文章目录
- 引言
- 设计说明
-
- [为什么需要 ImageModel 抽象?](#为什么需要 ImageModel 抽象?)
- 项目的实现策略
- 原理方案
-
- [Spring AI 的 Image 抽象](#Spring AI 的 Image 抽象)
- [DashScope 图像模型自动装配](#DashScope 图像模型自动装配)
- 源码解析
-
- [DrawImageController 完整实现](#DrawImageController 完整实现)
- 简化的请求/响应
- [与 ChatClient 的协作](#与 ChatClient 的协作)
- 验证结果
- 优化方向
- 小结
引言
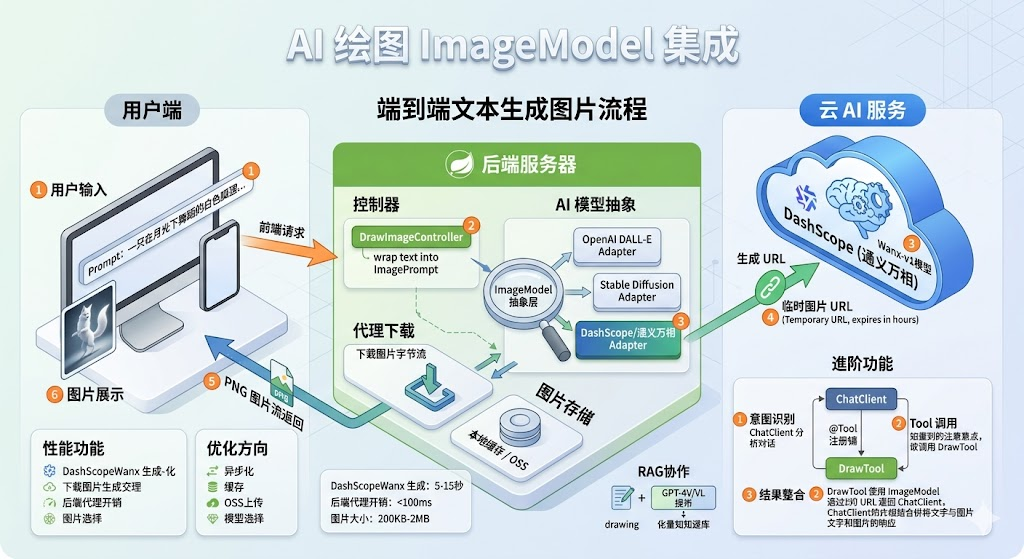
知识库系统的"主菜"是问答,但当用户想要"画一张架构图"或者"生成一个产品示意图"时,纯文本回复就显得力不从心。文生图(Text-to-Image)是大模型应用中的另一条主线,Spring AI 通过 ImageModel 抽象提供了对它的统一接入。
本篇将解析项目中的 AI 绘图实现:从 Prompt 到图片字节流的端到端流程。
设计说明
为什么需要 ImageModel 抽象?
