
前面几篇已经完成了项目的基础运行层:
objectivec
域名
服务器
K3S
Dockerfile
GHCR
GitHub Actions
ConfigMap / Secret
CLS 日志采集到这里,项目已经有了一条完整上线链路:
arduino
代码合并到 release
↓
GitHub Actions 构建 Docker 镜像
↓
推送到 GHCR
↓
SSH 登录服务器
↓
更新 K3S Deployment
↓
浏览器访问域名
↓
CLS 查看线上日志这说明基础运维层已经跑通。
但这个项目的目标不是普通网站,也不是普通 AI 聊天页面。
接下来真正要做的是:
复刻一个轻量版 Agent 执行链路。
1. 为什么不是简单 AI 聊天页面?
如果只是做一个普通 AI 聊天页面,链路很简单:
输入框
↓
调用模型接口
↓
返回文本
↓
页面展示这种方式当然也是 AI 应用。
但它没有体现 Agent 系统的核心过程。
我想复刻的是公司智能体项目里的执行链路:
rust
用户输入
↓
创建 Agent Run
↓
Agent Runtime 执行
↓
模型分析
↓
模型返回 tool_call
↓
服务端路由 Tool
↓
Tool 内部执行多个 Skill
↓
Tool Result 回填模型
↓
模型继续生成最终答案
↓
SSE 推送执行过程
↓
前端 Timeline 展示也就是说,前端不是只等最终答案,而是要看到 Agent 执行过程。
比如:
agent_start
model_text_delta
tool_call_start
skill_start
skill_result
tool_call_result
final_answer_delta
agent_done这才是 Agent Console 的核心。
2. 重新拆分后续能力层级
运维链路跑通后,我重新梳理了项目目标。
后续能力拆成三层:
MVP 必须层
进阶运行层
高阶平台层
3. MVP 必须层
MVP 的目标是先跑通 Agent 核心链路。
包含:
创建会话
创建消息
创建 Agent Run
返回 runId
前端用 runId 建立 SSE 订阅
Agent Runtime 执行
模型分析
Tool 调用
Skill 执行
SSE 推送 AgentEvent
前端 Timeline 展示
Run 详情页复盘
数据库落库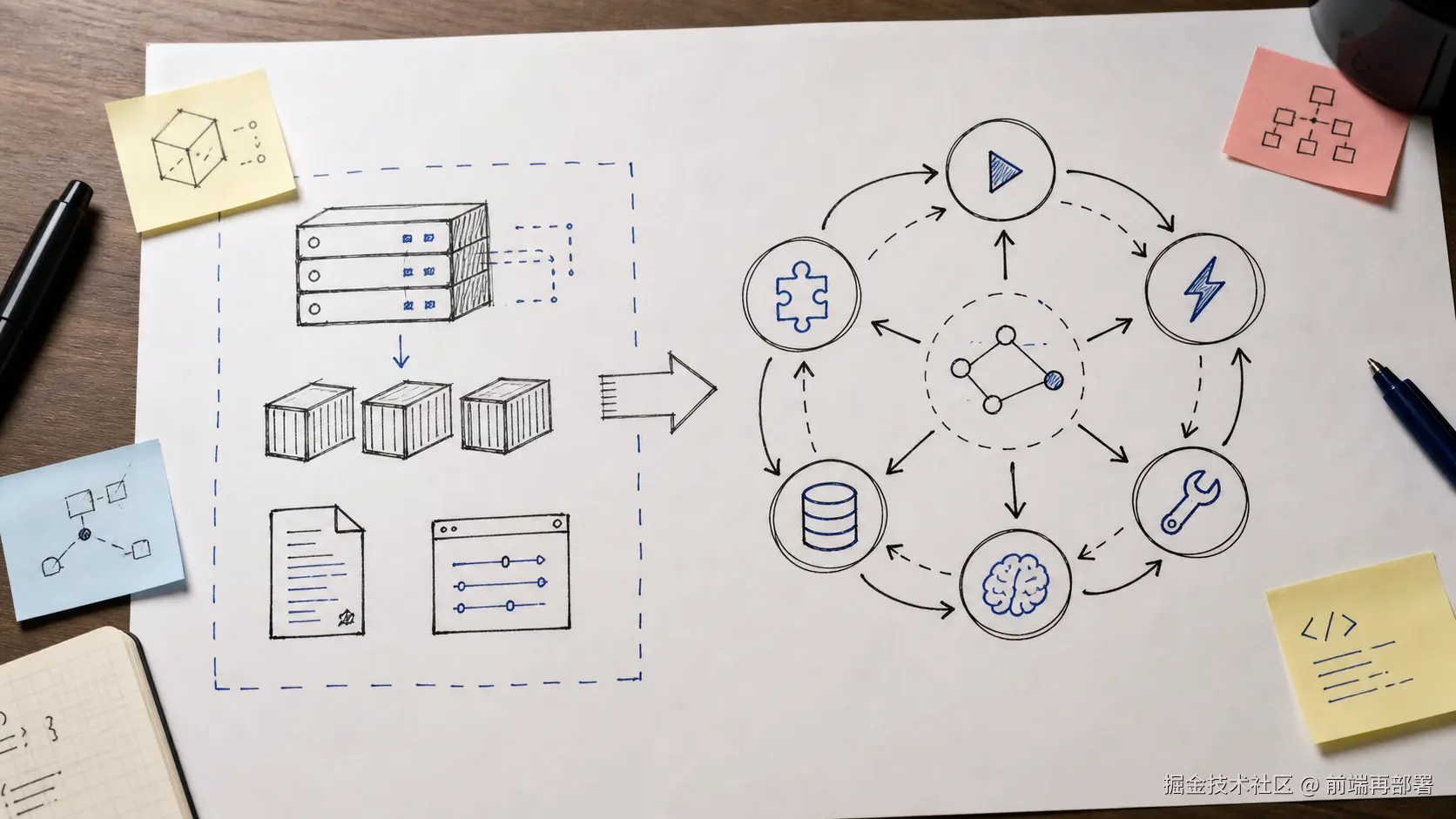 这一层不追求生产级完整。
这一层不追求生产级完整。
但必须做到:
链路能跑
状态能看
事件能推
过程能复盘
代码能讲清楚4. 进阶运行层
MVP 跑通后,再考虑进阶能力:
objectivec
NSQ 异步任务
Redis SSE Replay
上下文管理
多 Tool 动态调用
Retry / Cancel / Timeout
更完整的状态机这些能力更偏生产化运行。
比如 NSQ 可以把 Agent 执行从 HTTP 请求中解耦出去。
Redis SSE Replay 可以缓存一次真实 SSE 流,用于后续回放和 debug。
5. 高阶平台层
更后面的高阶能力包括:
vbnet
Nacos 配置中心
Coze Loop / Trace
Tool 和 Skill 配置后台
可视化 Workflow
RAG
Memory
多模型 Adapter这些是平台化能力,不放进第一阶段。
否则很容易一开始就陷入平台化幻想。
当前最重要的是:
先把 Agent 的核心执行链路跑通。
6. 为什么第一版不直接接真实模型?
MVP 阶段,我没有直接接真实大模型。
原因是变量太多。
如果一开始同时做:
真实模型调用
Tool Calling
Skill 执行
SSE 展示
状态机
数据库落库
Run 详情页一旦出问题,很难判断是哪一层的问题。
可能是:
模型没有按预期返回
tool_call 格式不对
参数 schema 校验失败
服务端状态没有流转
