相信大家都有遇到:AI 助手在换会话、换工具、换机器后,信息全丢了。更重要的时,历史经验和踩坑教训无法被持续记住与复用,知识难以形成复利。
主流的 AI 编码工具,几乎都内置了"记忆"机制------Claude Code 有 CLAUDE.md、Cursor 有 Rules、Windsurf 有 Memories。普遍存在以下硬伤:
- 本质都是静态文件:人工维护,写进去就在那躺着,不会随项目演进而自我更新。
- 容量天花板很低:通常 200 行左右就开始臃肿,再塞就要么超 token,要么模型读不动。
- 检索方式很原始:要么整份全量塞进上下文,要么靠简单的 grep / 文件名匹配,召回质量看运气。
- 跨会话、跨工具不互通:在 Cursor 里攒下的经验,换到 Claude Code 就得重写一遍;同一个项目换台机器也接不上。
- 缺乏生命周期管理:没有衰减、没有去重、没有矛盾消解,时间一长就变成一堆相互打架的陈年笔记。
agentmemory 想解决的正是这一块------把协作过程中的事实、决策、踩坑沉淀下来,在下一轮按需召回。
它用检索 + 生命周期管理,把真正相关的上下文给到模型。同一套记忆服务可同时为 Claude Code、Cursor等多个客户端服务。

gitHub:github.com/rohitg00/ag...
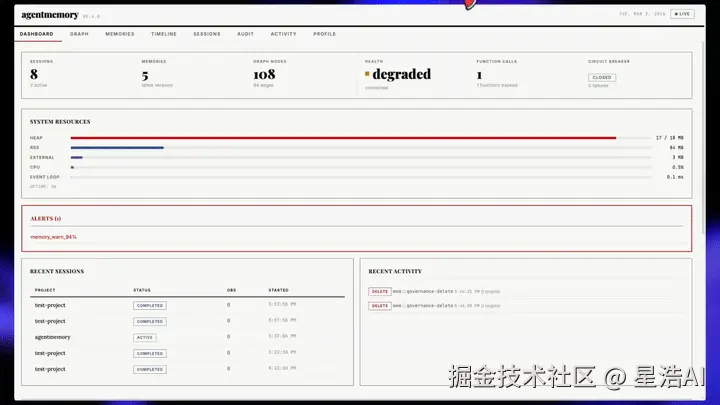
为什么要引入 agentmemory
引入它的价值:把一次性对话变成可复用资产:
- 自动沉淀上下文:把协作中的事实、操作痕迹、结论逐步落库。
- 新会话更快进入状态:按需召回相关记忆,减少重复解释。
- 跨客户端共享:同一套记忆可服务多种 Agent(通过 MCP/HTTP)。
- 降低协作损耗:把"口头共识"变成可检索、可追溯的信息。
- 提升迭代连续性:长期项目里,关键背景不容易随会话结束而丢失。
agentmemory 核心设计思路
它是一条可持续运转的记忆流水线。按开发视角看,核心就 4 步:
-
第一步:自动采集,不靠人手写
通过
SessionStart / PreToolUse / PostToolUse / Stop等 Hook 把真实协作过程记下来(你问了什么、工具做了什么、结果是什么),尽量减少"手动记笔记"这件事。 -
第二步:把原始日志加工成可检索记忆
原始观察先做去重、脱敏,再压缩成结构化条目(事实、结论、模式),并进入分层记忆(Working / Episodic / Semantic / Procedural),避免库里全是长日志。
-
第三步:检索走混合路线
召回时同时跑 BM25(关键词)、向量检索(语义)和图谱线索(实体关系),再做融合排序(README 提到 RRF)。这样既能命中专有名词,也能找回"意思相近"的历史经验。
-
第四步:记忆要有生命周期,不是只进不出
有衰减、遗忘、矛盾处理、版本/治理能力,目标是让旧经验逐步退场、有效经验保留。否则记忆越多,噪音越大,最后反而拖慢模型。