各家厂商的图像生成 API 风格不一:
- OpenAI 的 DALL-E 返回 URL 或 base64
- Stable Diffusion 通常返回 base64
- 阿里通义万相返回临时 URL
- Midjourney 异步任务,需要轮询
直接对接每家 API 都要写一套适配代码。ImageModel 把这些差异抽象成统一接口:
java
ImageResponse imageModel.call(ImagePrompt prompt);不管底层是哪家服务,调用方代码完全一致。切换厂商只需要换一个 starter 依赖。
项目的实现策略
java
前端请求 GET /draw/image?prompt=xxx
↓
ImageModel.call(new ImagePrompt(prompt))
↓
DashScope API 调用(通义万相)
↓
返回图片 URL
↓
后端从 URL 下载图片字节
↓
作为 image/png 流式写回 response后端做了一层"代理下载",把临时 URL 转成直接的图片字节流。这样做的好处:
- 前端只看到一个稳定的接口,不用关心临时 URL 的过期问题
- 可以在中间做缓存、水印、压缩等处理
- 不暴露第三方 API 的细节
原理方案
Spring AI 的 Image 抽象
java
ImagePrompt // 包含 prompt 文本和参数
↓
ImageModel.call(prompt)
↓
ImageResponse // 包含若干 ImageGeneration
↓ getResult()
ImageGeneration // 单张图片的元数据
↓ getOutput()
Image // url 或 base64DashScope 图像模型自动装配
引入 spring-ai-alibaba-starter-dashscope 后,ImageModel Bean 会自动注入。配置项:
yaml
spring:
ai:
dashscope:
api-key: ${ALI_AI_KEY}
image:
options:
model: wanx-v1 # 通义万相模型
size: 1024*1024api-key 与对话模型共用同一个,无需额外申请。
源码解析
DrawImageController 完整实现
java
@RestController
@RequestMapping(ApplicationConstant.API_VERSION + "/draw")
public class DrawImageController {
private final ImageModel imageModel;
public DrawImageController(ImageModel imageModel) {
this.imageModel = imageModel;
}
@GetMapping("/image")
@Loggable
public void image(HttpServletResponse response, @RequestParam(value = "prompt") String prompt) {
// 1. 调用 ImageModel 生成图片
ImageResponse imageResponse = imageModel.call(new ImagePrompt(prompt));
String imageUrl = imageResponse.getResult().getOutput().getUrl();
try {
// 2. 从临时 URL 下载图片字节
URL url = URI.create(imageUrl).toURL();
InputStream in = url.openStream();
// 3. 设置响应头并写出字节
response.setHeader("Content-Type", MediaType.IMAGE_PNG_VALUE);
response.getOutputStream().write(in.readAllBytes());
response.getOutputStream().flush();
} catch (IOException e) {
response.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
}
}
}逐步解析:
- 构造函数注入 :
ImageModel由 Spring AI 自动装配,构造时直接拿到 new ImagePrompt(prompt):把用户的文本描述包装成 ImagePromptimageModel.call(...):同步调用 DashScope API,返回 ImageResponse- 取出 URL :通过
getResult().getOutput().getUrl()链式取值 - 下载字节:URL 是临时的(通常几小时过期),需要立即下载
- 写出响应 :设置
Content-Type为image/png,浏览器会直接渲染
简化的请求/响应
请求:
GET /api/v1/draw/image?prompt=一只在月光下舞蹈的白色狐狸,水彩画风格响应: 直接返回 PNG 图片(浏览器会渲染或下载)
与 ChatClient 的协作
如果想让 AI 自己决定何时画图,可以把 ImageModel 包装成 Tool:
java
@Service
public class DrawTool {
@Autowired
private ImageModel imageModel;
@Tool(description = "根据描述生成图片,返回图片 URL")
public String drawImage(@ToolParam(description = "图片描述") String prompt) {
ImageResponse resp = imageModel.call(new ImagePrompt(prompt));
return resp.getResult().getOutput().getUrl();
}
}注册到 ChatClient:
java
chatClient = ChatClient.builder(chatModel)
.defaultTools(drawTool)
.build();后续对话中,模型如果识别到"画一张..."类的意图,会自动调用 drawImage Tool 并把结果整合到回答中。
验证结果
直接访问浏览器
打开:
java
http://localhost:8989/api/v1/draw/image?prompt=雪山下的湖泊,写实风格浏览器会直接显示生成的图片。
前端集成
vue
<template>
<div>
<input v-model="prompt" placeholder="描述你想画的内容" />
<button @click="draw">生成</button>
<img v-if="imageSrc" :src="imageSrc" />
</div>
</template>
<script setup>
const prompt = ref('');
const imageSrc = ref('');
async function draw() {
const url = `/api/v1/draw/image?prompt=${encodeURIComponent(prompt.value)}`;
imageSrc.value = url; // 浏览器会自动加载
}
</script>性能观察
- DashScope 通义万相生成一张 1024×1024 的图片大约 5-15 秒
- 后端"下载-转发"的额外开销在 100ms 以内
- 图片大小通常 200KB ~ 2MB
优化方向
异步化
当前实现是同步的,前端要等待整个流程完成才能看到结果。可以改成"两步走":
接口 A:发起绘图任务
java
@PostMapping("/start")
public BaseResponse startDraw(@RequestParam String prompt) {
String taskId = UUID.randomUUID().toString();
CompletableFuture.runAsync(() -> {
ImageResponse resp = imageModel.call(new ImagePrompt(prompt));
redisTemplate.opsForValue().set("draw:" + taskId, resp.getResult().getOutput().getUrl(), 1, TimeUnit.HOURS);
});
return ResultUtils.success(taskId);
}接口 B:轮询结果
java
@GetMapping("/result/{taskId}")
public BaseResponse getResult(@PathVariable String taskId) {
String url = (String) redisTemplate.opsForValue().get("draw:" + taskId);
if (url == null) {
return ResultUtils.success(Map.of("status", "pending"));
}
return ResultUtils.success(Map.of("status", "done", "url", url));
}缓存
相同 prompt 大概率会得到相似结果。可以基于 prompt 的哈希做缓存:
java
String cacheKey = "draw:" + DigestUtils.md5DigestAsHex(prompt.getBytes());
String cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) {
return cached; // 直接返回缓存的图片 URL
}
// 调用 ImageModel ...
