
1.1 背景知识
GROUP BY 是 OLAP 最高频的算子,没有之一。
实现方式主要两种:
Sort-based aggregation
先按 key 排序,再相邻合并。Spark SQL 默认。
Hash-based aggregation
用哈希表按 key 聚合。DuckDB、ClickHouse 默认。
内存够用时,hash-agg 几乎永远胜出------单 pass、O(N)、cache 友好。
哈希表的工程考量
- 哈希函数 :OLAP 不需要密码学强度,要的是 快 。
ahash、xxhash、wyhash是常见选择。Rust 标准库的SipHasher抗 HashDoS 但慢 3~5 倍 - 冲突解决 :开放寻址(linear probing)比拉链法 cache 更友好。
hashbrown(即 std HashMap 的底层)就是开放寻址 - 聚合状态 :每个 group 维护一个 state(
SUM维护f64,AVG维护(sum, count),COUNT_DISTINCT维护HashSet) - 向量化 聚合:先批量算出每行的 hash,再批量 probe 哈希表,把"一行一探"摊销到一次循环
本章实现 hash-agg + SUM/COUNT/AVG,单 i64 列 group by。
1.2 设计思路
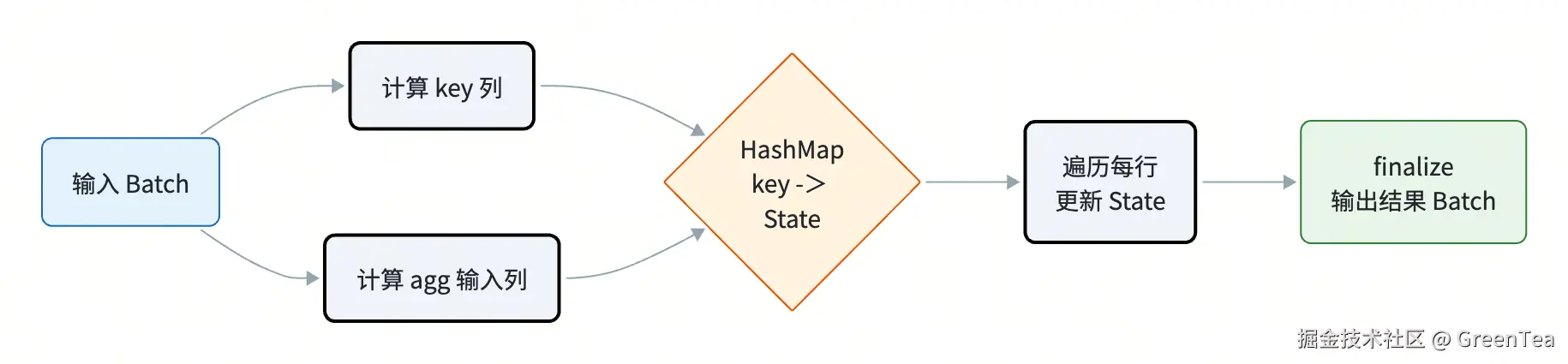
rust
HashAggregate {
keys: Expr, // 单 key 表达式(教学版)
aggs: Vec<AggExpr>, // 聚合函数列表
state: HashMap<i64, Vec<State>>,
}为了简洁,本章只支持单 key 且为 i64。多 key 的通用做法是把所有 key 列序列化成 Vec<u8> 当哈希键,DuckDB 用了一个叫 "row layout" 的紧凑布局。
1.3 代码实现
src/agg.rs(核心片段):
rust
use hashbrown::HashMap;
use ahash::RandomState;
#[derive(Clone, Debug)]
pub enum AggFunc { Sum, Count, Avg }
#[derive(Clone, Debug)]
pub struct AggExpr { pub func: AggFunc, pub input: Expr }
#[derive(Default, Clone, Copy)]
struct State { sum: f64, count: u64 }
pub struct HashAggregate {
child: BoxedOp,
key: Expr,
aggs: Vec<AggExpr>,
table: HashMap<i64, Vec<State>, RandomState>,
done: bool,
}
impl HashAggregate {
fn ingest(&mut self, batch: Batch) {
let key_col = self.key.eval(&batch);
let key_arr = key_col.as_any().downcast_ref::<Int64Array>().unwrap();
let agg_cols: Vec<Column> =
self.aggs.iter().map(|a| a.input.eval(&batch)).collect();
for row in 0..batch.len() {
let k = key_arr.value(row);
let entry = self.table.entry(k)
.or_insert_with(|| vec![State::default(); self.aggs.len()]);
for (i, agg) in self.aggs.iter().enumerate() {
let v = downcast_f64(&agg_cols[i]).value(row);
let s = &mut entry[i];
match agg.func {
AggFunc::Count => { s.count += 1; }
AggFunc::Sum => { s.sum += v; s.count += 1; }
AggFunc::Avg => { s.sum += v; s.count += 1; }
}
}
}
}
// finalize() 把哈希表变回一个 Batch(key 列 + 各聚合列)
}
impl Operator for HashAggregate {
fn next_batch(&mut self) -> Option<Batch> {
if self.done { return None; }
// 阻塞型算子:先把上游全部消费完
while let Some(b) = self.child.next_batch() { self.ingest(b); }
self.done = true;
Some(self.finalize())
}
}测试:
rust
let scan = Scan::new(&t);
let mut agg = HashAggregate::new(
Box::new(scan), Expr::Col(0),
vec![
AggExpr { func: AggFunc::Sum, input: Expr::Col(1) },
AggExpr { func: AggFunc::Count, input: Expr::Col(1) },
],
);
println!("{:?}", agg.next_batch());
// city_id | sum | count
// 1 | 90 | 3
// 2 | 60 | 2
// 3 | 60 | 11.4 自测题
- 哈希聚合是阻塞型算子(必须读完所有上游才能出结果),这对 streaming pipeline 意味着什么?什么场景下需要 partial agg + final agg 两阶段?
- 为什么 OLAP 普遍用
ahash而不是SipHash?性能差多少?安全性损失什么? - 多 key GROUP BY(比如
GROUP BY city, category),如何把多列拼成一个哈希 key?要避免哪些坑(比如 endian、对齐)? - 当哈希表大小超过内存怎么办?提示:spill to disk + external aggregation。
1.5 拓展学习
- DuckDB 论文:Data Management for Data Science 中关于 grouping 的 vectorized hash table 设计
- 阅读 hashbrown::raw::RawTable 源码,理解开放寻址的工程细节
- 动手:实现
COUNT(DISTINCT x),对比"精确 HashSet"与"HyperLogLog 近似"的性能/精度