Agent Knowledge Runtime:从一个 Codex 自动填工时案例看 Agent 工程化
上一篇文章里,我写过一次实践:
那篇文章主要讲的是一个具体问题:如何让 Codex 借助 Chrome 插件进入真实 OA 系统,根据 Excel 工作计划创建任务、登记工时、检查重复日期,并把用户纠正过的规则沉淀成一个可复用 Skill。
当时我更关注的是"工作流重构":不要只让 AI 替我点按钮,而是把原来靠人工记忆维持的隐性规则显性化,让它下一次还能复用。
但最近继续拆这个过程时,我发现这件事背后还有一个更大的结构:
我们真正做的,不只是一个浏览器自动化 Skill,而是在构建一个面向真实任务的 Agent Knowledge Runtime。
这篇文章就想把这个概念讲清楚。
一、普通 RAG demo 解决不了真实工作流问题
很多人第一次接触 AI 应用时,会从 RAG 开始。
一个典型 RAG demo 大概是这样的链路:上传文档、文档切分、向量化、检索相关片段、拼进 prompt,最后让 LLM 回答。
这套流程很有价值。它解决了大模型不知道企业内部知识、知识过期、回答容易幻觉的问题。
但真实工作流往往不只是"问一个问题,然后回答"。
以 OA 工时填报为例,用户真正想要的不是"请告诉我工时填报规则是什么?",而是一个完整任务:
帮我根据 Excel 工作计划,同步这个月的任务和工时。遇到重复日期要跳过,遇到缺失日期要列出来问我,不要处理预测任务,并且需要真实进入 OA 页面操作。
这时,RAG 只是其中一部分。
Agent 还需要:
- 读取 Excel。
- 理解任务规则。
- 进入真实 Chrome 登录态。
- 操作 OA 页面。
- 判断哪些任务该跳过。
- 遇到风险动作时请求确认。
- 记录哪些任务创建成功、哪些失败。
- 把用户纠正过的规则沉淀到下一次。
这已经不是一个普通 RAG demo 能覆盖的范围。
它需要一个更完整的运行层。
我把这个运行层称为:
Agent Knowledge Runtime。
二、什么是 Agent Knowledge Runtime?
我现在对它的定义是:
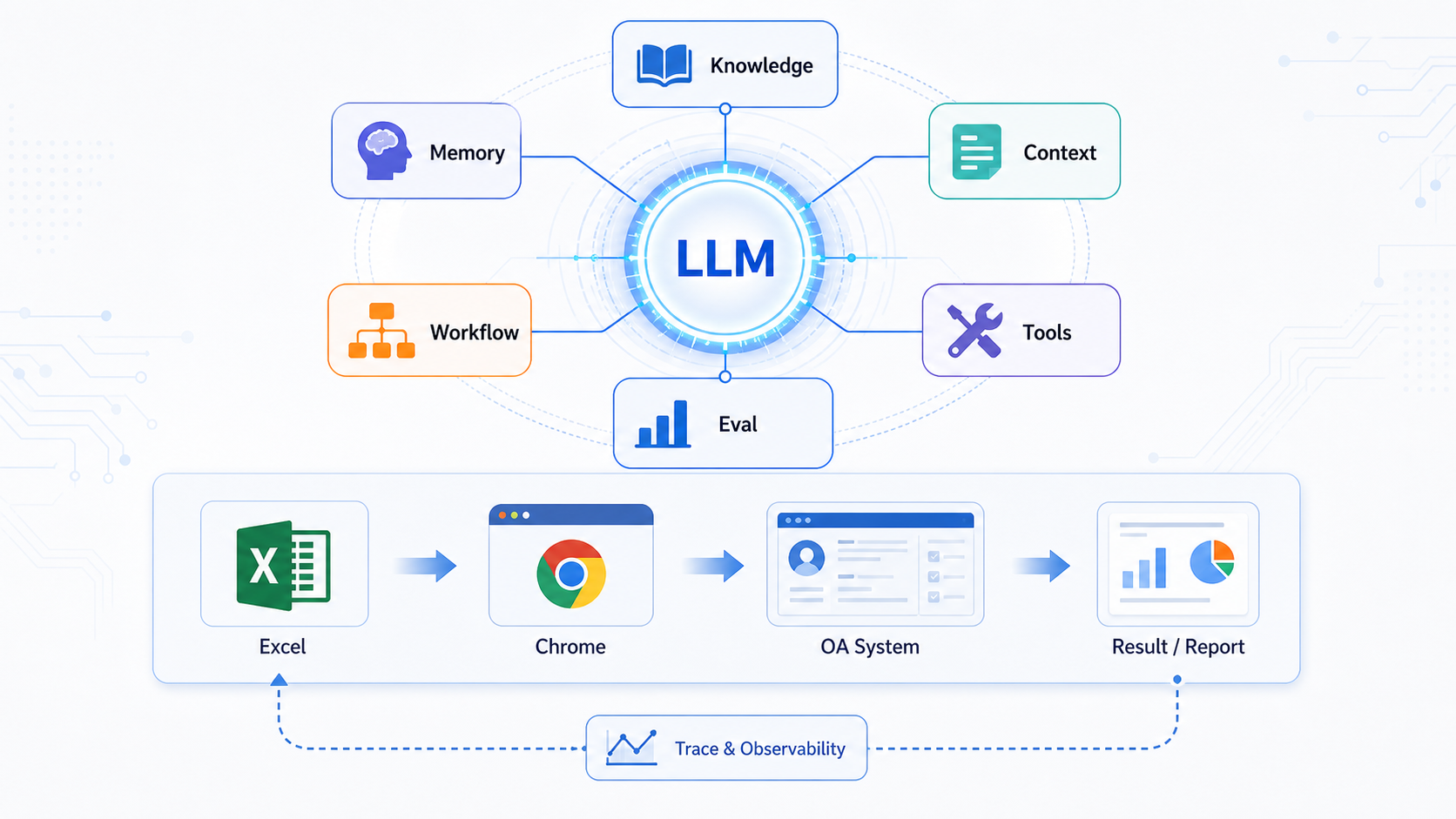
Agent Knowledge Runtime 是围绕 LLM 的工程运行层,它把文档知识、长期记忆、上下文组装、工具流程、权限审批和评测追踪组合起来,让 agent 能处理真实任务,而不只是回答问题。
