切片

张量
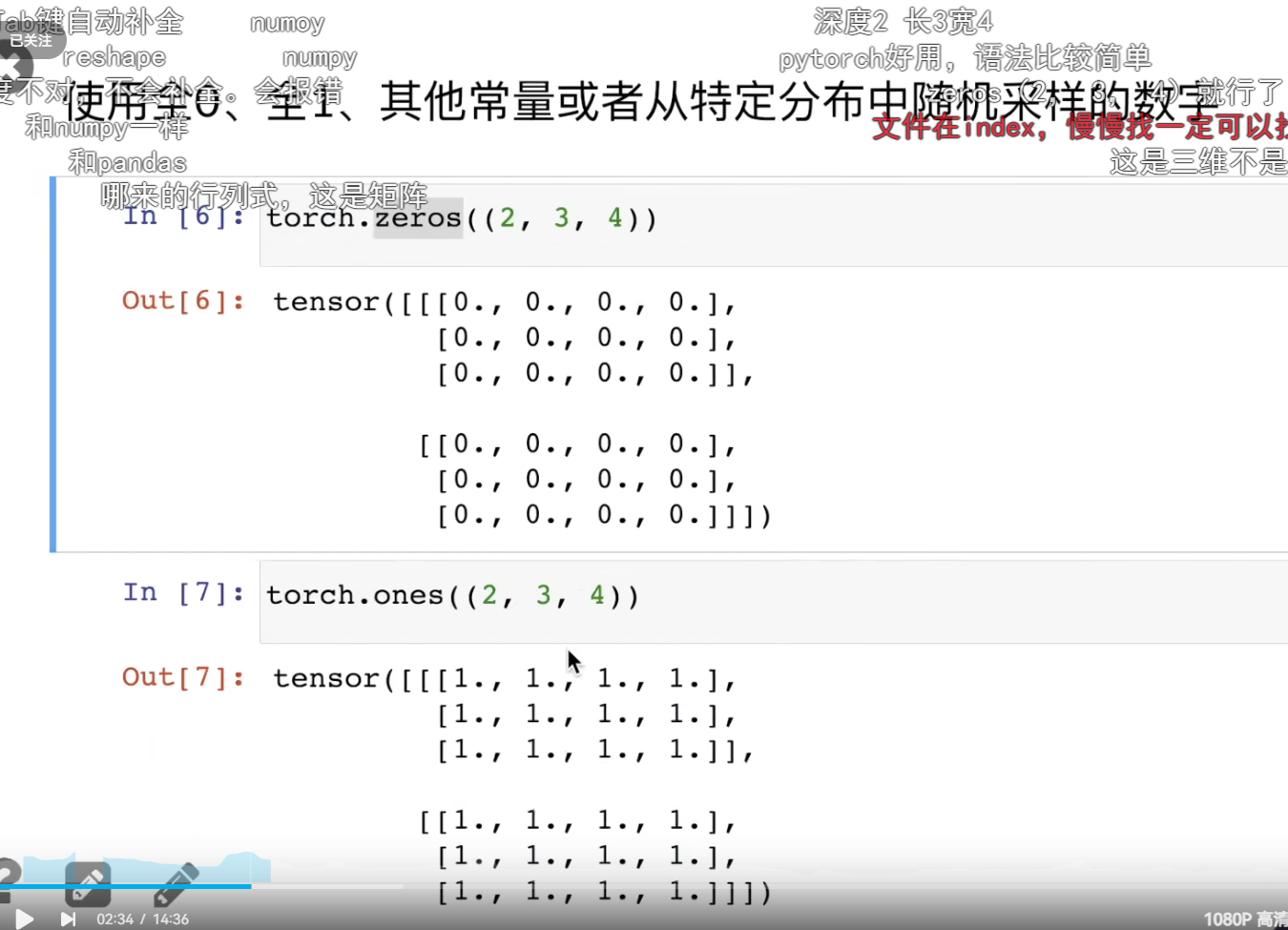
第一段代码:torch.zeros((2, 3, 4))
-
功能:创建一个所有元素值都为 0 的张量。
-
参数
(2, 3, 4):这是一个元组,表示生成的张量的形状(Shape) ,也就是维度大小。这代表了一个三维张量 ,其具体结构为:2 个深度层 ,每层有 3 行 ,每行有 4 列。 -
输出结果 :控制台打印出了一个三维嵌套列表形式的张量,其中包含了
2 × 3 × 4 = 24个 0.0。 -
注意代码中传入的是
((2, 3, 4))。虽然最外层的括号在实际使用中经常省略(写成torch.zeros(2, 3, 4)也可以),但加上它可以更明确地告诉程序这是一个整体(元组)

二维数组


三维数组
这个数据是一个三维张量,它的具体尺寸是:
-
第 1 维(Depth/深度):大小为 1。这就像一叠纸,这里只有 1 张纸。
-
第 2 维(Height/高度) :大小为 3。这张纸上共有 3 行数据。
-
第 3 维(Width/宽度) :大小为 4。每一行有 4 列数据。
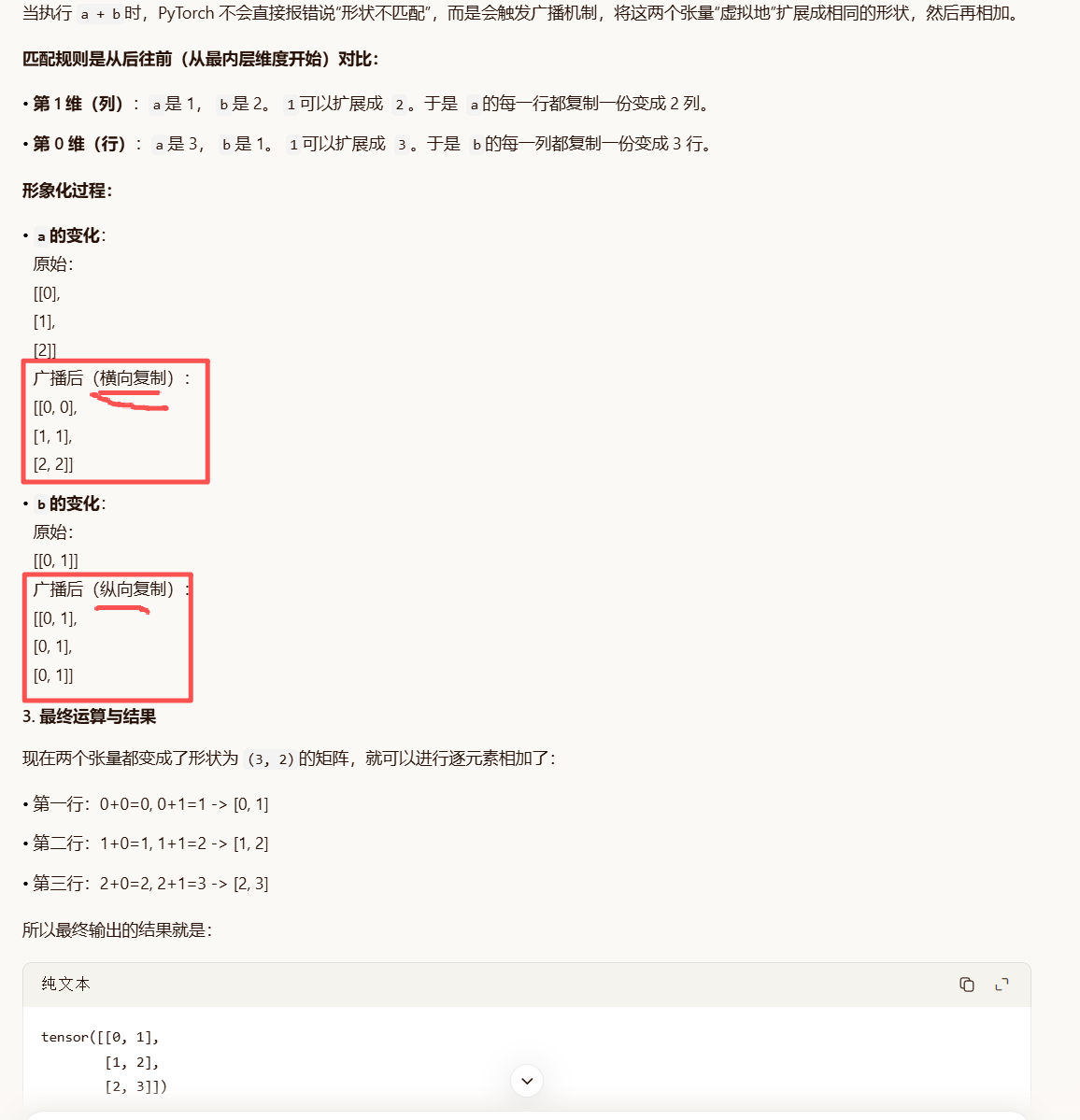
广播机制:
内存机制:
