不要只优化 Prompt,更要优化 Context。
Claude Code 很强大,这在前面的实践文章中我们已经验证过了,但与此同时,也有不少朋友说Token消耗过多,成本过高。
面对这个问题,很多人第一反应是:是不是Prompt写得太啰嗦了?
其实,很多时候真正"烧 Token"的,并不是输入的那句话,而是Claude背后带着的整段上下文。
它们可能包括:
- 之前的聊天记录
- 已经读取过的代码文件
- 工具调用输出
- 像
CLAUDE.md这样的记忆文件 - 系统或后台注入的额外指令
也就是说,当Token消耗越来越高时,问题往往不是Prompt不够简洁,而是上下文已经变得臃肿。
很多所谓的建议,比如"尽量缩短对话",当然没错,但太泛了,真正落地时帮助有限。
真正有效的做法,是搞清楚Claude Code的上下文是怎么构建的、哪些内容会被重复携带,以及工作流里有哪些"隐性成本"正在不断累积。
这篇文章我们来讲7个真正实用的方法,在不牺牲效率的前提下,尽可能降低Claude Code的Token开销。
1. 根据任务复杂度切换模型
这一点最简单、但也最容易被忽视:不是所有任务都值得用最贵的模型。
如果使用按API计费,不同的模型成本大概有几倍的差距;如果使用订阅方案,那么更重的模型也会更快消耗额度。
在执行任务时,可以做一个简单的分层:
- 日常任务:写测试、简单改代码、解释逻辑、常规重构
- 复杂任务:多文件架构设计、棘手 bug 排查、跨系统分析
- 轻量任务:查找、格式化、重命名、重复性操作
不同的任务采用不同的模型,像日常任务使用适中的模型即可,复杂任务则切换到能力更强,具备深度分析能力的模型,而且单纯的普通操作、机械性任务交给一般的低参数模型即可。
以国外模型为例:
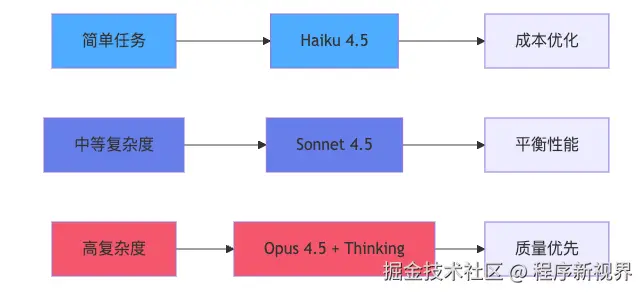
国内模型参考:
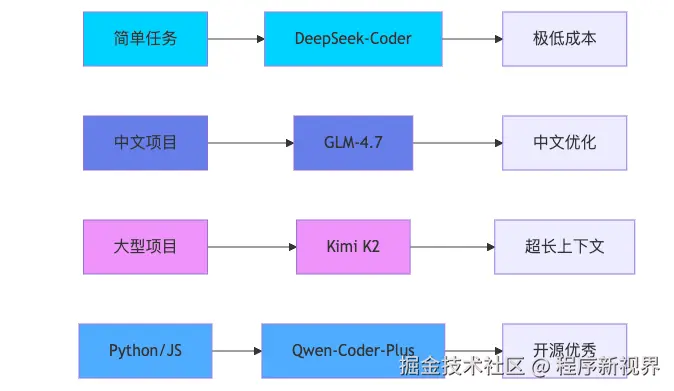
另外,不少人忽略了 /effort。
 对于一些本来就很直接的问题,适当降低 effort level,可以减少模型的"思考预算",从而直接降低输出 Token。
对于一些本来就很直接的问题,适当降低 effort level,可以减少模型的"思考预算",从而直接降低输出 Token。

一句话总结:模型能力要和任务复杂度匹配,不要让高性能模型去做低价值工作。
2. 把 CLAUDE.md 当"规则索引",而不是"百科全书"
如果你经常在每次对话里重复输入项目约束、开发规范、测试方式,那其实是在持续浪费 Token。这正是 CLAUDE.md 的意义所在。
在《使用Claude Code最需要做的一件事:与AI签订一份契约(CLAUDE.md)》一文中我们也有专门讲到。
CLAUDE.md会在Claude读取代码之前就被加载,而且会在整个会话过程中一直驻留在上下文里。
重点在于:它不是按需加载的,也不会轻易被"挤出去"。
这意味着什么?如果你的 CLAUDE.md 有 5000 Token,那么每一轮对话几乎都要为这 5000 Token 付费。
不管你本次会话只有 2 轮,还是 200 轮,它都会持续产生成本。
那么,适合放进 CLAUDE.md 的内容有哪些?
