上周数据部的小张又被业务部门找上门------市场部要的"全国各区域线上线下销售额对比"报表,AI生成的SQL把电商库的"交易金额"和线下POS库的"实收金额"直接关联求和,结果差了近20%。小张只能加班排查,发现是两个库的金额字段统计口径不同,且表间关联关系没有被AI识别到。这样的场景,几乎每天都在企业数据部门上演:跨库智能问数看似高效,却常常因为数据关系混乱导致结果失真,最终还是要数据工程师兜底。
多源数据时代,跨库智能分析的"可信度"困境
随着企业数字化转型深入,数据分散在MySQL、Hive、ClickHouse等多类数据源中已成为常态。业务部门的分析需求越来越复杂,从单一库的"本月销售额"转向跨库的"线上用户转化与线下库存联动分析"。NL2SQL(自然语言转SQL)作为智能问数的核心技术,本应降低业务人员的用数门槛,但跨库场景下的准确率始终难以突破------根据某咨询机构调研,超过65%的企业反馈跨库NL2SQL生成的查询结果存在逻辑错误,无法直接用于业务决策。
这种困境背后,是企业多源数据管理的两大核心痛点:
痛点一:手动维护跨库关系,成本高易出错
企业多源数据的表间关系、字段映射、口径规则往往散落在文档、工程师的经验中。当新的业务系统上线、数据源更新时,数据工程师需要手动梳理关联关系,不仅耗时(平均每个新数据源梳理需3-5个工作日),还容易遗漏隐藏的关联规则,比如不同库中"用户ID"的命名差异(uid/user_id/customer_id),导致后续分析出现数据匹配错误。更棘手的是,数据随着业务迭代不断变化,手动维护的关系表很快就会失效,形成"梳理-失效-再梳理"的恶性循环。
痛点二:NL2SQL缺乏可信数据底座,生成逻辑易失真
大多数NL2SQL工具仅依赖单库的表结构和字段信息生成查询,无法识别跨库数据的关联规则和血缘关系。当用户提出跨库查询需求时,AI只能基于字面匹配生成SQL,比如将"销售额"直接关联不同库的金额字段,却忽略了字段的统计口径(含税/不含税)、数据流转链路(是否经过清洗聚合),最终导致查询结果与业务预期不符,降低了业务人员对智能问数的信任度。
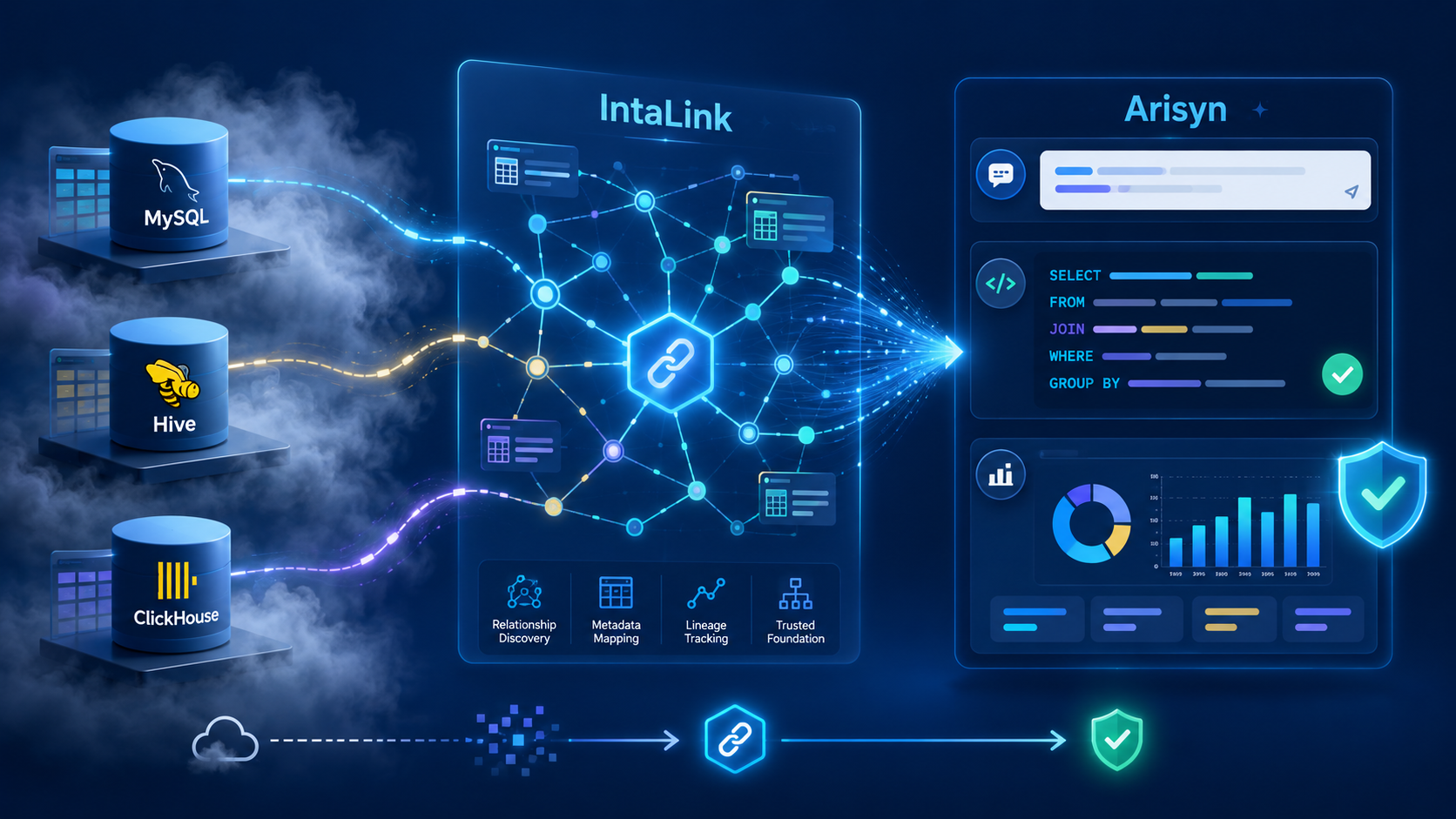
技术本质:跨库NL2SQL的核心是"数据关系可信"
跨库NL2SQL的核心痛点,本质是"数据关系的不可信"------没有准确的表间关联、字段血缘和语义映射,AI就无法理解数据背后的业务逻辑,自然生成不出正确的跨库查询。
传统元数据管理工具仅能被动收集数据结构信息,无法主动发现隐藏的关联关系;而一些AI问数工具试图通过大模型的语义理解弥补这一缺陷,但缺乏真实数据关系的支撑,大模型的"幻觉"问题会被放大,导致跨库查询逻辑错误频发。