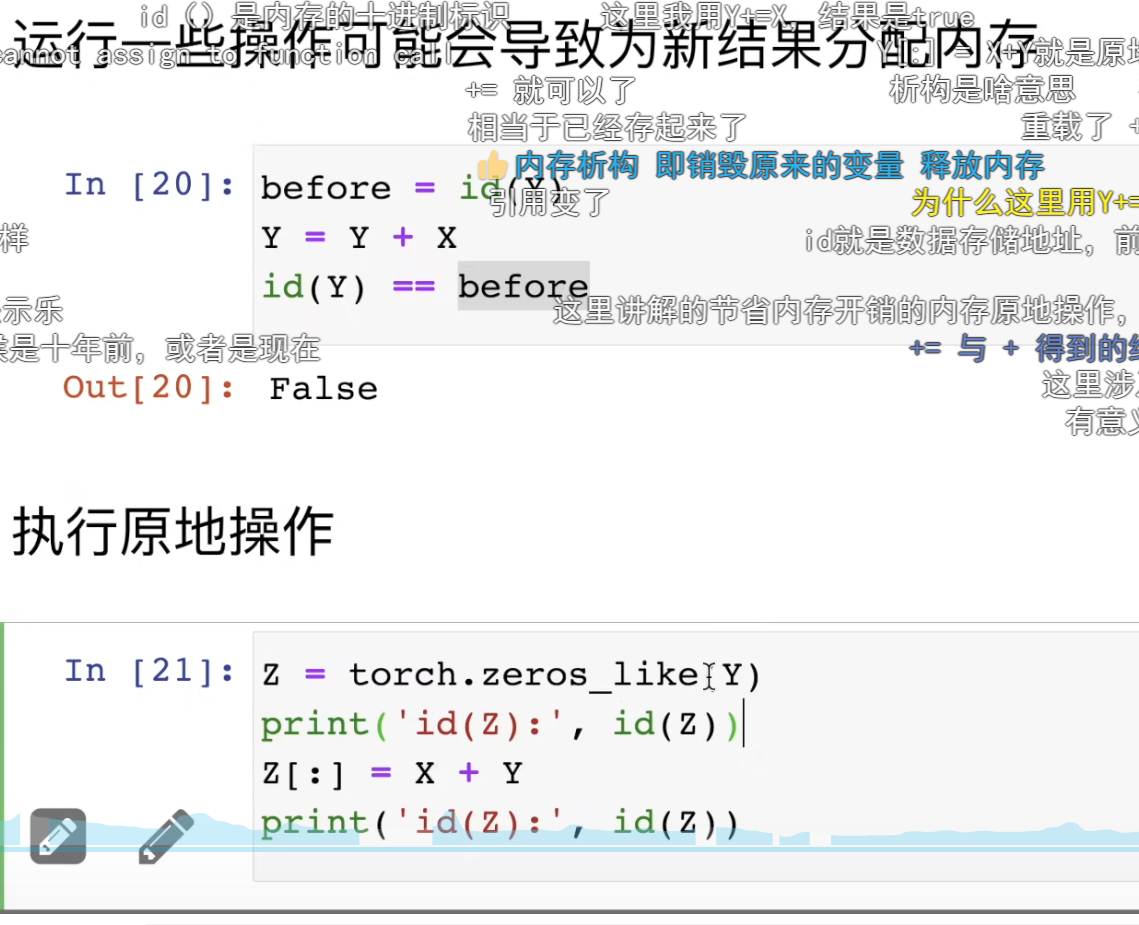
第一部分代码结果 False的含义:
结果为 False,说明门牌号变了。
before = id(Y):先记录下变量 Y现在住在哪块内存(记下门牌号)
-
为什么? 因为
Y + X这个动作会先算出一个全新的结果 (住在新房子),然后Y = ...这一步相当于把Y这个标签从旧房子撕下来,贴到了新房子上。 -
后果 :原来的旧房子(旧的
Y)如果没有其他标签指着它,就会被 Python 的垃圾回收机制销毁,释放掉内存。这会导致额外的内存分配和释放开销。
第二部分:结果两个输出id一样
Z = torch.zeros_like(Y)
"照着
Y的样子,造一个全是 0 的Z。"
-
zeros:全是 0 -
like(Y):长得像Y(形状、数据类型都一样)
Z:的含义:
这里的 :代表切片赋值,意思是"把右边的结果,直接填进 Z原本住的那块内存空间里",而不是让 Z搬家。
在深度学习训练大模型时,非原地操作(如 Y = Y + X)会不断产生新变量、销毁旧变量,导致内存频繁波动;而使用原地操作(如 Z[:] = X + Y或 PyTorch 自带的 .add_()方法)可以复用同一块内存,从而节省内存开销,防止爆显存。