agentmemory 的架构定位是:一套独立记忆服务(MCP/HTTP),给多个 Agent 共享使用。
你可以在 Cursor 积累经验,再让 Claude Code 或其它 MCP 客户端直接复用,避免每个工具各管一份"孤岛记忆"。
这也是它和
.claude/ Rules 这类静态规则文件的分工:前者是动态记忆系统,后者是稳定约束文档。
快速上手
下面我以Claude Code 为例,带你走通全流程。
一键安装
打开终端,执行以下命令:
bash
npx @agentmemory/agentmemory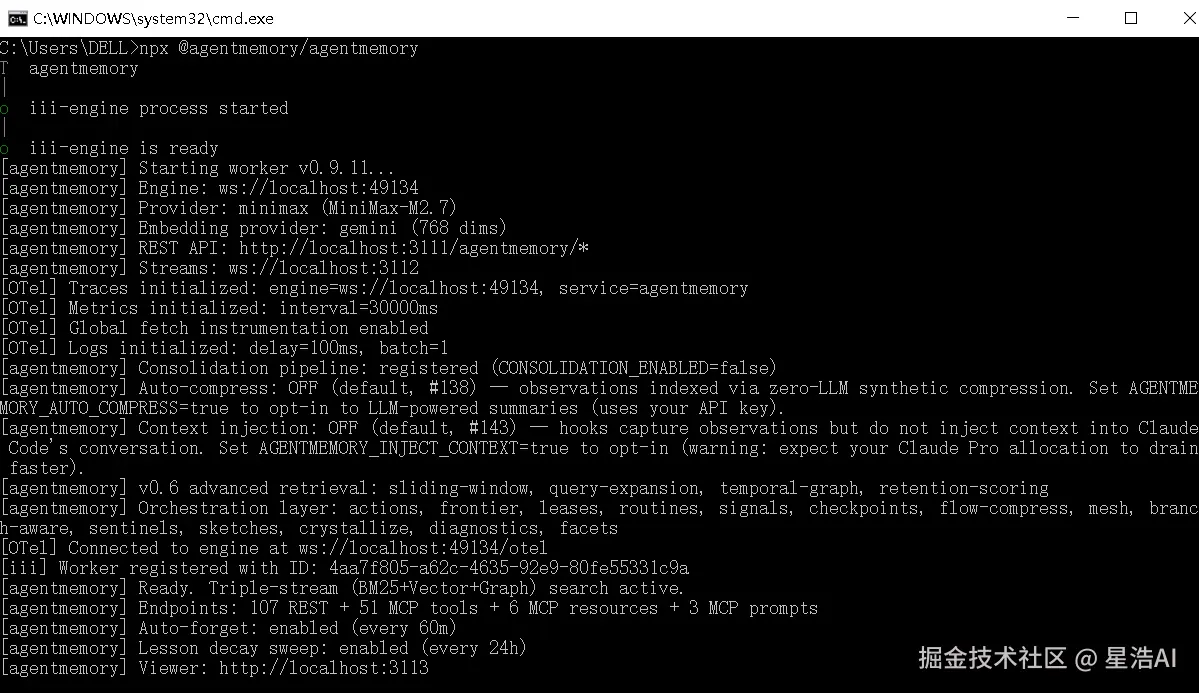
启动成功后,访问http://localhost:3113/
注意 :底层依赖 iii-engine 运行时环境;
Windows 安装不成功:未安装 iii-engine
如果运行 npx @agentmemory/agentmemory 时提示缺少 iii-engine(版本要求 v0.11.2)
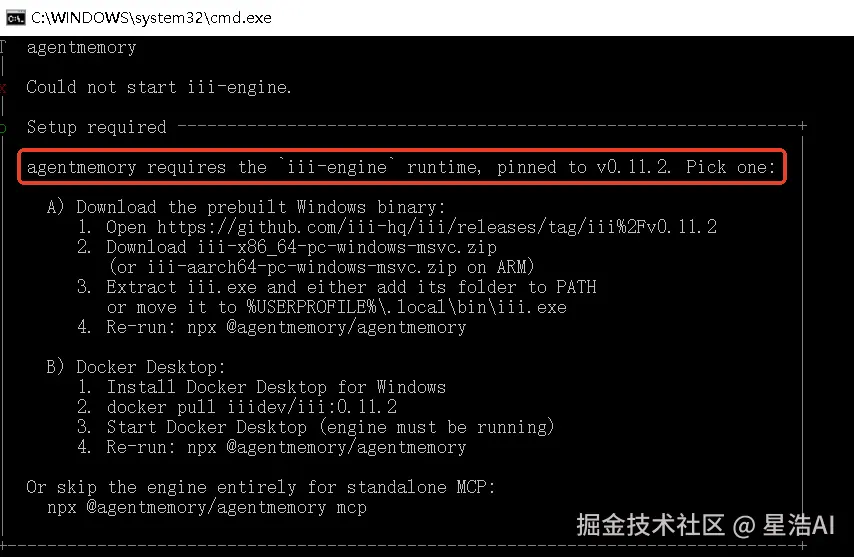
可以按下面步骤处理:
- 下载并安装 iii-engine
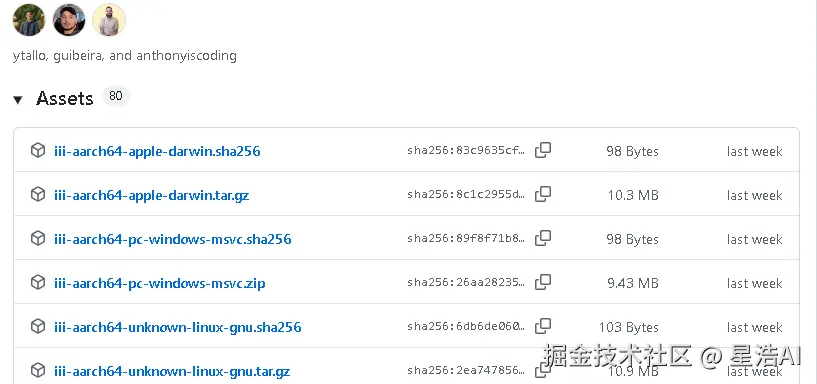
- 打开发布页:github.com/iii-hq/iii/...
- 在 Assets 中下载对应系统的压缩包(例如 Windows 常见为
iii-x86_64-pc-windows-msvc.zip)。
-
解压文件
- 解压后可得到
iii.exe可执行文件。
- 解压后可得到
-
配置环境变量
- 将
iii.exe所在目录加入系统PATH环境变量。
- 将
-
验证安装
bash
iii --version看到版本号后,说明安装成功。然后再次运行:
bash
npx @agentmemory/agentmemorycc 安装插件/配置MCP
在Claude Code的聊天窗口中执行以下命令:
- 从官方市场添加 agentmemory 插件
bash
/plugin marketplace add rohitg00/agentmemory- 安装 agentmemory 插件
bash
/plugin install agentmemory安装完成后,插件会自动完成所有配置:
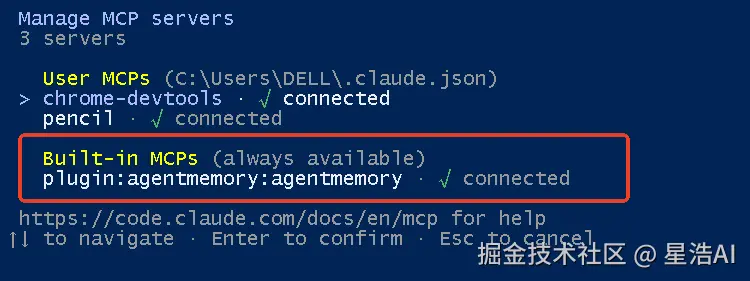
-
注册全部12个生命周期钩子,实现自动捕获。
-
通过其自带的 .mcp.json 配置文件,自动将 @agentmemory/mcp 这个MCP服务器连接到Claude Code。
-
获得全部51个MCP工具。
-
验证是否成功
访问 http://localhost:3111/agentmemory/health,页面上输出JSON字符串,表示成功。
