你好!你分享的 judicial-doc-anomaly-mcp 项目确实很有意思。它为法律专业人士和开发者提供了一个不错的起点。)千问3.6plus友情配图(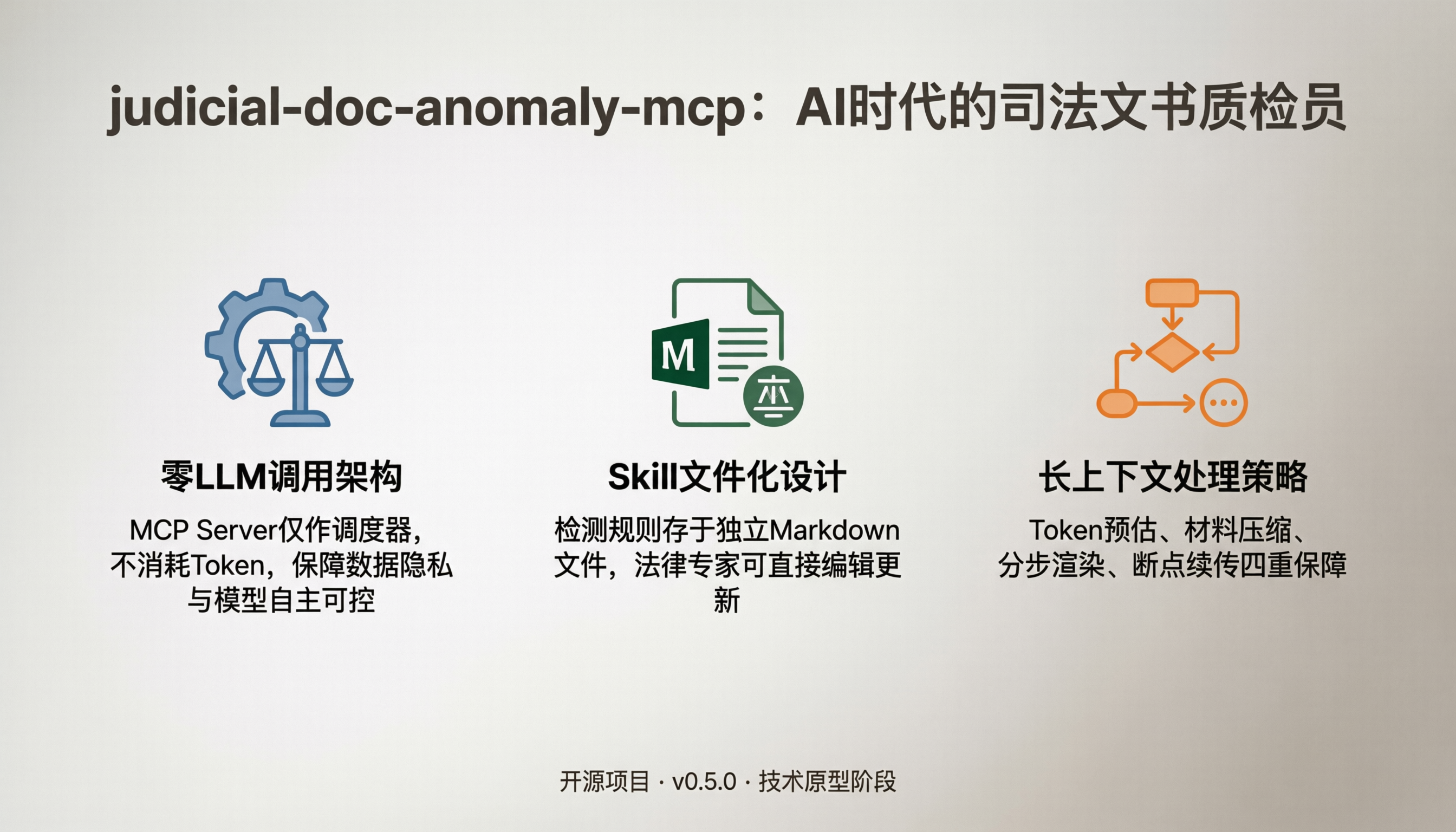
在开始详细的技术点评之前,有两点情况想先同步给你:
- 这是一个非常新的项目,目前仅有 2个Star和0个Fork,社区活跃度尚在起步阶段。
- 项目在一天内密集发布了 13个commits,正处于快速迭代的初期。
基于以上现状,我的分析会更多聚焦于项目的技术架构和创新理念。
📝 项目速览:AI时代的"司法文书质检员"
这个项目的核心定位是 AI Agent与司法文书审查之间的"桥梁" 。它通过一个MCP服务器,将结构化的Skills(检测技能) 分发给AI,并利用AI的推理能力对法律文书进行16个维度的全面"体检",最终生成结构化的异常检测报告。
项目目前虽处于v0.5.0早期版本,但其理念和架构已经非常清晰,尤其适合作为AI辅助法律领域的探索性项目和原型验证。
💡 核心亮点:三大架构优势
1. 巧妙的分层架构:轻量化与灵活性的平衡
项目最核心的设计是"零LLM调用"的桥接架构。MCP Server本身不直接调用任何大模型,而是作为纯粹的"调度器",负责加载和渲染Prompt、解析AI返回的结果。这种方式带来了两个显著好处:
- 轻量解耦:MCP Server几乎不消耗AI Token,降低了使用成本,且与具体的大模型提供商解耦。
- 自主可控:用户可以自由选择使用哪个大模型,并完全掌控整个分析过程。这确保了数据隐私和流程可控,对处理敏感司法文书至关重要。
2. 独特的Skill文件化设计:可进化的"业务知识库"
项目将所有的检测逻辑和规则都存储在独立的Markdown文件(Skills) 中。这意味着法律专家可以直接编辑、修改这些文件,来更新或增加检测规则,而无需改动任何Python代码。这实现了法律知识与代码的真正解耦,让项目能持续进化,更贴近实际业务需求。
3. 务实的长上下文处理策略
法律文书通常篇幅很长,对AI的上下文窗口是个巨大挑战。项目为此设计了完整的处理策略:
- Token预估 (
estimate_tokens):执行检测前,Agent可先预估任务所需的总token数。 - 材料压缩 (