这里有一个关键点:
LLM 本身不是完整 agent。
LLM 有很强的语言理解、推理、生成能力,但它默认不知道:
- 我的项目规则是什么。
- 我的 Excel 在哪里。
- 我的 OA 系统怎么打开。
- 哪些按钮可以点,哪些动作要先问我。
- 上次我纠正过什么。
- 这次执行是否成功。
所以真实 agent 系统要做的事情,不是把一个 prompt 写得越来越长,而是给 LLM 配一套外部运行系统:知识、记忆、上下文构建、工作流、工具、权限和评测观察。
这些能力组合起来,才会变成一个可用的 agent 系统。
如果说 LLM 是通用能力,那么 Agent Knowledge Runtime 就是在做三件事:
-
扩展
让 LLM 能接触外部文档、表格、代码、浏览器、业务系统。
-
规范
让 LLM 在权限、流程、审批、规则边界内做事。
-
塑造
把通用 LLM 塑造成一个具体场景里的 agent,比如代码 agent、学习 agent、工时填报 agent、企业知识库 agent。
三、Agent Knowledge Runtime 的 6 个核心模块
我目前把 Agent Knowledge Runtime 拆成 6 个模块。
| 模块 | 作用 |
|---|---|
| Document Ingestion | 导入文档、代码、Excel、网页、对话摘要等外部信息 |
| Knowledge Index | 对知识进行切分、索引、检索、引用溯源 |
| Memory Store | 存储用户偏好、项目状态、长期上下文、候选记忆 |
| Context Builder | 组装本次要给 LLM 的上下文 |
| Workflow Runtime | 编排工具调用、审批、状态机、重试、handoff |
| Eval & Observability | 记录 trace、失败案例、召回质量、执行结果 |
这 6 个模块不是为了造概念,而是为了描述一个真实 agent 系统必须处理的问题。
普通 RAG demo 主要覆盖的是文档导入、知识索引、上下文构建和 LLM 回答。
而 Agent Knowledge Runtime 还要处理记忆、工作流、工具、权限、审批、重试、Trace 和 Eval。
这就是"知识库问答"和"真实 agent 工作流"的区别。
四、LLM 在 Runtime 里到底是什么位置?
