前面几节里,Hify 的工程骨架其实已经搭得差不多了。
我们有了 Maven 多模块结构,有了 hify-common 里的统一返回 Result、全局异常处理器、MyBatis-Plus 配置、Redis 配置,也把前端 Vue 工程和一键启动链路打通了。按理说,接下来好像就该直接写业务模块了。
但如果你真的这样往下做,很快就会发现一个问题:
项目虽然"能启动",但离"能稳定写业务"还差一层非常关键的基础设施。
比如:
-
每个实体的公共字段要不要统一封装?
-
列表分页怎么从前端参数转成 MyBatis-Plus 的 Page?
-
创建和更新接口的参数校验怎么统一接进全局异常处理?
-
调外部 LLM API 的 HTTP 客户端怎么封装?
-
线程池要不要隔离?
-
熔断和重试什么时候该加?
-
日志和 traceId 要不要先打好?
这些东西如果不先做,后面每个业务模块都会重复处理一遍。你写 Provider 要补一次,写 Agent 再补一次,写 Chat 时还得再补一轮。最后不仅代码重复,标准也会越来越散。
这一节,我们就专门把这层"后端业务基础设施"搭起来。
这一次,先不要急着做,先让 Claude Code 帮你想
前面我们和 Claude Code 的协作,大多数时候是这样的:
-
你已经想清楚了要做什么
-
你给出明确指令
-
Claude Code 负责执行
-
你再 review 和验收
这种方式非常适合"问题已经定义清楚"的场景,我把它叫做执行模式。
但到了"业务开发前还缺哪些基础组件"这个问题上,情况就不太一样了。
你通常知道一个大概方向,比如线程池、分页、缓存、HTTP 客户端这些肯定要有;但你未必能一次性列全,也未必确定先后顺序是不是合理。这个时候,如果还硬按执行模式走,很容易做着做着才发现漏项。
所以这里更适合切换一种协作方式:
先让 Claude Code 帮你梳理全景,再由你来做取舍,最后再进入执行。
我把这种方式叫做咨询模式。
两种模式的区别可以简单理解成:
-
执行模式:你想清楚了,让它做
-
咨询模式:你知道方向,但不确定细节,先让它帮你查漏补缺
这不是把决策权交给 AI,而是把它当成一个高效率的架构咨询对象。它帮你列出可能项、补上盲区、提醒你常见遗漏,你再结合项目现状判断哪些该做、哪些可以后做。
这套方法后面会反复用到。每次进入一个新阶段,比如业务开发、测试体系、部署优化,你都可以先问一句:
"这一阶段我应该优先考虑什么?"
有时候,光这一问,就能帮你少掉很多返工。
先让 Claude Code 列一份后端基础设施清单
我当时直接问 Claude Code:
Hify项目工程骨架已经搭好(Maven多模块、hify-common的Result / 异常处理 / MyBatis-Plus配置 / Redis配置、前端Vue工程)。现在要开始做业务功能了。在写业务代码之前,还需要准备哪些基础组件?从数据库层、接口层、外部调用、缓存、可观测性几个角度帮我梳理,每个组件说明它解决什么问题。

Figure 1: Claude Code 给出后端基础组件的第一版清单

Figure 2: 从数据库、接口、缓存、可观测性等角度展开清单

Figure 3: 清单延展出的组件说明与作用解释
这一步特别有价值的地方,不是它列出了多少组件,而是它帮我发现了几个我自己很容易忽略的点。
像线程池、分页、熔断这些,我本来就预期会做。但有两个东西如果只靠自己列清单,我很可能会漏掉:
