目录
- 前言
- 一、RAG基本概念
-
- [1.1 核心定义](#1.1 核心定义)
- [1.2 作用](#1.2 作用)
- [二、RAG 的核心工作流程](#二、RAG 的核心工作流程)
-
- [2.1 离线索引:数据准备](#2.1 离线索引:数据准备)
- [2.2 检索环节](#2.2 检索环节)
- [2.3 生成环节](#2.3 生成环节)
- [三、 关键组件解析](#三、 关键组件解析)
-
- [3.1 文本分割策略](#3.1 文本分割策略)
- [3.2 嵌入模型](#3.2 嵌入模型)
- [3.3 向量数据库](#3.3 向量数据库)
- 四、RAG类型
-
- [4.1 Native RAG](#4.1 Native RAG)
- [4.2 Agent RAG](#4.2 Agent RAG)
- [4.3 Graph RAG](#4.3 Graph RAG)
-
- [Graph RAG优势](#Graph RAG优势)
- [4.4 Hybrid RAG](#4.4 Hybrid RAG)
- [五、RAG 落地注意事项](#五、RAG 落地注意事项)
-
- 文本分割不合理,检索精度低
- 嵌入模型选型不当,语义匹配不准
- [Agent RAG/Graph RAG 落地困难](#Agent RAG/Graph RAG 落地困难)
前言
- 在大模型时代,RAG(Retrieval-Augmented Generation,检索增强生成)早已不是小众技术,而是解决大模型"知识过期、幻觉严重、专业度不足"的核心方案
- 这篇博客梳理一下RAG相关的知识体系
一、RAG基本概念
1.1 核心定义
RAG直译是"检索增强生成",核心思想是:在模型生成答案之前,先从外部知识库中检索出最相关的文档片段,然后将这些片段作为上下文提供给模型,让模型基于这些"参考资料"生成回答。
1.2 作用
大模型(如GPT、LLaMA)虽然强大,但存在天然短板,RAG正是为解决这些问题而生:
- 知识过期:大模型训练数据有截止日期(比如GPT-4截止到2023年4月),无法获取实时信息(如最新政策、行业动态),RAG可通过更新知识库,让大模型"实时学习"。
- 幻觉严重:大模型容易编造不存在的信息(比如假数据、假引用),RAG基于真实的知识库检索,能大幅降低幻觉,让回答更可信。
- 专业度不足:大模型对垂直领域(如医疗、法律、工业)的细分知识掌握不深,RAG可接入行业专属知识库,让大模型快速具备专业能力。
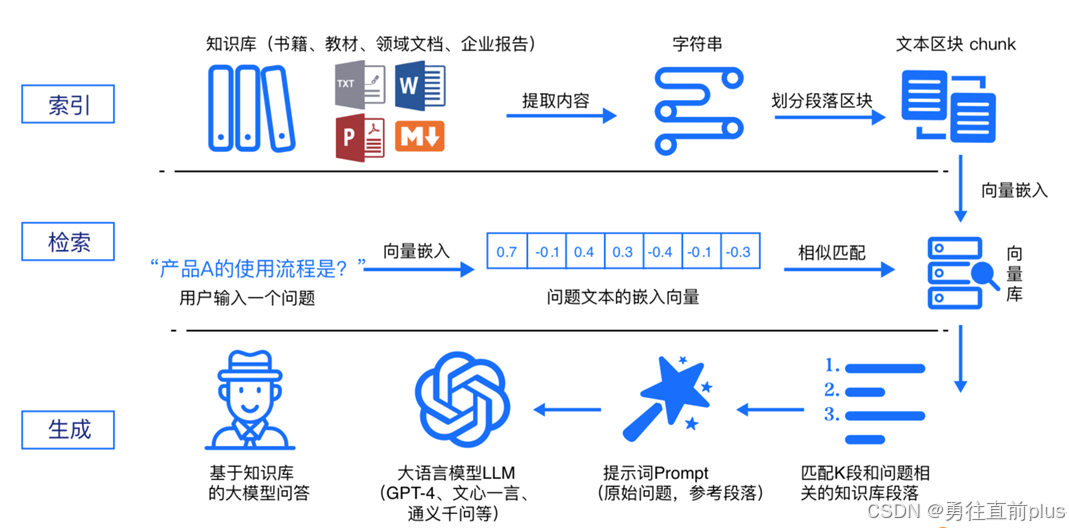
二、RAG 的核心工作流程
RAG的整体流程可拆解为「数据准备→检索→生成」三个核心环节
2.1 离线索引:数据准备
- 文档加载:从 PDF、网页、数据库等多源加载文档。
- 文本分割(Chunking):将长文档切分为语义连贯的小块。
- 嵌入(Embedding):将每个文本块经过嵌入模型,转化为向量。
- 向量存储:将向量连同元数据存入向量数据库,构建索引。
2.2 检索环节
- 查询处理:对用户问题做重写、扩展或分解。
- 嵌入(Embedding),将处理之后的用户问题经过相同的嵌入模型,转化为向量。
- 检索:用问题向量在知识库中检索 Top-K 个最相关文本块。
- 重排序(Reranking):基于重排序(rerank)模型对候选文本快重新打分、筛选。
2.3 生成环节
- 将检索到的相关文本片段,作为上下文传入大模型,让大模型基于这些"参考资料",生成连贯、精准、无幻觉的回答。
- 关键细节:提示词(Prompt)设计很重要,需要明确告诉大模型"只能基于提供的参考资料回答,不要编造信息",避免大模型忽略检索结果、依赖自身记忆。
三、 关键组件解析
3.1 文本分割策略
好的分块直接影响检索质量。常用策略有:
- 固定大小分块:按 token 或字符数切分,设置重叠窗口(overlap)防止语义断裂。
- 递归分块:先按段落、后按句子递进切分,尽量保留语义边界。
- 语义分块:利用模型判断句子间的语义相似度,在主题变化处切分。
- 句子窗口检索:检索时取命中的句子,再扩展其周围句子作为上下文。
3.2 嵌入模型
负责将文本转换成向量,是检索精准度的"基础",常用模型分为两类:
