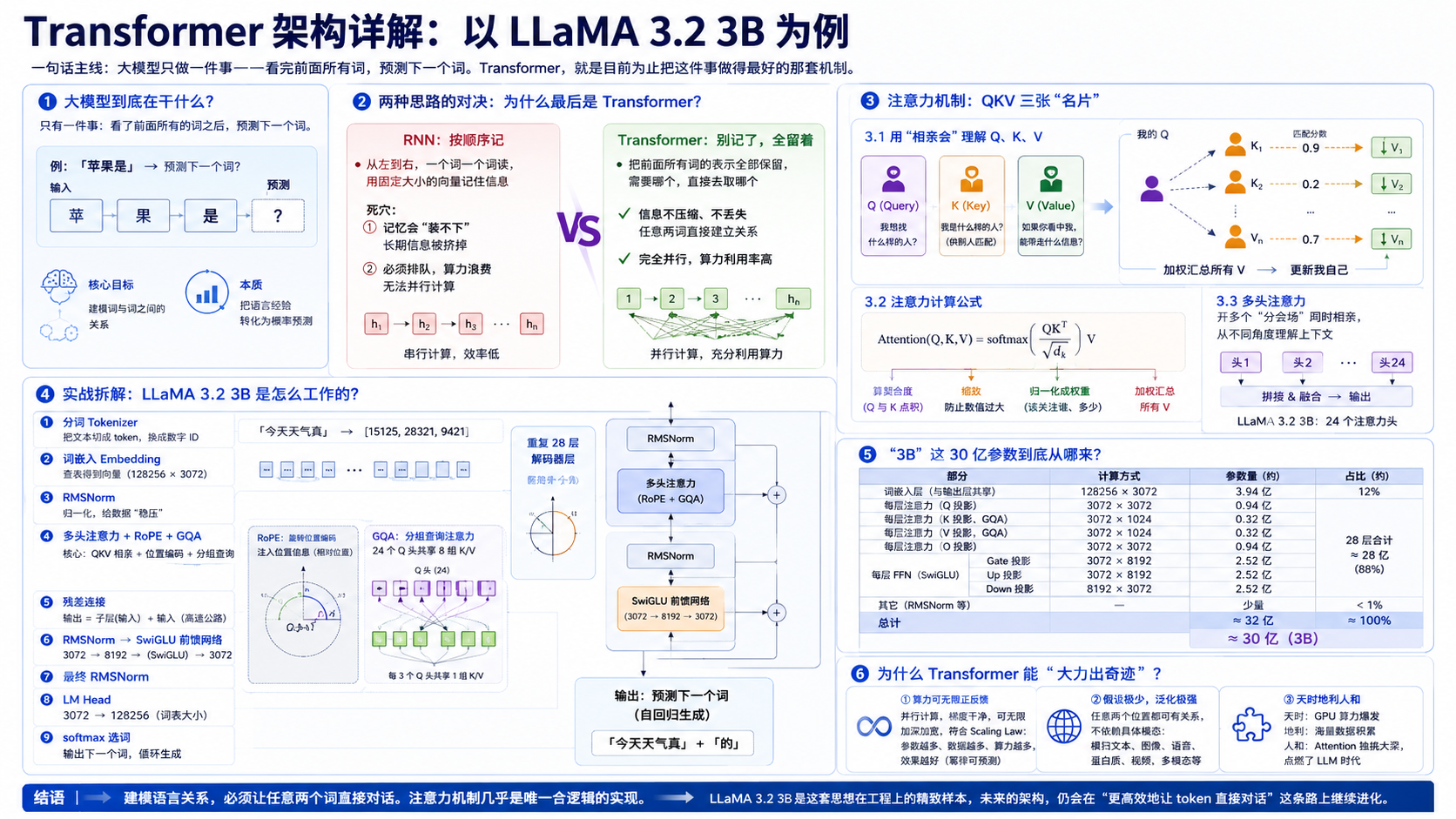
Transformer 架构详解
从第一性原理出发,拆解一个真实的小模型
------ 以 Meta LLaMA 3.2 3B 为例
一句话主线: 大模型只做一件事------看完前面所有词,预测下一个词。Transformer,就是目前为止把这件事做得最好的那套机制。
目录
- 第一章 先把问题剥到最里面:大模型到底在干什么
- [第二章 两种思路的对决:为什么最后是 Transformer](#第二章 两种思路的对决:为什么最后是 Transformer)
- [第三章 注意力机制:QKV 三张"名片"](#第三章 注意力机制:QKV 三张"名片")
- [第四章 实战拆解:LLaMA 3.2 3B 是怎么工作的](#第四章 实战拆解:LLaMA 3.2 3B 是怎么工作的)
- [第五章 "3B"这 30 亿参数到底从哪来](#第五章 "3B"这 30 亿参数到底从哪来)
- [第六章 为什么 Transformer 能"大力出奇迹"](#第六章 为什么 Transformer 能"大力出奇迹")
- 结语 一句话收束
第一章 先把问题剥到最里面:大模型到底在干什么 {#第一章}
在讲 Transformer 之前,我们先不谈任何技术。先问一个最根本的问题:一个大模型,本质上在干什么?