-
schema.sql
-
@MapperScan
这两个都不是什么"高级架构设计",但偏偏最容易在忙着想线程池、缓存、熔断的时候被忽略。结果就是:你以为自己已经准备好写业务了,一启动才发现表没建、Mapper 没扫上,然后开始花时间排查这种本来应该提前发现的问题。
所以我最后没有直接照着这份清单往下做,而是先把它分成了三档优先级。
这个动作很关键,因为不是所有基础组件都要现在做。
有些不做,业务代码根本跑不起来;有些则可以在第一个模块开发时同步补;还有些更偏健壮性和可运维性,可以稍晚一点做,但最好在真正进入大规模业务开发前补齐。
第一档:必须先做,不然业务代码根本跑不起来
第一档的判断标准很简单:
如果不先做,后面一写业务就会直接卡住。
1. 数据库初始化脚本
这是我差点忽略掉的一项。
因为前面一直在搭工程骨架、公共模块、前端工程,脑子里想的更多是代码结构和协作规范,结果差点忘了一个最基础的事实:
表都还没建。
所以我给 Claude Code 的提示词是:
按照CLAUDE.md的数据库规范和数据模型,生成所有业务表的建表DDL。放在hify-app/src/main/resources/db/schema.sql。表名小写下划线、主键id bigint自增、时间字段created_at/updated_at datetime、逻辑删除deleted tinyint默认 0、字符集utf8mb4。包含:provider、model_config、agent、agent_tool、mcp_server、chat_session、chat_message。
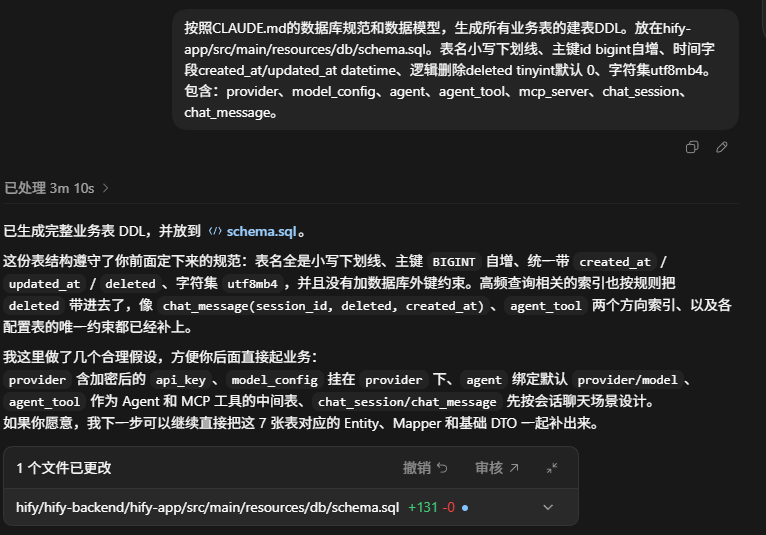
Figure 4: 生成业务表建表 DDL 的执行结果
这一步看起来很基础,但它其实是所有后端业务开发的真正起点。没有 DDL,Mapper 没法跑,实体没法对上,CRUD 也无从验证。
2. @MapperScan 扫描路径
第二个很容易漏掉的是 Mapper 扫描。
因为 Hify 不是单模块项目,业务 Mapper 分散在各个子模块里,比如:
-
com.hify.provider.mapper
-
com.hify.agent.mapper
-
com.hify.mcp.mapper
如果启动类只扫自己的局部包路径,后面所有 Mapper 注入都会报错。
我给 Claude Code 的提示词是:
在HifyApplication启动类上加 @MapperScan("com.hify.**.mapper"),扫描所有子模块的Mapper包。
这件事就是典型的"说出来不难,但特别容易忘"。而咨询模式的价值,恰好就在这种地方体现出来了。
3. 线程池配置
第三个必须先做的是线程池。
这里不只是为了"以后好看",而是因为前面在规范里其实已经定下了要求:LLM 调用必须走独立线程池,不能和普通异步任务混用。
所以如果你后面进入 Chat 模块开发,代码里要注入 @Qualifier("llmExecutor"),那这个 Bean 就必须先存在。
我给 Claude Code 的执行指令是:
