
1.1 背景知识
到目前为止我们手写算子树,用户体验糟糕。一个真正的数据库需要让用户写 SQL。完整管道是:
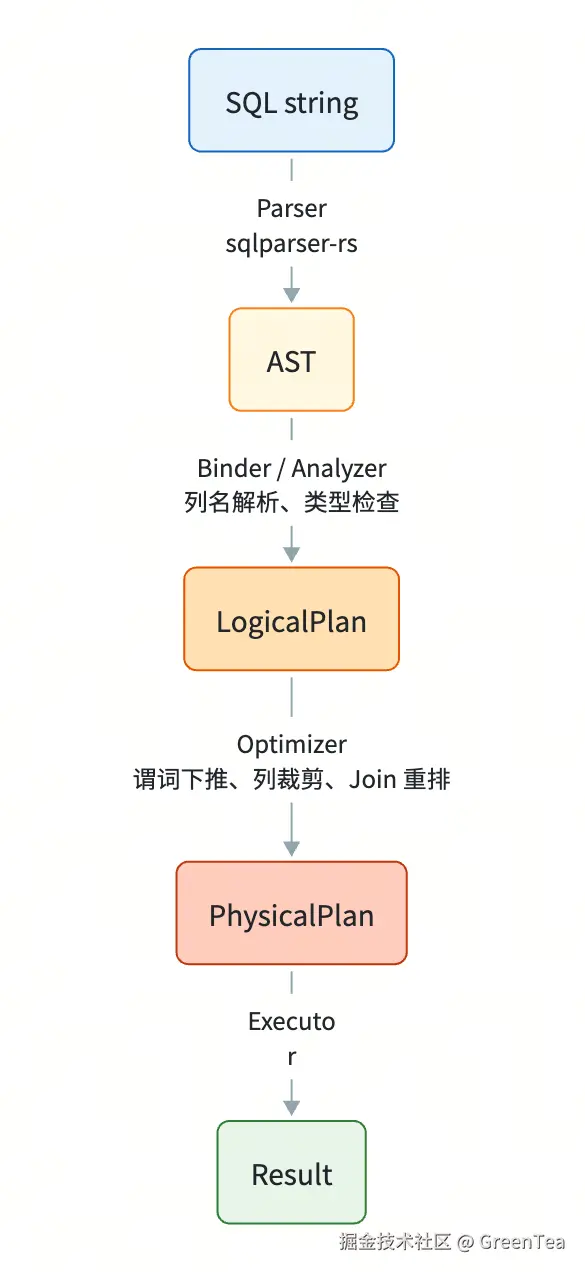
DuckDB、DataFusion、Spark 都是这个套路,差别仅在于优化器的复杂程度和物理算子的丰富度。
本章只做最小闭环:
- 用
sqlparser-rs直接解析 SQL - 实现一个超简化的 Planner:AST 直转算子树(跳过逻辑计划层和优化器)
- 真正的优化器在第 6 章简单介绍
1.2 设计思路
支持的 SQL 子集:
sql
SELECT col1, col2, AGG(col3)
FROM table
[WHERE condition]
[GROUP BY col1]约束:
- 单表,无 JOIN
- 无 ORDER BY、LIMIT(留作练习)
- 列引用按名字解析
- 表名 →
Table通过简单的Catalog哈希表映射
1.3 代码实现
src/catalog.rs:
rust
use std::collections::HashMap;
use crate::storage::Table;
#[derive(Default)]
pub struct Catalog { tables: HashMap<String, Table> }
impl Catalog {
pub fn register(&mut self, t: Table) { self.tables.insert(t.name.clone(), t); }
pub fn get(&self, name: &str) -> Option<&Table> { self.tables.get(name) }
}src/planner.rs(核心,约 80 行,完整版见仓库):
rust
pub fn run_sql(sql: &str, catalog: &Catalog) -> Batch {
let ast = Parser::parse_sql(&GenericDialect{}, sql).unwrap();
let Statement::Query(q) = &ast[0] else { panic!("only SELECT") };
let SetExpr::Select(sel) = q.body.as_ref() else { panic!() };
// 1. FROM
let TableFactor::Table { name, .. } = &sel.from[0].relation else { panic!() };
let tname = name.0[0].value.clone();
let table = catalog.get(&tname).unwrap();
let resolve = |c: &str| table.col_index(c).unwrap();
let mut op: BoxedOp = Box::new(Scan::new(table));
// 2. WHERE
if let Some(w) = &sel.selection {
op = Box::new(FilterExpr::new(op, build_expr(w, &resolve)));
}
// 3. GROUP BY + AGG
if let GroupByExpr::Expressions(g, _) = &sel.group_by {
if !g.is_empty() {
let key = build_expr(&g[0], &resolve);
let aggs = collect_aggs(&sel.projection, &resolve);
op = Box::new(HashAggregate::new(op, key, aggs));
}
}
op.next_batch().unwrap()
}跑一段端到端 SQL:
rust
let mut cat = Catalog::default();
cat.register(Table::from_columns("orders", vec![
("city_id", col_i64(&[1,2,1,2,1,3,3,3])),
("amount", col_f64(&[10.,20.,30.,40.,50.,60.,70.,80.])),
]));
let result = run_sql(
"SELECT city_id, SUM(amount), COUNT(amount) \
FROM orders WHERE amount > 15 GROUP BY city_id",
&cat,
);
println!("{:?}", result);至此,MiniDuck 已经是一个可用的嵌入式 OLAP 引擎------能解析 SQL、构建算子树、向量化执行、输出列式结果。
1.4 自测题
- 为什么真实数据库要分"逻辑计划"和"物理计划"两层,而不是 AST 直转算子?
- 列裁剪(Column Pruning)应该在逻辑计划还是物理计划阶段做?为什么?
- 当前的
Table::clone性能糟糕,怎么改成零拷贝?提示:Arc<Table>(仓库已用 Arc 实现)。 - 如果要支持子查询(
SELECT ... FROM (SELECT ...)),Planner 需要怎么改?
1.5 拓展学习
- DataFusion 的 LogicalPlan 与 PhysicalPlan 模块
- 论文:Volcano---An Extensible and Parallel Query Evaluation System(Goetz Graefe, 1994)
- 动手:实现
ORDER BY+LIMIT,思考 TopN 算法(堆 vs 排序)