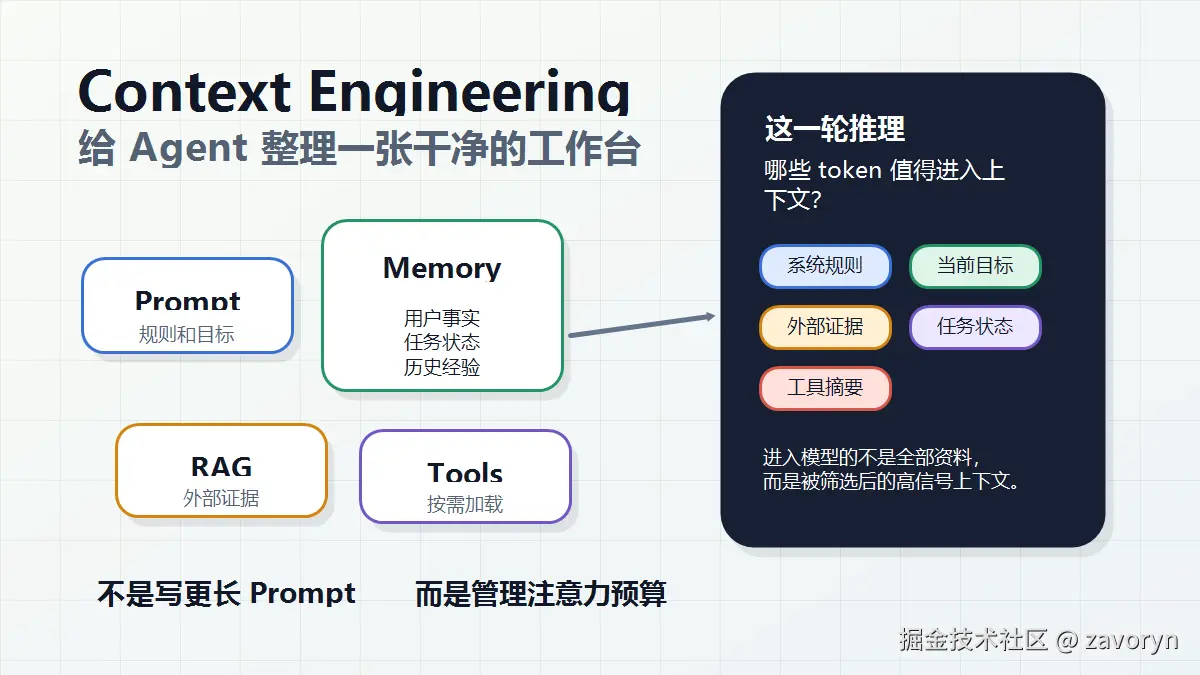
Context Engineering 不是写更长 Prompt,而是管理 Agent 的注意力预算
过去很多大模型应用的问题,都被归因到"Prompt 没写好"。
回答不稳定,是 Prompt 没写好;工具用错了,是 Prompt 没写好;RAG 幻觉了,还是 Prompt 没写好。
但做 Agent 做久了会发现:真正难的不是写一句神奇提示词,而是每一轮推理时,到底应该把哪些信息放进上下文。
用户历史要不要放?工具返回要不要放?RAG 检索出来的 10 个 chunk 要不要全放?上一次失败的原因要不要放?系统规则、代码文件、日志、网页、数据库结果,谁优先?
这就是 Context Engineering。
一句话讲:Prompt Engineering 关注"怎么说",Context Engineering 关注"让模型看见什么"。
为什么上下文窗口不是越大越好?
很多同学第一次做 RAG 或 Agent,容易有一个朴素想法:
既然模型靠上下文回答,那我把资料都塞进去,不就更准了吗?