在hify-common中创建ThreadPoolConfig(com.hify.common.config)。定义两个线程池:llmExecutor(核心10,最大50,队列100,线程名前缀llm-,拒绝策略CallerRunsPolicy)用于LLM调用;asyncExecutor(核心5,最大20,队列200,线程名前缀async-)用于日志异步写入等非关键任务。用@Bean + @Qualifier注册。
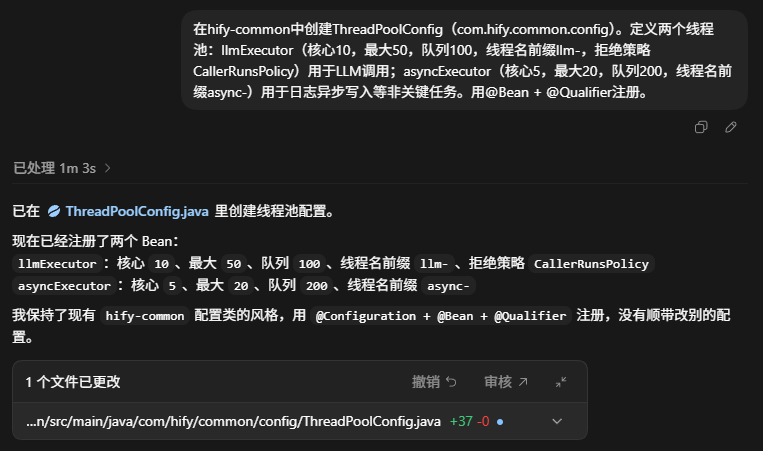
Figure 5: LLM 线程池和异步线程池配置结果
这里有两个点值得特别说明。
第一,线程池隔离不是形式主义。
想象一个场景:用户 A 正在对话,请求一个 LLM,卡了 30 秒;同时用户 B 打开管理页面,想看 Agent 配置。如果所有异步任务都共用一个线程池,对话请求把线程占满了,管理页面也会一起卡住。
第二,线程名前缀非常有用。
后面你看日志时,llm-3 一眼就知道是 LLM 调用线程,async-1 一眼就知道是普通异步任务。要是全都叫 pool-1-thread-3,排查问题时就会非常难受。
至于线程池参数为什么这么设,也不是拍脑袋:
-
目标用户量是 20 到 50 人
-
假设一半人在同时对话,大概就是 10 到 25 个并发 LLM 调用
-
核心线程 10 足够起步
-
最大线程 50 是给高峰留缓冲
一期先这样,后面再根据真实监控调整,这就是比较合理的做法。
第二档:开始写业务前最好补齐的基础能力
第二档的特点是:
不做也不是完全跑不起来,但只要开始写第一个标准业务模块,你就会马上用到。
与其等每个模块里重复补,不如现在一次补好。
1. BaseEntity
后端所有实体都会有一组几乎相同的公共字段:
-
id
-
created_at
-
updated_at
-
deleted
如果不抽基类,后面每个 Entity 都要重复写这些字段和对应注解,不仅啰嗦,而且很容易不一致。
所以我给 Claude Code 的指令是:
在hify-common中创建BaseEntity类。字段:id(Long,@TableId自增)、createdAt(LocalDateTime,插入时自动填充)、updatedAt(LocalDateTime,插入和更新时自动填充)、deleted(Integer,@TableLogic,默认0)。后面所有业务实体继承这个类。
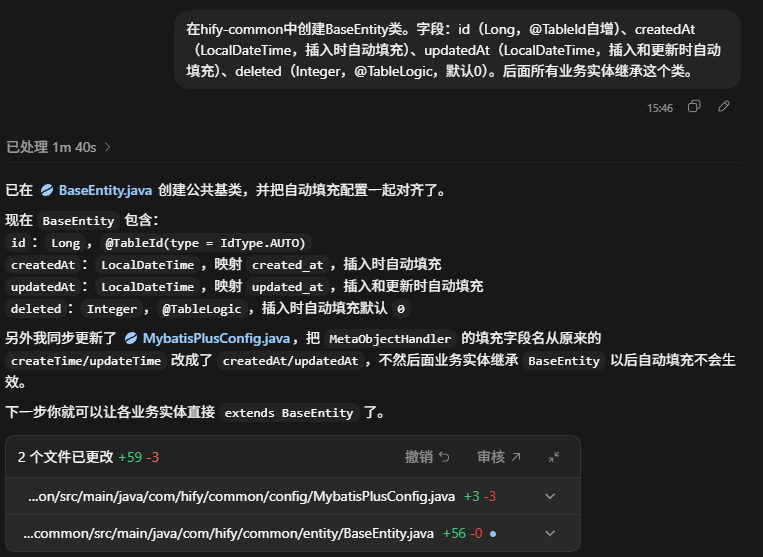
Figure 6: 公共实体基类 BaseEntity 的实现结果
这种基础类看起来很普通,但它能让后面所有业务实体的代码明显干净很多。
2. 统一分页封装
前面我们已经定过分页请求参数和响应结构,也配过 MyBatis-Plus 分页插件,但还差一个真正把两边接起来的工具层。
不然每个列表接口都要自己处理:
-
page/pageSize 的默认值
-
最大分页大小限制
-
MyBatis-Plus Page 对象构造
-
IPage 到 PageResult 的转换
所以我让 Claude Code 创建一个统一工具类:
在hify-common中创建PageHelper工具类。提供两个静态方法:toPage(page, pageSize)把前端参数转成MyBatis-Plus的Page对象(page从1开始,pageSize默认20最大100);toPageResult(IPage)把查询结果转成我们的PageResult。
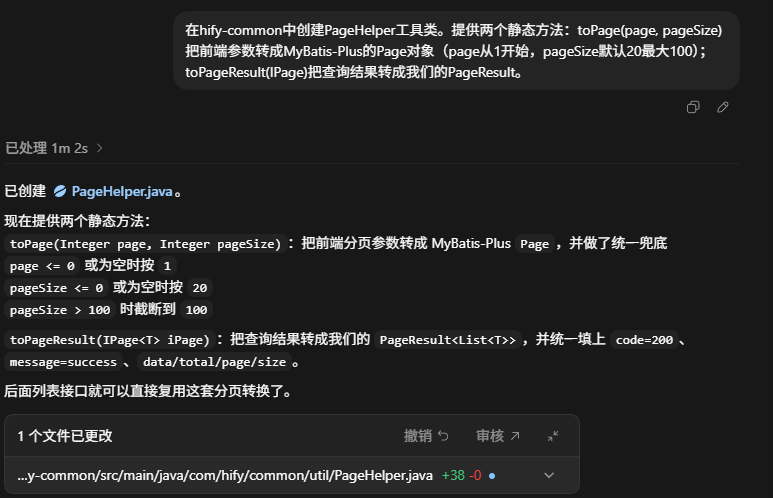
