Partition分区
hashPartitioner

自定义分区器
以上案例中,如果我们希望将hello、lisi结果输出到同一个文件中、zhangsan结果输出到一个文件中、wangwu结果输出到一个文件中,那么就可以自定义分区器方式来自定义哪些数据分配到相同的Reduce进行处理。
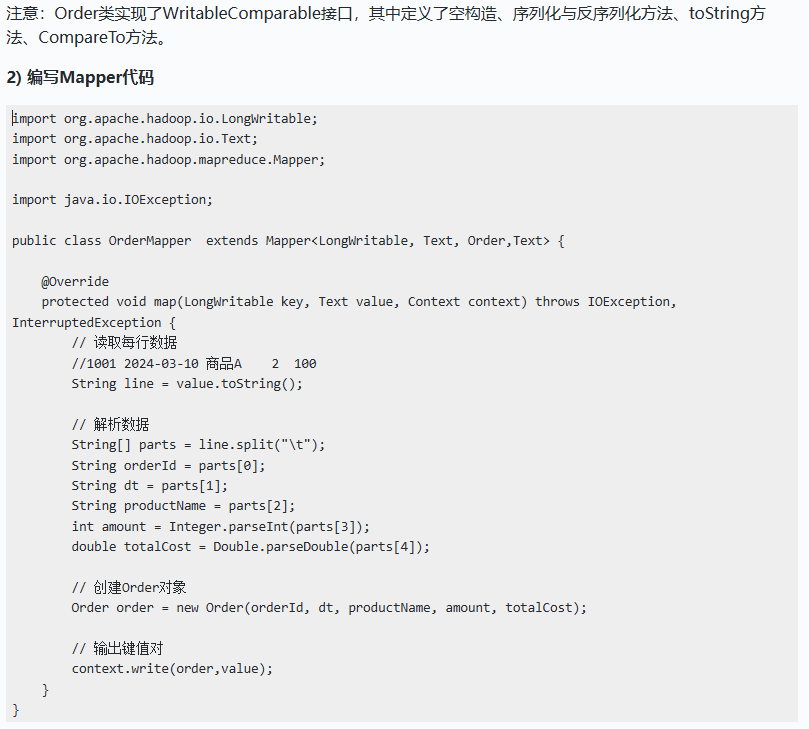
自定义分区器需要创建类继承Partitioner并重写getPartition方法,在该方法中控制数据分区的策略,然后在Driver代码中通过设置"job.setPartitionerClass(CustomPartitioner.class)"来使用自定义分区,另外还需要根据自己定义分区的个数在Driver代码中设置对应的ReduceTask个数,否则MapReduce会使用默认Reduce Task为1,导致自定义分区器不起作用或者报错。
下面对以上案例自定义分区类,实现将hello、lisi结果输出到同一个文件中、zhangsan结果输出到一个文件中、wangwu结果输出到一个文件中。
- 自定义分区类
MyPartitioner.class:
java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
String key = text.toString();
if(key.equals("hello") || key.equals("lisi")){
return 0;
}else if(key.equals("zhangsan")){
return 1;
}else{
return 2;
}
}
}
MapReduce排序
MapReduce的三次排序
在MapReduce处理数据过程中,无论在业务逻辑上是否需要,Map Task和Reduce Task都会按照key对数据进行排序,Map和reduce两个阶段中涉及到三次排序,具体如下:
第一次排序发生在Map阶段的磁盘溢写时:当MapReduce的环形缓冲区达到溢写阈值时,在数据刷写到磁盘之前,会对数据按照key的字典序进行快速排序,以确保每个分区内的数据有序。
第二次排序发生在多个溢写磁盘小文件合并的过程中:经过多次溢写后,Map端会生成多个磁盘文件,这些文件会被合并成一个分区有序且内部数据有序的输出文件,从而确保输出文件整体有序。
第三次排序发生在Reduce端:Reduce任务在获取来自多个Map任务输出文件后,进行合并操作并通过归并排序生成每个Reduce Task处理的分区文件整体有序。
MapReduce排序案例
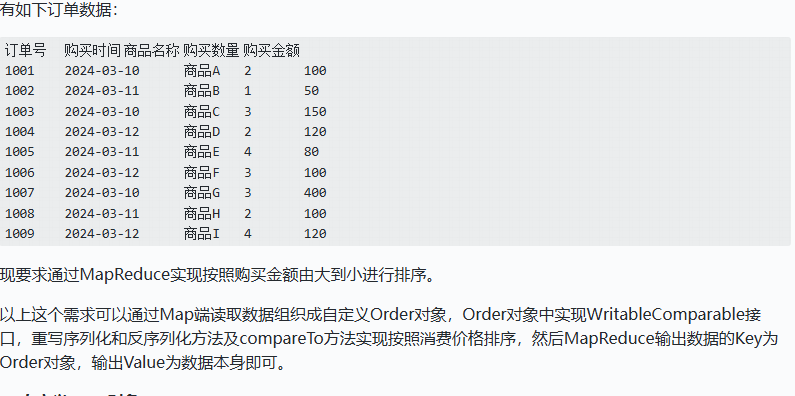
- 自定义Bean对象
Order.class:
java
/**
* 订单信息
*/
public class Order implements WritableComparable<Order> {
private String orderId;
private String dt;
private String productName;
private int amount;
private double totalCost;
// 无参构造方法
public Order() {
}
// 带参构造方法
public Order(String orderId, String dt, String productName, int amount, double totalCost) {
this.orderId = orderId;
this.dt = dt;
this.productName = productName;
this.amount = amount;
this.totalCost = totalCost;
}
// Getter和Setter方法
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getDt() {
return dt;
}
public void setDt(String dt) {
this.dt = dt;
}
public String getProductName() {
return productName;
}
public void setProductName(String productName) {