redisTemplate.opsForValue().set(cacheKey, imageUrl, 24, TimeUnit.HOURS);或者把图片本身存到 OSS 做长期缓存:
java
byte[] bytes = downloadImage(imageUrl);
String ossUrl = aliOssUtil.upload(bytes, UUID.randomUUID() + ".png");
return ossUrl;多模型选择
通过参数让用户选择模型:
java
@GetMapping("/image")
public void image(@RequestParam String prompt, @RequestParam(defaultValue = "wanx-v1") String model) {
ImageOptions options = DashScopeImageOptions.builder()
.withModel(model)
.withWidth(1024)
.withHeight(1024)
.build();
ImageResponse resp = imageModel.call(new ImagePrompt(prompt, options));
// ...
}不同模型适合不同场景:写实、漫画、3D 等。
安全过滤
文生图同样存在内容安全风险。可以复用敏感词过滤逻辑:
java
public void image(HttpServletResponse response, @RequestParam String prompt) {
if (sensitiveWordService.containsSensitiveWord(prompt)) {
response.setStatus(400);
return;
}
// ...
}或者使用阿里云的图片内容审核服务对生成结果做后审。
错误处理
当前实现的错误处理较为简单(response.setStatus(500)),可以丰富:
java
catch (IOException e) {
log.error("下载图片失败 url={}", imageUrl, e);
response.setStatus(500);
response.getWriter().write("图片下载失败,请重试");
}
catch (Exception e) {
log.error("AI 绘图失败 prompt={}", prompt, e);
response.setStatus(500);
response.getWriter().write("生成失败:" + e.getMessage());
}流式渲染(高级)
某些 SD 派生模型支持渐进式生成,可以用 SSE 推送中间状态:
java
@GetMapping(value = "/image/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> streamDraw(@RequestParam String prompt) {
// 推送进度:{"progress": 0.3} → {"progress": 0.6} → {"url": "xxx"}
}阿里通义万相目前不支持流式,但可以在客户端用 SSE 模拟"加载动画"。
将图片纳入 RAG 知识库
更进一步,可以让生成的图片成为知识库的一部分:
- 生成图片后存到 OSS
- 用多模态模型(GPT-4V、通义千问 VL)描述图片内容
- 把描述和图片 URL 一起向量化入库
- 后续对话检索时可以同时召回相关图片
这样就形成了"图文一体"的知识库。
小结
本篇展示了 Spring AI 文生图能力的最简集成方式:
ImageModel抽象屏蔽了不同厂商的差异- 后端"代理下载"模式让前端拿到稳定的图片流
- 简单几行代码就能让知识库系统具备绘图能力
进阶方向:异步化、缓存、模型选择、安全过滤、流式渲染、图文一体。
接下来的几篇博客将进入 v2.0 的进阶特性,从来源追溯开始,看看如何让 AI 的回答可信、可溯源。
