进程优先级
1.进程优先级是什么
对比优先级<->权限
- 权限:是能不能的问题;
- 优先级:已经能了,先后的问题。
优先级:进程在已经能得到某种资源的情况下,得到资源的先后顺序。
2.为什么要有
资源不足,需要分配资源,就要设置优先级:决定进程,获得资源的先后顺序。
3.Linux下,怎么设计的?
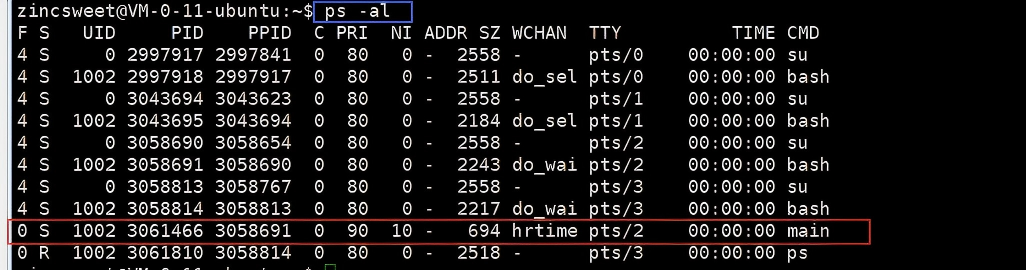
查看系统进程 :命令ps -l

- UID:对应此进程对应的用户编号,不同用户都有各自的编号;
- PRI :代表此进程可被执行的优先级,值越小越早被执行;
- NI :一个进程的nice值,优先级的修正数值。当nice值为负数,进程优先级将会变高,越快被进行。
所以,在Linux下,调整进程优先级就是调整进程的nice值,nice的范围是-20~19,一共40个级别。
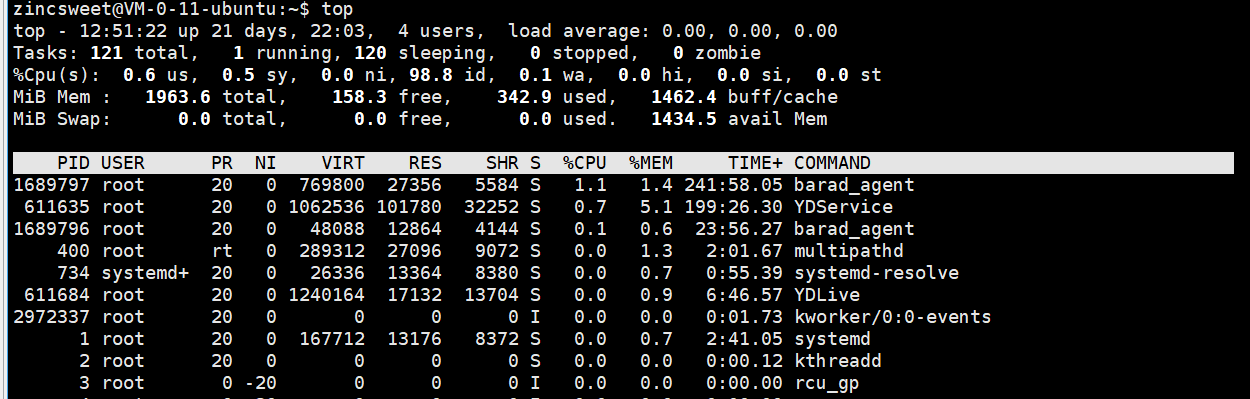
通过top命令,按r进入修改指定进程的nice值;将某进程nice值改变后观察:
优先级不能频繁更改。
注意 :通过nice值改动的PRI始终是PRI默认值(80)-nice值。比如当一开始对一个进程的nice值赋10,PRI变为90;第二次改nice赋值为-10,PRI变为70,而不是变回80。
4.nice范围
在修改某进程nice值的过程中,无论赋任何值,最终只能是在-20~19这个范围内;那么进程PRI范围只能是60~99。
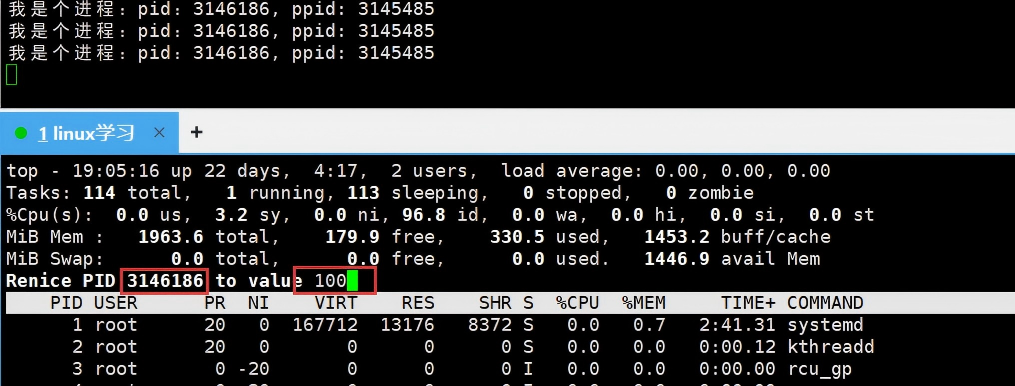
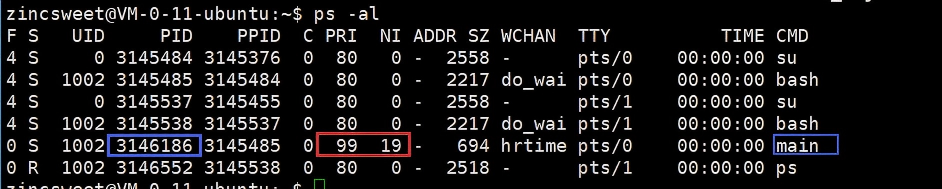
5.为什么优先级变化范围有限?
常见的操作系统Linux、windows等,都是分时操作系统。
