先抓住一条完整链路:从 Cursor、Trae 这类 AI 编程工具,到大模型 API 怎么调用,再到 Function Call、RAG、MCP 和 Agent 到底是什么。
很多概念第一次看会觉得很散:一会儿讲 Prompt,一会儿讲 Token,一会儿又讲 Function Call 和 Agent。其实把它们放到工程流程里看,就会清楚很多:
text
用户需求
-> system prompt / user prompt
-> messages
-> LLM
-> 判断是否需要外部资料或工具
-> RAG / Function Call / MCP
-> 工具返回结果
-> 放回上下文
-> LLM 生成最终答案可以按"工具生态 -> 模型原理 -> API 调用 -> 工具调用 -> Agent"的顺序理解。
AI 编程工具生态
现在常见的 AI 编程工具大概可以分成几类。
国外工具比较常见的是:
- Cursor
- Claude Code
- Codex
- VS Code + AI 插件
国内工具比较常见的是:
- Trae
- Lingma
- CodeBuddy
模型服务平台也有很多选择:
- 阿里云百炼
- DashScope
- ModelScope
- DeepSeek
- OpenAI
- Anthropic Claude
常见模型包括:
- qwen-flash
- qwen-plus
- qwen-max
- deepseek-v3
- deepseek-r1
- Qwen3-Coder-30B-A3B-Instruct
其中,Qwen3-Coder 这类模型更偏向代码生成和编程辅助,也可以用于本地部署。它们适合做代码补全、代码解释、脚本生成、单测生成、重构建议等任务。
AI 编程需要懂代码到什么程度
很多刚接触 AI 编程的人都会问:
AI 都能写代码了,我还需要懂代码吗?
答案是:需要,但不一定一开始就达到专业程序员的水平。
AI 编程真正需要的是:
懂需求,懂基本技术逻辑,会和 AI 交互,能 review AI 写出来的代码。
也就是说,你不一定要从零手写所有代码,但至少要知道:
- 代码输入是什么
- 代码输出是什么
- 中间大概做了什么处理
- 报错是什么意思
- AI 写出来的结果是否符合业务目标
- 什么时候需要让 AI 修改
对业务同学来说,重点不是马上成为程序员,而是学会把需求表达清楚,并且能判断 AI 给出的代码和运行结果是否靠谱。
AI、大模型和生成式 AI
AI 的目标,是让机器完成一些通常需要人类智能才能完成的事情,比如理解语言、识别图片、解决复杂问题、做判断和决策。
