上一篇我写了 Codex 怎么参与 Good Plan 的开发过程。
那篇文章里,我真正想说的不是"Codex 帮我写了多少代码",而是另一个感受:AI coding 真的进入项目以后,最考验人的地方,往往不是写代码本身,而是问题定义、任务拆解和结果验证。
写完以后,我觉得还缺一篇更具体的文章。
因为对很多会写代码的人来说,真正卡住的可能不是"Codex 有没有用",而是怎么把它放进一个稳定的工程流程里。
是不是直接说一句:
帮我做一个 XX 系统。它当然会动起来。
但这也是很多新手第一次用 AI coding 工具时最容易踩的坑。
不是因为 Codex 不够强,而是因为它太容易开始了。
你还没有讲清楚项目是什么,边界在哪里,哪些地方不能动,什么结果算完成,它就已经可以生成一堆看起来很完整的代码。
所以这篇文章不写安装教程,也不做工具广告。
这篇我想写得更具体一点:我在 Good Plan 里试用 Codex 时,是怎样围绕 Superpowers 和 OpenSpec,把一个模糊需求先问清楚、写成规格、再小步实现和验证的。
我的建议很简单:
第一次用 Codex,不要急着让它写代码。先让它理解项目、理解问题,再让它小步推进,最后一定让它拿证据交付。
这里先交代两个工具。
Superpowers 的地址是:
arduino
https://github.com/obra/superpowers它的 README 里把自己定义成一套给 coding agents 使用的软件开发方法论,建立在一组可组合 skill 和初始指令之上。它的核心思路不是让 AI 更快开写,而是让 AI 在写代码前先停下来:问清楚需求、形成设计、拆计划、用 TDD 推进、完成前验证。
OpenSpec 的地址是:
arduino
https://openspec.dev/它负责的是另一层:把一次变更写成规格。也就是先把 proposal、design、tasks 和 spec deltas 整理出来,让人和 AI 在写代码前先对齐"这次到底要改什么"。
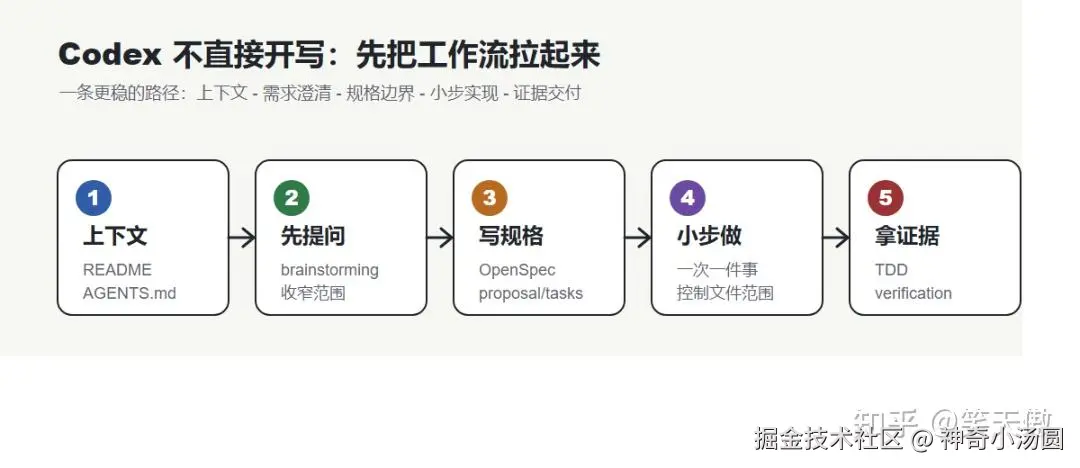
所以这篇文章真正想讲的,不是单独介绍 Codex,也不是单独介绍某个 skill,而是我试用下来更顺的一套组合:
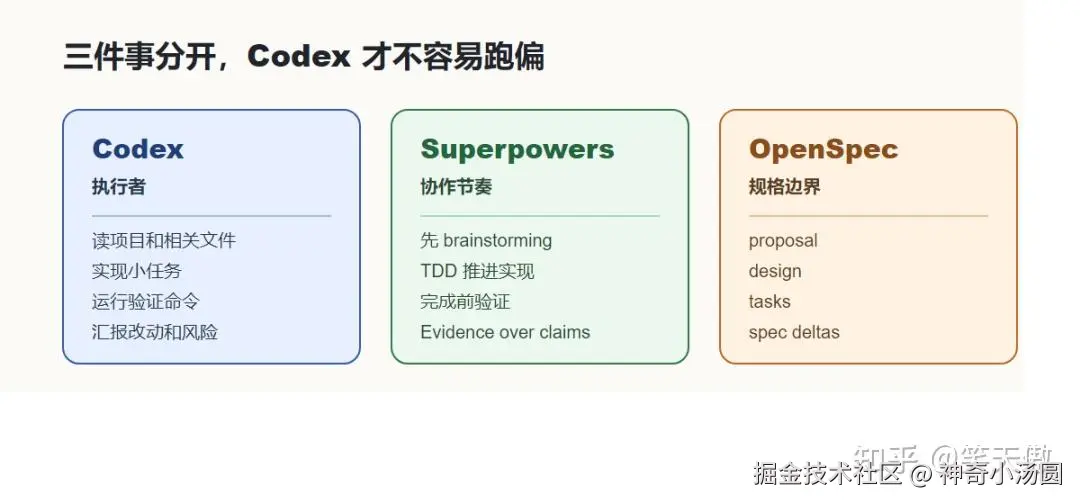
Codex 负责执行,Superpowers 负责协作节奏,OpenSpec 负责规格边界。
第一个误区:把 Codex 当成更快的代码生成器
很多人第一次用 AI coding 工具,最自然的反应是把它当成一个升级版代码生成器。
以前我们搜代码片段,后来用 ChatGPT 问一个函数,现在有了 Codex,就想直接让它在项目里改文件。
这个变化当然很大。
但问题也在这里。
当 Codex 可以直接读项目、改代码、跑命令、修错误时,它已经不只是"帮你写一段代码"了。它在参与你的工程过程。
如果你给它的只是一个很大的、边界模糊的目标,比如:
帮我加一个积分系统。它可能会真的开始做。
它会找数据库模型,找接口,找前端页面,补一些字段,写一些逻辑,也许还会顺手加一点 UI。
从表面上看,这很爽。
你一句话,它动了一堆文件。
但如果你没有提前说清楚这些问题,后面就会很麻烦:
•积分是谁的积分?
•什么行为会增加积分?
•积分能不能扣减?
•重复操作怎么算?
•管理员能不能手动调整?
•有没有历史记录?
•第一版是不是只做最小闭环?
这些问题如果人不说,Codex 也会补答案。
只是那些答案不一定是你真正想要的。
这就是 AI coding 新手最容易踩的坑:不是它不干活,而是它太能干活了。