听起来合理,实际很容易翻车。
上下文窗口不是仓库,而是工作台。工作台上东西太少,模型缺信息;东西太多,模型会分心,成本会上涨,延迟会变长,关键信息还可能被噪声淹没。
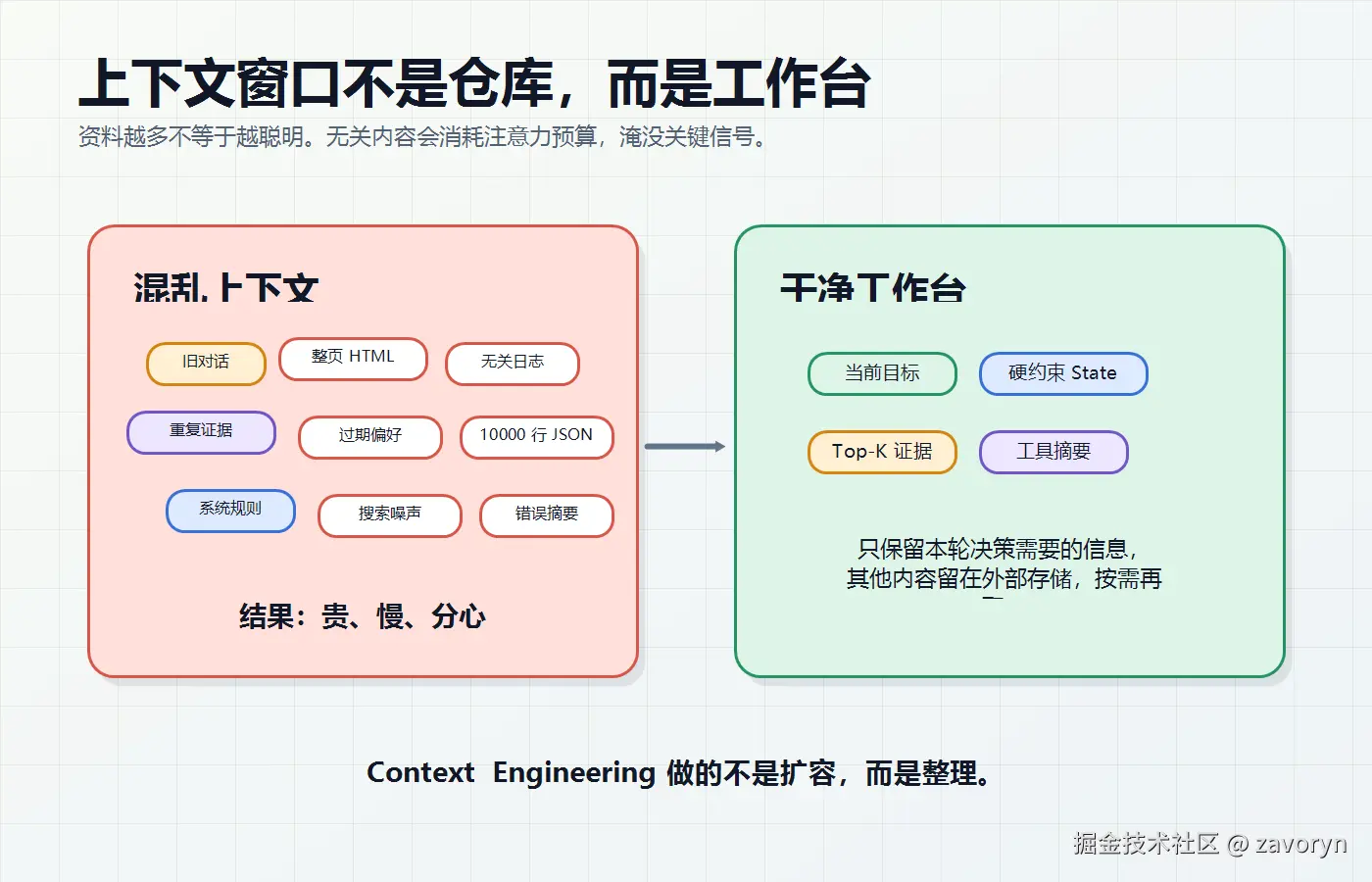
Agent 每一轮推理的上下文里,通常会混着这些东西:
- System Prompt:身份、规则、输出格式、工具使用约束。
- 当前任务:用户现在到底要什么。
- 近期对话:最近几轮发生了什么。
- Memory:用户偏好、任务状态、历史决策。
- RAG:从外部知识库检索出来的证据。
- Tool Results:搜索、数据库、代码执行、浏览器返回的结果。
- Examples:Few-shot 示例或历史成功路径。
这些内容都在抢同一个资源:模型的注意力预算。
Anthropic 在 Context Engineering 相关实践里提到一个很关键的判断:上下文是有限资源,而且边际收益会下降。不是 token 越多越好,而是要找到最小但高信号的 token 集合。
这句话很适合后端同学理解:
Context Window 不是硬盘,是 CPU Cache。
硬盘可以放很多东西,但 Cache 只应该放即将被计算用到的热数据。把冷数据、重复数据、低价值日志都塞进 Cache,系统不会更快,只会污染缓存。
上下文也是一样。
Context Engineering 到底在工程上做什么?