建议只放那些长期稳定、反复要用到的规则,比如:
- 项目如何运行测试
- 使用哪个包管理器
- 代码格式要求
- 关键架构约束
- 哪些目录不要碰
- 团队通用的开发约定
不建议放进去的内容
很多团队会把下面这些东西也一股脑塞进去:
- 会议纪要
- 设计演进历史
- 冗长的实现说明
- 临时性的任务背景
- 很长的业务文档
这些都不适合。
一个更好的原则是:
让 CLAUDE.md 像"速查手册",而不是"信息垃圾场"。
写得越精炼,长期收益越高。
3. 把啰嗦任务交给 Subagent,但别滥用
这是一个非常值得重视的技巧,因为它能从根本上改变上下文膨胀的方式。Claude Code 的 Subagent,本质上是一个独立上下文窗口中的 Claude 实例。
当你让 Subagent 去执行任务时,它产生的很多"过程性噪音"------比如:
- 文件检索
- 大段日志分析
- 多轮推理过程
- 中间步骤输出
当使用Subagent去执行任务时,可以避免上述噪声直接污染主会话。
最终回到主线程的,通常只是一个总结结果。这对于保持主上下文干净非常有帮助。
但这里也有一个常见误区:
Subagent 并不天然更省 Token。
如果只是处理很小的任务,比如简单 shell 操作、快速 git 命令,Subagent 往往反而更浪费。
因为它本身也有启动成本,包括:
- 子代理的初始提示
- 工具定义注入
- 额外的工具调用往返
- 独立上下文构建开销
所以,正确的使用原则不是: "所有事情都交给 Subagent。"
而应该是:
"只有当它节省下来的主上下文污染,足以覆盖启动成本时,再使用它。"
适合交给 Subagent 的任务,通常有以下特征:
- 输出会很长
- 检索范围较广
- 过程信息多但结果摘要短
- 不需要主线程保留完整过程细节
4. 明确指定文件和行号,别让Claude在仓库里"自由发挥"
很多 Token 浪费,根本不是因为 Claude 回答太长,而是因为你给它的任务太模糊,导致它要先花很多 Token 去"找问题"。
比如这类说法:
"你帮我看看 auth 相关代码哪里有问题。"
这听起来很自然,但在 Claude 看来,这基本等于:
- 去 repo 里搜一圈
- 打开多个相关文件
- 试图猜测你真正关心的点
- 还可能走很多弯路
如果问题实际上只在 1~2 个文件里,这种探索就是纯浪费。更好的写法应该像这样:
"请对比 src/auth/session.ts 第 30~90 行,和 src/api/login.ts 第 10~60 行,说明两者之间的逻辑不一致在哪里。"
这类表达有几个好处:
- 直接缩小搜索范围
- 减少无意义文件读取
- 降低模型重建上下文的成本
- 更容易得到准确结论
另一个容易被忽略的技巧:先用 Plan Mode
在执行一些可能成本较高的操作前,可以先切到 Plan Mode (Shift+Tab)。这个模式下,Claude 会先给出一个分步骤计划,而不会直接修改代码。
你可以先审核这个计划,把明显没必要的步骤删掉,再切回正常模式执行。
为什么这很重要?
因为实际使用中,最浪费 Token 的环节之一就是:试错式执行。
比如 Claude 先尝试一种方案,失败了;再试第二种;又报错;然后继续修正......每一次尝试、每一次报错、每一次迭代,都是在消耗 Token。
而提前规划,往往能大幅减少这种无效来回。
5. 主动使用 /compact,不要等"上下文快炸了"才想起来
很多人知道 Claude Code 有 /compact,但真正用得好的人并不多。原因通常不在于"会不会用",而在于用得太晚。

一个典型场景是:
- Claude 已经看过多个文件
- 跑过若干命令
- 试过几条错误方向
- 上下文里塞满了中间过程
这时候其实已经积累了很多"历史噪音"。而这些内容,对你接下来的任务未必还有价值。这正是最适合执行 /compact 的时机。
为什么要尽早 compact?
