文章目录
-
- [一、问题:Agent 到底是什么?](#一、问题:Agent 到底是什么?)
- 二、什么是驾驭工程?
- [三、AI-7D-SATS 的四层驾驭架构](#三、AI-7D-SATS 的四层驾驭架构)
- [四、第一层:Skill --- 标准化的原子能力](#四、第一层:Skill — 标准化的原子能力)
-
- [4.1 严格的输入输出契约](#4.1 严格的输入输出契约)
- [4.2 BaseSkill 的模板方法模式](#4.2 BaseSkill 的模板方法模式)
- [4.3 自动发现的注册中心](#4.3 自动发现的注册中心)
- [五、第二层:Agent --- 驾驭体](#五、第二层:Agent — 驾驭体)
-
- [5.1 三种推理策略(Strategy Pattern)](#5.1 三种推理策略(Strategy Pattern))
- [5.2 AgentContext --- 推理状态容器](#5.2 AgentContext — 推理状态容器)
- [5.3 ReAct 循环里的决策机制](#5.3 ReAct 循环里的决策机制)
- [5.4 Plan-and-Execute 的自动重规划](#5.4 Plan-and-Execute 的自动重规划)
- [六、第三层:Orchestrator --- 薄薄的协作层](#六、第三层:Orchestrator — 薄薄的协作层)
-
- [6.1 从 800 行 if/elif 到 100 行路由层](#6.1 从 800 行 if/elif 到 100 行路由层)
- [6.2 三层降级路径](#6.2 三层降级路径)
- [6.3 SkillPipeline:静态链式编排](#6.3 SkillPipeline:静态链式编排)
- [七、第四层:LLM Router --- 给 LLM 也加一层 Harness](#七、第四层:LLM Router — 给 LLM 也加一层 Harness)
-
- [7.1 LLM Router 的解析顺序](#7.1 LLM Router 的解析顺序)
- [7.2 FallbackManager 的健康感知](#7.2 FallbackManager 的健康感知)
- [7.3 配套的两个支撑系统](#7.3 配套的两个支撑系统)
- 八、可观测性:每一步都看得见
-
- [8.1 实时 SSE 事件流](#8.1 实时 SSE 事件流)
- [8.2 完整 Trace 持久化](#8.2 完整 Trace 持久化)
- [九、配置驱动:Agent 即数据](#九、配置驱动:Agent 即数据)
- 十、五条设计原则
- 十一、实际效果
- 十二、写在最后
当 AI Agent 系统逐渐复杂,我们需要一套工程化的方法来"驾驭"它。本文以 AI-7D-SATS 智能平台的真实架构为蓝本,讲清楚 Harness Engineering(驾驭工程)如何把零散的能力打磨成可观测、可配置、可演进的工程制品。
一、问题:Agent 到底是什么?
最朴素的实现是把 Agent 写成 Skill 的薄包装。"帮我生成脚本"就调脚本生成 Skill,"帮我分析根因"就调根因分析 Skill。Agent 没有思考能力,只是一个透传层。这种实现看起来"能跑",但当业务真实复杂起来,就会暴露三个连锁问题:
1. 编排器职责膨胀
一个 800 行的 if/elif 链,所有意图、所有领域知识、所有工具调用全集中在它身上,改一处牵一片。
2. Agent 没有恢复能力
Skill 失败就是任务失败,没有重试、没有降级、没有 replan。
3. 黑盒不可观测
用户只能看到最终结果,过程中的推理、Skill 选择、决策点全在日志里漂着,没法做事后审计、调优和自进化。
这就像把一堆零散的工具随意塞进工具箱------能用,但谈不上工程。我们需要的不是工具的堆砌,而是对工具的驾驭。
二、什么是驾驭工程?