它不是一个单点技术,而是一条流水线。
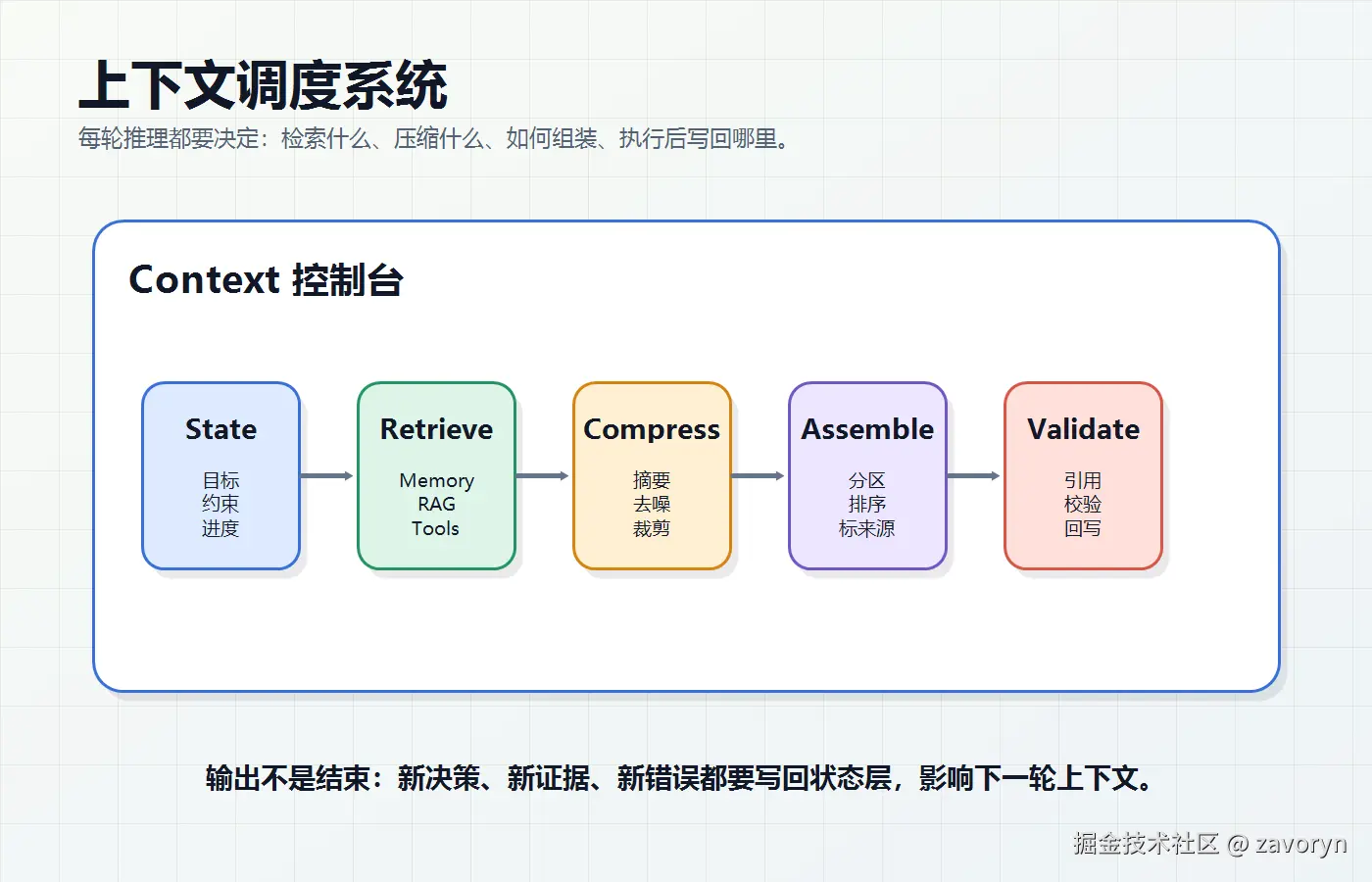
可以拆成五步:
- Build State:先明确当前任务状态。用户目标是什么?已经完成到哪一步?有哪些硬约束?
- Retrieve:按需检索上下文。该从 RAG 取文档,还是从 Memory 取用户历史,还是用 Tool 实时读取?