1. X += Y的本质
在 PyTorch(以及底层 Python)中,+=符号被解释为 X.add_(Y) 。注意那个隐藏在下划线 _结尾的方法,在 PyTorch 中,这代表这是一个原地修改的操作。
它的执行逻辑是:直接在 X原本占据的那块内存空间里,把 Y的值加进去,覆盖掉 X原来的数据。它不需要申请一块新的内存来存放计算结果。
2. 与上一张图的对比
-
上一张图 (
Y = Y + X):这是一个"非原地"操作。计算机会先计算
Y + X,这个结果会诞生在一个全新的内存地址 。然后,变量名Y被重新指向了这个新地址。所以原来的Y地址就丢了(变成了False)。 -
这一张图 (
X += Y):这是一个"原地"操作。计算
X + Y后,直接把结果写回X的老家。因此,X依然住在原来的地方,它的身份证(id)自然就没变(所以是True)。
numpy和张量转换
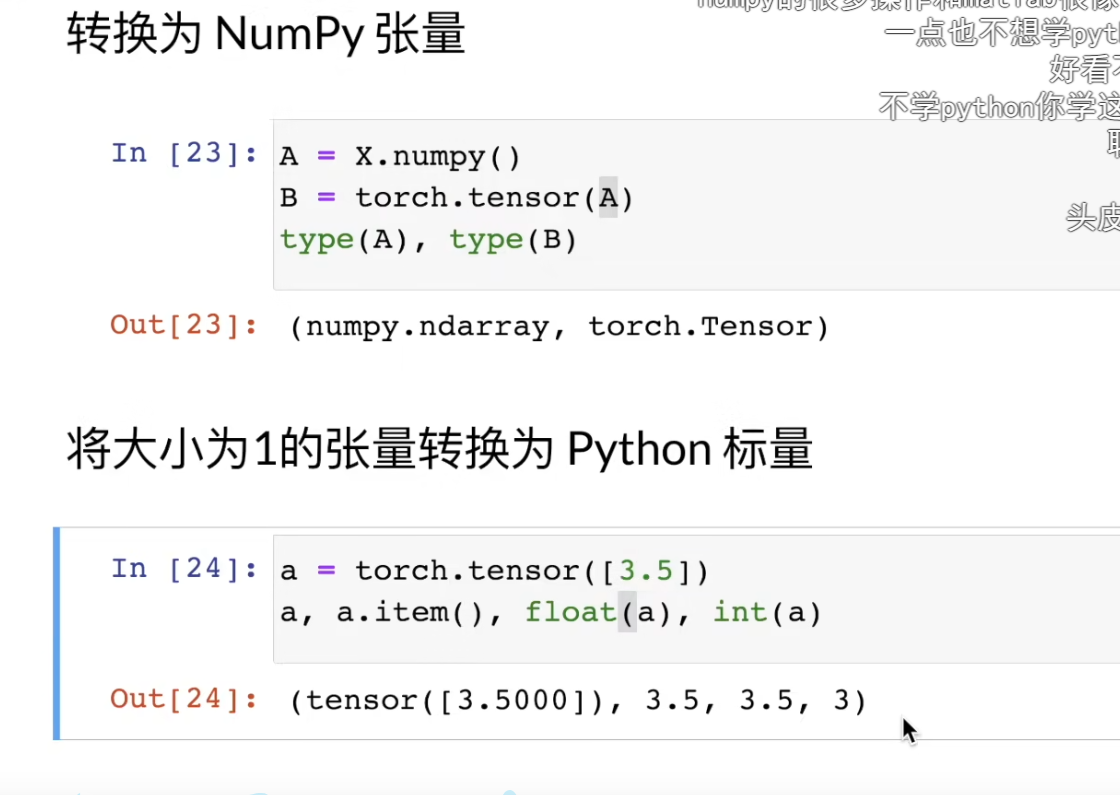
a.item():这是 PyTorch 专属的方法。它会把大小为 1 的张量提取出对应的 Python 浮点数。这里输出 3.5。注意:如果张量里有多个元素,用 .item()会直接报错。