答案简单到让人意外------只有一件事:看了前面所有的词之后,预测下一个词。 就这一件事,不停地做,预测够了,就成了能跟你对话的 AI。GPT、Claude、DeepSeek、LLaMA,全是在做这一件事,没有例外。
举个例子。当你看到「苹果是」这三个字,作为一个会说中文的人,你大概率会接上「红的」「甜的」或者「一种水果」。你为什么能接上?因为你在过去几十年的语言经验里,掌握了词与词之间的"关系"------「苹果」后面常跟什么、什么样的搭配合理、什么样的搭配荒唐,你心里有数。
大模型的智能,本质上就是把这种"关系"学到了极致。所以整部 LLM 的技术史,其实就是人类在反复回答同一个问题:
核心问题
怎么用机器,把"词与词之间的关系"建模出来?
谁能把这个"关系"建模得又准、又快、又能无限做大,谁就赢。
记住这句话。下面要讲的 RNN、Transformer、注意力机制、QKV,全部都是在回答这一个问题的不同答案而已。理解了这一点,整个架构的来龙去脉就清晰了。
第二章 两种思路的对决:为什么最后是 Transformer {#第二章}
建模"词与词的关系",历史上主要有两种思路。我们一个一个看。
2.1 第一种答案:按顺序记(RNN 的思路)
最朴素的想法,就是模仿人读书:从左到右,一个词一个词地读,把读过的信息攒在脑子里,读下一个词的时候调用这份记忆。
这就是 RNN(循环神经网络)的核心思路。每读一个词,就把"当前的记忆"更新一次,像滚雪球一样往下传。听起来很合理,对吧?但它有两个结构性的死穴:
死穴一:记忆会"装不下"
RNN 要用一个固定大小的向量,去装下任意长度序列的全部信息。问题是:序列越长,早期的信息被挤掉得越多。读到第 500 个词时,第 1 个词说了什么,基本已经忘光了。
这不是调参能解决的,而是信息论的基本约束------用有限的容量去装无限的信息,必然有损失。
死穴二:必须排队,算力浪费
RNN 必须串行计算:第 3 步算完,才能算第 4 步。哪怕你有一万张 GPU,它也得乖乖排队,一个一个来。结果就是昂贵的并行算力被白白浪费。
2.2 第二种答案:别记了,全留着(Transformer 的思路)
Transformer 的作者做了一个听起来"很蠢"、但事后看来无比正确的决定:
Transformer 的关键一步
既然压缩信息会丢,那就干脆不压缩。
把前面所有词的表示全部保留下来,需要用哪个,就直接去取哪个。
这个"需要哪个取哪个"的机制,就是大名鼎鼎的注意力机制(Attention)。它一举解决了 RNN 的两个死穴:
- 信息不压缩、不丢失。 任意两个词之间的关系是直接建立的,不经过任何中间记忆节点。第 1 个词和第 500 个词,可以直接"对话"。
- 完全并行。 所有词同时计算,没有先后依赖。几千张 GPU 可以一起开工,算力第一次被真正"喂饱","大力出奇迹"才有了物理基础。
代价是计算量暴涨------每个词都要跟所有其他词算一遍相关性,复杂度是 O(n²)。但相比它换来的好处,这个代价是值得的。下一章,我们就来彻底搞懂这套"取信息"的机制到底怎么运作。
第三章 注意力机制:QKV 三张"名片" {#第三章}
这是整个 Transformer 最核心、也最容易被讲得云里雾里的部分。我们用一个生活化的比喻,把它一次讲透。
3.1 用"相亲会"理解 Q、K、V
想象一个相亲会现场。每个人(每个词)进场时,都会准备三张名片:
- Q(Query,查询): "我想找什么样的人?" ------ 这是我主动去问别人的需求。
- K(Key,关键字): "我是什么样的人?" ------ 这是我挂在胸前、供别人来匹配的标签。
- V(Value,价值): "如果你看中我,能从我这里带走什么信息?" ------ 这是我真正能提供的内容。