分时操作系统:给进程分配时间片,相对公平、公正的调度策略,较为均衡地让不同的进程,都能得到CPU的资源。
所以:改变优先级就不能改变得太狠,就要控制范围。
补充:实时操作系统
与分时操作系统相对。
只有执行完一个进程后,才会去执行下一个进程,在工业运用中比较多。
6.其他修改优先级的命令
1)nice
nice -n <调整值> <命令/程序>
<调整值>:是在默认值0的基础上加减,比如-n 5就是把 nice 值设为0+5=5;普通用户:只能把 nice 值调大(降低优先级),范围0~19;root 用户:可以调小(提高优先级),范围-20~19.
注意:当运行完nice这个命令时,会自动启动对应的进程/程序。
# 示例1:降低优先级启动程序(普通用户也能做)
nice -n 10 ./main
# 示例2:提高优先级启动程序(需要root权限)
sudo nice -n -5 ./cpu_intensive_program
# 示例3:查看当前nice默认值
nice2)renice
renice <调整值> -p <PID>
<调整值>:指定最终的 nice 值;-p <PID>:目标进程的 PID;- 权限规则和
nice一样:普通用户只能调大(降优先级),root 可以任意调。
注意:修改的是已经在运行的进程的nice值。
# 示例1:降低某个进程的优先级(普通用户)
renice 15 -p 12345
# 示例2:提高某个进程的优先级(需要root)
sudo renice -5 -p 123457.补充概念
1)竞争性:CPU资源必然有限,进程必然众多,所以进程之间必然有竞争;
2)独立性 :多进程运行,需要独享各自的资源,进程间互不干扰;父子进程也有独立性!