int(a):使用 Python 的内置 int()函数。它会把张量里的数字转成整数(直接截断小数部分),所以输出是 3。
数据操作
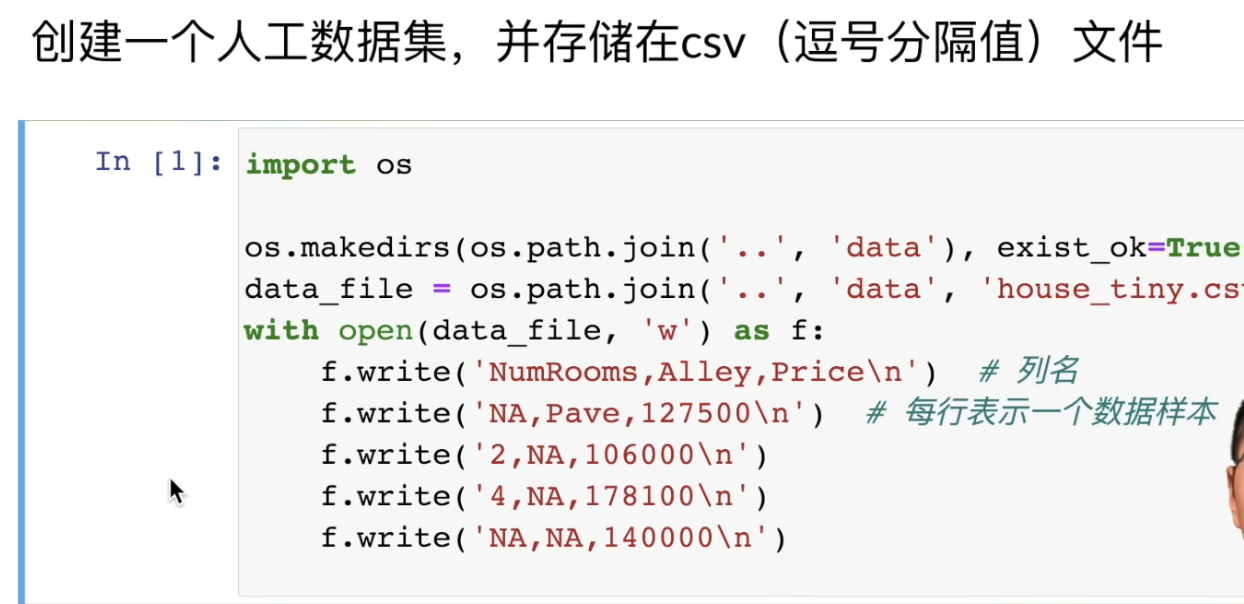
os.path.join('..', 'data'):拼接路径。'..'表示上一级目录 ,所以这行代码的意思是"在上一级目录里建一个名为 data的文件夹"。
exist_ok=True:这是一个非常贴心的参数。意思是"如果这个文件夹已经存在了,别报错,默默跳过就好"。如果没有它,重复运行代码时程序会因为"文件夹已存在"而崩溃。
data_file = os.path.join('..', 'data', 'house_tiny.csv')
这行代码继续拼接,最终生成了一个完整的文件路径:上一级目录下的 data文件夹里的 house_tiny.csv文件(CSV 是一种纯文本表格格式,Excel 可以直接打开)。
**如果当前目录里没有这个
house_tiny.csv,这行代码也不会报错,也不会帮你创建文件。**它只是**"生成一个路径字符串"**,不会真正创建文件
拼接字符串,得到一个路径
比如在 Windows 上可能是:
..\data\house_tiny.csv那什么时候文件才会被创建?