现在,相亲开始。轮到"我"这个词时,我拿着自己的 Q (我的需求),挨个去和全场每个人 的 K(他们的标签)做匹配,算出一个"契合度分数"。
- 和我的需求越契合的人,分数越高;
- 完全不搭的,分数很低。
然后我按照这个分数,去"加权"地收集每个人的 V (他们能提供的信息):契合度高的人,我多拿一点他的信息;契合度低的,少拿一点。最后把所有人的信息按比例混合起来,就得到了一个**"融合了全场信息"的全新的我**。
所以这时候可以这么理解了,后面一个人去相亲的时候就可以拿这个加权的分数来找新的对象,这样定位就更精准了,因为融合了不容的相亲对象提供的信息。
一句话总结 QKV
用我的 需求 Q 去匹配所有人的 标签 K ,
算出该关注谁、关注多少,再按这个权重把所有人的 内容 V 加权汇总,更新我自己。
回到语言上。「它」这个词的 Q,可能在问"我指代的是前面哪个名词?";而前文「那只猫」的 K 正好能高度匹配上,于是「它」就从「那只猫」的 V 里大量取信息,模型由此"知道"了------这里的「它」指的就是「那只猫」。这就是注意力机制能理解上下文的根本原理。
3.2 这三张名片是怎么来的?
关键点:Q、K、V 不是凭空捏造的,而是每个词的原始向量 (词嵌入,下一章讲)分别乘以三个可学习的权重矩阵 W_Q、W_K、W_V 得到的。
python
# 假设某个词的输入向量是 x(一行数字)
Q = x · W_Q # 生成"查询"名片
K = x · W_K # 生成"关键字"名片
V = x · W_V # 生成"价值"名片
# W_Q、W_K、W_V 就是训练中要学习的参数
# 模型"学会语言",本质就是学好这些矩阵里的数字所以"训练大模型"这件事,说白了就是:通过海量文本,不断调整 W_Q、W_K、W_V(以及后面会讲的其他矩阵)里的每一个数字,直到模型生成的 Q/K/V 能精准地捕捉词与词的真实关系。
3.3 完整的注意力计算公式
把上面的相亲过程写成数学公式,就是那个著名的 Attention 公式:
Q · Kᵀ
Attention(Q,K,V) = softmax( ────────── ) · V
√d_k逐项拆解(继续用相亲比喻):
| 公式部件 | 通俗含义 |
|---|---|
| Q · Kᵀ | 我的需求 Q 和每个人的标签 K 做点积,算出"原始契合度分数" |
| ÷ √d_k | 除以一个缩放系数,防止分数太大导致后面计算不稳定(数值技巧) |
| softmax(...) | 把一堆分数归一化成"加起来等于 1 的权重",即"该关注谁、占比多少" |
| ... · V | 用这组权重,对所有人的内容 V 做加权求和,得到融合后的新表示 |
其中 d_k 是 K 向量的维度。在 LLaMA 3.2 3B 里,这个值是 128,所以缩放系数是 √128 ≈ 11.3。这个细节下一章会对上号。
3.4 多头注意力:开多个"分会场"同时相亲
单一注意力还不够。Transformer 用了多头注意力(Multi-Head Attention):把相亲会拆成好几个"分会场",每个会场关注不同的维度。
- 有的"头"专门关注语法关系(主谓宾);
- 有的"头"专门关注指代关系("它"指代谁);
- 有的"头"专门关注语义搭配("苹果"配"吃"还是"买")。
每个头独立地做一遍 QKV 相亲,最后把所有头的结果拼接起来,再融合一次。这样模型就能同时从多个角度 理解同一句话------这正是"多头"的威力。LLaMA 3.2 3B 用了 24 个注意力头,相当于 24 个分会场并行运作。
本章小结
QKV = 需求、标签、内容三张名片;
注意力 = 用 Q 匹配所有 K 算权重,再用权重加权汇总所有 V;
多头 = 多个角度同时做注意力,最后拼起来。
这一整套,就是 Transformer 理解"词与词关系"的引擎。