Figure 7: 分页参数转换与分页结果封装工具
这个工具一旦定下来,后面每个分页列表接口都会轻很多。
3. 入参校验
这块其实技术本身不复杂,Spring Boot 自带的 @Valid + JSR 303 就够用了。
关键不在"会不会写注解",而在于:
要把它和全局异常处理链路真正串起来。
所以我给 Claude Code 的约束是:
每个创建和更新接口都需要校验入参。Spring Boot的 @Valid + JSR 303注解就够用,关键是和GlobalExceptionHandler配合好。它已经捕获了MethodArgumentNotValidException,会转成 Result.fail(ErrorCode.PARAM_ERROR, 具体校验信息)。
Figure 8: 参数校验与全局异常处理链路对齐
这样后面每个创建、更新接口都只需要在 DTO 上写好校验规则,在 Controller 入参上加 @Valid,剩下的统一交给公共链路处理。
4. 统一时间序列化
这件事我特别建议尽早做。
因为如果你不主动配,Jackson 序列化 LocalDateTime 时,很多情况下会输出成数组格式:
[2025,3,16,10,30,0]
前端看到这种结构通常会很痛苦,解析和展示都不顺手。
所以我让 Claude Code 统一配置时间序列化:
在hify-common中配置Jackson的全局时间序列化。LocalDateTime统一用ISO 8601格式(yyyy-MM-dd'T'HH:mm:ss),LocalDate用yyyy-MM-dd。配置JavaTimeModule,关掉WRITE_DATES_AS_TIMESTAMPS。
Figure 9: Jackson 全局时间序列化配置
这就是那种典型的"十几行代码,省掉后面无数坑"的基础设施。
5. Spring Cache 集成
现在 Hify 里已经有了 RedisTemplate 和 RedisUtil,但它们本质上还是"裸 Redis 操作"。
而业务层真正想要的通常是:
-
@Cacheable
-
@CacheEvict
-
@CachePut
这种声明式缓存能力。
比如 Provider 配置、Agent 配置,本质上就是典型的"读多写少"场景。你不需要每次都手动写一层 if-else 来查缓存、查库、回填缓存,只要统一把 Spring Cache 接起来就行。
所以我给 Claude Code 的执行指令是:
在hify-common中启用Spring Cache。@EnableCaching,配置RedisCacheManager,默认TTL 30分钟,key前缀hify:。配置不同缓存名的TTL:provider-cache 30分钟、agent-cache 30分钟、session-cache 2小时。
Figure 10: Spring Cache 与 RedisCacheManager 配置
这样后面业务 Service 里直接加:
@Cacheable(cacheNames = "provider-cache")
就能开始走标准的 Cache-Aside 模式了。写操作再配 @CacheEvict 做失效,整个链路就顺了。
6. 用一个最小 CRUD 验证第二档基础设施是否真的可用
第二档这些组件单独看都不复杂,但真正重要的是:它们组合起来能不能工作。
