
核心流程
生成短链:用户输入长 URL → 生成唯一短链码(如 abc123)→ 拼接域名得到 短域名/abc123 → 存储映射关系 → 返回短链。
访问重定向 :请求 短域名/abc123 → 根据映射关系查询得到长 URL → 返回 HTTP 301(永久)或 302(临时)重定向到长地址。
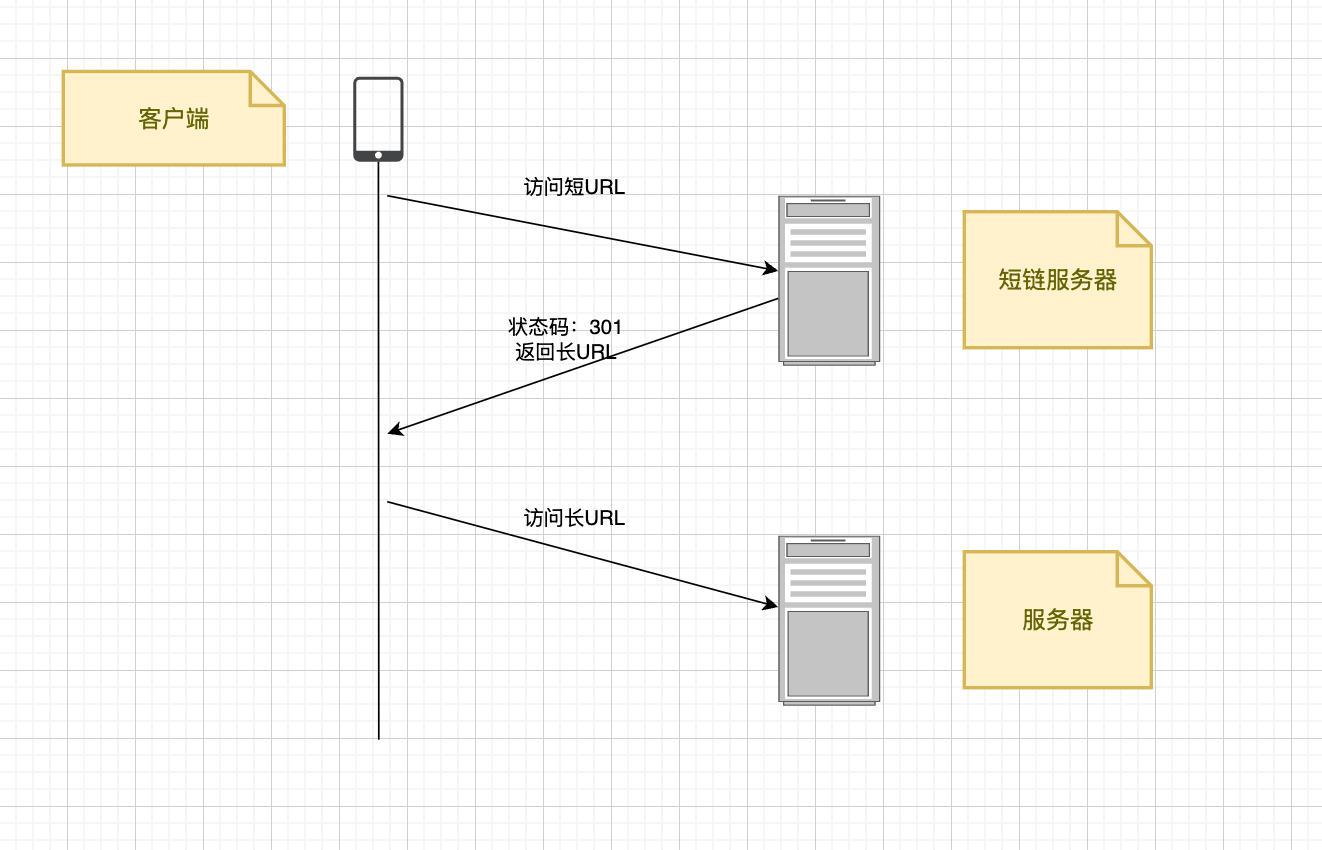
选择301重定向还是302重定向
301 (永久重定向) :浏览器会缓存该关系,下次访问直接走浏览器缓存,减轻短链服务器压力。缺点是无法精确统计每一次的点击数据(如 PV/UV)
302 (临时重定向) :每次访问都会经过短链服务器,方便收集分析数据(地理位置、点击量等)。缺点是服务器压力大
为了减轻服务器压力选择301,方便数据分析选择302
表可以定义为如下
| 字段 | 类型 | 说明 |
|---|---|---|
| short_code | varchar(8) | 短链码,如 abc123 |
| long_url | text | 原始长 URL |
| created_at | datetime | 创建时间 |
关键设计点
方案一:哈希算法(如 MurmurHash)+ 冲突解决
原理:使用高性能、低碰撞的 MurmurHash 算法对长链进行哈希,得到一个 32 位的整数,再将其转化为 62 进制的 6 位字符串。