因为如果你拖到后面,等到Claude开始遗忘前文,出现上下文告警,回答质量变差时,才去压缩,那么此时的会话已经很"脏"了。
这时生成的摘要,往往也不够清晰、不够高质量。
相反,如果在会话还比较健康的时候就主动 compact:
- 关键信息更容易保留下来
- 无关细节更容易被清理掉
- 后续每一步都会更轻量
所以,/compact 的最佳用法不是"亡羊补牢",而是"定期保养"。
一个很实用的心法是:
当关键结论已经出来,而中间过程开始变多时,就该考虑compact了。
6. 优化之前,先用 /context 找到真正的"耗 Token 元凶"
很多开发者在发现 Token 消耗过快时,第一反应是改Prompt、缩短提问、减少对话轮次。这些当然可能有帮助,但很多时候你根本没打到重点。
因为真正昂贵的内容,未必是你当前看到的 Prompt。它可能是:
- 之前读入的超大文件
- 工具调用留下的大段输出
- 某个过重的记忆文件
- 某些集成工具带来的系统开销
这时候,/context 就非常关键。它相当于你的"上下文诊断面板"。

在大改工作流之前,先看一眼到底是谁在占用上下文,通常会更有价值。
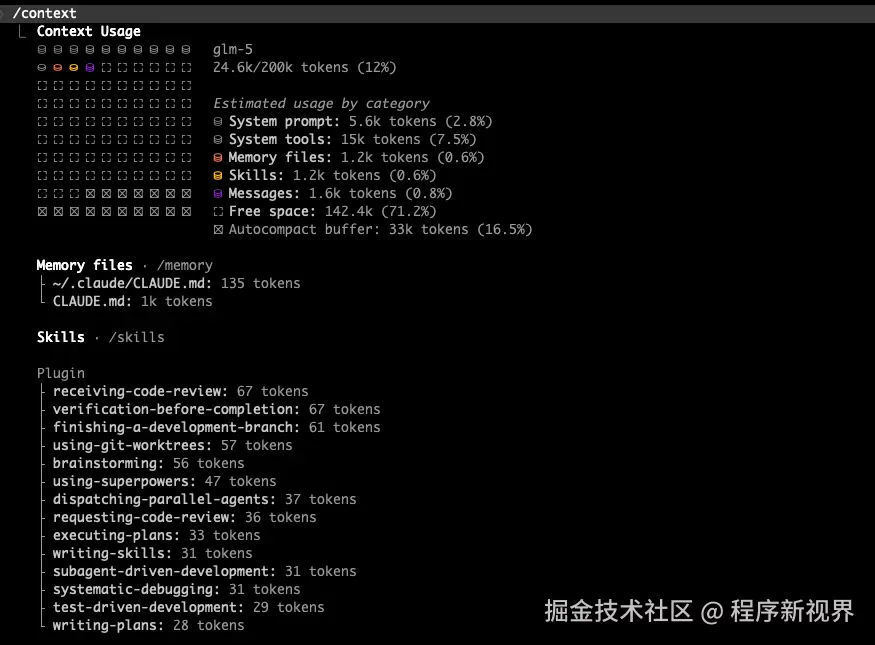
很多优化收益最大的场景,并不是你 Prompt 写得更精炼了,而是你终于发现:
有一个"沉默的大块头",一直在每一轮对话里默默消耗 Token。
所以,不要盲目优化。正确顺序应该是:
- 先检查
/context - 看看哪些内容被重复加载或重复携带
- 找出真正的臃肿来源
- 再有针对性地删减
先诊断,再优化。 这条原则在 Claude Code 里非常重要。
7. 工具链要克制,集成不是越多越好
Claude Code 可以接很多外部工具、数据源和辅助能力,这一点非常强大。但强大的另一面,是它也更容易把你的上下文结构搞复杂。
当工具接得越来越多时,模型可能需要额外处理:
- 工具定义
- 调用协议
- 上下文桥接信息
- 工具返回结果
- 多工具协同带来的额外说明
问题在于:很多任务根本不需要这么重的配置。
如果你把所有能接的技能、插件、辅助器全部挂上去,最后很可能出现一个尴尬局面:
任务很小,但系统开销很大。
因此,一个更稳妥的策略是:
- 只保留真正高频、刚需的工具集成
- 只接那些能持续解决重复问题的能力
- 不要因为"可以接"就全部接上
对 Claude Code 来说,精简的工具链通常比"全家桶式"集成更高效。
小结
真正该优化的,不只是Prompt,而是 Context Architecture。
如果只用一句话概括这篇文章,那就是:
降低 Claude Code Token 成本的核心,不是对每条 Prompt 精打细算,而是设计好你的上下文架构。
真正带来大收益的,通常不是"把一句话少写 20 个字",而是这些更本质的动作:
- 控制自动注入的上下文
- 缩小任务搜索范围
- 及时压缩会话
- 把高噪音工作隔离出去
- 避免不必要的工具链负担
说到底,Claude Code 的成本问题,本质上是一个上下文管理问题 。很多开发者只盯着 Prompt 在优化,但真正成熟的用法,应该开始转向另一层思考:不要只写 Prompt,要设计 Context。
以下是Claude Code系列其的他相关文章:
第1篇: 《国内环境下的Claude Code安装与使用教程》
第2篇:《使用Claude Code最需要做的一件事:与AI签订一份契约(CLAUDE.md)》
第3篇:《Claude Code实践:从零开始,一行代码不写生成一个项目》
第4篇:《Claude Code的Skills实践及利器推荐:工欲善其事,必先利其器》
第5篇:《6条Claude Code实践中的经验与思考》
第6篇:《 Claude Code的一次真实项目实践 》
第7篇:《 Claude Code在不同开发环节的应用案例分享 》