前言 :本文将简单介绍一下RabbitMq的工作流程
设想你有两个服务,服务A负责分发消息,服务B负责处理消息, 如果在流量高峰时, 服务A的VIP用户却反馈响应速度很慢, 这该如何解决? 没有什么是加一层中间件不能解决的,如果不能那就加两层. 这里我们添加的中间件正是 RabbitMQ ,那么RabbitMQ是如何处理上述问题的呢,本文将为大家简单分析
1. 核心组件:谁在幕后各司其职?
在解释流程之前,必须先明确 RabbitMQ 的几大核心概念。它们就像快递系统的各个环节:
-
生产者 (Producer):消息的源头,负责发布消息(寄件人)。
-
消费者 (Consumer):消息的终点,负责接收并处理消息(收件人)。
-
Broker:RabbitMQ 服务器实体,包含 Exchange 和 Queue。
-
交换机 (Exchange):消息的中转站。它不存储消息,只负责根据路由规则(Routing Key)把消息分发到对应的队列。
-
队列 (Queue):消息的容器,负责存储消息,直到被消费者消费。
-
绑定 (Binding):建立 Exchange 和 Queue 之间的关联关系(路标)。
-
信道(Channel) : 减少TCP频繁建立和销毁带来的开销, 每条Channel之间独立, 实现多路复用 .
2. 图解:RabbitMQ 核心工作流程
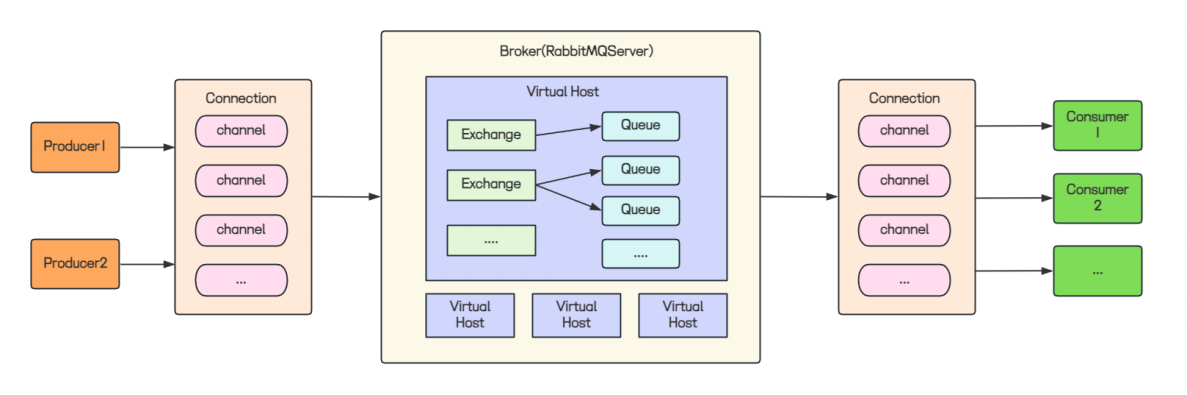
如果把broker 服务器本体比作一个邮局,那么以上的流程就可以视为是利用邮局实现邮件分发的机制, 生产者把货件送到邮局, 消费者从中拿取
1. 建立连接
生产者既然要把货件发送到邮局,那自然不能直接发送, 也就需要和broker建立连接, 这个连接一般是TCP连接. 但是这也带来了一个问题 , 当生产者producer过多时, 频繁创建和销毁TCP连接的开销太大了 ,这该如何做?

这就需要Channel (信道) ,如果把 TCP 连接 比作一条光纤电缆 ,那么 Channel 就是里面一根根独立的光纤丝 。 Channel的核心功能是连接复用 ,Channel在生产者发送消息到仓库中起作用,还在消费者获取信息这一过程中也有参与. 如此一来, 客户端就只需要和建立单个更少的TCP连接通道, 但是然后在这条 TCP 连接内部,划分出成百上千个虚拟的 Channel。每个 Channel 之间完全隔离,独立完成自己的工作,即使一条Channel挂了也不影响其余Channel。这种技术在网络通信中被称为多路复用(Multiplexing)。
2. 消息存储与路由
连接建立 ,消息准备就绪, 接下来就是消息的分发. 这就有一个问题, 消息是直接经由Channel 直接发送到Broker仓库中吗? 自然不是, 因为消息的种类自然有很多, 仓库从
生产者接收到的消息可能有用户消息和订单消息这两种, 为了区分这两种消息, 仓库中引入了不同的Queue(队列)来存放对应的消息类型.
消息的存放在Queue中, 但当我们想要把一条消息发送到多个Queue中,但是消息只有一条我该如何做?
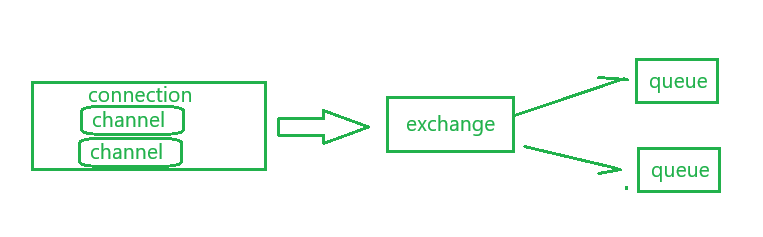
把Channel比作去邮局的路,那Queue就是私人邮箱, 我们当然可以把一封信直接塞入对应的邮箱中, 但当我们想要实现 一信多发时, 这就需要Exchange(交换机) 了 .exchange就好比一个邮局分拣中心,它不存储消息,而是根据接收到的消息的 路由键 (Routing Key) 和交换机自身的类型,以及预先设置的绑定 (Binding) 规则,决定将消息转发到哪些队列 (Queue)。
有了exchange 和binding 就实现了消息和队列之间的解耦
消息经过交换机的路由存储在queue中, 在流量高峰时, 消费者处理不过来, 就可以把消息堆积在queue中防止服务器被打垮; 等到空闲时,把积攒的消息转发给消费者去处理,这就是削峰填谷的基本使用
3. 消息消费
消费者从队列中获取消息并处理消息. 以优先级队列为例, 消息在分发时就为其设置了一个优先级, 优先级高的先被消费. 以云游戏为例, 充值了VIP的用户排队的时间就比普通用户等待时间更短.
消息在从队列中到达消费者手中同样要建立连接,经由信道(Channel)
4.消息确认
如果消息在从队列到达消费者手中出现了丢包等问题,导致消费者没有收到消息,但是queue中的消息已被弹出, 这该如何应对?
这就需要确认应答(ACK)的参与 ,消息并不是在离开queue中就立刻删除, 当消费者在成功接收并处理完一条消息之后,会向RabbitMQ发送一条ACK,RabbitMQ收到之后才会执行安全的删除操作
以上就是RabbitMQ的基本工作流程,如有纰漏还请指出~~