冲突处理:哈希必然存在碰撞。如果算出的短链在 DB 中已存在(且长链不同),就在长链后面拼接一个固定的"随机盐值",重新计算哈希,直到不冲突为止。
优缺点:实现简单,URL 看起来很随机;但随着数据量增大,碰撞概率增加,检测冲突的 DB 查询开销会变大。
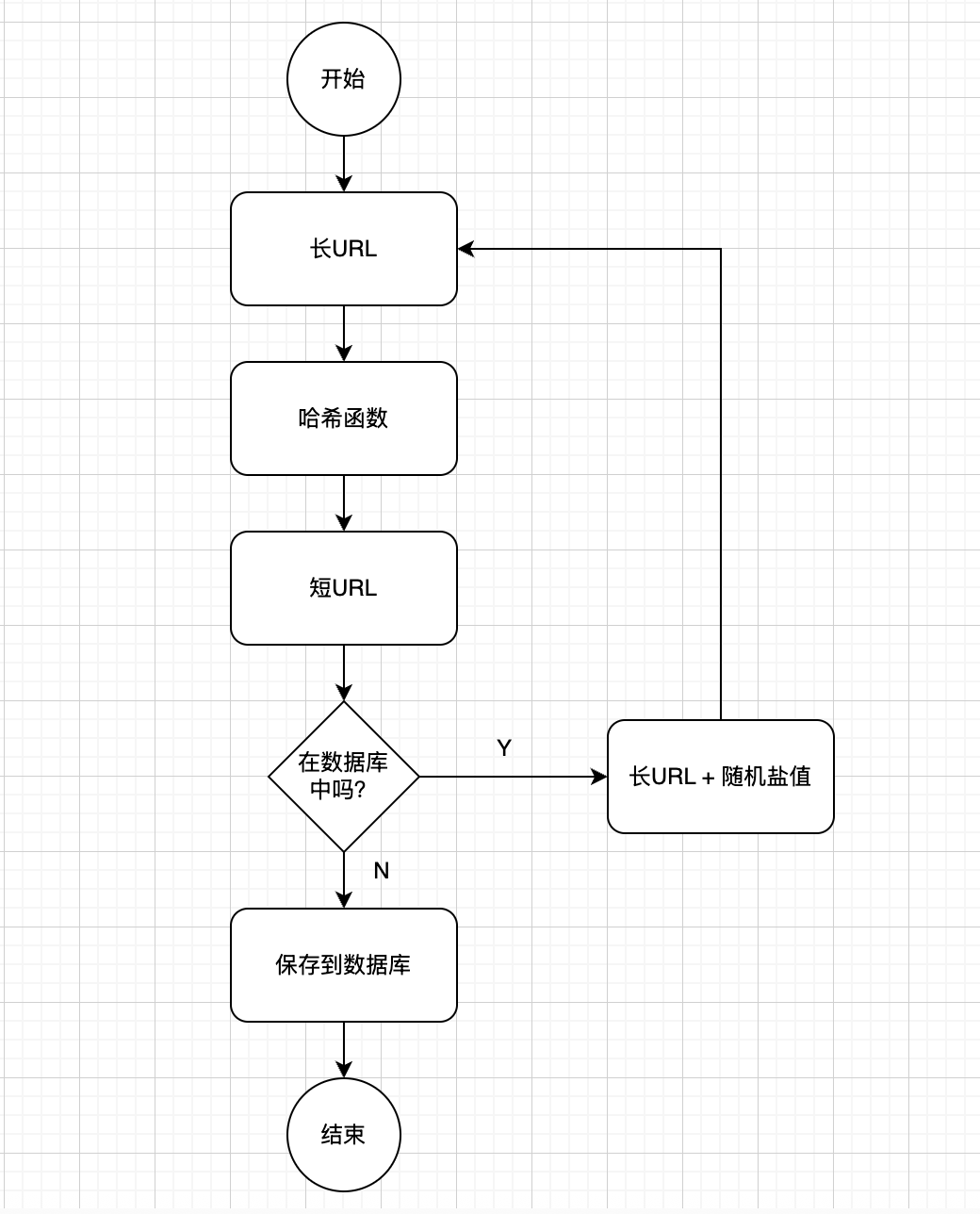
注意:在发生哈希冲突的时候虽然会在长URL后面加随机盐值重新计算哈希值,但是最终存到数据库中的长URL并不会有盐值
方案二:分布式自增 ID + 62 进制转换(推荐)
原理:这是最常用的方案。系统维护一个全局自增的分布式 ID(如 10001、10002),每来一个长链,就分给他一个 ID,然后把这个 10 进制的 ID 转换成 62 进制字符串。
例如:ID 568002355 转换为 62 进制后可能就是 Xy7Z8a。
优缺点:绝对不会冲突,效率极高;但缺点是短链是递增的,容易被别人猜出规律并恶意爬取。
解决递增被猜到的办法:在 62 进制转换后,利用固定的位移或混淆矩阵(Shuffle)将字符串顺序打乱。
系统架构设计
为了支撑海量高并发的访问,短链系统必须采用分层架构。
1. 接入层 (API Gateway / Load Balancer)
Nginx / Gateway:负责负载均衡,限流(防止恶意刷接口导致系统瘫痪)。
2. 逻辑服务层
短链生成服务:负责接收长链,获取全局 ID,转换成 62 进制并写入存储。