compact_materials):当文档过长时,Agent可调用工具对原始材料进行压缩。 - 分步渲染 (
render_skill):通过将一个完整检测任务拆分为16个独立维度逐个渲染,避免了上下文的过度膨胀。 - 断点续传 (
pipeline_progress):记录检测进度,即使长任务中断也能恢复,避免重复工作。
🔧 待改进空间:从原型到产品的必经之路
1. 项目的"未完成"感
- 版本迭代痕迹 :项目中存在新旧架构并存的情况。例如,
prompts.py(Prompt模板)被标注为"兼容旧版",llm_caller.py(LLM调用器)被标注为"保留"。这表明项目正在进行架构演进,但尚未完成彻底的清理和统一。 - 文档位置说明 :目前仓库的文件结构和README描述并非完全一致。例如,README中提及的
skills/目录,其实际位置可能在src/judicial_lint_mcp/源目录内,而非项目根目录。这表明项目文档和实际结构还在同步调整中。
2. 可靠性、测试与安全挑战
- LLM依赖风险 :项目的检测质量完全依赖于外部LLM的稳定性和准确性,但LLM输出的非确定性和**"幻觉"问题**,在严肃的司法领域是巨大的挑战。
- 测试覆盖不足 :虽然存在
full_test.py和quick_test.py等测试脚本,但缺少全面的单元测试和集成测试,这对保证核心检测逻辑的可靠性至关重要。 - 安全机制缺失 :目前没有内置的身份认证 和访问控制机制,任何能连接到MCP服务器的Agent都可以调用其工具。对于处理敏感法律文件来说,这是一个必须补齐的短板。
💎 总结与展望
judicial-doc-anomaly-mcp 是一个技术理念新颖、架构设计精巧的开源项目,为AI+法律的细分场景提供了极具参考价值的开源方案。
尽管目前还处在早期阶段,但其"零LLM调用 "和"Skill文件化 "的核心理念,展示了未来AI辅助专业领域应用的可能范式。若能在规则化检测兜底、安全认证机制、生产级测试覆盖等方面持续完善,它将有潜力从一个优秀的原型,成长为法律科技领域真正实用的工具。对于关注AI Agent应用和"AI+法律"交叉领域的开发者来说,这是一个非常值得关注和研究的项目。