短期记忆: 对话上下文管理与Token限制应对
三种记忆管理策略: - 上下文截断: 设定一个固定的窗口大小,比如只保留最近的 N 轮对话
- 滚动摘要: 每次窗口快满时,调用大模型将窗口上下文进行压缩精简成摘要
- 向量化召回(rag召回): 每次对话结束后,将内容embeddingh计算向量,对话内容存入向量数据,每次提出问题先检索获取上下文
- 从被动上下文到主动记忆管理: Agent自主决定何时记、何时读
- 短期与长期记忆的混合系统
六、SKILL技能--提示词复用
将prompt固化为skill,避免每次需要输入很多详细的提示词
SKILL分为以下几个部分
skill.md 文件分为YAML frontmatter(name、description)和markdownBody。以及其他的模块md文件按需加载
如何写出高质量SKILL--五步法
- 判断值不值得写SKILL: 必须使用频率高,够复杂
- 提取该写什么: 提取专家的决策树而非单纯的步骤------"在什么条件下选择方案A,什么条件下选择方案B"。注入反模式检查------"哪些坑绝对不能踩"。 标准化输出格式,并给出示例
- 写好指令: ,精简准确,渐进式披露,主文件保持精简,详情按需加载
- 配工具: 脚本代码要ai友好,例如架构化json输出,错误信息包含修复线索,优雅降级避免崩溃,支持幂等重试
- 验证迭代: 先没有skill完成任务,让agent自己总结一个skill,让另外一个agent使用skill,重复验证