短链重定向服务:负责接收短链请求,查询缓存/DB,返回 302 重定向。这两块业务要读写分离,因为读的并发量通常远大于写。
3. 全局发号器 (针对分布式自增 ID 方案)
如果所有服务都去数据库申请自增 ID,数据库会成为瓶颈。
优化方案(号段模式):发号器服务每次去数据库"批发"一批 ID(比如一次拿 10000 个)缓存在内存中。当短链服务来申请时,直接在内存中自增分发。内存发完了,再去数据库拿下一个号段。即便数据库挂了,号段没用完前系统依然能正常工作。
4. 存储与缓存层 (核心)
由于短链系统是典型的 读多写少 场景,缓存是抗住高并发的关键。
数据库:可用关系型(MySQL/PostgreSQL)或 NoSQL(Redis + 持久化 DB)。
缓存:热点短码用 Redis 缓存 <short_code, long_url>,降低 DB 压力
本地缓存 (Guava/Caffeine) + 分布式缓存 (Redis):
使用 Redis 存储 短链 -> 长链 的映射,设置合理的过期时间。
采用 布隆过滤器 (Bloom Filter):用户访问不存在的短链时,布隆过滤器可以直接拦截,防止缓存穿透击垮数据库。
底层数据库:
使用 MySQL 或 NoSQL(如 MongoDB/HBase)。因为主要是 KV 查询,NoSQL 表现更好。
如果用 MySQL,需要对 短链码 字段建立唯一索引。当数据量极大时,按短链码的 Hash 进行分库分表。