所以我没有只停留在"工具类和配置都建好了",而是让 Claude Code 做了一个最简单的 CRUD 演示,用它来验证整条链路。
提示词是:
实现一个最简单的CRUD演示。实体:DemoItem,只有name(String)和status(Integer)两个字段,继承BaseEntity。完整实现Controller → Service → ServiceImpl → Mapper → Entity → CreateReq/UpdateReq/Resp DTO。Controller使用RESTful路径 /api/v1/demo-items,返回统一Result,列表接口返回PageResult,创建和更新接口使用@Valid校验,Service层处理业务逻辑,Mapper继承BaseMapper。
Figure 11: 用 DemoItem 跑通完整 CRUD 标准流程
它的意义不在于这个 Demo 本身有多重要,而在于它可以一次性验收第二档所有关键基础设施:
# 入参校验生效吗? curl -X POST http://localhost:8080/api/v1/demo-items \ -H "Content-Type: application/json" \ -d '{"name": "", "status": 1}' # 期望:Result.fail,提示 name 不能为空 # 正常创建 curl -X POST http://localhost:8080/api/v1/demo-items \ -H "Content-Type: application/json" \ -d '{"name": "测试项", "status": 1}' # 期望:Result.ok(id),数据库 created_at 自动填充 # 分页列表 curl "http://localhost:8080/api/v1/demo-items?page=1&pageSize=10" # 期望:PageResult,时间字段是 ISO 8601 格式 # 逻辑删除 curl -X DELETE http://localhost:8080/api/v1/demo-items/1 # 期望:数据库 deleted=1,再查列表看不到了
这里每一个请求,其实都在验证一条基础能力:
-
空 name:验证入参校验和全局异常处理
-
创建成功:验证 BaseEntity 自动填充
-
分页列表:验证 PageHelper + MyBatis-Plus 分页链路
-
时间格式:验证 Jackson 时间序列化配置
-
逻辑删除:验证 MyBatis-Plus 逻辑删除配置
如果这套 Demo 全部跑通,说明第二档基础设施已经不是"看起来有了",而是真正能支撑业务开发了。
而且这个 Demo 最好不要删。后面开始做 Provider、Agent 等正式模块时,它就是最好的参考模板。
第三档:不影响起步,但最好尽早补齐的健壮性能力
第三档的特点是:
不做也能写业务,但从工程质量和后续演进来看,越早补越省事。
1. 调外部 LLM API 的 HTTP 客户端封装
Hify 后面一定会接各种外部 LLM API,这件事迟早要做。
在正式动手前,我先用咨询模式确认方案是否合理:
帮我分析普通请求用RestTemplate、流式SSE请求用OkHttp EventSource这个方案,有没有问题?