如果按技术发展脉络来看,可以粗略分成几层:
- 早期的专家系统:主要靠人提前写好的规则和逻辑。
- 机器学习:让模型从数据里学习规律,用来分类、预测或决策。
- 深度学习:用神经网络处理更复杂的特征和任务。
- 大模型:用更大规模的数据和算力训练通用模型,让模型具备更强的泛化能力。
这里还需要区分两类 AI:分析式 AI 和生成式 AI。
分析式 AI 更擅长判断、分类和预测;生成式 AI 更擅长生成文本、图片、音频和代码。

这两类能力不是互斥的。比如电商评论分析里,模型可以先生成评论摘要,再把评论归类为正向、负向或中性;运维场景里,模型既要理解告警内容,也要生成排查建议。
大模型到底是什么
从工程角度看,大模型本质上可以理解为一个巨大的参数文件。
简单写就是:
text
Model = 神经网络结构 + 参数权重文件如果一个大模型没有联网、没有工具、没有知识库,那么它本质上就是一堆参数。只不过这些参数不是随机的,而是通过大量数据训练出来的。
训练过程可以粗略理解为:
text
大量文本数据
-> 模型不断预测下一个 token
-> 计算预测误差
-> 更新模型参数
-> 误差越来越小
-> 得到最终模型有一种形象说法是:几十 TB 的训练数据,最后被压缩进了更小规模的模型参数里。
这不是严格意义上的文件压缩,而是统计规律和知识模式的压缩。大模型里的知识不是像数据库一样一条一条存储的,而是分布在模型权重中。
大语言模型能做什么
大语言模型可以理解为一种通用自然语言生成模型。它通过大量文本语料训练,学会生成文本、回答问题、总结内容、进行多轮对话,也能在一定程度上写代码和理解代码。
大语言模型的能力可以分成两层。
基础能力包括:
- 语言生成
- 上下文学习
- 世界知识
进一步的能力包括:
- 响应人类指令
- 泛化到没见过的任务
- 代码生成和代码理解
- 连续对话
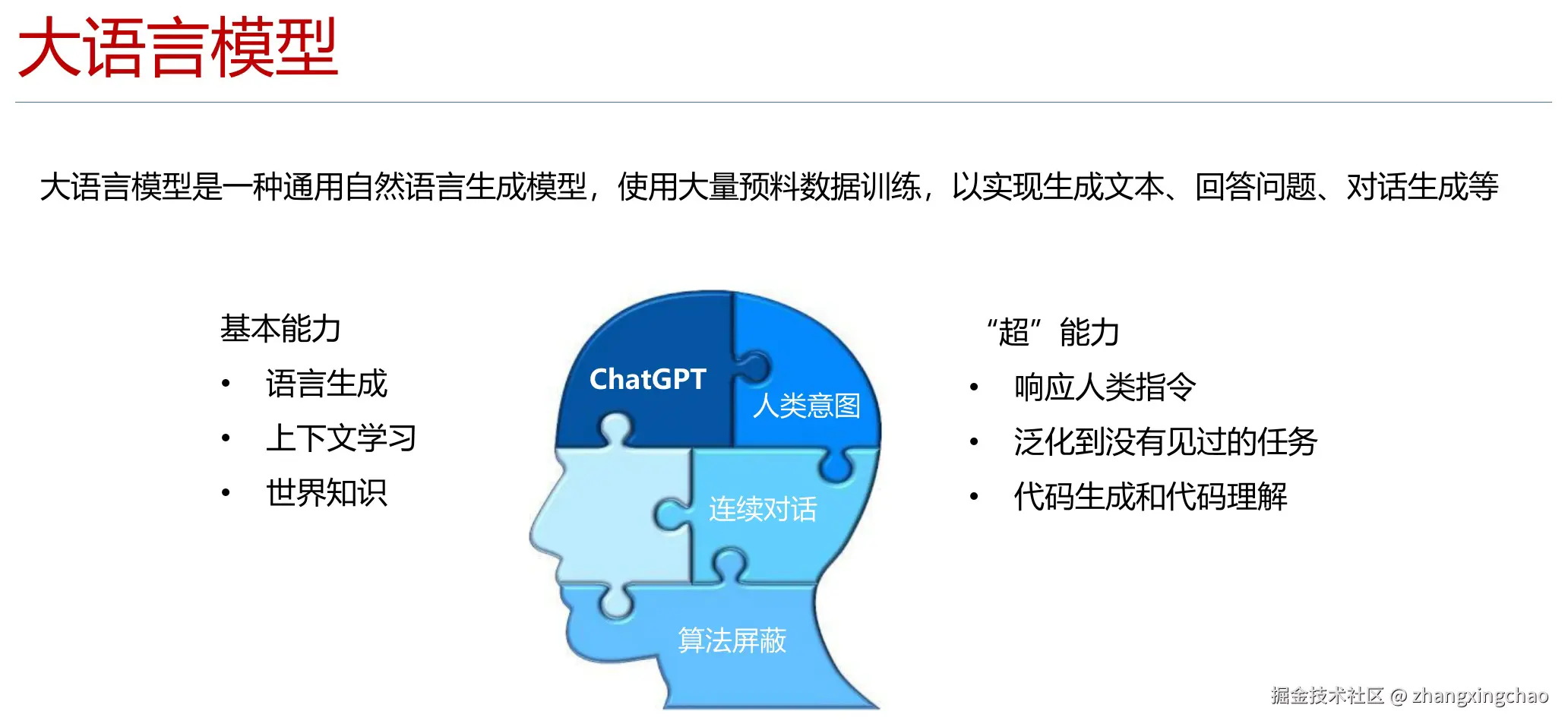
但要注意一点:大模型本身不是业务系统。它更像一个很强的语言和推理引擎。要让它真正解决业务问题,还需要提示词、工具、数据、权限、接口和流程控制。
ChatGPT 是怎么训练出来的
ChatGPT 这类模型并不是只靠"预测下一个词"就直接变成聊天助手的。它还经过了让模型更会听指令、更符合人类偏好的训练过程,其中一个关键方法就是 RLHF,也就是人类反馈强化学习。
可以理解成三步:
- 先用海量文本训练一个基础语言模型,让它具备语言生成能力。
- 再通过人工标注和示例,让模型更像一个会听指令的助手。
- 最后引入 Reward Model,让模型学习什么样的回答更符合人类偏好。