文件只有在 **真正"打开并写入"** 的时候才会被创建。
比如你后面这行代码:
with open(data_file, 'w') as f:
f.write(...)这里才发生两件事:
-
open(..., 'w'):-
如果文件不存在 → 新建
-
如果文件存在 → 清空原内容
-
-
f.write(...):- 把内容写进去
✅ 所以:文件是 open()创建的,不是 os.path.join()创建的。
维度求和axis=0 / 1 2 重点
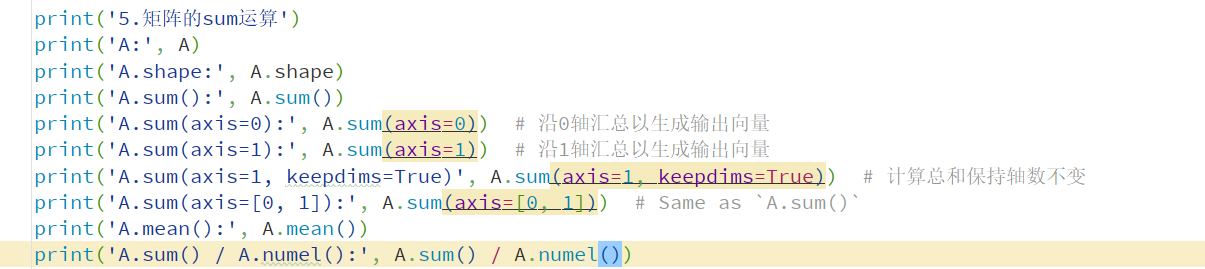

keepdims是有时候需要后续结果可以广播
sumaxis=0,1如何求:
先sumaxis=0再axis=1求和 针对一个矩阵来说的
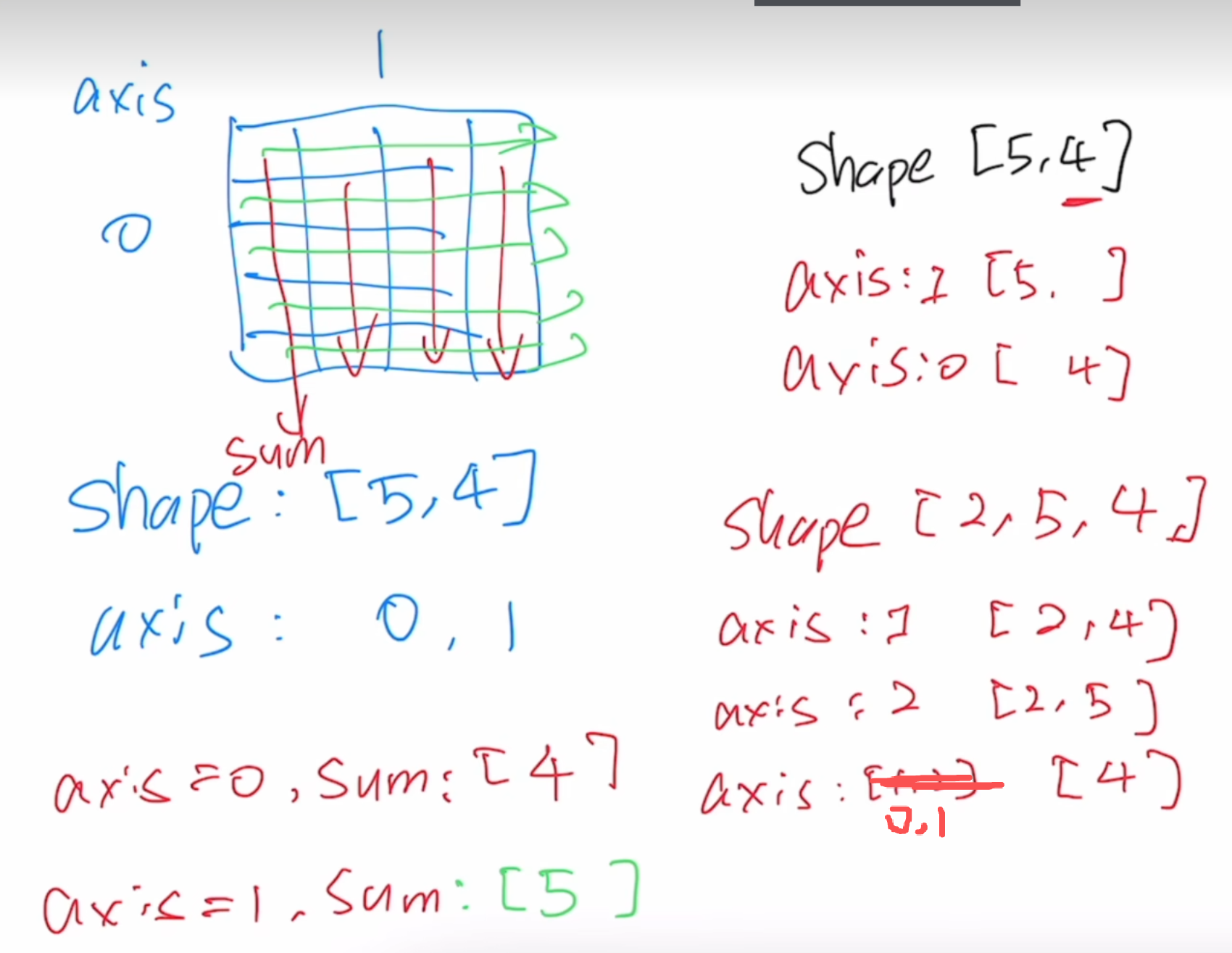
按照哪个轴求和,最后形状的哪个轴就去掉了,留下别的轴 这一个是把维度压掉了 对哪个维度求和就是消掉哪个维度 变成一个数值

如果keepdims后,那个轴形状就变成1 , 这一个是把一个维度上的长度压成1