Claude Code 的反馈是:这个方向基本合理,但要注意连接池、超时参数和流式场景的差异。
确认思路没问题之后,再进入执行模式:
在hify-common中创建LlmHttpClient 类(com.hify.common.http)。内部持有RestTemplate(连接超时5s,读超时60s)和 OkHttpClient(连接超时5s,读超时120s)。提供 post(url, headers, body) 方法返回String,提供stream(url, headers, body, callback) 方法通过回调逐行返回。所有请求记录日志(URL、耗时、状态码),异常统一转为LlmApiException(区分 TIMEOUT、AUTH_FAILED、RATE_LIMITED)。
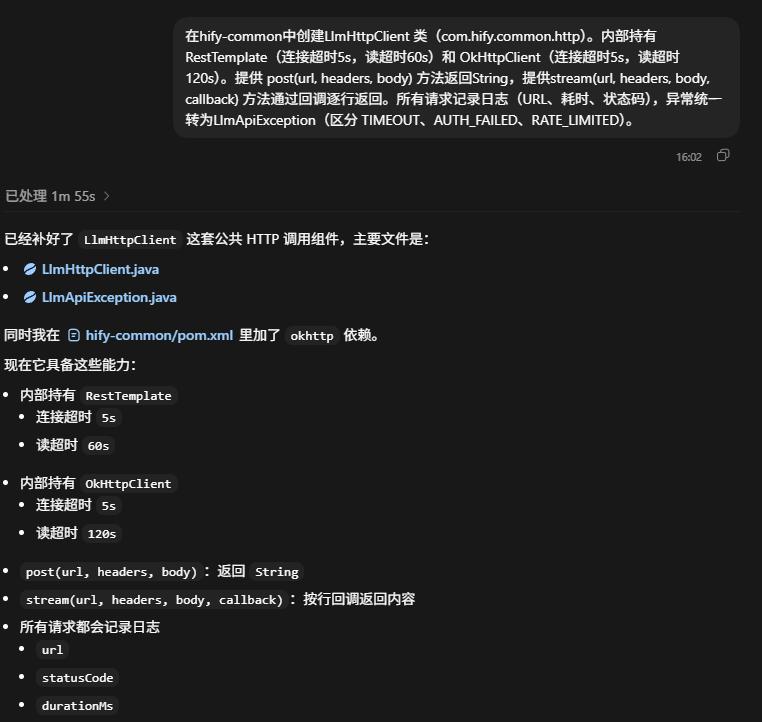
Figure 12: LLM HTTP 客户端封装结果
这里有一个很容易被忽略但其实很重要的点:为什么超时设这么长?
因为 LLM API 根本不是普通 HTTP 调用。
一次 GPT-4 级别的调用,10 到 20 秒并不奇怪;流式响应如果拉满,持续一两分钟也完全正常。用普通内部接口那种几秒超时的思路去配,很快就会把自己坑进去。
这也是为什么我一直强调:AI 可以帮你写代码、列方案,但真正理解这些参数为什么这么设,仍然是程序员很有价值的一部分能力。
2. 熔断与重试
线程池解决的是"慢请求不要拖死其他功能"。
熔断解决的是另一个问题:
某个 Provider 已经明显挂了,你还要不要继续傻等它每次超时?