IntaLink的核心价值在于构建了一套自动、可信的多源数据关系底座:
-
通过内置的元数据采集引擎,对接各类数据源获取表结构、字段属性等基础信息;
-
再通过智能关系发现算法,结合字段名相似度、数据类型匹配、样本值分布、业务规则(如用户ID的唯一性约束)等多维度特征,自动识别跨库表间的关联关系,比如电商库的"订单表"与物流库的"运单表"通过"订单ID"关联;
-
同时,通过数据血缘分析追踪数据从源头到加工的全链路,记录字段的口径变化、清洗规则,形成完整的可信数据关系图谱。
IntaLink与Arisyn的协同则解决了跨库NL2SQL的落地难题:IntaLink提供的可信数据关系图谱,成为Arisyn理解业务查询的"知识底座"------当用户提出"线上订单的物流配送时长分布"时,Arisyn首先通过IntaLink的关系图谱识别到订单表与运单表的关联关系,再结合血缘信息确认"配送时长"字段的计算规则(签收时间-发货时间),最终生成准确的跨库SQL,避免了字段错配、口径不一致等问题。
IntaLink 如何为跨库NL2SQL创造真实价值
1. 自动构建多源数据关系网络,释放工程师产能
IntaLink的智能关系发现能力,无需工程师手动梳理跨库关联规则,可自动识别90%以上的表间关联关系,将新数据源的关系梳理时间从3-5个工作日缩短至数小时。某连锁零售企业接入IntaLink后,数据工程师用于维护跨库关系的时间减少了70%,得以将精力投入到更有价值的数据建模和分析工作中
2. 为跨库NL2SQL提供可信支撑,提升查询准确率
基于IntaLink的关系图谱和血缘分析,Arisyn的跨库NL2SQL查询准确率从平均60%提升至90%以上。业务人员无需担心查询结果的可信度,因为每一条SQL的生成都基于真实的数据关系,且可通过数据血缘追溯到数据源,确保结果符合业务逻辑。
3. 统一数据语义与口径,消除跨部门用数分歧
IntaLink的元数据管理能力,可将跨库的字段语义、口径规则统一管理,结合Arisyn的双语义层治理,让业务人员和技术人员对数据的理解保持一致。比如"销售额"字段,无论来自电商库还是线下POS库,都能明确区分含税与不含税的口径,避免了跨部门用数时的分歧。
总结:数据关系是跨库智能分析的"隐形地基"
跨库智能分析的本质,是让AI真正理解多源数据之间的业务逻辑,而不仅仅是生成SQL语句。IntaLink作为数据关系底座,通过自动发现、构建可信的跨库数据关系网络,为Arisyn的NL2SQL能力提供了坚实的基础,解决了跨库查询中"结果不可信"的核心痛点。
当企业不再需要为数据关系的梳理和验证耗费大量人力,当业务人员可以放心使用跨库智能问数获取准确结果时,多源数据的价值才能真正被释放,成为驱动业务决策的核心动力。