- Compress:压缩和裁剪。长日志、网页、JSON、历史对话,不能原样塞进模型。
- Assemble:组装上下文。不同信息要分区、排序、标来源,让模型知道哪些是规则,哪些是证据,哪些只是历史。
- Validate:输出后校验,并把新的状态写回记忆或任务日志。
这和传统 Prompt Engineering 最大的区别在于:Prompt 通常是静态的,Context 是动态的。
一个 Agent 在循环里运行,每调用一次工具、读一个文件、搜索一个网页,都会产生新的上下文候选项。Context Engineering 要做的,就是不断决策:哪些留下,哪些丢掉,哪些压缩,哪些以后再按需读取。
RAG 和 Memory 不要混为一谈
很多文章会把 RAG 和 Memory 混着讲,因为它们都可能用向量数据库,都涉及"从外部取信息"。但从架构上看,它们解决的问题不同。
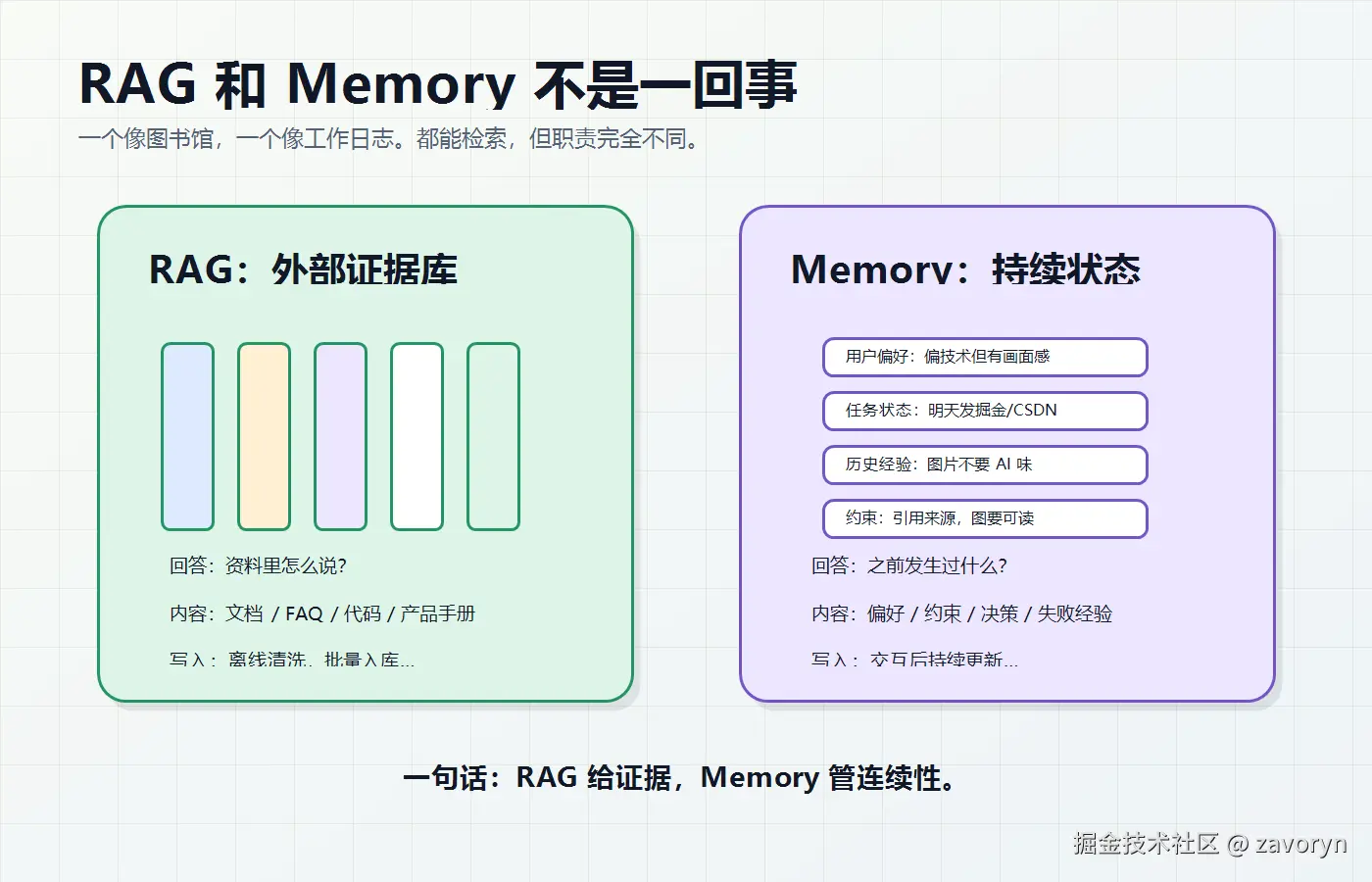
RAG 回答的是:
资料里怎么说?
比如产品文档、接口文档、合同条款、公司 FAQ、代码仓库。它更像开卷考试,模型不需要把知识记在参数里,而是在回答前先检索证据。
Memory 回答的是:
这个用户、这个任务、这个 Agent 之前发生过什么?