第四章 实战拆解:LLaMA 3.2 3B 是怎么工作的 {#第四章}
理论讲完了,现在我们打开一个真实存在、你今天就能下载来跑的模型------Meta 在 2024 年开源的 LLaMA 3.2 3B(30 亿参数的小模型,能在手机和边缘设备上运行),把它从输入到输出,一层一层拆开看。
4.1 先看"身份证":LLaMA 3.2 3B 的核心配置
这些数字全部来自官方配置文件,后面每个数字我们都会用到:
| 配置项 | 数值 | 通俗解释 |
|---|---|---|
| hidden_size(隐藏维度) | 3072 | 每个词被表示成一个 3072 维的向量 |
| num_hidden_layers(层数) | 28 | 28 个 Transformer 解码器层,从下往上堆叠 |
| num_attention_heads(注意力头) | 24 | 每层有 24 个"相亲分会场" |
| head_dim(每个头的维度) | 128 | 3072 ÷ 24 = 128,也是公式里的 d_k |
| num_key_value_heads(KV 头) | 8 | GQA 分组查询:24 个 Q 头共享 8 组 K/V |
| intermediate_size(FFN 中间层) | 8192 | 前馈网络把 3072 撑大到 8192 再压回来 |
| vocab_size(词表大小) | 128256 | 模型认识 12.8 万个 token |
| max_position_embeddings(上下文) | 131072 | 最长能处理 12.8 万 token 的上下文 |
| rope_theta(RoPE 基数) | 500000 | 旋转位置编码的参数,与长上下文有关 |
注意 LLaMA 是一个 Decoder-only(仅解码器) 架构------它没有原始 Transformer 论文里的编码器部分,只保留了解码器,专心做"预测下一个词"这一件事。现在主流的 GPT、Claude、DeepSeek 也都是这个路线。
4.2 整体数据流:一个词从输入到输出的旅程
假设我们输入一句话「今天天气真」,希望模型预测下一个字。整个流程是这样的:
输入文本「今天天气真」
│
▼ ① 分词 Tokenizer:切成 token,转成数字 ID
▼ ② 词嵌入 Embedding:每个 ID 查表 → 3072 维向量
│
├──────────── 进入 28 层解码器(核心循环)────────────┐
│ 每一层都做这 4 件事: │
│ ③ RMSNorm 归一化 │
│ ④ 多头注意力 + RoPE 位置编码 + GQA │
│ ⑤ 残差连接(把输入加回来) │
│ ⑥ RMSNorm → SwiGLU 前馈网络 → 再残差 │
└──────────── 28 层叠完,输出 3072 维向量 ───────────┘
│
▼ ⑦ 最终 RMSNorm
▼ ⑧ LM Head:3072 维 → 128256 维(每个词的分数)
▼ ⑨ softmax → 选出概率最高的词
│
输出「的」(预测的下一个字)下面把每一步都讲清楚。
4.3 第①②步:从文字到向量
① 分词(Tokenizer)
计算机不认识汉字,只认识数字。Tokenizer 的工作就是把「今天天气真」切成一个个 token,再查词表换成数字 ID。LLaMA 用的是 BPE(字节对编码) 算法,一个 token 可能是一个字、一个词、甚至半个词。比如可能切成:
「今天天气真」
→ ["今天", "天气", "真"] (切成 3 个 token)
→ [15125, 28321, 9421] (查词表换成 ID,数字仅为示意)② 词嵌入(Embedding)