Cursor配置MCP
Cursor : ~/.cursor/mcp.json
添加配置内容:
json
{
"mcpServers": {
"agentmemory": {
"command": "npx",
"args": ["-y", "@agentmemory/mcp"]
}
}
}体验官方 demo
agentmemory 提供了 demo,方便我们快速体验记忆检索的能力。执行命令如下:
bash
npx @agentmemory/agentmemory demo命令执行完毕截图:
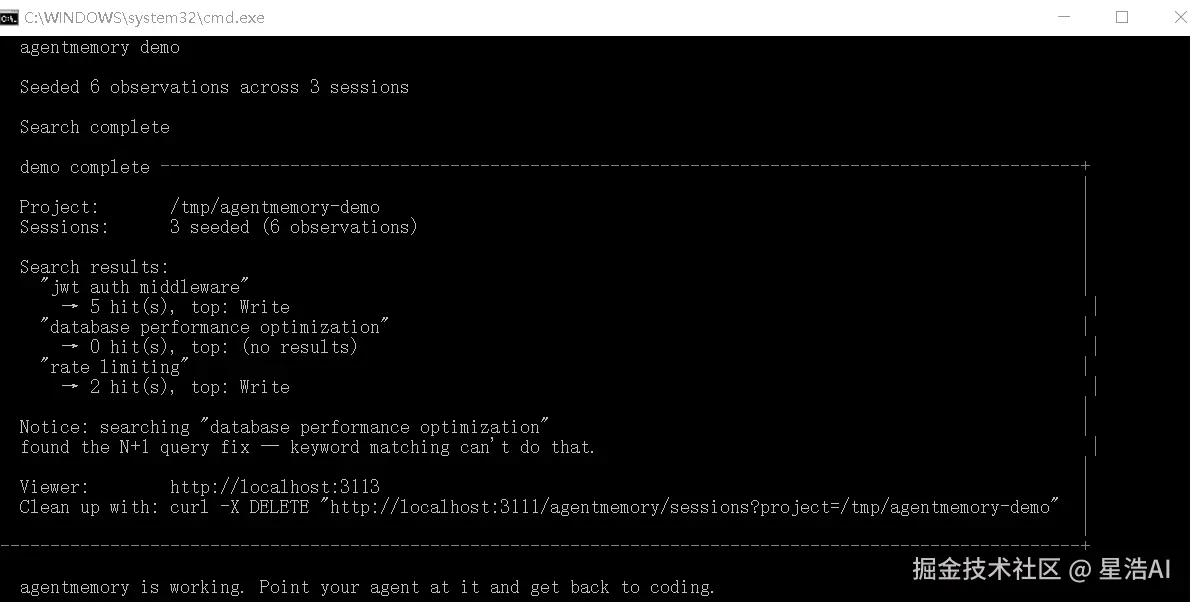
现在,你的 agentmemory 演示已经顺利跑通了!🎉
从终端输出的日志来看,我们发现:
-
演示成功:
成功在 3 个会话中植入了 6 条观察记录。
-
搜索功能正常:
比如搜索 "jwt auth middleware" 命中了 3 条结果,"rate limiting" 也成功找到了对应记录。
-
语义理解亮点:
日志里特别提到,当搜索 "database performance optimization"(数据库性能优化)时,虽然关键词没有完全匹配,但它依然找到了 "N+1 query fix"(N+1查询修复)的相关内容。
-
可视化界面
在浏览器中打开 http://localhost:3113,可以直观地查看刚才演示生成的记忆和会话数据。
导入历史会话
如果你一直使用 Claude Code 进行 vibe coding ,那么你可以将积累的历史会话导入,充实你的记忆库。
typescript
# 导入默认路径(~/.claude/projects)下的所有历史会话
npx @agentmemory/agentmemory import-jsonl
# 或者导入单个指定的会话文件
npx @agentmemory/agentmemory import-jsonl ~/.claude/projects/f--cc-work-GraphRAGAgent/06e5b5fd-8876-47c6-97f2-bafb9f7c5aa5.jsonl导入进来的 JSONL 会走和实时会话同一套流程:先做去重和隐私脱敏,再压缩成可检索条目并建索引。处理完后,在 Viewer 的「会话回放」里能看到这些导入记录;检索时和新建会话走同一套逻辑,不区分来源。
实战技巧
agentmemory不仅"能记住",更在于"记得好、找得准、管得精"。
优化检索效果
- 启用本地嵌入模型
官方文档中提到: 1.自动检测:
安装 @xenova/transformers 后,agentmemory 会自动切换到本地模型 all-MiniLM-L6-v2(免费、离线、隐私友好)。
根据官方文档,支持的 embedding 提供商如下:
| Provider | 模型 | 费用 | 备注 |
|---|---|---|---|
local |