比如用户偏好、之前做过的选择、未完成的计划、上次工具失败的原因、某个长期任务的进度。它更像任务状态和个人经历。
二者的区别可以这样看:
| 维度 | RAG | Agent Memory |
|---|---|---|
| 核心问题 | 外部资料怎么说 | 之前发生过什么 |
| 数据范围 | 团队共享知识库 | 用户/会话/任务状态 |
| 写入方式 | 离线清洗、批量入库 | 交互后持续更新 |
| 典型内容 | 文档、FAQ、代码、网页 | 偏好、约束、决策、失败经验 |
| 主要风险 | Chunk 断裂、召回不准、证据噪声 | 错记、旧记忆污染、过度推断 |
一个典型错误是:把用户记忆也丢进 RAG。
比如用户说:"以后帮我写文章,风格要偏技术但有画面感。"这不是文档知识,而是用户偏好。它应该进入 Memory,并且带上来源、时间、置信度,而不是和一堆博客文档混在同一个知识库里。
另一个典型错误是:把 RAG 当长期记忆。
RAG 可以检索文章资料,但它不会自动知道"这次任务已经写到第几步"。任务进度、当前决策、待办事项应该是结构化 State,而不是靠向量搜索碰运气。
一个可落地的 Agent Memory 分层
Agent 记忆不是把所有历史对话存起来就完事。真正可用的记忆系统,要分层。
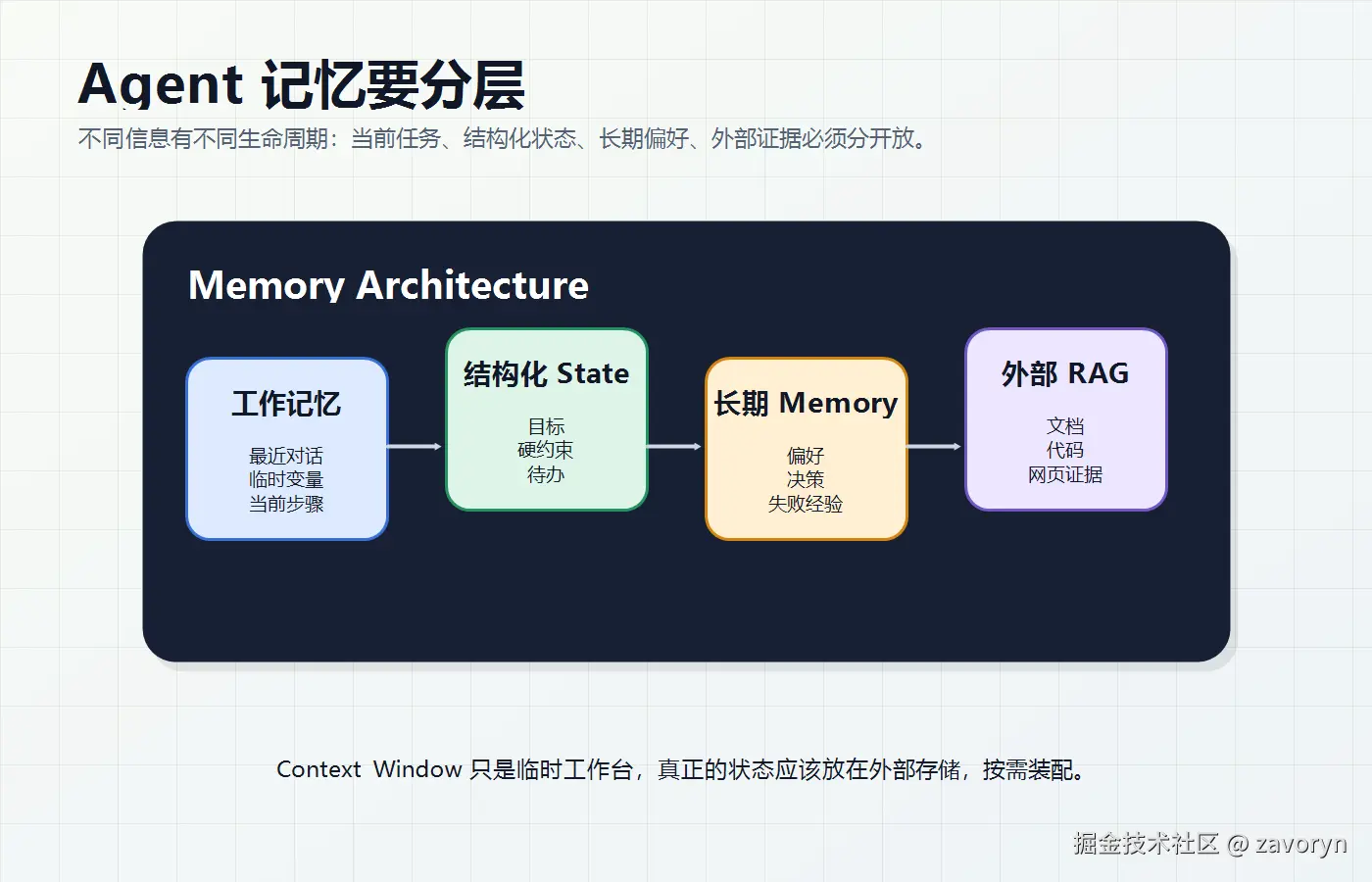 我建议至少分四层。
我建议至少分四层。
第一层:工作记忆。
它保存当前会话和当前任务的短期信息,比如最近几轮对话、正在处理的文件、临时变量、当前步骤。它的特点是读写频繁、生命周期短,适合放在进程内状态、Redis、LangGraph state 或任务上下文里。
第二层:结构化状态。
这是很多 Agent 项目容易忽略的一层。比如:
json
{
"goal": "完成明天要发的技术博客",
"target_platforms": ["掘金", "CSDN"],
"style": "科普 + 技术深度",
"must_include": ["封面", "正文图", "参考来源"],
"current_stage": "drafting",
"open_questions": []
}这类信息不适合只做自然语言摘要。因为它里面有硬约束。摘要模型一旦把"必须包含参考来源"压缩成"最好有参考",行为就变了。
第三层:长期记忆。
它保存用户偏好、历史决策、长期项目背景、成功和失败经验。可以用 KV 存结构化事实,用向量库存情节记忆,用关系库存审计记录。