拿到 ID 后,模型有一张巨大的查找表(Embedding 表),大小是 128256 × 3072。每个 token ID 对应表里的一行------一个 3072 维的向量。这个向量就是这个词的"初始含义坐标"。
词嵌入表参数量 = 词表大小 × 隐藏维度 = 128256 × 3072 ≈ 3.94 亿
光这一张表,就占了 3B 模型里相当大的一块参数。
小贴士: LLaMA 3.2 3B 还用了权重共享(tied embeddings) ------输入的词嵌入表和最后输出的 LM Head 是同一张表,省下了近 4 亿参数。这是小模型为了节省参数常用的技巧。
4.4 第③⑦步:RMSNorm 归一化------给数据"稳压"
每进注意力或前馈网络之前,数据都要先过一道 RMSNorm。它的作用类似"稳压器":把一组数值的大小拉到一个统一、稳定的范围,避免某些数字过大过小导致训练崩溃。
传统 Transformer 用的是 LayerNorm,而 LLaMA 改用了更简洁的 RMSNorm------它省掉了减均值这一步,只用"均方根"做缩放。好处是:计算更快、更省、训练更稳定,对大规模扩展更友好(奥卡姆剃刀:能省则省)。
4.5 第④步核心之一:RoPE 旋转位置编码------告诉模型"词的位置"
还记得吗?注意力机制让所有词并行计算,但这带来一个副作用:模型天然不知道词的先后顺序。对它来说「我打你」和「你打我」里的字是一样的一堆向量。必须有办法把"位置信息"注入进去。
LLaMA 用的是 RoPE(旋转位置编码) 。它的巧妙之处在于:不是简单地给每个词"贴个位置标签",而是根据词的位置,把它的 Q 和 K 向量旋转一个对应的角度。
RoPE 的直觉
想象每个词的向量是钟表上的指针。
第 1 个位置的词,指针转 1 个单位角度;第 2 个位置转 2 个单位......
位置越靠后,转得越多。两个词做注意力点积时,它们的"角度差"就天然编码了"相对距离"。
距离近的词角度差小、关系更紧;距离远的角度差大。
RoPE 编码的是相对位置(谁离谁多远),而不是绝对位置(谁是第几个)。这让它在处理长文本时表现特别好。配合前面那个 rope_theta = 500000 的大基数,LLaMA 3.2 3B 才能支持高达 12.8 万 token 的超长上下文。
4.6 第④步核心之二:GQA 分组查询注意力------小模型的"省钱"绝招
标准多头注意力里,24 个头各有自己的 Q、K、V,一共 72 套。但在推理时,K 和 V 需要被缓存起来(叫 KV Cache)反复使用,非常吃显存。序列越长,KV Cache 越大,显存越扛不住。
LLaMA 3.2 3B 用了 GQA(Grouped-Query Attention,分组查询注意力) 来省显存。看配置:24 个 Q 头,但只有 8 个 KV 头。也就是说:
| 注意力方案 | Q 头数 | K/V 头数 | 特点 |
|---|---|---|---|
| MHA 标准多头 | 24 | 24 | 每个 Q 独享 K/V,效果好但最费显存 |
| MQA 多查询 | 24 | 1 | 所有 Q 共享 1 套 K/V,最省但可能掉效果 |
| GQA 分组查询(LLaMA 用) | 24 | 8 | 24 个 Q 分成 8 组,每 3 个共享 1 套 K/V |
GQA 的精髓
24 ÷ 8 = 3,即每 3 个"查询头"共用 1 组"标签 K + 内容 V"。
在"效果几乎不掉"和"显存大幅下降"之间取得平衡。
这正是 3B 这种要跑在手机/边缘设备上的小模型必须做的优化。
4.7 第⑤步:残差连接------给信息留一条"高速公路"
每个子层(注意力、前馈)算完后,都会把这一层的输入原样加回到输出上,这叫残差连接(Residual Connection)。
python