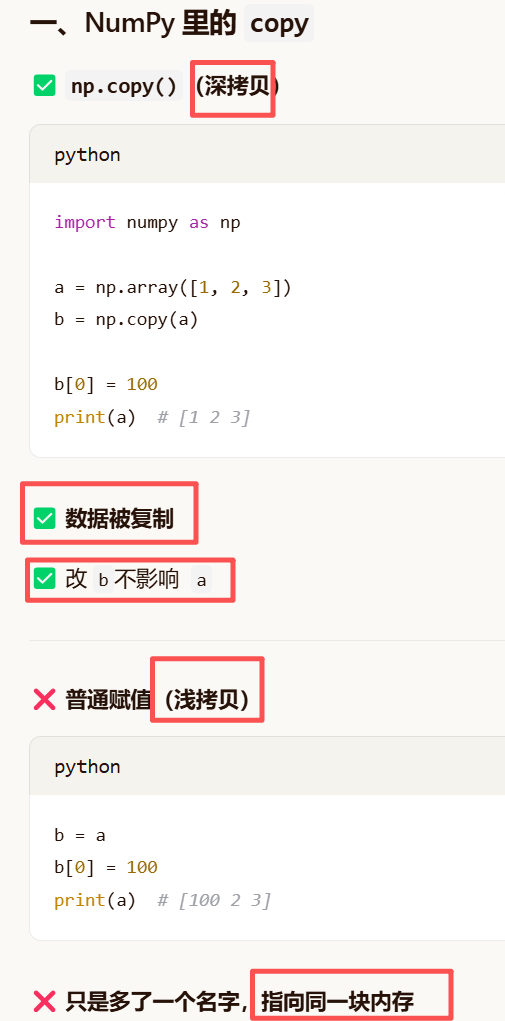
copy和clone:
copy是numpy的,clone是torch,都是一个意思 但copy有深拷贝和浅拷贝 clone是一定复制内存

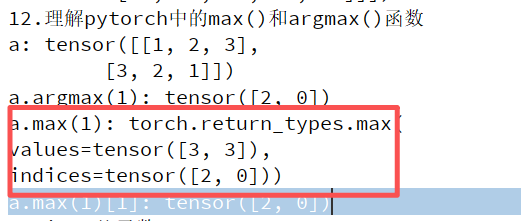
argmax和max:

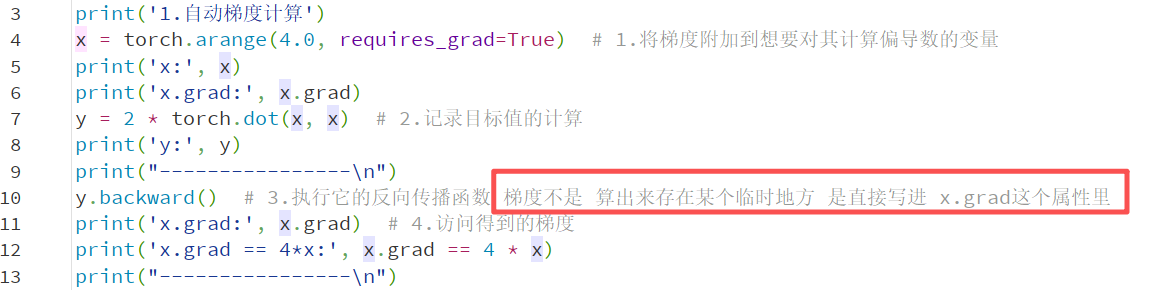
反向传播:
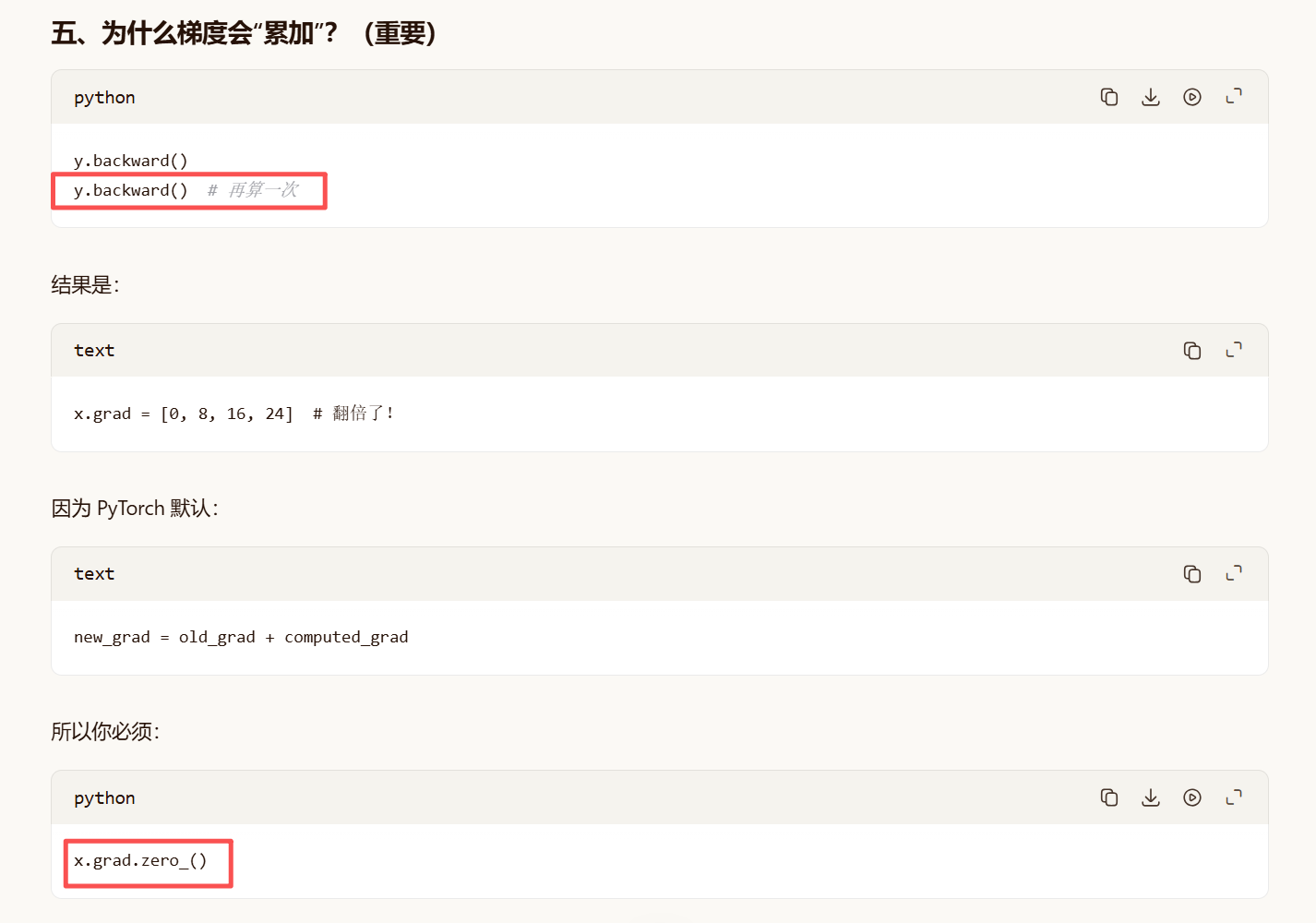