第四层:外部知识。
这就是 RAG,包括文档、网页、代码库、数据库记录、搜索结果。它不一定要长期放进上下文,而是按需检索、按需加载。
关键点是:上下文窗口不是存储层。
它只是当前推理的临时工作台。真正的存储应该在外部,当前轮需要什么,再拿什么。
Context 压缩:不是把文字变短这么简单
Agent 跑长任务时,迟早会遇到上下文膨胀。
最直接的做法是摘要,也就是 compaction:当上下文接近上限时,把历史压缩成一段摘要,再开启新的上下文窗口。
但这里有一个坑:摘要会丢信息。
对于闲聊来说,丢一点细节可能没关系。但对于工程任务来说,丢掉一个约束、一个 bug 原因、一个文件路径,就可能导致后面整条链路跑偏。
所以压缩不是"越短越好",而是要分类型处理。
对话历史可以摘要:
text
用户希望文章面向开发者,风格偏科普和技术,要求图片美观且避免 AI 味。任务状态应该结构化:
json
{
"article_topic": "Context Engineering",
"publish_date": "2026-05-18",
"platforms": ["juejin", "csdn"],
"image_style": "clean technical infographic",
"avoid": ["AI-generated text image", "Chinese garbling", "repeating Tool Use topic"]
}工具结果应该过滤:
text
原始结果:10000 行日志
进入上下文:Top 5 相关错误 + 时间范围 + 文件路径 + 可复现命令RAG 证据应该带来源:
text
[source: docs/context-engineering.md]
Context engineering is about curating what enters the model context at each turn.也就是说,压缩不是一个动作,而是一组策略:
- 摘要历史对话。
- 结构化硬约束。
- 清理重复工具结果。
- 保留来源和时间。
- 对低置信度记忆做标记。
- 把大文件、大表格、大日志留在外部,只放引用或索引。
Just-in-time Context:按需加载,而不是提前全塞
一个更高级也更实用的思路是 Just-in-time Context。