all-MiniLM-L6-v2 |
免费 | 默认;离线可用、隐私友好 |
gemini |
text-embedding-004 |
免费 tier | 1500 RPM |
openai |
text-embedding-3-small |
$0.02/1M tokens | 质量最高 |
voyage |
voyage-code-3 |
付费 | 代码场景优化 |
cohere |
embed-english-v3.0 |
免费试用 | 通用场景 |
openrouter |
视所选模型而定 | 视模型而定 | 多模型代理;可选用 Qwen 等 embedding 模型 |
若只要本地免费模型且隐私优先,使用默认即可,也可显式设置:
Create ~/.agentmemory/.env
env
EMBEDDING_PROVIDER=local若使用openai,则需要额外配置API_KEY:
env
EMBEDDING_PROVIDER=openai
OPENAI_API_KEY=sk-...走 OpenRouter 使用 Qwen 等任意兼容模型时,将 EMBEDDING_PROVIDER 设为 openrouter,并配置 OPENROUTER_API_KEY;模型 ID 与其它可选变量以 README 中 Embedding 小节为准。
2.效果提升:
相比纯 BM25(关键词检索),召回率提升 +8 个百分点
bash
npm install @xenova/transformers-
问法里带上「能对上代码」的词
只问「上次图片上传怎么弄的」;不如把组件名、文件名、包名、路由、中间件写进问题里,更容易和当初落库时的用词撞上。
-
召回不对,先用 Viewer 对一下三路结果
在
http://localhost:3113打开 Viewer,用同一句话再搜一次,看 BM25、向量、图谱各自回了什么。看清短板后再改提问:缺专有名词就补锚点,缺场景就把「要干什么」说具体。
记忆生命周期
agentmemory 内置了记忆生命周期管理能力,包含:基于时间的衰减、基于重要性的评估、矛盾检测与消解、自动归档与删除。
- 主动标记
遇到重要决策时,可使用 /remember 技能或 memory_save 工具,为该条记忆手动赋予高重要性。
- 审查"低置信度"记忆
可在实时查看器中,筛选出置信度低的记忆,进行删除或修正它们。
- 合规清理
利用memory_governance_delete将包含敏感信息进行合规清理。
多智能体协作:团队记忆与信号机制
在团队协同开发时,记忆共享非常重要,同事1解决的难题,同事2可以直接复用。
按项目隔离:命名空间
默认以项目路径当命名空间。路径一致、连到同一套记忆服务的助手,记忆才共享。
团队共享 vs 个人私有
可以通过 MCP 里的 memory_team_share 工具,将有价值的记忆标记为"团队共享"。 团队成员用 memory_team_feed 能拉到近期共享内容。