输出 = 子层(输入) + 输入 # 把输入"抄近路"加回来为什么要这样?因为 28 层堆下来,如果每层都彻底改写数据,原始信息很容易在层层传递中丢失(梯度消失)。残差连接相当于修了一条贯穿所有层的"高速公路",让原始信息可以无损地一路传到顶层,每层只在上面做"微调"。这是深层网络能堆得很深还不崩的关键。
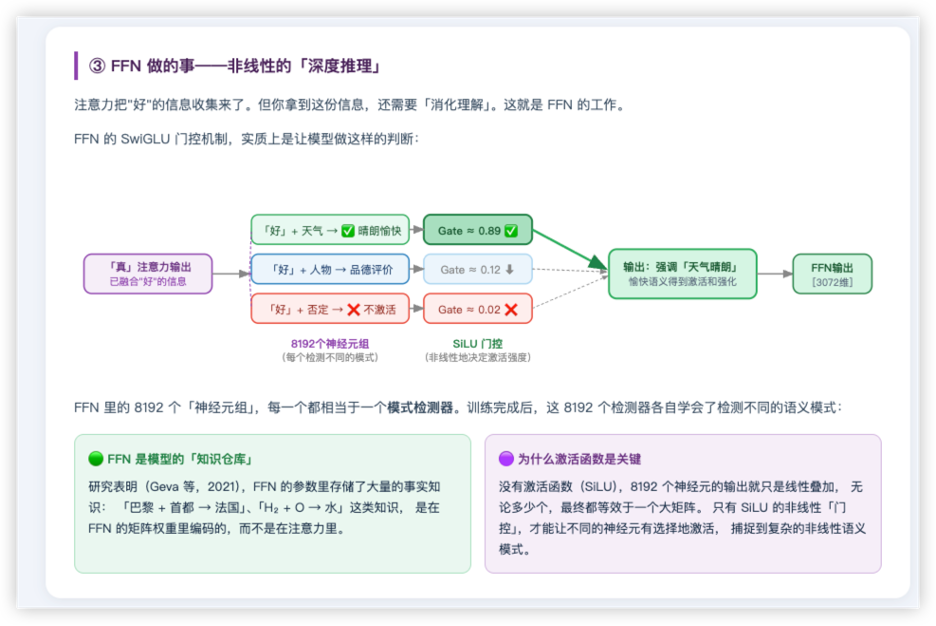
4.8 第⑥步:SwiGLU 前馈网络------逐词"深度加工"
注意力负责"词与词之间交流信息",而前馈网络(FFN)负责"对每个词单独做深度加工",提炼出更抽象的特征。
LLaMA 用的是 SwiGLU 结构。流程是:先把每个词的 3072 维向量撑大到 8192 维 (intermediate_size),用一个叫 SiLU 的激活函数做非线性变换,再压回 3072 维。
3072 维 ──撑大──▶ 8192 维 ──SiLU激活+门控──▶ ──压回──▶ 3072 维"先放大再缩小"是为了给模型更大的中间表达空间 去捕捉复杂模式。SwiGLU 里还有一个"门控"机制,相当于让模型自己决定哪些信息该放行、哪些该抑制,比传统的 ReLU 表达力更强。FFN 通常是一个 Transformer 层里参数量最大 的部分。




4.9 第⑧⑨步:LM Head------投票选出下一个词
28 层全部走完后,最后一个 token(这里是「真」)位置上的 3072 维向量,已经融合了整句话的全部信息。最后一步:把它通过 LM Head (一个 3072 × 128256 的大矩阵),变成一个 128256 维 的向量------词表里每个词都得到一个分数(logit)。
再用 softmax 把这些分数变成概率,谁的概率最高,就预测谁是下一个词。比如:
词表里 128256 个词,各得一个分数 → softmax 归一化成概率
「的」 : 0.62 ← 概率最高,选它!
「好」 : 0.18
「不」 : 0.05
......(其余 12 万多个词概率都很低)
输出:「今天天气真」+「的」然后把「的」拼回输入,再跑一遍整个流程预测下一个词......如此循环,一个字一个字地"吐"出来,就是你看到的大模型在"打字"的过程。这个过程叫自回归生成(Autoregressive Generation)。
第五章 "3B"这 30 亿参数到底从哪来 {#第五章}
我们常说"3B 模型",意思是它有约 30 亿个参数。这些参数具体藏在哪里?我们用前面的配置数字粗略算一遍,让"参数量"这个抽象概念变得具体。
① 词嵌入层(与输出层共享)
词表 × 隐藏维度 = 128256 × 3072 ≈ 3.94 亿
(因为输入输出共享同一张表,这部分只算一次)② 每一层 Transformer 的参数
一层里主要有两大块------注意力 + 前馈网络:
| 模块 | 矩阵 | 参数量(约) |
|---|---|---|
| 注意力 Q 投影 | 3072 × 3072 | 约 944 万 |
| 注意力 K 投影(GQA,8 头) | 3072 × 1024 | 约 315 万 |
| 注意力 V 投影(GQA,8 头) | 3072 × 1024 | 约 315 万 |
| 注意力 O 输出投影 | 3072 × 3072 | 约 944 万 |
| FFN gate 投影 | 3072 × 8192 | 约 2516 万 |
| FFN up 投影 | 3072 × 8192 | 约 2516 万 |
| FFN down 投影 | 8192 × 3072 | 约 2516 万 |
| 单层合计 | --- | 约 1.0 亿 |