3)并行 :多个进程在多个CPU下分别,同时进行运行,这称之为并行;(少见)
4)并发 :多个进程在⼀个CPU下采用进程切换 的方式,在⼀段时间之内,让多个进程都得以推进,称
之为并发。
进程切换
进程上下文:
1)作用 :进程切换 :保存旧进程上下文 → 加载新进程上下文,保证进程暂停后再恢复,能接着原来位置继续跑,不乱序、不丢数据。
2)包含三部分(了解):
- 用户级上下文:程序代码、数据、栈、全局变量、用户寄存器
- 寄存器上下文 (最核心):程序计数器 PC、栈指针、通用寄存器、状态字
- 系统级上下文:进程 PCB、内核栈、页表、内存映射、打开文件等内核信息
切换:
因为并发 特点,当进程进行切换,因寄存器是共享的,A进程运行时,将A的上下文存进寄存器中,当需要中途离开系统进行下一个B进程时,A进程将寄存器里的上下文剥离 ,存到A自己的task_struct中,然后B进程的上下文再存进寄存器中,运行B进程。
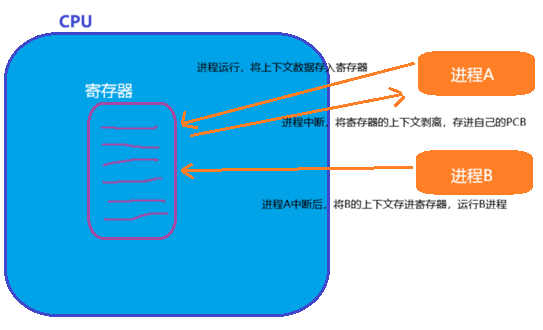
(时间片):当代计算机都是分时操作系统,每个进程都有它合适的时间片(其实就是⼀个计数
器)。时间片到达 ,进程就被操作系统从CPU中剥离下来。
组织进程
Linux是由c语言组织的,当创建一个结构体如下,它的地址怎么存的呢?
c
struct A {
int a;
int b;
int c;
double d;
};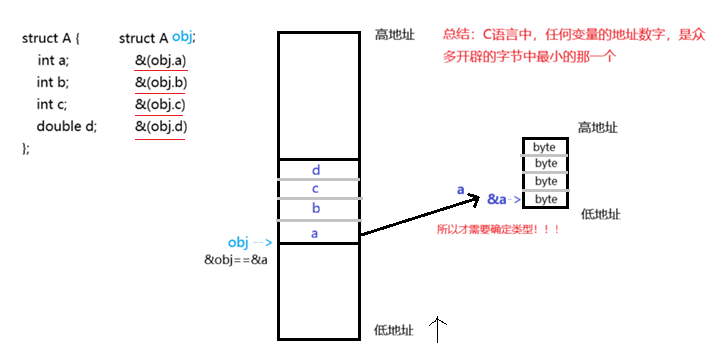
提出问题 :引用上面的结构体A,假如我知道一个对象的c成员 的地址,但是我不知道这个对象的地址,我要怎样求得这个对象的地址呢?
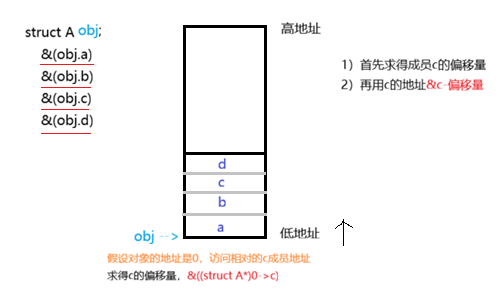
由此在进程之间可以重新设计一个双链表:
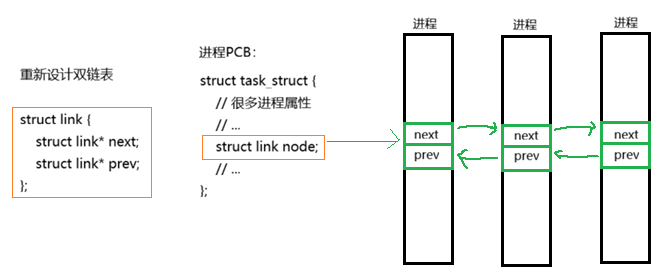
1)如何获取进程的其他属性?
刚刚展示的,由成员变量地址可以求出整体对象的地址。所以这里我们知道了成员变量链表节点的地址,自然能求得整个进程的地址,也就能访问该进程的其他属性;
2)为何如此设计?
增加链式管理的扩展性,其他地方也能用这种结构;代码只需要维护一份;
3)节点连接
当新的进程需要连接上来时,只需要insert这个link node。
4)进程都在哪?
Linux内核,会将所有进程的task_struct统一放在一张全局的双链表list_head task中;
5)进程不是也会在运行队列、阻塞队列吗?