Harness 这个词在英文里有"驾驭、驯服、整合利用"的含义。驾驭工程的核心命题是:
单个能力只是原材料。经过标准化、编排、保护、路由和观测之后,它们才能成为可靠的工程制品。
一套合格的驾驭体系必须同时具备:
| 维度 | 具体含义 |
|---|---|
| 原子能力 | 最小、自治、可独立测试的功能单元 |
| 标准接口 | 让能力之间能正确对接、彼此替换 |
| 编排逻辑 | 按特定推理拓扑把能力组合成更高阶的工作 |
| 保护机制 | 故障隔离,防止局部失败级联放大 |
| 可观测性 | 运行状态实时可见,推理过程完整留痕 |
| 路由策略 | 根据任务特征把请求送到最合适的处理者 |
驾驭工程不是能力的简单集合,而是一个经过精心设计、自身就有结构和智能的独立系统。
三、AI-7D-SATS 的四层驾驭架构
我们把这套思想落地为四层模型,每一层都有自己的契约、状态和保护机制:
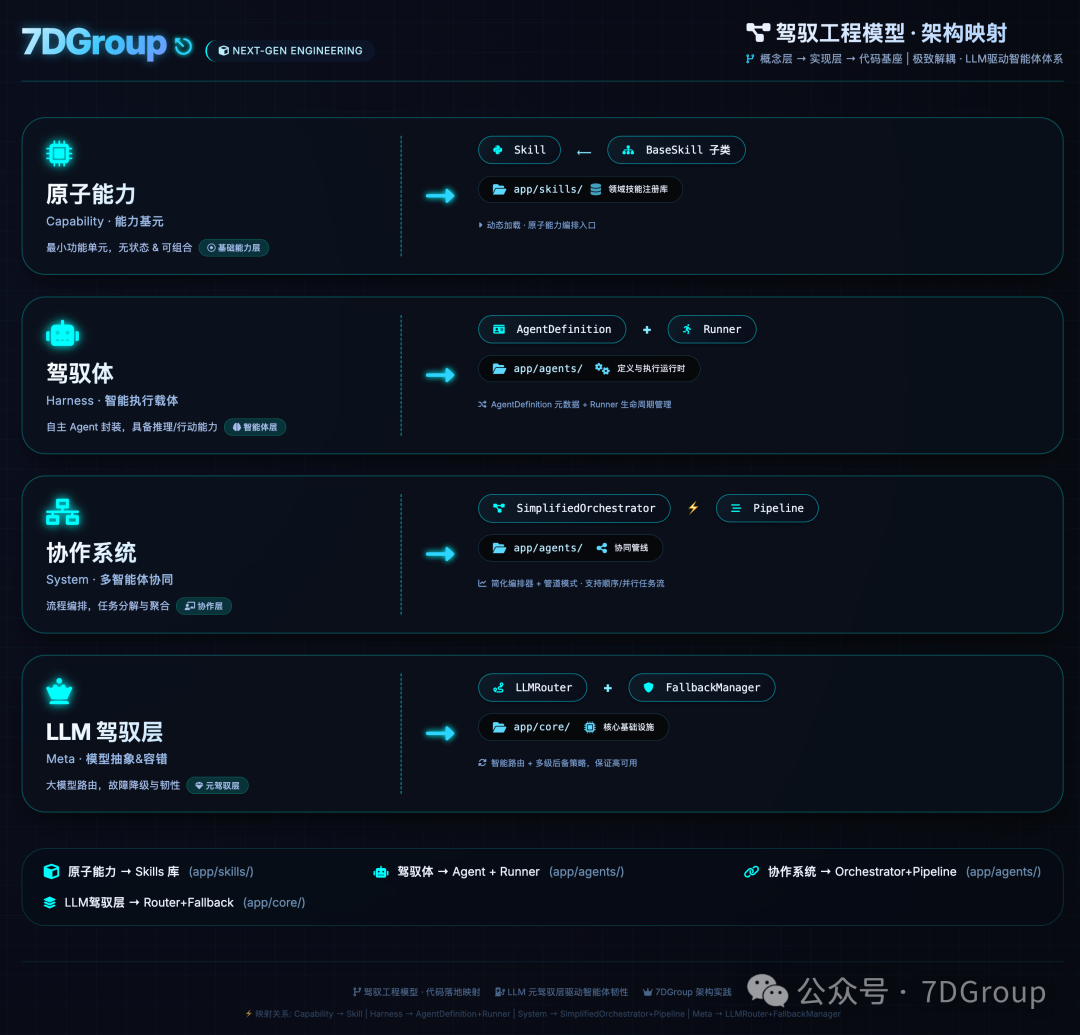
- 第一层:Skill --- 标准化的原子能力
- 第二层:Agent --- 驾驭体(推理引擎 + 状态管理 + 故障恢复)
- 第三层:Orchestrator --- 薄薄的协作层
- 第四层:LLM Router --- 给 LLM 也加一层 Harness
特别值得提的是第四层------LLM 驾驭层。我们不仅驾驭 Skill,也驾驭 LLM 本身。
四、第一层:Skill --- 标准化的原子能力
4.1 严格的输入输出契约
每个 Skill 都通过同一份 Pydantic 契约对外:
python
class SkillInput(BaseModel):
data: dict
context: dict
options: dict
class SkillOutput(BaseModel):
success: bool
error: str | None
warnings: list[str]
skill_name: str
skill_version: str
execution_time_ms: int
confidence: float = 1.0
reasoning: str = ""
result: Any注意 confidence 和 reasoning 这两个字段------它们不是装饰,是后续 Agent 决策"要不要继续往下走"的核心依据。一个低置信度的输出会让上层 Agent 选择重试或换条路,这就是驾驭工程里"局部状态指导全局决策"的具体体现。
4.2 BaseSkill 的模板方法模式
所有 Skill 子类只关心一件事:_execute() 里写业务逻辑。剩下的边界工作由 BaseSkill.execute() 统一处理:
python
async def execute(self, input: SkillInput) -> SkillOutput:
start = time.monotonic()
err = self.validate_input(input)
if err:
return SkillOutput.fail(error=err)
try:
output = await self._execute(input)
except Exception as e:
output = SkillOutput.fail(error=str(e))
output.skill_name = self.name
output.execution_time_ms = int((time.monotonic() - start) * 1000)
return output子类永远不需要操心计时、版本号、异常吞吐------这些一致性是模板方法保证的。标准化不是规范文档,是用代码强约束的边界。
4.3 自动发现的注册中心
SkillRegistry 是一个单例,启动时通过 pkgutil.iter_modules 扫描 app/skills/ 包,把所有 BaseSkill 子类自动注册:
python
def _discover_skills(self) -> None:
for importer, module_name, is_pkg in pkgutil.iter_modules(...):