需求还没想清楚,代码已经铺开了。
边界还没定义,文件已经改了十几个。
验收标准还没说,页面已经看起来能用了。
所以我现在更愿意把 Codex 当成工程搭档,而不是代码打印机。
搭档的意思是:它可以帮你推进,但你要先告诉它方向、边界和完成标准。
第一步:先让 Codex 理解项目上下文
如果你第一次在一个项目里用 Codex,我建议不要马上说需求。
先让它理解项目。
很多人会在提示词里写:
你是一个资深工程师。这句话不是完全没用,但用处有限。
真正重要的不是它扮演什么身份,而是它知道自己现在站在哪个项目里。
拿 Good Plan 来说,它后来已经不是一个单页 Demo。
它是一个 pnpm monorepo,里面有后端、前端和共享类型:
•packages/server:NestJS + Prisma 后端。
•packages/web:Vue 3 + Vite + Tailwind 前端。
•packages/shared:前后端共享枚举和常量。
项目里还有 docs/prd、docs/test、openspec、tests/api、tests/checks、tests/e2e 这些目录。
如果你第一次让 Codex 进入这样的项目,最好不要只说"帮我改功能"。
Good Plan 的 AGENTS.md 里就写了很多具体约束:
•所有 AI 回复、文档、注释和提交信息默认使用简体中文。
•后端是 NestJS,所有 API 路由前缀是 /api。
•family 模块路径是 /api/family,不是 /api/families。
•业务枚举统一从 @good-plan/shared 导入,不从 @prisma/client 导入。
•NestJS 的 @Post() 默认返回 201,不是 200。
•孩子登录用 /api/auth/login 加 {nickname, password},没有独立端点。
•本地验证可以跑路由检查、角色检查和 API 场景测试。
这些规则看起来很细。
但它们会直接决定 Codex 写出来的代码是不是贴合项目。
如果没有这些上下文,它可能会按自己熟悉的习惯生成接口路径,可能会从错误的包里导入枚举,也可能会把 201 当成异常情况去修。
这类问题不一定是 Codex "不会写代码"。
很多时候只是它不知道项目里的约定。
一个好的 AGENTS.md,不是写几句客气话,而是告诉 Codex:
•这个项目是做什么的。
•技术栈是什么。
•目录怎么分工。
•常用启动、测试、检查命令是什么。
•哪些文件可以改,哪些文件不要随便动。
•具体业务和技术约定是什么。
•完成后要怎么验证。
你可以把它理解成项目给 AI 协作者看的入职文档。
人接手一个老项目,第一件事也不是直接写代码,而是看 README、看目录、看现有风格、看测试怎么跑。
Codex 也一样。
我现在比较常用的第一句话是:
请先阅读 README、AGENTS 和相关目录,不要马上改代码。读完后用 5 条以内总结这个项目的结构、规则和你认为需要注意的边界。这句话的重点不是"总结"。
重点是"不要马上改代码"。
先让它读一遍项目,它后面的判断才更像是在这个项目里工作,而不是从外面空降一套想当然的方案。
第二步:用 brainstorming,把需求问清楚
上下文有了以后,也不要急着让 Codex 开工。
尤其是当你的需求还只有一句话时。
比如:
帮我做一个奖励系统。这句话对人来说已经能懂大概意思。
但对工程来说,它还不够。
奖励系统是给谁用的?谁创建奖励?谁兑换奖励?兑换后要不要审核?积分不足时怎么处理?奖励会不会下架?是否需要库存?第一版要不要做通知?
