
1.1 背景知识
OLAP vs OLTP
数据库世界有两类典型负载:
- OLTP( 联机事务处理 ) :MySQL、PostgreSQL 的主战场。特点是高并发、点查、单行更新,例如"扣减一个库存"。
- OLAP(联机分析处理) :DuckDB、ClickHouse、Snowflake 的主战场。特点是宽表扫描、聚合、低并发,例如"统计过去 30 天每个品类的 GMV"。
OLTP 关心点 ,OLAP 关心面。两者在存储、执行、索引上的设计哲学完全不同。
行存 vs 列存
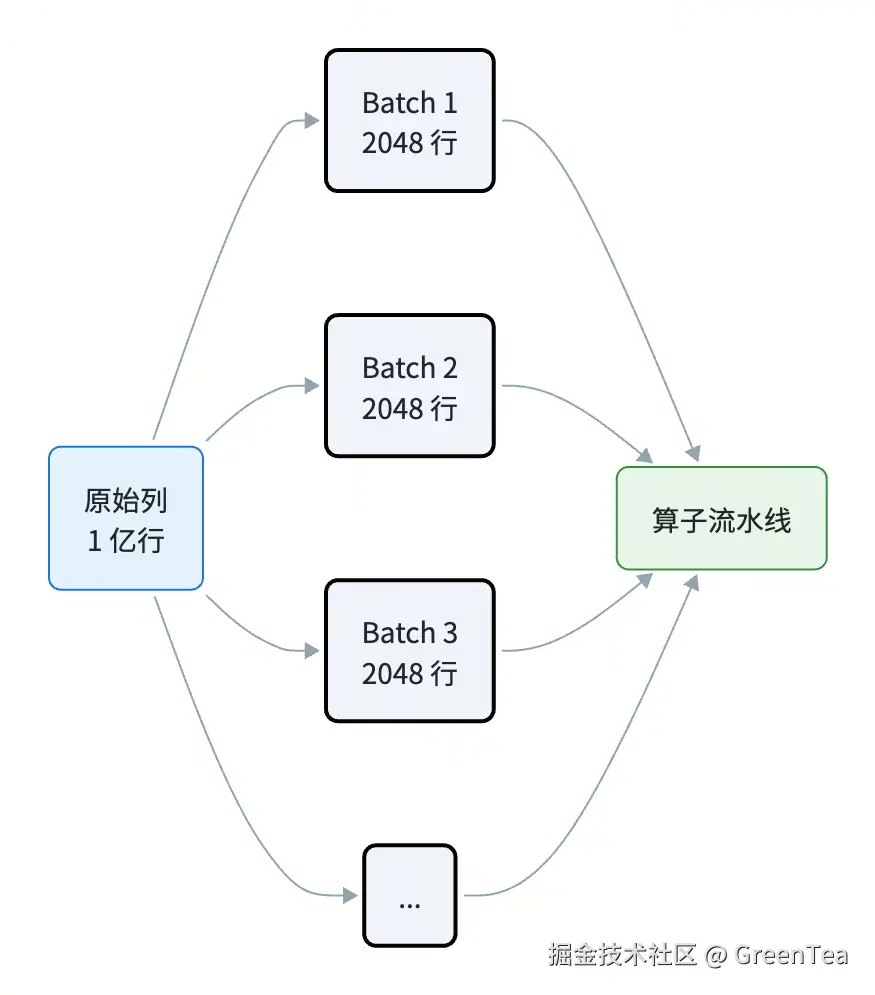
假设一张订单表 orders(id, user_id, amount, ts),有 1 亿行。
行存(按行排列)
(id1,user1,amt1,ts1), (id2,user2,amt2,ts2), ...
- 优点:读单条记录只需一次 IO
- 缺点:
SELECT SUM(amount)要把所有列都读进内存,IO 浪费严重 列存(按列排列)
[id1,id2,...], [user1,user2,...], [amt1,amt2,...], [ts1,ts2,...]