module = importlib.import_module(...)
for attr_name in dir(module):
attr = getattr(module, attr_name)
if issubclass(attr, BaseSkill) and not isabstract(attr):
self._skills[attr.metadata.name] = attr()写一个新 Skill,0 配置 就能被全平台用上。注册中心还提供 validate_skill_names(),在 Agent 创建/更新接口里前置校验,防止配置层引用不存在的 Skill。注册→校验→调用形成完整的反馈闭环。
五、第二层:Agent --- 驾驭体
这是整个架构的核心转变。Agent 不再是 Skill 的薄壳,而是一个有独立智能、可自主推理、可恢复故障的驾驭体。
5.1 三种推理策略(Strategy Pattern)
Agent 的推理引擎用经典的策略模式实现,所有策略继承自同一个抽象基类:
python
STRATEGY_MAP = {
"react": ReActStrategy,
"cot": CoTStrategy,
"plan_and_execute": PlanAndExecuteStrategy,
}| 策略 | 模式 | 适用场景 | 失败处理 |
|---|---|---|---|
| ReAct | 思考→行动→观察→再思考 | 需要动态决策的复杂分析 | 自动 retry / skip 换 Skill |
| CoT | 先完整推理生成计划→顺序执行→LLM 汇总 | 逻辑清晰的分析任务 | 单步失败仅 skip |
| Plan-and-Execute | 生成计划→执行→失败时 LLM 重新规划 | 多步骤系统化任务 | 自动 replan(最多 2 次) |
关键设计 :三种策略共用同一个 AgentContext 和 on_event 回调,可以在不改 Runner 的前提下随便加新策略。
5.2 AgentContext --- 推理状态容器
Agent 在执行过程中维护一个跨步骤的状态容器:
python
class AgentContext(BaseModel):
task: str
system_prompt: str = ""
available_skills: list[str]
reasoning_steps: list[ReasoningStep]
skill_results: dict[str, Any]
current_step: int = 0
max_steps: int = 10
status: str = "running"skill_results 是这个设计里最巧妙的字段------它把前一个 Skill 的输出作为 SkillInput.context 自动注入下一个 Skill,实现了信息有序传递。
python
inp = SkillInput(
data=skill_input_data,
context=dict(context.skill_results),
)
output = await skill.execute(inp)
if output.success:
context.skill_results[action] = output.result这就是"驾驭"的具体含义:不是把三个工具摆在一起,而是按特定推理逻辑让它们协同思考。
5.3 ReAct 循环里的决策机制
以 ReAct 为例,看 LLM 每一步必须返回的结构化决策:
json
{
"thought": "...",
"action": "skill_name | FINISH",
"action_input": { "...": "..." },
"decision_reasoning": "为什么选这个动作"
}核心循环大致是:
python
while current_step < max_steps:
raw = await llm.ainvoke(messages)
parsed = _parse_json(raw)
if action == "FINISH":
return
output = await skill.execute(...)