这些问题不问清楚,Codex 也可以写。
但写出来以后,你很可能会发现:它做了一个"奖励系统",却不是你家里、你项目里、你当前阶段真正需要的那个奖励系统。
所以我在第三篇里提到过 brainstorming。
在 Good Plan 这种项目里,我把它理解成一句话:需求没想清楚时,先让 Codex 提问和收窄范围,不要直接写代码。
这个词听起来像头脑风暴,容易让人以为是在发散创意。
但我自己的理解更简单:
brainstorming 是让 Codex 先陪你把需求问清楚。
它不是为了聊得更热闹,而是为了在动手之前回答几个问题:
•这个需求解决什么真实问题?
•谁会使用它?
•第一版必须做什么?
•哪些东西只是看起来不错,可以先不做?
•什么结果算完成?
•哪些已有流程不能被破坏?
所以比起直接说:
帮我给项目加一个积分系统。我更推荐这样开始:
我们先不要写代码。请先和我一起梳理积分系统的使用场景、角色、边界和第一版范围。一次只问我一个问题,直到需求足够清楚。这句话有几个关键点。
第一,先不要写代码。
第二,一次只问一个问题。
第三,目标不是发散,而是收窄到第一版范围。
这对新手很重要。
因为 AI coding 最大的诱惑,就是让你误以为"开始写"就是"开始推进"。
但很多时候,真正的推进发生在写代码之前。
你把问题讲清楚了,后面的实现才会稳。
你没讲清楚,后面的代码越多,返工越多。
第三步:用 OpenSpec 把需求拆成规格和任务
需求问清楚以后,下一步也不是马上让 Codex 改代码。
我会先让它进入 SDD,也就是 Spec-Driven Development。
这一步听起来有点像流程负担。
尤其是个人项目里,很容易觉得:就我一个人,写什么计划,直接改不就行了。
以前我也常这样。
但 AI 参与以后,我越来越觉得,规格不是为了显得正式,而是为了防止 Codex 跑偏。
一个好的计划至少要说清楚三件事:
第一,这次改什么。
第二,这次不改什么。
第三,怎么判断它完成了。
比如你要做积分系统,计划里应该写清楚:
•这一版只支持完成任务后增加积分。
•暂时不做积分商城。
•暂时不做管理员手动调整。
•要补一条积分变更记录。
•要有测试证明重复打卡不会重复加分。
•前端只展示当前积分,不做复杂统计。
这样 Codex 后面写代码时,就不会顺手把商城、排行榜、成就系统一起加进来。
你也更容易审查它的结果。
OpenSpec 的定位就是轻量级 spec-driven framework。它会围绕一次变更生成 proposal、design、tasks 和 spec deltas,让人和 AI 在写代码前先对齐"这次到底要改什么"。
在 Good Plan 里,这部分就落在 openspec/changes/archive 下面。
比如:
•2026-03-05-good-plan-mvp
•2026-03-06-reward-shop-enhance
•2026-03-06-habit-reminder-system
•2026-04-04-mobile-app-mvp
•2026-04-05-multi-mode-growth-system
这些目录不是为了好看。
它们是在记录每一轮变化的 proposal、设计取舍、任务拆解和规格变化。
不一定每个个人项目都要写很重的规格文档。
但至少要有一个轻量版本:
•背景是什么。
•目标是什么。
•范围是什么。
•不做什么。
•任务怎么拆。
•验收标准是什么。
我会这样说:
请按 OpenSpec / SDD 的方式,先为这个需求整理一份轻量规格:背景、目标、范围、不做什么、任务拆解和验收标准。先不要动代码。Good Plan 后来能一轮一轮推进,也是因为每次都尽量先说清楚这一轮要解决什么。
先做 MVP,再补奖励商店,再补习惯频率,再补提醒系统,再补移动端和质量门禁。
它不是一次生成出来的。
它是一轮一轮被推进出来的。
这个节奏对 Codex 很重要。
任务越清楚,它越像工程搭档。
任务越模糊,它越像一个很勤快但方向不稳定的执行者。
第四步:小步实现,每次只让它推进一件事
有了计划以后,才进入实现。
这时新手还会遇到一个诱惑:既然 Codex 能干,那就让它多干一点。
比如一次性说:
把后端接口、前端页面、测试、文档都一起做完。不是绝对不行。
但对第一次使用 Codex 的人,我不建议这样。
因为改动范围一大,你就很难判断每一步到底发生了什么。
后端模型改了,接口改了,前端状态改了,路由改了,测试也改了。
一旦报错,你不知道问题出在数据结构、接口返回、页面调用,还是测试本身写错了。
这时候 Codex 也许能继续修。
但你会越来越被动。
我更推荐小步推进。
比如:
这次只实现后端积分记录,不改前端页面。完成后告诉我修改了哪些文件,以及怎么验证。或者:
这次只接前端展示,不改后端接口。如果发现后端接口不够用,请先说明缺口,不要直接扩展接口。再比如:
请不要顺手重构无关代码。如果发现无关问题,单独记录,不要混在这次修改里。这些提示看起来啰嗦。
但它们会帮你保住节奏。
AI coding 不是让你一次性把项目扔出去,然后等它带回来一个成品。
更稳的方式是:每次只让它推进一块,然后你检查、验证、确认,再进入下一步。
这和以前人写代码其实很像。
好的工程师也不会在一个提交里同时改业务逻辑、UI 样式、数据库结构、构建脚本和无关重构。
Codex 只是让这种纪律变得更重要。
因为它动手太快了。
你不给边界,它真的会帮你把很多东西一起动了。
第五步:用 TDD 和验证收尾
如果这篇文章只能留下一个提醒,我希望是这一句:
Codex 写完代码,不等于任务完成。
这是我做 Good Plan 时很深的感受。
AI 可以很快写出页面、接口、状态和测试。
但系统是不是真的能用,不能只看代码有没有生成。
页面能打开,不代表业务流程跑通。
没有报错,不代表没有问题。
接口返回 200,也不代表权限、角色、数据状态都正确。
第三篇里我提过,Good Plan 曾经修过一些很典型的问题。
有些页面跳到了不存在的路由,结果空白。
有些家长创建完习惯后,被带到了孩子视角页面,调用了不该调用的接口。
还有一些 catch 把错误吞掉,页面看起来没崩,但实际上用户什么也做不了。
这些问题最麻烦的地方,不是它们报错很吓人。
恰恰相反,它们有时候不吓人。
它们只是让系统看起来"好像没坏"。
所以后来我越来越重视验证。
这里对应的是 Superpowers 里的两类 skill:test-driven-development 和 verification-before-completion。
前者强调 RED-GREEN-REFACTOR:先写失败测试,确认失败,再写最小实现让它通过。后者对应 Superpowers 里的"Evidence over claims":没有新鲜的验证证据,就不要轻易说完成。
TDD 对我最大的提醒,不是"你必须写很多测试",而是顺序:
先说清楚什么行为算对。
如果是修 Bug,最好先写一个能暴露问题的测试,确认它失败。
然后再做最小修改,让测试通过。
最后再整理代码。
你可以这样要求 Codex:
请先补一个失败测试,证明当前问题存在。测试失败后,再做最小修改让它通过。如果不是严格 TDD,至少也要让它在完成前给出证据。