租约 + 信号:减少硬冲突
租约与信号是解决多智能体"冲突"的关键。
memory_lease 工具可以让一个助手对文件资源加锁,在锁释放前,不允许被修改。
memory_signal_send / memory_signal_read 允许助手之间发送简单的状态消息或通知。
建立团队记忆规范
-
统一项目路径
团队成员在本地克隆项目时,使用相同或能映射的相对路径,它是命名空间匹配的基础。
-
定义共享原则
适合共享的:架构决策、公共组件怎么用、踩过的坑和解决方案。
不适合共享的:尝试性解决问题的方法
-
善用"行动项"管理
memory_action_create和memory_frontier可以创建和追踪待办事项。
通用设置
- 环境变量配置
ini
# 将每次会话注入的上下文Token上限从2000提高到4000
export AGENTMEMORY_MAX_CONTEXT_TOKENS=4000
# 将工作记忆的存活时间从5分钟延长到30分钟
export AGENTMEMORY_WORKING_MEMORY_TTL=1800
# 控制知识图谱中保留的最大实体数量,防止图谱膨胀
export AGENTMEMORY_MAX_GRAPH_ENTITIES=5000- 配置文件配置 在项目根目录创建
.agentmemory/config.json文件进行更细致的控制:
json
{
"retrieval": {
"bm25_weight": 0.4,
"vector_weight": 0.4,
"graph_weight": 0.2,
"results_per_session": 2
},
"compression": {
"target_compression_ratio": 0.3
}
}通过上面配置,调整混合检索中各项的权重,或者控制压缩的激进程度。
性能调优
记忆条数上来以后,体感问题通常集中在两类:搜得慢 、占内存多。下面按现象拆,具体参数名仍以仓库 README / iii 文档为准。
-
检索变慢
对于超大型项目(数万条记忆),可以考虑启用更高效的向量索引,需要在启动引擎时配置
iii-engine的参数。 -
内存占用偏高
调整
AGENTMEMORY_WORKING_MEMORY_TTL,让工作记忆更快地被压缩和归档。同时,定期使用memory_consolidate工具手动触发记忆巩固,可以释放活跃内存。 -
偏代码仓库:更信字面匹配
对于纯代码项目,可以增加 BM25 的权重(
bm25_weight),因为代码中的精确匹配(函数名、变量名)往往比语义更重要。
小结
agentmemory 把协作过程中的事实、决策、踩坑 变成可检索、能随项目演进、还能跨会话 / 跨工具复用的知识,存入记忆中,并形成知识复利。
agentmemory 具备零侵入集成能力和卓越的检索能力,无须改变你的AI编程习惯,在你需要的时候,默认默认为你提供相关上下文。