if output.success:
context.skill_results[action] = output.result
else:
decision = "retry"注意 _parse_json 这种细节------它会兜底处理 LLM 输出的 markdown 围栏。这种"工程化的细节"才是驾驭工程区别于学术 Demo 的关键。
5.4 Plan-and-Execute 的自动重规划
最值得一提的是 Plan-and-Execute 策略的失败恢复。当某一步执行失败时,Runner 不是直接放弃,而是把"已完成步骤 + 失败步骤 + 错误信息 + 可用 Skill"打包丢给 LLM,生成一份修订后的剩余计划:
python
async def _replan(self, context, skills_text, llm, completed, failed_step, error):
replan_prompt = f"""The previous plan step failed:
- Failed step: {failed_step}
- Error: {error}
- Completed: {completed}
Generate a revised plan."""
response = await llm.ainvoke(...)
return _parse_json(response.content)["plan"]max_replans = 2 的硬上限保证不会无限重规划。这就是驾驭体最珍贵的能力:单点故障不会扩散成系统故障。
六、第三层:Orchestrator --- 薄薄的协作层
6.1 从 800 行 if/elif 到 100 行路由层
老的 OrchestratorAgent 是一个 LangGraph 工作流,800 行硬编码意图分支。重构后的 SimplifiedOrchestrator 只做四件事:
python
async def stream(self, session_id, user_message, db_session):
# 1. 关键词快路径
if any(kw in user_message for kw in EXECUTION_KEYWORDS):
yield from self._legacy.stream(...)
return
# 2. 从数据库加载所有 is_active = True 的 Agent
agents = await db_session.execute(
select(AgentDefinition).where(AgentDefinition.is_active == True)
)
# 3. LLM 意图识别 → 选出最匹配的 Agent
parsed = json.loads(await llm.ainvoke(intent_prompt))
matched = next(a for a in agents if a.id == parsed["agent_id"])
# 4. 委托给 AgentRunner.execute_stream
runner = AgentRunner(matched, registry, db)
async for chunk in runner.execute_stream(...):
yield chunk核心理念 :让每个驾驭体拥有自己的智能,而不是把所有智能堆在一个中央控制器里。新增 Agent 完全不需要改编排器------它只需要在数据库里多一行。
6.2 三层降级路径
SimplifiedOrchestrator.stream() 的设计还隐藏了一个重要的鲁棒性细节------三层降级:
Agent 路由(LLM 意图识别成功)
↓ 失败 / 没匹配到
Legacy Orchestrator(LangGraph,处理 subprocess 类任务)
↓ 失败
直接 LLM Chat(SYSTEM_PROMPT + 知识库 RAG + 历史)任何一层失败都能优雅降级到下一层,用户永远会得到一个有意义的响应,而不是 500 错误。
6.3 SkillPipeline:静态链式编排
除了 Agent 自主推理,平台还提供了三个预定义的 SkillPipeline,适用于流程固定的标准化任务:
python
PIPELINE_REGISTRY = {
"full_analysis": [指标解读 → 根因分析 → 调优建议],
"test_design": [需求分析 → 场景设计 → 脚本生成],
"capacity_review": [指标解读 → 容量预测 → 报告生成],
}注意 Pipeline 与 Agent 的差异:
- Pipeline 是确定的:写死步骤,适合"流程不变,只换数据"。
- Agent 是动态的:LLM 自己挑 Skill 顺序,适合"流程也会随场景变"。
驾驭工程不是非此即彼------用最合适的工具应对最合适的场景。
七、第四层:LLM Router --- 给 LLM 也加一层 Harness
很多人忽略了一件事:LLM 本身也是不稳定的依赖。供应商挂掉、API 限流、模型下线,任何一种都会让上层 Agent 直接失血。我们给 LLM 也加了一层驾驭。
7.1 LLM Router 的解析顺序
Agent 显式指定(provider/model)
↓ 没指定
能力匹配(min_context_window / function_calling / vision_support)
↓ 没需求