它的意思是:不要在一开始把所有信息都塞进上下文,而是让 Agent 保留轻量引用,需要时再加载。
比如做代码任务时,不要把整个仓库塞给模型,而是给它:
text
项目根目录
文件树
搜索工具
读取文件工具
测试命令让它先用 rg 找相关文件,再读关键文件,再根据错误日志继续深入。
这其实很像人类工作方式。我们不会把一本书背下来再写文章,而是先知道目录、索引、书签在哪里,需要某一节时再翻出来看。
在 MCP 和 Tool Use 场景里,这个思路尤其重要。工具太多时,如果把所有工具定义都放进上下文,模型还没读用户问题,就先被几万 token 的工具说明淹没了。
更好的方式是:
- 先只暴露工具目录或
search_tools。 - 根据任务按需加载具体工具定义。
- 大数据结果在代码环境里过滤聚合,只把结论放回模型。
- 中间数据保留在执行环境,避免所有内容都穿过上下文窗口。
这也是为什么一些新的 Agent 实践会强调 code execution、文件系统、结构化笔记和渐进式披露。它们本质上都是在减少上下文污染。
最常见的 4 个坑
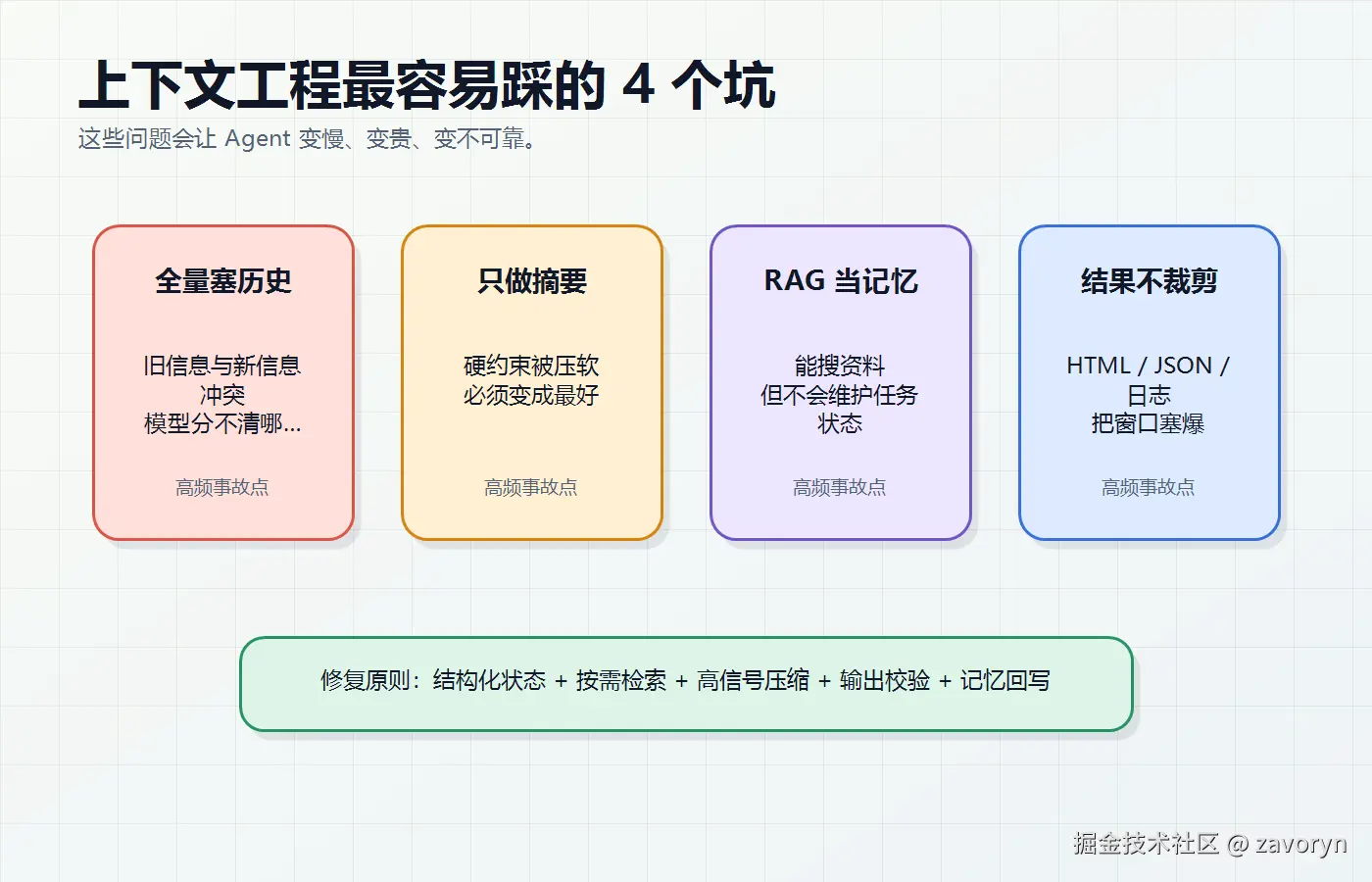
1. 全量塞历史
把所有对话都放进 prompt,看起来"记忆完整",实际上很快会变慢、变贵、变乱。旧信息可能和新信息冲突,模型还分不清哪个更新。
2. 只做自然语言摘要
摘要适合压缩事实,但不适合保存硬约束。比如"不要用 AI 风格图片"如果被摘要成"偏好自然图片",约束强度就下降了。
3. RAG 当万能记忆
RAG 适合查资料,不适合维护任务状态。任务进度、用户偏好、失败记录应该进入 Memory 或 State。
4. 工具结果不裁剪
浏览器 HTML、数据库 JSON、代码日志、搜索结果,如果原样进上下文,会快速污染窗口。工具返回要面向决策,而不是面向原始记录归档。
一个最小可落地方案
如果你现在要给自己的 Agent 应用做 Context Engineering,不需要一开始就上复杂框架。先做好这六件事。
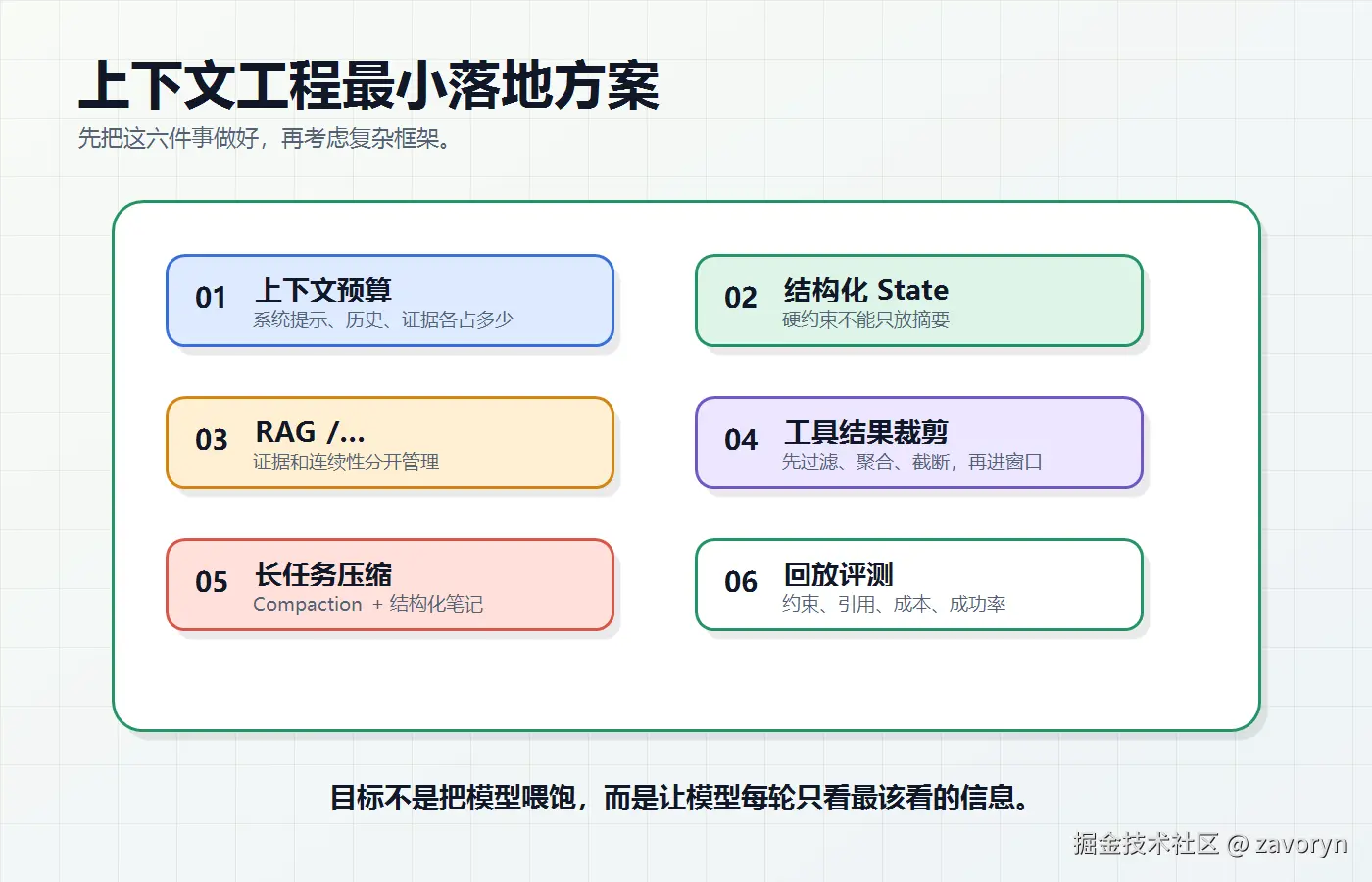
第一,定义上下文预算。
比如每轮最多给模型 20k token,就应该大致分配:系统提示 2k,当前任务 1k,近期历史 3k,RAG 证据 8k,工具结果 4k,余量 2k。这个比例不用一开始就完美,但必须有意识。
第二,把硬约束做成结构化 State。
用户目标、平台要求、不能做的事、必须包含的内容,不要只依赖摘要。