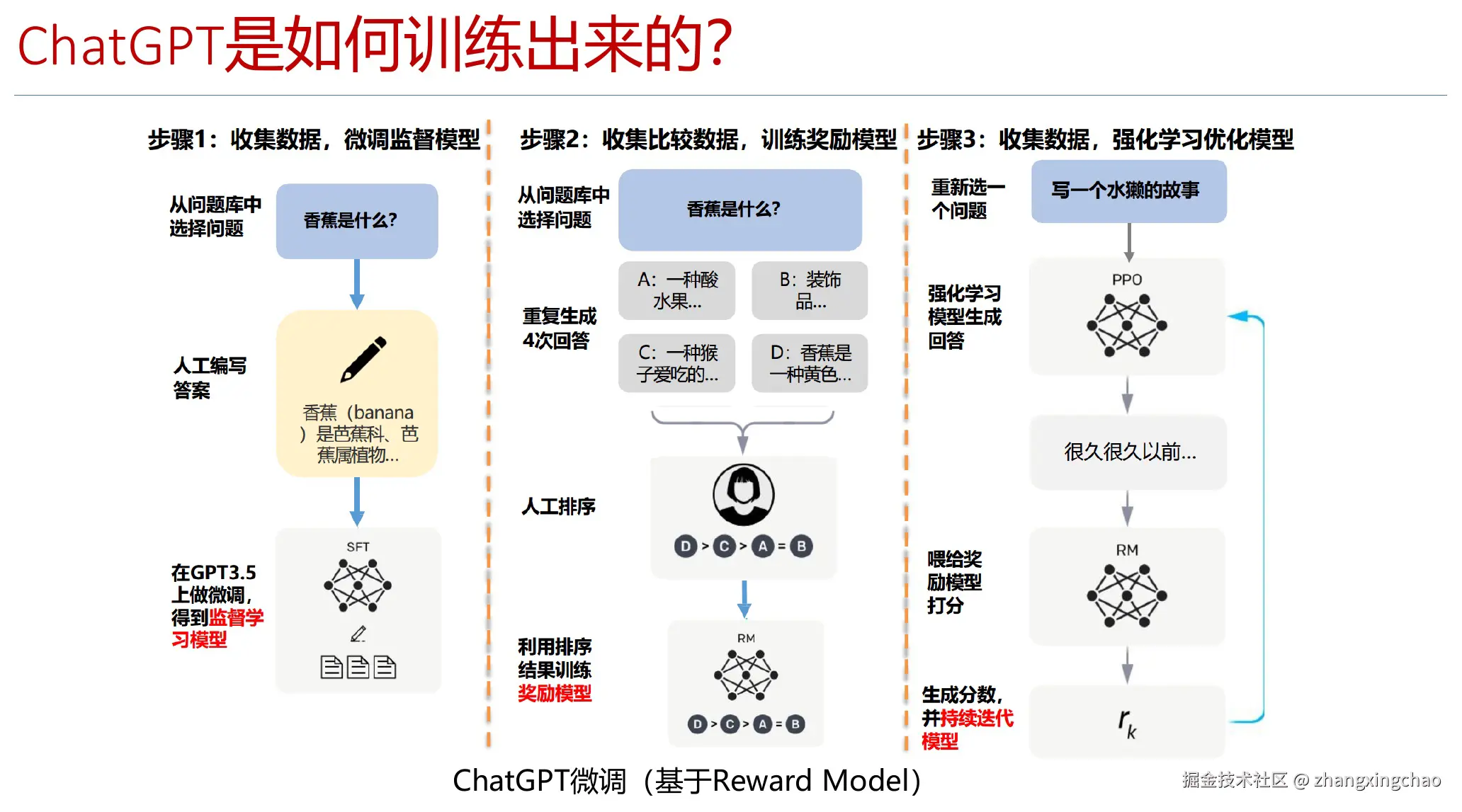
这里有个细节很重要:如果让标注员直接给回答打分,结果往往不稳定,因为每个人的打分标准不一样。相比之下,让标注员对多个回答做排序会更容易达成一致。Reward Model 就可以从这些排序数据里学到"哪个回答更好"。
这也是为什么同样是语言模型,普通 GPT、InstructGPT 和 ChatGPT 的体验会差很多。后训练和人类反馈会明显影响模型是否听指令、是否更安全、是否更适合对话场景。
Prompt Engineering、Context Engineering、RAG
这三个概念经常一起出现,但它们关注点不同。
Prompt Engineering:怎么把问题问清楚
Prompt Engineering 关注的是怎么把问题问清楚。
比如:
text
你是一名舆情分析师,帮我判断产品口碑的正负向,回复请用一个词语:正向 或者 负向。这个提示词里包含了几个关键信息:
- 角色:舆情分析师
- 任务:判断产品口碑正负向
- 输出格式:只回复"正向"或"负向"
- 约束:不要输出多余内容
Prompt Engineering 解决的是"怎么问"的问题。
Context Engineering:给模型看什么
Context Engineering 关注的是给大模型什么材料,让它能更准确地完成任务。
大模型回答问题时,不只看用户当前输入,也会看上下文。
上下文可以包括:
- system prompt
- user prompt
- 历史对话
- 工具返回结果
- 搜索结果
- 数据库查询结果
- 文档片段
- 图片识别内容
所以,Context Engineering 比 Prompt Engineering 更进一步。Prompt Engineering 关注"怎么问",Context Engineering 关注"给模型看什么"。
RAG:先检索,再回答
RAG 的全称是 Retrieval-Augmented Generation,中文一般叫"检索增强生成"。
它的核心逻辑是:
先检索外部资料,再把资料作为上下文交给大模型,让大模型基于资料回答。
例如用户问:
text
2026年4月23日黄金价格是多少?如果模型本身没有实时联网能力,它是不知道当天黄金价格的。这时可以走 RAG 或 Web Search 流程:
text
用户问题
-> 联网搜索 / 知识库检索
-> 返回相关资料
-> 把资料放入上下文
-> 大模型总结并回答所以,RAG 的本质不是让模型"凭空知道更多",而是让模型在回答前先拿到外部资料。