this.productName = productName;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public double getTotalCost() {
return totalCost;
}
public void setTotalCost(double totalCost) {
this.totalCost = totalCost;
}
@Override
public String toString() {
return "Order{" +
"orderId='" + orderId + '\'' +
", dt='" + dt + '\'' +
", productName='" + productName + '\'' +
", amount=" + amount +
", totalCost=" + totalCost +
'}';
}
// 实现序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(dt);
out.writeUTF(productName);
out.writeInt(amount);
out.writeDouble(totalCost);
}
// 实现反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
orderId = in.readUTF();
dt = in.readUTF();
productName = in.readUTF();
amount = in.readInt();
totalCost = in.readDouble();
}
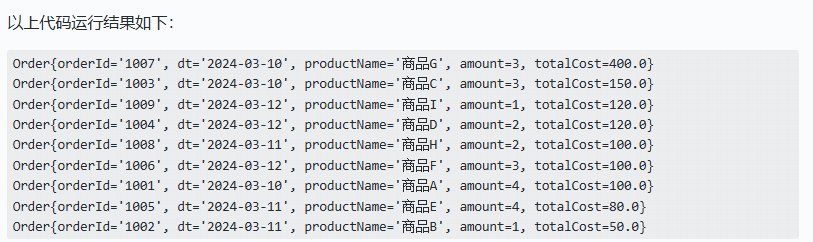
@Override
public int compareTo(Order o) {
//按照总价格倒序排序
if(this.totalCost > o.totalCost){
return -1;
}else if(this.totalCost < o.totalCost){
return 1;
}else{
return 0;
}
}
}

- 编写Driver代码
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OrderDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取配置信息及job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置Driver 程序对应的jar/类
job.setJarByClass(OrderDriver.class);
//3.设置Mapper和Reducer对应的类
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
//4.设置Mapper输出key、value类型
job.setMapOutputKeyClass(Order.class);
job.setMapOutputValueClass(Text.class);
//5.设置最终输出K,V类型
job.setOutputKeyClass(Order.class);
job.setOutputValueClass(NullWritable.class);
//6.设置数据输入和结果写出路径
FileInputFormat.setInputPaths(job,new Path("data/orderinfo.txt"));
FileOutputFormat.setOutputPath(job,new Path("output3/"));
//7.运行任务,运行成功返回true
boolean success = job.waitForCompletion(true);
if (success) {
// 任务执行成功的逻辑
System.out.println("任务执行成功");
} else {
// 任务执行失败的逻辑
System.out.println("任务执行失败");
}
}
}
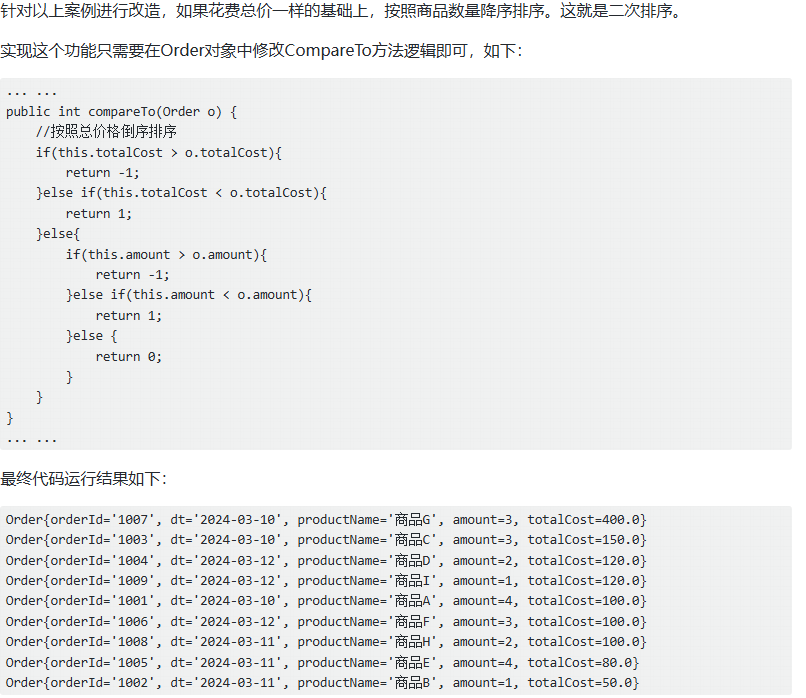
二次排序案例
分区内排序案例