显然不该。
所以我给 Claude Code 的执行指令是:
在hify-common中配置Resilience4j熔断器(com.hify.common.resilience)。application.yml配置:slidingWindowSize 10,failureRateThreshold 50%,waitDurationInOpenState 30s,permittedNumberOfCallsInHalfOpenState 3。创建CircuitBreakerService,按providerName获取或创建独立熔断器实例。重试逻辑:网络超时重试2次(间隔1s),限流退避重试(2s、4s),认证失败不重试。
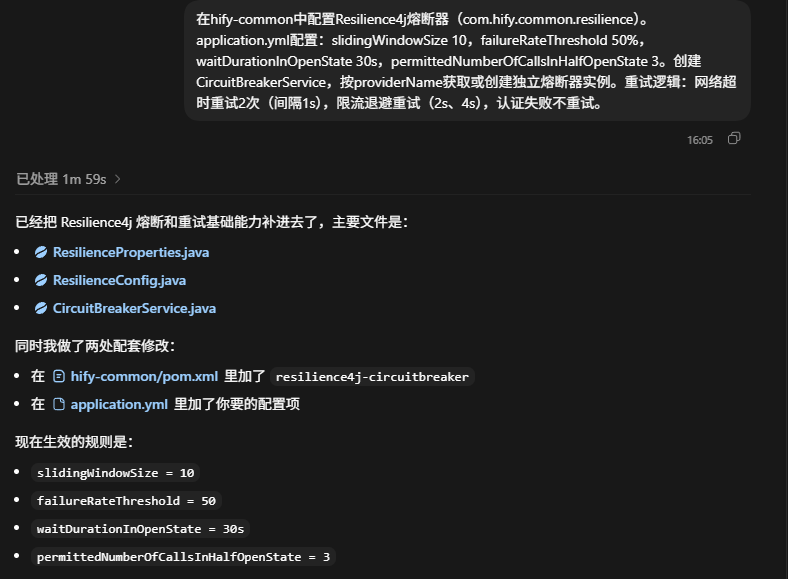
Figure 13: Resilience4j 熔断器与重试逻辑配置
这里设计成"每个 Provider 一个独立熔断器"也很重要。
因为你不希望 OpenAI 挂了之后,Claude、Gemini、Ollama 的请求也一起受影响。按 Provider 维度隔离,才是合理的做法。
3. 结构化日志与请求追踪
最后一项是日志。
很多项目早期会觉得日志这事"先随便打着",但真实开发里,你很快就会发现:
-
没有 traceId,一条请求链路的日志串不起来
-
没有统一格式,联调时看日志特别痛苦
-
没有慢请求标记,接口变慢时很难第一时间看出来
所以我给 Claude Code 的执行指令是:
在hify-common中配置统一日志(com.hify.common.log)。logback-spring.xml区分环境:开发环境控制台彩色输出,生产环境JSON格式输出到文件(按天滚动,保留30天)。创建RequestLogInterceptor(HandlerInterceptor),记录每个请求的method、path、status、耗时,慢请求(>1s)标WARN。请求进入时生成traceId放入MDC,请求结束时清理。日志格式:%d{HH:mm:ss} %thread %X{traceId} %-5level %logger{20} - %msg%n。
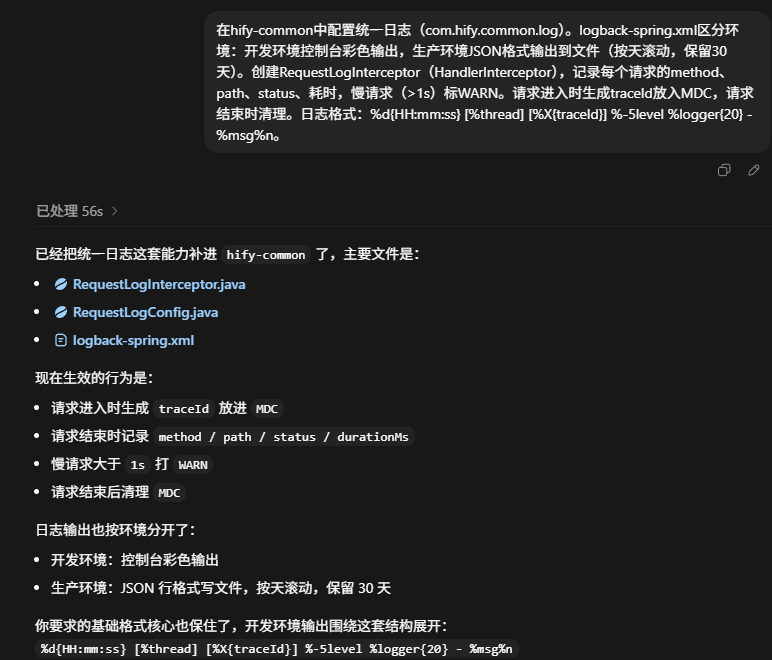
Figure 14: 统一日志配置与请求日志拦截器实现
traceId 的价值非常直接:
一个对话请求进来之后,可能会经过:
-
Controller
-
Service
-
LLM 调用
-