全局活跃配置(LLMActiveConfig 表)
↓
健康感知降级(FallbackManager.resolve_provider)
↓
ProviderFactory.create(...) → BaseChatModel每一层都是显式的、可观察的、可数据库驱动的。Agent 可以说"我要 32K context + function calling",LLM Router 就在 ProviderRegistry 里挑出符合的模型;也可以什么都不说,走全局默认。
7.2 FallbackManager 的健康感知
python
async def resolve_provider(self, preferred: str) -> str:
if self.is_available(preferred):
return preferred
chain = await self.get_fallback_chain()
for fallback_id in chain:
if self.is_available(fallback_id):
return fallback_id
return preferred最后那个"兜底再试一次"很关键------它体现了降级要保守、不要激进的工程哲学:即便所有备选都不可用,也至少给 preferred 一次机会,而不是直接报错。
7.3 配套的两个支撑系统
- ProviderRegistry:数据库驱动的供应商画像,每个模型带 max_context_window / streaming_support / function_calling / vision_support / 价格,内存缓存 5 分钟 TTL。
- KeyVault:API Key 加密存储,支持 rotation 时间戳,日志和接口出口都用 masked_key。
八、可观测性:每一步都看得见
驾驭工程把可观测性当作重要功能,而不是事后补的日志。这体现在两层:
8.1 实时 SSE 事件流
AgentRunner.execute_stream() 通过 SSE 把每个事件实时推送到前端:
| 事件类型 | 时机 | Payload 关键字段 |
|---|---|---|
| reasoning_step | LLM 给出新一步思考 | step_number, thought |
| skill_call | 准备调用 Skill | skill_name, input_summary |
| skill_result | Skill 执行完毕 | success, confidence, result_summary |
| decision | 推理引擎做出决策 | decision_type, reasoning |
| complete | 任务成功结束 | final_result, total_steps |
| error | 不可恢复的失败 | message, last_successful_step |
| done | 流结束 | --- |
事件先进 events_buffer,然后批量 yield------这样既保证顺序,又避免在 LLM 流式过程中频繁握手。
前端能看到的运行轨迹是这样的:
推理 Step 1: 分析用户需求,需要先解读当前的性能指标...
调用 Skill: 指标解读 (输入: TPS=500, P99=2000ms, 错误率=5%)
✅ Skill 完成: 指标解读 (耗时 1200ms, 置信度 92%)
决策: continue → 需要进一步定位根因
推理 Step 2: P99 异常偏高,需要分层分析...
调用 Skill: 根因定位
✅ Skill 完成: 根因定位 (耗时 2300ms, 置信度 87%)
完成! 共 4 步,使用 Skills: 指标解读, 根因定位, 调优建议8.2 完整 Trace 持久化
执行结束后,完整轨迹被写入 agent_execution_traces + agent_reasoning_steps 两张表:
sql
agent_execution_traces: id, agent_id, task, status, final_result, total_execution_time_ms, created_at
agent_reasoning_steps: id, trace_id, step_number, thought, action, action_input(JSON), observation, decision (next/retry/skip/complete/abort), decision_reasoning, execution_time_ms, timestamp注意 decision 字段是枚举的------让事后分析能快速回答"这次任务为什么失败"、"哪个 Skill 经常被 retry"、"哪种策略的 abort 率最高"。
这份数据为三件事铺路:
- 审计:任何一次回答都能完整重放推理过程。
- 调优:基于 execution_time_ms 和 decision 分布,识别瓶颈 Skill。
- 自进化:成功的轨迹可以入库为知识库案例,回喂未来的推理。
九、配置驱动:Agent 即数据
每个 Agent 的全部行为都存在 agent_definitions 表的一行里:
python
class AgentDefinition(Base):
name: str
system_prompt: str