当然,说明task_struct中,不仅有一套list_head task,还会有其他的链表,如:struct list_head run代表的就是运行队列的链表。这也就使得进程能在不同的队列链表中自由切换。
甚至,不同的结构体对象也能连接起来;
甚至task_struct里还能接不同的数据结构,红黑树、hash表等。
Linux的调度(运行)队列
每一个CPU都有一个调度(运行)队列:struct runqueue{};
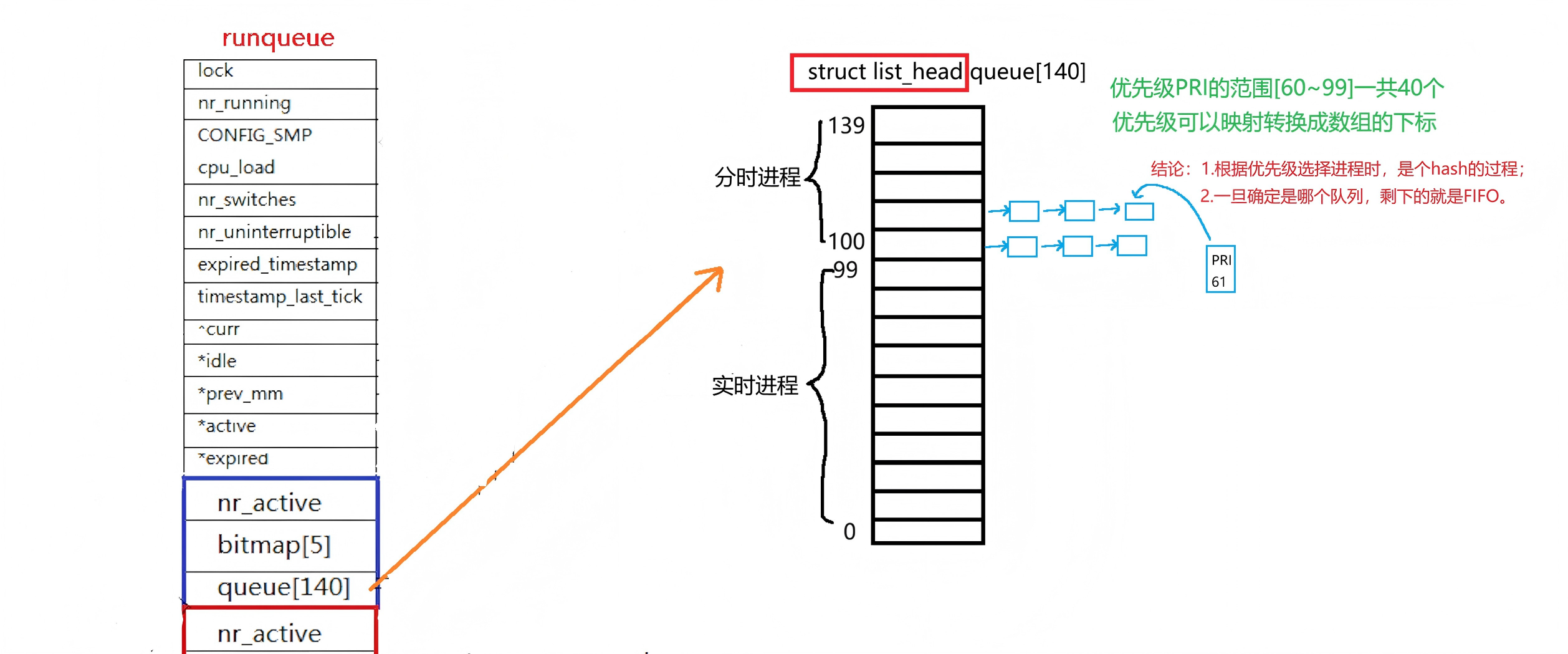
当系统要运行进程时,会在140个数组元素中找下标较小且非空的,然后在找到的元素中再看其中链表最靠前的,那一个就是要运行的进程。
那此时是需要去循环找到哪个元素吗?