SSE 数据格式不对
前端解析有问题
数据库落库异常所以第一步先做 mock Agent Runtime。
7. Mock Agent Runtime 做什么?
Mock Agent Runtime 不依赖真实模型。
但它模拟一次完整 Agent 执行:
生成 runId / traceId
输出 agent_start
输出 model_text_delta
输出 tool_call_start
执行两个 mock Skill
输出 skill_start / skill_result
输出 tool_call_result
输出 final_answer_delta
输出 agent_done这样可以先验证系统骨架。
前端验证:
SSE 连接
流式输出
Timeline 渲染
Tool / Skill 状态展示服务端验证:
AgentEvent 协议
状态流转
事件推送
日志输出
数据库落库Run 详情页验证:
一次 Agent Run 能否被复盘等这些基础链路稳定后,再接真实 LLM。
8. 用计划文档控制边界
为了避免项目越做越大,我新增了三份计划文档:
bash
docs/plans/mvp-agent-core-plan.md
docs/plans/advanced-agent-runtime-plan.md
docs/plans/platform-agent-capability-plan.md它们的作用是控制边界。
每做完一步,就在 checklist 里打勾。
这样可以避免做着 MVP,突然跑去做 Nacos、Coze Loop、RAG 或可视化 Workflow。
当前阶段只关注:
Agent 核心链路
AgentEvent
SSE
Timeline
Tool / Skill
Run 详情页9. 运行底座和业务内核
从 CLS 日志采集结束,到正式开始做 Agent,其实是一个阶段切换。
前面做的是运行底座:
项目怎么上线
项目怎么发布
项目怎么配置
项目怎么采集日志现在做的是业务内核:
Agent 怎么创建任务
Agent 怎么执行
Agent 怎么调用工具
Agent 怎么展示过程
Agent 怎么复盘
Agent 怎么落库运行底座保证项目能上线。
业务内核决定项目有没有真正价值。
10. Agent Console 的意义
做 AI 项目不能只盯着模型接口。
模型接口只是一个能力点。
真正的 Agent 系统还需要回答这些问题:
一次请求怎么变成一次 Run?
Run 的状态怎么流转?
每一步过程怎么变成 AgentEvent?
事件怎么通过 SSE 推给前端?
前端怎么展示 Timeline?
执行结束后怎么复盘?
日志、数据库和 runId 怎么串起来?如果只是调用一次模型接口,模型回答错了,很难判断原因。
但如果有完整 Agent 执行过程,就可以判断:
prompt 是否没写清楚
模型是否没正确选择工具
tool_call 参数是否错误
Skill 输出是否不合理
最终回答是否偏离工具结果
前端是否解析错误这就是 Agent Console 的价值。
它不是为了炫技,而是为了让 Agent 执行过程可观察、可复盘、可调试。
11. 下一步:双接口结构
接下来,我会从原来的"一个聊天接口"改成更接近真实项目的双接口结构:
bash
POST /api/conversations/messages
GET /api/agent/runs/:runId/events第一个接口负责:
创建或复用 conversation
创建 message
创建 Agent Run
处理 clientRequestId 幂等
返回 conversationId / messageId / runId第二个接口负责:
基于 runId 建立 SSE 连接
订阅这次 Agent Run 的执行事件
推送 AgentEvent从这一步开始,这个项目就不再只是一个聊天页面。
而是开始进入真正的 Agent Runtime 实现。