数据库写入
-
缓存更新
中间随便就是十几条日志。没有 traceId,你只能靠时间和关键词大海捞针;有了 traceId,整条链路一下就串起来了。
最终验收:别只看代码写没写,重点看链路是不是全通
三档组件全部补完之后,最好做一次整体检查。
我自己的验收顺序会是这样:
-
启动项目,确认日志格式正确,能看到 traceId 和线程名
-
跑一遍 DemoItem CRUD,确认请求日志拦截器能记录 method/path/status/duration
-
检查线程池相关日志,确认 llm- 和 async- 前缀都已生效
如果这些都通过,才说明 Hify 的后端业务基础设施是真正"就绪"了,而不是"文件都建了,但没整体验证过"。
总结
这一节我们做的事情,其实可以概括成三档:
-
第一档:让业务代码先跑起来
-
第二档:让业务代码写起来顺手、统一、可复用
-
第三档:让系统具备基本的健壮性和可运维性
具体来说:
-
第一档包括:建表 DDL、@MapperScan、LLM 与异步线程池
-
第二档包括:BaseEntity、分页封装、入参校验、时间序列化、Spring Cache、CRUD 标准流程验证
-
第三档包括:HTTP 客户端封装、熔断与重试、结构化日志与请求追踪
但如果只让我选一个最值得你带走的方法论,我会选这一条:
当你对某个阶段还没有完全想清楚时,先用咨询模式,不要急着直接执行。
让 Claude Code 先帮你梳理全景、补齐遗漏、列出候选项;再由你结合项目现状做判断和取舍;最后再进入执行。这会比一上来就凭感觉往下做,稳很多。
另外,这一节我其实还特别想强调一点。
这门课教的从来不只是"怎么使用 Claude Code",我也希望你能真正掌握一套标准后端项目的基础组件清单,并理解每个组件为什么存在。
像线程池隔离、熔断重试、Cache-Aside、traceId 串联、统一参数校验、统一时间序列化,这些都不是"高级概念展示",而是生产级项目里非常实在的底层能力。
很多工程师工作几年,做的项目里这些东西都是现成的,自己从来没有从零搭过,于是知道名字,却说不清为什么要这样做、顺序该怎么排、参数为什么这么设。
而这一节的真正价值就在这里:
你不只是用 Claude Code 把 Hify 的基础组件搭起来了,你还顺手积累了一份以后做新项目时几乎可以直接复用的后端基础设施清单。
下一次你再开一个新项目,不管还用不用 Claude Code,这套三档优先级、每个组件解决什么问题、哪些先做哪些后做,你心里都会更有数。