比如:
请运行与这次修改相关的最小验证命令,并把结果告诉我。如果不能运行,请说明原因。或者:
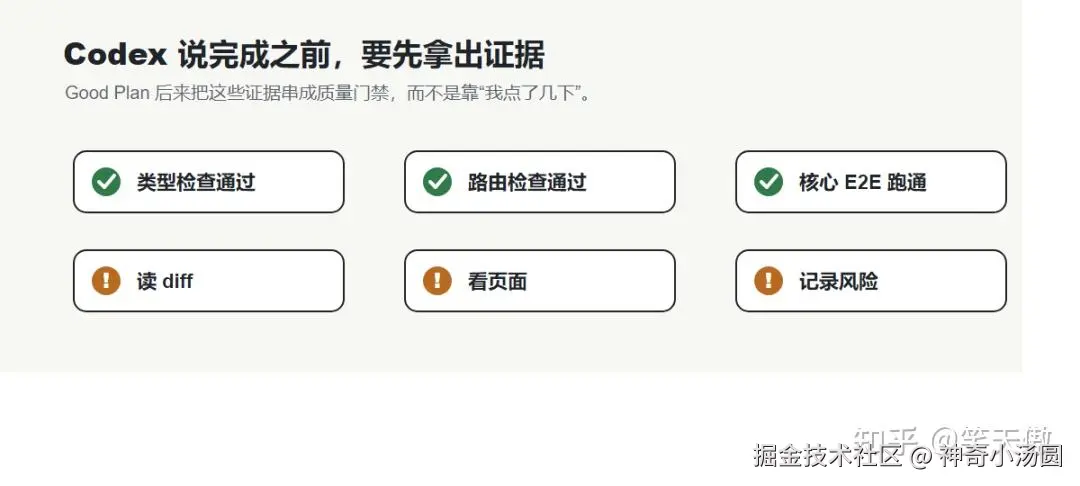
不要只说"已完成"。请告诉我:你做了什么、验证了什么、还有什么风险。在真实项目里,这些证据可以包括:
•类型检查是否通过。
•单元测试或接口测试是否通过。
•路由检查是否通过。
•浏览器里核心流程是否跑通。
•这次修改有没有影响已有页面。
•哪些地方还需要人工复核。
Good Plan 后来有一条质量门禁命令,把类型检查、路由检查和 E2E 串起来。
命令本身不神奇。
真正重要的是心态变化:
以前我可能会问:"这个功能写完了吗?"
现在我会多问一句:"有什么证据说明它写完了?"
用 Codex 的最后一步,不是感谢它写完代码。
而是要求它交出证据。
给新手的一套最小流程
如果你是第一次用 Codex 做项目,我建议先别追求复杂玩法。
就按下面这 5 步来:
第一步,写清项目上下文。
至少准备好 README 和 AGENTS.md。告诉 Codex 项目是什么、技术栈是什么、目录怎么分工、常用命令是什么、哪些边界不能碰。
第二步,用 Superpowers 的 brainstorming 先讨论需求。
不要一句话直接开写。让 Codex 先问你问题,把用户、场景、边界、第一版范围和验收标准问清楚。
第三步,用 OpenSpec / SDD 写规格和任务。
让它先列出这次改什么、不改什么、怎么拆任务、怎么验证。规格确认后再实现。
第四步,小步实现。
每次只推进一件事。尽量控制文件范围,避免一次性改后端、前端、移动端、测试和文档。
第五步,用 Superpowers 的 TDD 和 verification 收尾。
让 Codex 跑相关命令,说明验证结果。你自己也要读 diff、看页面、跑关键流程。最后确认的不只是代码,而是业务结果。
这套流程刚开始会显得慢。
尤其当你看到 Codex 几秒钟就能改一堆文件时,会觉得前面的讨论、计划和验证有点磨人。
但我现在越来越觉得,这个"慢"是值得的。
因为它减少的是后面的返工。
它让 Codex 的速度用在正确的方向上。
Codex 没有降低专业要求
很多人讨论 AI 编程时,会自然走向一个问题:
程序员是不是不重要了?
我自己的感受刚好相反。
Codex 的确能写很多代码。
但它没有替你决定真实问题是什么。
它没有替你决定第一版做多大。
它没有替你决定哪些取舍符合当前项目。
它也不会天然知道某个结果是不是真的能交付。
这些判断仍然在人这里。
只是程序员的专业能力,开始往两端移动。
往前,你要更会定义问题。
不是只说"做个功能",而是能讲清楚用户、场景、边界和成功标准。
中间,你要更会拆任务。
不是一次性把所有东西扔给 AI,而是把需求拆成能独立实现、独立验证的小步骤。
往后,你要更会验结果。
不是看它有没有写代码,而是看它有没有通过测试、跑通流程、留下证据,还有没有隐藏风险。
这可能才是会写代码的人第一次用 Codex 最该练的东西。
不是怎么让它多写一点。
而是怎么让它在正确的问题上,小步写,写完验,验完再继续。
如果说以前的程序员更多是在和代码本身较劲,那么 AI coding 之后,我们要更多地和问题、边界、证据较劲。
Codex 可以成为一个很强的工程搭档。
但前提是,你不能把方向盘也交出去。
第一次用它,不要急着让它写代码。
先让它理解你正在做什么。
再让它理解你真正要解决什么。
最后,让它用可验证的结果证明:这一步,确实走对了。