reasoning_strategy: str
available_skills: str
llm_model: str
provider: str | None
temperature: float
max_reasoning_steps: int
is_active: bool平台启动后会写入 10 个内置 Agent。每个 Agent 的策略都是按业务特性精心选的:
| Agent | 策略 | 原因 |
|---|---|---|
| 需求解析 | cot | 一次性逻辑分析,无需动态切换 |
| 脚本生成 | react | 需根据中间结果调整生成路径 |
| 场景设计 | plan_and_execute | 多步任务,需要失败重规划 |
| 指标解读 | react | 不同指标走不同分支 |
| 根因定位 | react | 分层探索,需要多轮(max_steps=12) |
| 调优建议 | cot | 给定根因后逻辑一次性 |
| 报告生成 | plan_and_execute | 多模块汇总 |
| 容量规划 | react | 预测 + 解读交替 |
修改任何字段都不需要改代码、不需要重启:Agent 即数据。
十、五条设计原则
把上面所有细节抽象出来,驾驭工程的五条核心原则是:
原则一:原子能力标准化
所有 Skill 共享 SkillInput → SkillOutput 契约,带 confidence/reasoning/timing 元数据。标准化用代码强约束,而不是文档约定。BaseSkill 的模板方法把校验、计时、版本号、异常吞吐统一处理,业务逻辑只关心 _execute()。
原则二:驾驭体有独立智能
Agent 不是 Skill 的容器,而是一个推理引擎。它通过策略模式自主推理(ReAct / CoT / Plan-and-Execute),通过 AgentContext 维护跨步骤状态,通过 replan 机制恢复故障。单点故障不会变成全局故障。
原则三:配置驱动而非代码驱动
Agent 的全部行为(角色、策略、可用 Skill、LLM 参数)都在数据库里。新增/修改 Agent 不需要重启,不需要改代码,不需要改编排器。编排器变得很薄,智能下沉到驾驭体本身。
原则四:可观测性是重要的能力
SSE 实时推送每一步推理,完整轨迹持久化到数据库,decision 字段枚举 next/retry/skip/complete/abort,让事后分析有抓手。没有可观测性的 Agent 就像没有仪表盘的飞机------你不知道它在想什么,也不知道它为什么这么做。
原则五:故障隔离与优雅降级
每一层都有降级路径:Skill 失败可被 retry/skip,Plan-and-Execute 可 replan,LLM 不可用时 FallbackManager 切换供应商,Agent 路由失败回退到 legacy,legacy 失败再回退到直接 LLM chat。用户永远得到一个有意义的响应。
十一、实际效果
驾驭工程架构上线后,我们观察到几个显著的变化:
| 维度 | 旧架构 | 新架构 |
|---|---|---|
| 编排器代码量 | 800 行 if/elif | ~140 行薄路由 |
| 新增 Agent 成本 | 改编排器 + 新增 Skill 包装 | 数据库写一行 |
| Agent 调用 Skill | 1 个 | 自主调用 N 个并交叉验证 |
| 故障恢复 | 单 Skill 失败 = 任务失败 | retry / skip / replan / 多层降级 |
| 推理可见性 | 黑盒 | 每一步 thought/action/observation/decision |
| 多 LLM 切换 | 改代码 | 数据库改全局配置 + 健康降级链 |
更重要的是,代码的"可演进性"上了一个台阶:加一个新推理策略只需写一个类,加一个新 Skill 只需写一个子类,加一个新 LLM 供应商只需在 ProviderRegistry 里写一行画像。驾驭工程把"添加能力"从一个工程任务变成一个配置任务。
十二、写在最后
"驾驭"这个词很好地概括了我们对 AI Agent 架构的理解:不是让 Agent 野蛮生长,也不是把所有智能集中在一个中心化的控制器里,而是通过工程化的方法,让每个 Agent 成为一个有结构、有智能、可观测、可配置的独立单元。
如果说 LangChain 给了我们"用 LLM 调工具"的语法,那么驾驭工程给的是用工程化方法管理这些语法的语义------它让你能回答这些原本难以回答的问题:
- 这个 Agent 现在在想什么?→ SSE 实时推送
- 上次失败为什么?→ 完整 Trace + decision 枚举
- 改一个 Agent 的行为要花多大成本?→ 数据库改一行
- LLM 供应商挂了我会怎样?→ FallbackManager 自动切换
- 加一个新的推理策略要花多大成本?→ 写一个 Strategy 子类
下次设计 Agent 系统时,不妨先问自己:你的 Agent 是一堆散乱的工具,还是一个被精心驾驭的智能体?
本文基于 AI-7D-SATS 智能平台的真实架构。该平台后端使用 Python + FastAPI + LangChain/LangGraph,前端使用 Vue 3 + TypeScript,内置 11 个 Skill、10 个专业 Agent、3 种推理策略、3 个标准 Pipeline,支持多 LLM Provider 编排与健康降级。所有 Agent 与 Skill 配置数据库驱动,执行轨迹完整持久化。