这里很容易误解。
LLM 不是 Agent Knowledge Runtime 里面的某一个普通模块。
更准确地说:
Runtime 编排和约束 LLM;LLM 在 Runtime 的多个阶段被调用。
比如:
| 阶段 | LLM 可能做什么 |
|---|---|
| Document Ingestion | 摘要文档、抽取结构、生成 metadata |
| Knowledge Index | query rewrite、chunk summary、语义标签 |
| Memory Store | 判断一段信息是否值得记忆、压缩 session summary |
| Context Builder | 压缩上下文、合并证据、处理冲突 |
| Workflow Runtime | 判断下一步、选择工具、生成工具参数 |
| Eval & Observability | 判断回答是否忠实、分类失败原因、生成 failure case |
而且这里的"LLM 能力"也不一定只有一个模型。
一个成熟系统里可能同时存在:
- embedding model
- rerank model
- chat / reasoning model
- vision model
- eval model
所以更准确的架构不是"Runtime 里有一个 LLM 模块",而是:
Runtime 在不同阶段调用不同模型能力。
但也要注意,LLM 不应该替代所有确定性逻辑。
比如:
- 权限过滤不应该交给 LLM 猜。
- 幂等和事务不应该交给 LLM 临场发挥。
- 审批边界不应该由 LLM 自己决定。
- trace 不应该靠 LLM 事后脑补。
这些应该由工程系统明确控制。
五、用 codex-chrome-workflow-skill 对照这 6 个模块
回到我的 codex-chrome-workflow-skill。
这个 Skill 的目标不是"让 AI 帮我点网页",而是让 Agent 在真实 Chrome 登录态下,按照沉淀好的规则完成企业后台流程。
它的流程大概是:
读取本地配置
读取 Excel 工作计划
过滤预测或计划任务
打开真实 Chrome OA 页面
查找或创建月度父任务
创建子任务
登记工时
检查同人同日重复
统计缺失日期
需要补填时先询问用户
如果放到 Agent Knowledge Runtime 的 6 个模块里,可以这样对应。
1. Document Ingestion:读取外部工作数据
在这个场景里,外部数据不是 PDF 或知识库文档,而是 Excel 工作计划。
Skill 里的辅助脚本会提取目标月份的任务行,包括:
- 任务名称
- 开始日期
- 完成日期
- 负责人
- 审核人
- 任务描述
- 验收标准
- 完成状态
这就是 Document Ingestion。
它把原本散落在 Excel 里的业务数据,变成 Agent 可以处理的结构化输入。
2. Knowledge Index:沉淀规则和检索依据
这个 Skill 里有很多规则:
- 预测任务不提前处理。
- 工作计划以后续具体文件为准。
- 同人同日已填工时就跳过。
- 缺失日期不能直接编内容。
- 自动补填前必须询问用户。
- 真实内部地址和人员信息只能保存在本地配置里。
这些规则本质上就是 knowledge。
它们不一定都要放进向量数据库。
有些规则更适合以 Skill instruction、配置、流程约束的方式存在。
所以 Knowledge Index 不一定只等于 vector database。它更广义地表示:
Agent 在执行任务时可以查询和遵守的规则、文档、案例和约束。
3. Memory Store:把纠正变成下一次的默认行为
这个实践里最重要的一点,是用户纠正不能只停留在一次对话里。
比如我纠正过:
- 不要处理预测任务。
- 缺失日期必须先问我。
- 不要用隔离浏览器,要用真实 Chrome 插件。
- 周末是否填报要看 Excel 来源数据。
如果这些纠正只存在于当前对话,下次还会重来一遍。
所以它们应该进入 Skill 或长期上下文。
这就是 Memory Store 的价值:
把一次纠错变成长期能力。
4. Context Builder:把本次任务所需信息组织好
当用户说"帮我同步 5 月工时"时,Agent 不能只把这句话丢给 LLM。
Context Builder 要组装本次执行所需的上下文:
- 本地配置。
- 目标月份。
- Excel 提取结果。
- OA 入口地址。
- 项目、阶段、负责人、审核人。
- 工作流规则。
- 安全边界。
- 历史纠正。
- 当前页面状态。
这一步很关键。
LLM 生成下一步动作的质量,很大程度取决于 Context Builder 组织的信息是否完整、干净、边界清晰。
5. Workflow Runtime:真正让 Agent 做事
codex-chrome-workflow-skill 最明显的部分就是 Workflow Runtime。
它不是只回答问题,而是按步骤执行:读取配置、提取 Excel、打开 Chrome、登录或进入 OA、查找任务、创建任务、填写字段、登记工时、处理重复日期,并在遇到风险动作时暂停确认。
这里面有很多不是"知识问答"的问题,而是工作流问题:
- 页面加载失败怎么办?
- 找不到任务怎么办?
- 同名任务已经存在怎么办?
- 日期已经填过怎么办?
- 缺失工时能不能自动补?
这些都属于 Workflow Runtime。
它包括状态机、重试、工具调用、浏览器操作、审批点和错误恢复。
6. Eval & Observability:不是做完就结束
一个可靠的 agent 工作流,不能只看"有没有跑完"。
它还要记录:
- 创建了哪些任务。
- 跳过了哪些任务。
- 哪些日期已填过。
- 哪些日期缺失。
- 哪些页面加载失败。
- 哪些动作需要用户确认。
- 用户纠正了哪些规则。
这些信息用于两件事:
- 让用户知道这次执行是否可靠。
- 让下一次执行可以变得更好。
比如页面加载失败后等待 30 秒再刷新,这是 Workflow Runtime 的错误恢复。
而把这次失败记录下来、判断是否应该更新 Skill、下次是否要调整等待策略,就是 Eval & Observability。
六、Skill 到底算不算 Runtime 的一部分?