不是的,Linux中,为了提高效率,采用了位图的方法检测:
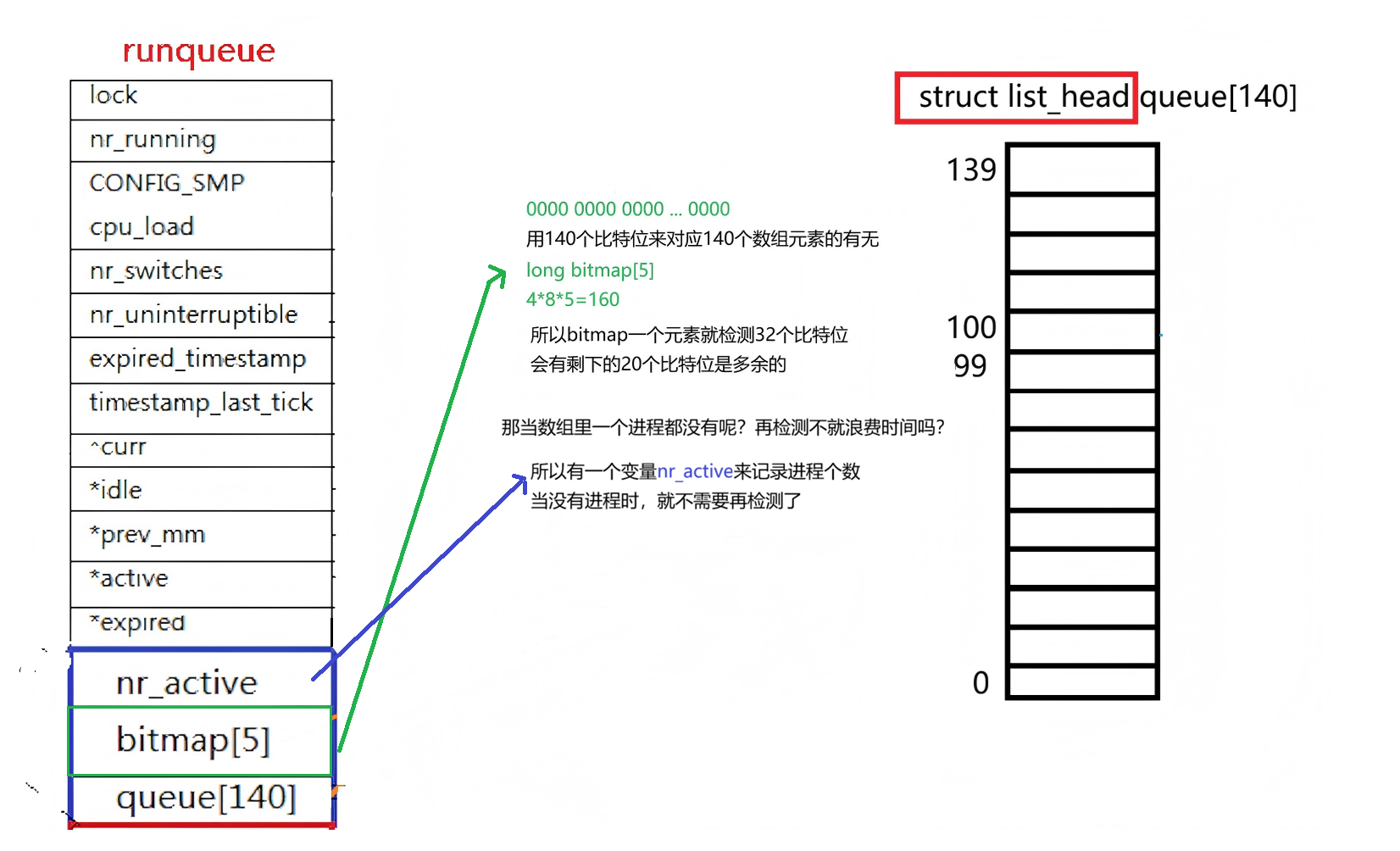
以上就设计出一个结构:优先级数组
c
struct prio_array_t {
int nr_active;
long bitmap[5];
struct list_head queue[140];
}问题:
1)假如系统中有一些进程优先级是61,然而不断的有优先级是60的进程加进来,那么61的进程就一直不运行了?
当然不是,因为这是个分时操作系统,会有时间片的限制。
2)那是将60的进程PRI变大吗?