Token 和 Tokenizer 是什么
模型并不是直接处理中文、英文或标点。输入文本会先被 Tokenizer 切成一个个 Token,再转成数字 ID,最后进入模型计算。
Token 不一定等于一个字,也不一定等于一个词。比如中文里的"负向",有的 tokenizer 可能把它当成一个 token,有的 tokenizer 可能拆成两个 token。
不同模型使用的 Tokenizer 不一样,所以同一句话在不同模型里切分结果可能不同。
举两个例子:
- 英文
Hello World在 GPT-4o 里会被切成类似Hello和World的 Token。 - 中文"人工智能你好啊"在 DeepSeek-R1 里可能被切成"人工智能""你好""啊"。

Tokenizer 可以理解为分词器。它负责把自然语言文本转换成模型能理解的 token ID。
完整流程是:
text
中文文本
-> tokenizer
-> token ID
-> model 处理
-> 输出 token ID
-> tokenizer 反解码
-> 中文结果Tokenizer.json 可以理解为分词字典,里面定义了文本和 token ID 之间的映射关系。
Token 之所以重要,主要是因为它会影响三件事:
- 上下文长度:模型一次最多能处理多少输入。
- 调用费用:很多 API 按输入 Token 和输出 Token 计费。
- 生成速度:Token 越多,通常推理时间越长。
大模型如何生成答案
大模型不是一次性生成一整段话,而是一个 token 一个 token 地生成。
它的工作方式更像是:
text
输入内容
-> 预测下一个 token
-> 再预测下一个 token
-> 再预测下一个 token
-> 最终组成完整答案例如:
text
今天天气真 ...模型可能预测下一个 token 的概率是:
| 候选 token | 概率 |
|---|---|
| 好 | 60% |
| 不错 | 30% |
| 差 | 5% |
| 奇怪 | 5% |
然后模型会根据采样策略选择其中一个 token 继续生成。
这就是为什么说大模型本质上是一个:
next token 生成器。
Temperature 和 Top P 到底是什么
大模型生成回答时,并不是每一步都只有一个确定答案。模型会给下一个 Token 算出一组概率,然后根据采样策略选出最终 Token。
Temperature 和 Top P 控制的就是这个采样过程。
Temperature 可以理解为控制"回答有多发散":
- 温度高,低概率词也更容易被选中,回答更有变化,但也更容易跑偏。