第三,RAG 和 Memory 分开。
外部文档进 RAG,用户偏好和任务连续性进 Memory,当前执行进 State。
第四,工具结果先过滤再进入上下文。
日志只给错误片段,表格只给相关行,网页只给正文摘要和链接,数据库只给必要字段。
第五,长任务使用 compaction 和结构化笔记。
每完成一个阶段,就写一份阶段性状态:做了什么、为什么这么做、还剩什么、哪些风险不能忘。
第六,用回放评测。
拿真实任务记录回放,检查几个指标:
- 关键约束有没有丢?
- RAG 引用是否支持最终结论?
- Memory 有没有错记?
- 工具结果是否过长?
- token 成本是否下降?
- 任务成功率是否提升?
没有评测的上下文工程,最后会变成玄学调参。
总结
Prompt Engineering 仍然重要,但它已经不是 Agent 工程的全部。
当系统进入多轮工具调用、RAG、Memory、长任务执行之后,真正决定效果的往往是 Context Engineering:在每一轮推理时,把最少但最高信号的信息放进模型上下文。
好的上下文工程,应该做到:
- 规则清楚,但不堆废话。
- 证据充分,但不塞噪声。
- 记忆连续,但不过度相信旧信息。
- 工具强大,但返回结果可控。
- 长任务可持续,但不会把历史全背着走。
开发 Agent 时可以记住这句话:
模型不是缺资料,而是缺一张干净的工作台。
Context Engineering 做的,就是帮模型把这张工作台整理干净。
参考资料
- Anthropic Engineering: Effective Context Engineering for AI Agents
www.anthropic.com/engineering... - Anthropic Engineering: Code Execution with MCP
www.anthropic.com/engineering... - Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeurIPS 2020
papers.neurips.cc/paper/2020/... - LangChain Docs: Memory
docs.langchain.com/oss/python/... - OpenAI Docs: Prompt Caching
platform.openai.com/docs/guides...