这个问题很重要。
我的判断是:
Skill 不是 Runtime 本身,但它可以成为 Runtime 的能力扩展单元。
如果 Skill 只是静态说明,它更像知识。
如果 Skill 定义了:
- 什么时候触发。
- 使用哪些工具。
- 哪些动作必须确认。
- 哪些异常如何处理。
- 哪些规则应该长期遵守。
那它就不仅是文档,而是 workflow policy。
codex-chrome-workflow-skill 就属于这种情况。
它既包含知识,也包含流程,也包含安全边界。
所以它可以被看作 Agent Knowledge Runtime 的一个可插拔能力模块。
七、为什么这件事比"AI 自动填表"更重要?
如果只看表面,这个例子是在做 OA 工时填报。
但它背后真正有价值的是:
把一个依赖人工经验的重复流程,改造成可执行、可纠错、可沉淀、可演进的 agent workflow。
这和传统自动化脚本不一样。
传统脚本通常有几个特点:规则固定、输入固定、异常靠报错、维护靠改代码。
Agent workflow 更像一套可以演进的流程:规则可以逐步显性化,异常可以分类处理,用户可以实时纠偏,纠偏可以沉淀为下一次默认行为,执行过程也可以被记录和评估。
这也是我现在更关注 Agent Knowledge Runtime 的原因。
未来有价值的 agent,不只是"会回答问题",而是能进入真实工作现场,并在长期使用中持续吸收规则、修正流程、积累上下文。
八、从这个例子看 Codex 的定位
Codex 最初看起来是 coding agent。
但从这个实践看,它不只是写代码工具。
它已经具备一个更通用的任务 runtime 形态:LLM 加上系统规则、开发者规则、Skills、浏览器、Shell、文件系统、自动化、记忆上下文和审批边界,就可以形成一个个人工作流 agent runtime。
在代码场景里,它可以读仓库、改文件、跑测试、提交 PR。
在企业后台场景里,它可以读 Excel、进 Chrome、操作 OA、登记工时。
在学习场景里,它可以维护学习计划、记录进度、验收掌握度。
关键不在于 Codex 是不是"开发工具",而在于:
它能否被扩展成一个围绕真实任务运行的 agent runtime。
从这个角度看,codex-chrome-workflow-skill 是一个很好的样本。
它说明:只要有合适的工具入口、规则沉淀方式、上下文组织能力和安全边界,Codex 可以从 coding assistant 扩展成个人工作流 agent。
九、我现在对 Agent 开发的理解
以前我可能会把 agent 简单理解成 LLM + tools。
现在我觉得这个说法太粗了。
现在我觉得这个说法太粗了。更准确的表达应该是:
| 能力 | 解决的问题 |
|---|---|
| LLM 能力 | 理解、推理、生成 |
| 外部知识 | 知道真实业务和项目资料 |
| 长期记忆 | 记住偏好、状态和历史纠正 |
| 上下文构建 | 决定这次给模型什么 |
| 工具调用 | 进入真实系统执行动作 |
| 工作流控制 | 决定下一步该做什么 |
| 权限审批 | 控制哪些动作必须问人 |
| 失败恢复 | 页面失败、工具失败、流程中断时怎么处理 |
| 评测观察 | 判断做得对不对,以及下次怎么改 |
RAG 解决的是"知道什么"。
Memory 解决的是"记住什么"。
Context Builder 解决的是"这次该给模型什么"。
Workflow Runtime 解决的是"下一步该做什么"。
Tools 解决的是"怎么进入真实世界执行"。
Eval & Observability 解决的是"做得对不对,以及下次怎么变好"。
这些东西合在一起,才是一个真正可用的 agent 系统。
十、结语:真正值得沉淀的不是一次操作,而是一套运行能力
codex-chrome-workflow-skill 最初只是为了解决一个具体问题:
每个月不要再手工填 OA 工时。
但它最后沉淀出来的东西,不只是一个自动化脚本。
它沉淀的是:
- 规则。
- 边界。
- 工具入口。
- 异常处理。
- 用户确认点。
- 可复用 Skill。
- 可继续演进的 workflow。
这就是 Agent Knowledge Runtime 的雏形。
未来我更想做的,不是让 AI 替我完成一次又一次孤立任务,而是把这些任务背后的知识、规则、记忆、工具和评测机制沉淀下来。
让每一次执行,都能让系统比上一次更成熟一点。
这可能才是 AI agent 真正改变个人工作方式的地方:
不是让 AI 临时替你做事,而是把你的工作经验逐步工程化成一个可运行、可复用、可进化的 agent 系统。
参考
- 旧文:用 Codex Chrome 插件重构工作流:从 OA 工时填报到可复用 Skill 的自动化实践
codex-chrome-workflow-skill:Chrome-backed workflow automation skill