也不是,因为将PRI变大,将优先级变底,不仅变得是PRI的数字,还要将进程的所在队列更改,成本大。
解决办法:
CPU的调度(运行)队列struct runqueue{};中会存在两个相同的优先级数组struct prio_array_t[2],一个是活跃队列 ,一个是过期队列 ,并且会有两个指针*active、*expired,各自指向一个队列。
任何运行的进程都是从活跃队列里拉出来的,当这个进程的时间片结束 了,这个进程会被放进过期队列中 的对应位置;当活跃队列为空时,两个指针指向将会调换,过期队列变成活跃队列,至此又来一轮进程的运行。
那么像问题(1)的现象,新来的60进程,不会直接接到活跃队列后面,而是接到过期队列后面,在下一轮过期-活跃对换时再运行60进程。
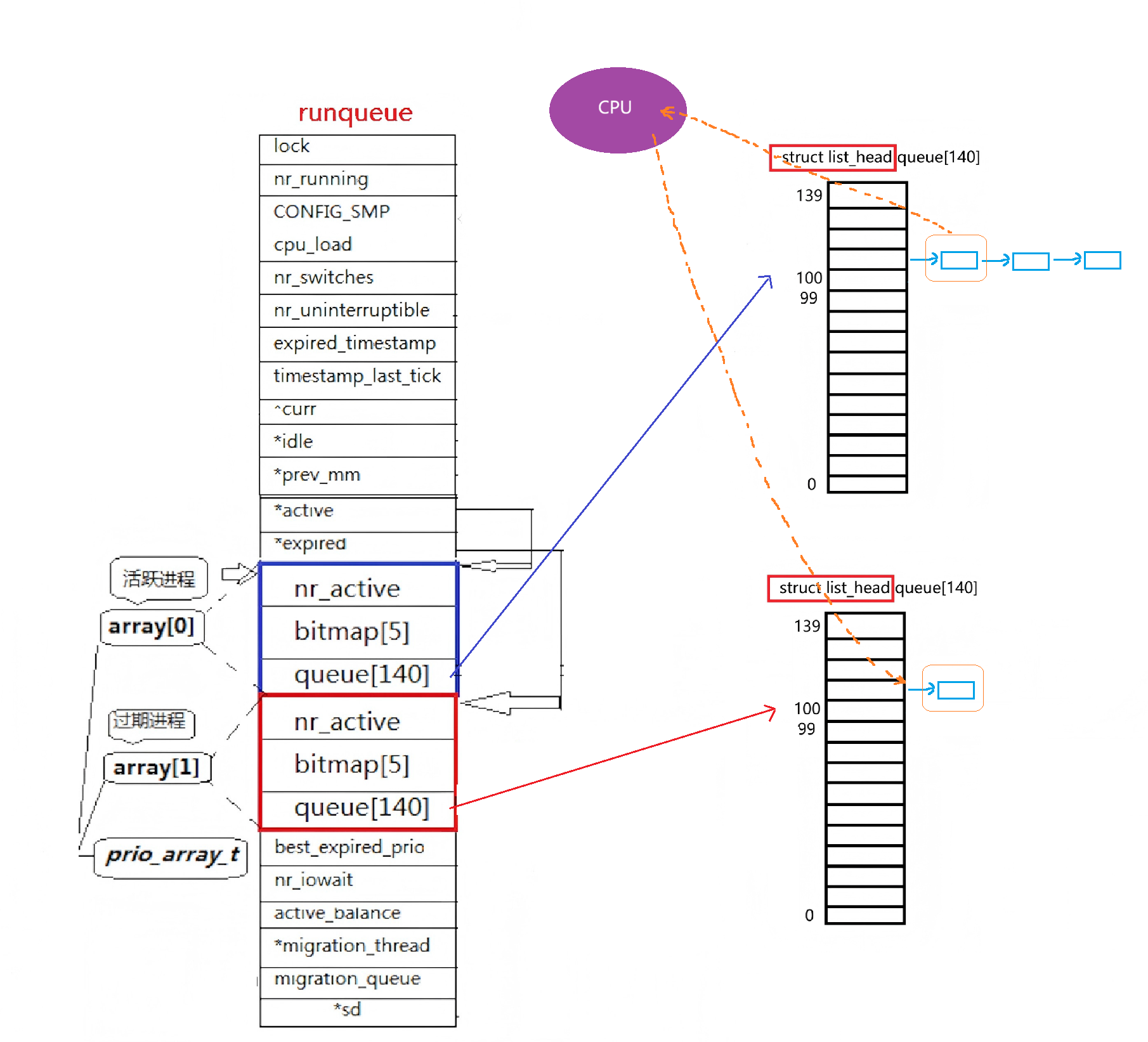
以上就是Linux进程队列的O(1)算法。