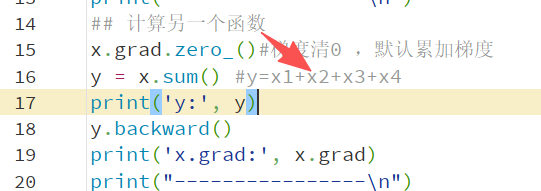
y.backward()
.requires_grad_(True):开启梯度追踪。PyTorch 会记录所有对这个变量的操作

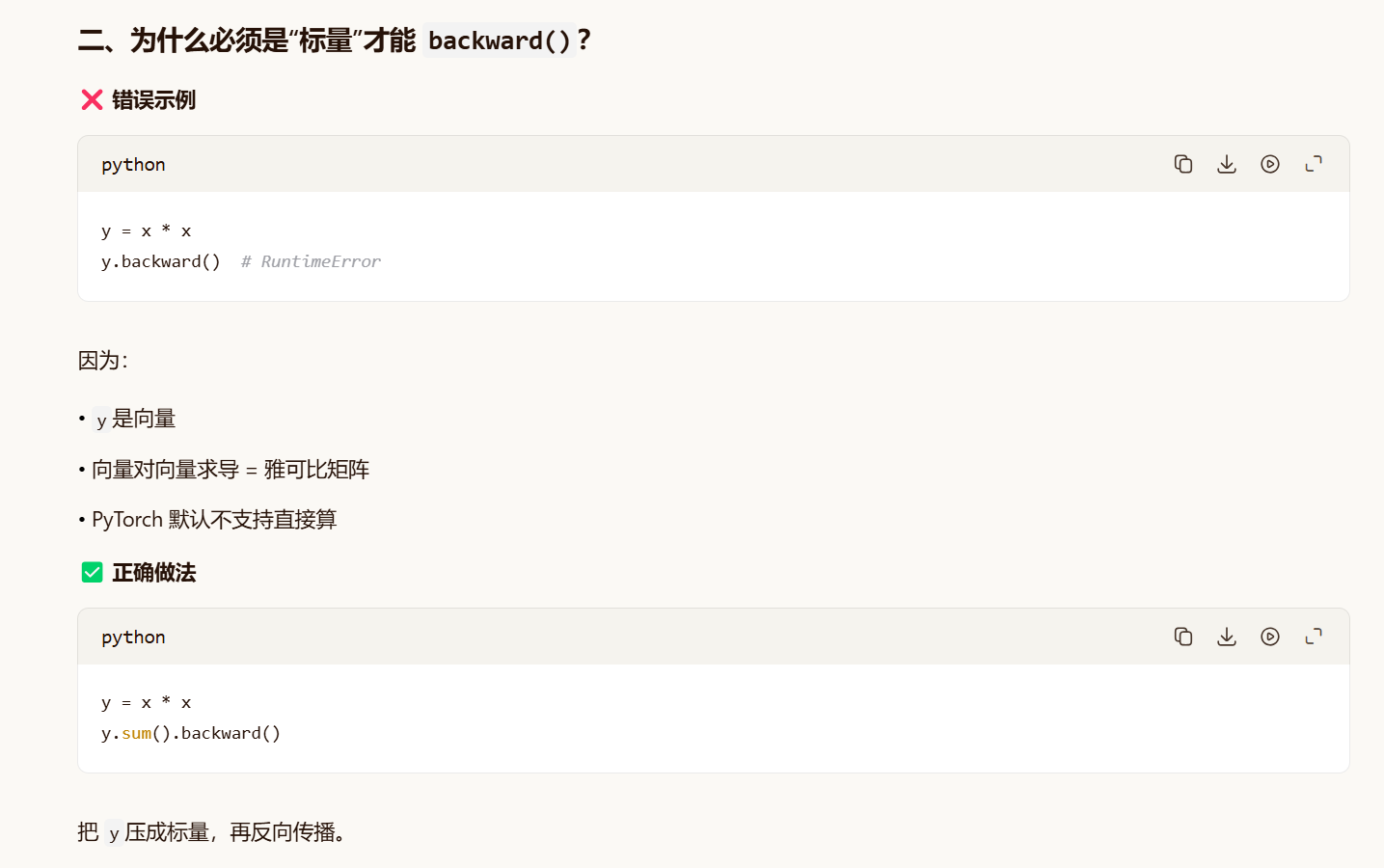
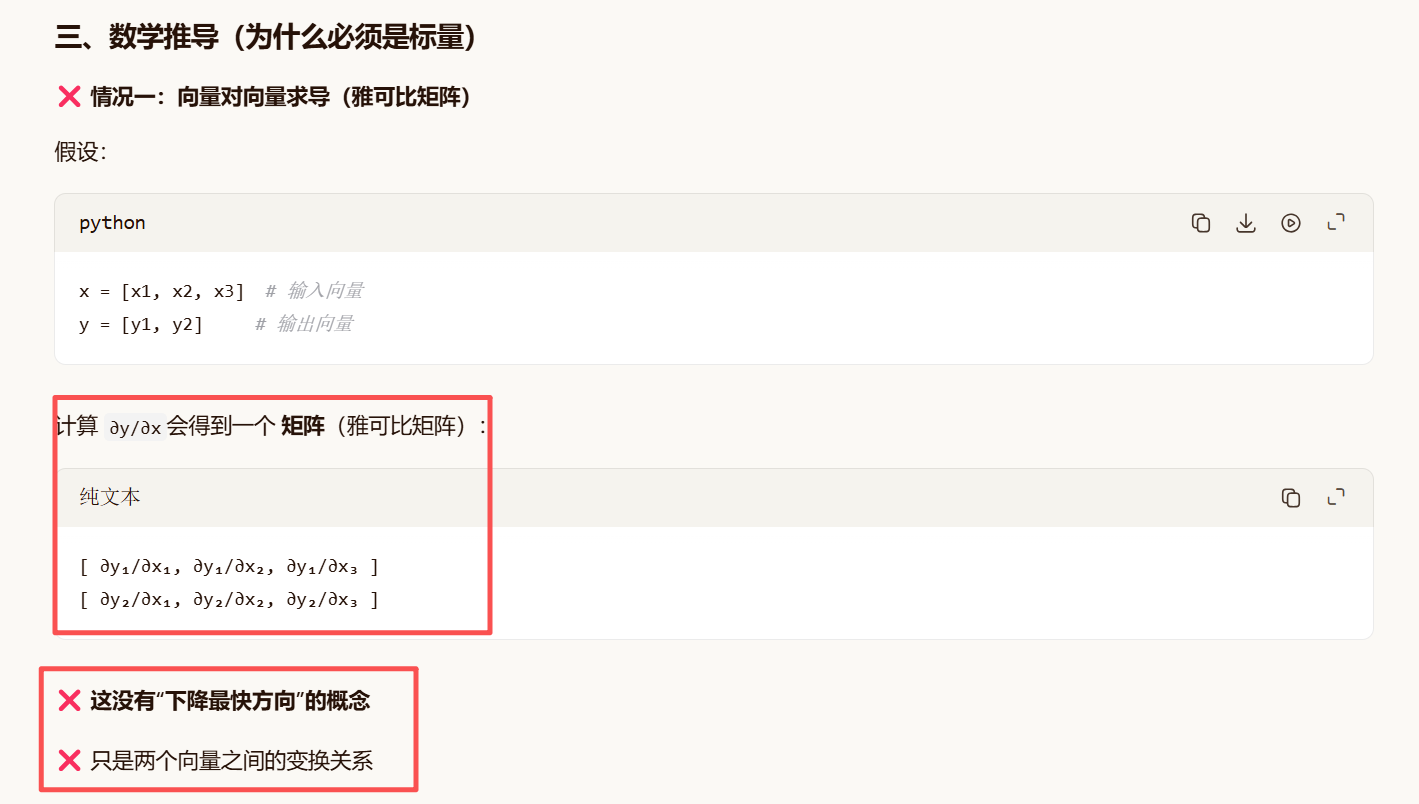
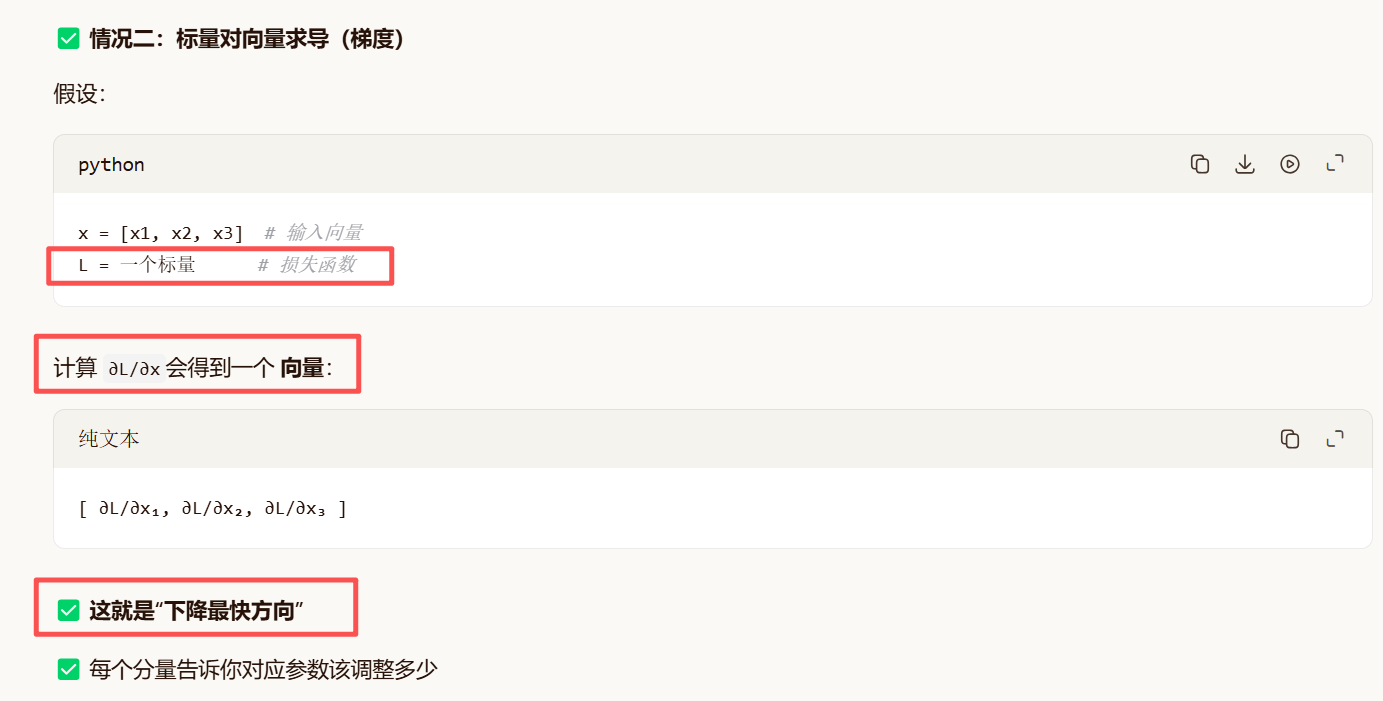
标量才能反向传播;

拓展:
默认梯度累加:所以一般要清0