注意 K、V 投影因为用了 GQA,只有 8 个头(8 × 128 = 1024 维),比 Q 的 24 个头(3072 维)小了 2/3------这就是 GQA 省参数省显存的直接体现。
③ 全部加总
28 层 × 每层约 1.0 亿 ≈ 28 亿
+ 词嵌入层 ≈ 3.94 亿
+ 其余(RMSNorm 等) ≈ 少量
─────────────────────────────────
总计 ≈ 32 亿 ≈ "3B"关键洞察
30 亿参数里,绝大部分集中在 28 层 Transformer 的注意力矩阵和 FFN 矩阵中。
所谓"训练大模型",就是用海量数据,把这 30 亿个数字一点点调到最优。
所谓"模型变大",主要就是:把层数堆更多、把隐藏维度撑更宽。
第六章 为什么 Transformer 能"大力出奇迹" {#第六章}
拆完结构,我们回到那个最根本的问题:为什么是 Transformer 成了所有大模型的基础,而不是别的架构?答案有三层。
6.1 它让算力可以被"无限正反馈"
没有了循环结构,整个网络变成纯前向计算,梯度传播极其干净。你可以无限加层、加宽,参数规模没有结构性的天花板。
于是 Scaling Law(规模定律) 出现了:参数越多、数据越多、算力越多,效果就越好,而且是可预测的幂律曲线。这个规律能成立,前提是"架构本身不是瓶颈"。RNN 堆参数会退化,而 Transformer 不会。
Transformer 是第一个让"投入越多、就越强、且没有顶"的架构。
这才是它成为 LLM 基础的根本原因------不是因为它多聪明,而是因为它能被无限做大。
6.2 它的"假设"极少,所以能横扫一切
Transformer 没有被设计成专门学某种语言规律。它的结构假设极少,只说一件事:任意两个位置之间,都可以有任意强度的关系。
至于这个"位置"装的是词、像素、氨基酸还是音频帧,架构本身根本不在乎。所以:
- ViT 用它处理图像;
- AlphaFold 用它折叠蛋白质;
- Sora / 各类视频模型 用它生成视频。
假设越少,适用范围越广。 这就是它能横扫文本、图像、语音、多模态等所有领域的底层原理(奥卡姆剃刀原则在这里再次发光)。
6.3 天时地利人和:火柴与炸药
最后要说一句公道话:Transformer 的成功,不只是"它聪明",而是三个条件在 2017 年前后同时成熟的结果。
| 要素 | 说明 |
|---|---|
| 天时(算力) | GPU 算力在 2017--2020 迎来爆发,恰好喂得起 Transformer 的并行计算需求。换在 2010 年,同样的架构也跑不起来 |
| 地利(数据) | 互联网积累了几十年的海量文本,恰好在这个时代可以被拿来训练。没有数据,再好的架构也是空架子 |
| 人和(设计) | 《Attention is All You Need》大胆抛弃循环结构,让"注意力"独立挑大梁,恰好成了点燃炸药的火柴 |
技术史上真正的革命,从来不只是某个天才的发明,而是无数个条件同时成熟之后,某一个设计恰好成了点燃炸药的那根火柴。Transformer,就是那根火柴。
结语 一句话收束 {#结语}
绕了一大圈,回到最开始的第一性原理判断:
建模语言关系,不能有"信息压缩的中间商"。任意两个词,必须能直接对话。
接受这个判断,注意力机制几乎是唯一合逻辑的实现。
并行性、可扩展性、跨模态泛化,全都是它的自然推论。
而我们今天拆解的 LLaMA 3.2 3B,正是这套思想在工程上的一个精致样本:28 层堆叠、QKV 注意力、RoPE 位置编码、GQA 省显存、SwiGLU 加工、残差高速公路------每一个设计,都是在"既要效果、又要省、还要能做大"之间反复权衡的结果。
它会被取代吗?大概率会。但取代它的东西,多半还是在解同一道题------如何让任意两个 token 高效地直接对话------只是找到了一个不那么贵的解法而已。
(全文完)