- 优点:只读需要的列;同列类型相同,压缩率极高;CPU cache 友好,便于 SIMD
- 缺点:单行写入/更新成本高
DuckDB、ClickHouse、Parquet 都选择列存------OLAP 场景下这是几乎唯一的正确答案。
Vector / Batch
完整列存还需要一个关键概念:Vector(DuckDB 术语,也叫 RecordBatch、Chunk)。
一次不处理一行,也不处理整列,而是处理"一段列"------例如固定 2048 行。这样既能享受列存的紧凑性,又不会一次性把 1 亿行装进内存。
1.2 设计思路
我们直接使用 arrow2 作为列存基础------这是 Rust 生态最成熟的 Apache Arrow 实现,DuckDB 的 Rust 绑定也兼容 Arrow 内存格式。
定义两个核心类型:
Column:一列数据,本质是Arc<dyn Array>(用Arc让列可低成本共享)Batch:一批列,即Chunk<Column>
1.3 代码实现
Cargo.toml 关键依赖:
toml
[package]
name = "miniduck"
edition = "2021"
[dependencies]
arrow2 = { version = "0.18", features = ["compute"] }
hashbrown = "0.14"
ahash = "0.8"
sqlparser = "0.45"src/storage.rs:
rs
use std::sync::Arc;
use arrow2::array::{Array, Float64Array, Int64Array, Utf8Array};
use arrow2::chunk::Chunk;
/// 用 Arc<dyn Array> 让列零拷贝共享
pub type Column = Arc<dyn Array>;
pub type Batch = Chunk<Column>;
#[derive(Clone)]
pub struct Table {
pub name: String,
pub schema: Vec<String>, // 列名列表
pub batch: Batch, // 教学版:单 batch
}
impl Table {
pub fn from_columns(name: &str, cols: Vec<(&str, Column)>) -> Self {
let schema = cols.iter().map(|(n, _)| n.to_string()).collect();
let arrays: Vec<Column> = cols.into_iter().map(|(_, c)| c).collect();
Table { name: name.to_string(), schema, batch: Chunk::new(arrays) }
}
pub fn col_index(&self, name: &str) -> Option<usize> {
self.schema.iter().position(|n| n == name)
}
pub fn num_rows(&self) -> usize { self.batch.len() }
}
// 便捷构造器
pub fn col_i64(v: &[i64]) -> Column { Arc::new(Int64Array::from_slice(v)) }
pub fn col_f64(v: &[f64]) -> Column { Arc::new(Float64Array::from_slice(v)) }
pub fn col_str(v: &[&str]) -> Column { Arc::new(Utf8Array::<i32>::from_slice(v)) }写一个最小 demo(examples/ch1_table.rs):
rs
use miniduck::storage::*;
fn main() {
let t = Table::from_columns("orders", vec![
("id", col_i64(&[1, 2, 3, 4])),
("city", col_str(&["BJ", "SH", "BJ", "SZ"])),
("amount", col_f64(&[10.0, 20.0, 15.0, 30.0])),
]);
println!("schema: {:?}", t.schema);
println!("rows: {}", t.num_rows());
}运行:cargo run --example ch1_table
1.4 自测题
- 一张 100 列的宽表,查询只用到 3 列。行存 vs 列存的 IO 量大致差几倍?为什么?
- 为什么列存压缩率天然高于行存?举两种典型的列式压缩算法。
- 为什么 DuckDB 选择 2048 作为默认 vector size,而不是直接 1 行或者整列?提示:从 L1/L2 cache 大小思考。
- Arrow 的
Array用Box<dyn Array>装箱,会不会有虚函数开销?这开销在 OLAP 场景里是否重要?
1.5 拓展学习
- 论文:MonetDB/X100: Hyper-Pipelining Query Execution(2005,向量化执行的开山之作)
- Apache Arrow 内存格式规范
- 动手:用
arrow2::io::parquet把Table写成 parquet 再读回来,观察文件大小