- 通用模型:Sentence-BERT、BERT、GPT-4 Embeddings,适合通用场景。
- 垂直领域模型:医疗领域的BioBERT、法律领域的LegalBERT,适合专业场景,能更好地理解领域术语。
3.3 向量数据库
负责存储向量和快速检索,选择时重点关注3点:检索速度、 scalability(可扩展性)、易用性,常用选型:
- 开源款:Milvus(开源、高性能,适合企业自建)、Chroma(轻量、易部署,适合开发测试)。
- 云服务款:Pinecone、Weaviate(无需自建,按需付费,适合快速落地)。
四、RAG类型
4.1 Native RAG
这是最基础、最常用的RAG形态,也是我们最初接触的RAG,核心特点:
- 检索方式:基于向量数据库的"相似性检索",只找"语义相似"的文本碎片。
- 流程:固定不变------用户提问→嵌入转换→向量检索→大模型生成。
4.2 Agent RAG
将 RAG 封装为智能体可以调用的工具。智能体可以规划、多步检索、对比多源信息、验证,并用思维链完成复杂研究任务。
4.3 Graph RAG
- GraphRAG的核心是"换一种检索底层",将普通的"文本碎片检索"换成"知识图谱检索"
- 本质是:先将知识库中的文本,抽成"实体+关系"的知识图谱(比如"硝苯地平→治疗→高血压"),检索时顺着关系链查找,而不是单纯匹配相似文本。
Graph RAG优势
GraphRAG 相比普通 RAG 的核心优势:
-
能回答"多跳"问题
普通 RAG 只能找相似片段,问"A 公司的竞争对手中,谁在 B 领域投资最大?"就需要跨实体推理,GraphRAG 通过知识图谱的关系链接,一次检索就能串联多个信息点。
-
答案更完整、不碎片化
普通 RAG 返回多个独立片段,可能重复或矛盾。GraphRAG 基于实体和关系,能输出结构化的、全局性的答案(比如"人物关系网、事件时间线")。
-
可解释性更强
普通 RAG 只说"来自文档 X"。GraphRAG 能展示推理路径:"A--投资--> B --竞争--> C",每步都有依据。
-
减少"不相关检索"
普通 RAG 容易被关键词误导。GraphRAG 通过知识图谱的语义关系过滤,只走有逻辑关联的路径,噪音更少。
4.4 Hybrid RAG
Hybrid RAG结合了"向量检索"和"关键词检索"(传统检索),核心特点:
- 向量检索:负责匹配"语义相似"的文本(解决同义词、歧义问题)。
- 关键词检索:负责匹配"关键词精准匹配"的文本(解决专业术语、精准查询问题)。
- 优点:兼顾"语义贴合度"和"精准度",是目前企业落地最常用的RAG形态。
五、RAG 落地注意事项
文本分割不合理,检索精度低
-
问题表现:要么分块太长(超过大模型上下文窗口,导致检索片段冗余),要么分块太短(语义断裂,比如一句话被拆成两段,无法理解完整含义),最终导致检索不到相关内容或检索结果无关。
-
解决方案:
- 优先选择「递归分块」或「语义分块」,避免固定大小分块的生硬割裂;
- 分块长度控制在 200-500token,设置 10%-20% 的重叠窗口(overlap),防止语义断裂;
- 垂直领域文档(如医疗、法律)可适当缩短分块,保证专业术语的完整性。
嵌入模型选型不当,语义匹配不准
- 问题表现:通用嵌入模型无法理解垂直领域术语(比如用 Sentence-BERT 检索医疗文献,无法识别专业病症、药物名称的语义关联),导致检索结果偏差。
- 解决方案 :
- 通用场景选 Sentence-BERT、GPT-4 Embeddings,兼顾效果和效率;
- 垂直领域必须选用对应领域模型(医疗用 BioBERT、法律用 LegalBERT),提升术语语义匹配度;
Agent RAG/Graph RAG 落地困难
- 问题表现:部署 Agent RAG 后,智能体频繁无效调用 RAG 工具;Graph RAG 图谱构建复杂,无法实现多跳推理。
- 解决方案 :
- Agent RAG:优化智能体的提示词,明确检索触发条件(比如 "当问题需要具体数据、专业内容时,再调用 RAG 工具"),避免无效调用;
- Graph RAG:优先简化图谱结构,聚焦核心实体和关系,避免过度复杂(比如医疗场景先构建 "药物 - 病症 - 治疗方式" 核心关系),后期再逐步扩展。