- 温度低,高概率词权重更大,回答更稳定、更保守。
Top P 可以理解为控制"候选范围有多大":
- Top P 高,候选词范围更大,输出更多样。
- Top P 低,候选词范围更小,输出更确定。
比如模型要补全"今天天气真...",候选词可能是:
text
好 60%
不错 30%
糟 9%
可乐 0.01%如果 Temperature 很高,"可乐"这种离谱词也可能被采样出来。
如果 Top P 设为 0.9,模型只会选累计概率达到 90% 的候选词,也就是"好"和"不错",直接排除低概率词。
实际使用时,可以按任务来调:
- 分类、抽取、格式化输出:用较低 Temperature,让结果更稳定。
- 文案、创意、头脑风暴:可以适当提高 Temperature 或 Top P。
- 需要严格 JSON 的任务:尽量降低随机性,并配合明确的输出格式约束。
js
模型给所有 token 打 logits 分数
↓
Temperature 调整 logits 的分数差距
↓
Softmax 把 logits 转成概率分布(softmax 是把 logits 原始分数 转成 概率分布的函数。)
↓
Top P 删除低概率尾部候选
↓
重新归一化剩余候选概率(删除部分选项后,重新分配剩下的概率)
↓
按概率采样,或者直接选择最高概率 token(主要看解码/采样策略,通常由调用模型时的生成参数决定)
↓
得到下一个 token
↓
把这个 token 拼回上下文
↓
重复以上过程
↓
直到生成完整回答logits 可以理解为:模型在 softmax 变成概率之前,给每个候选 token 打的"原始分数"。
Temperature 管"概率差距":候选之间的机会差距要不要拉大或压平。
Top P 管"候选范围":哪些候选 token 能进入最终抽选池。
这些参数通常由系统根据场景内部控制。例如:
| 场景 | 可能倾向 |
|---|---|
| 普通聊天 | 平衡自然性和稳定性 |
| 代码/推理 | 更偏稳定、少发散 |
| JSON/结构化任务 | 更偏低随机性 |
| 创意写作/命名 | 可能更发散 |
| 深度研究 | 更重视检索、引用、综合,不只是采样参数 |
| 图片生成 | 进入图像模型/图像工具链,不是普通文本 token 采样逻辑 |
| Gmail/GitHub 等应用 | 更重视工具调用、权限、结构化动作 |
所以,可以理解为:
不同模式下,系统可能会自动选择不同模型、不同工具、不同上下文策略、不同安全策略,也可能使用不同采样参数。
Chat 产品的"超能力"本质是什么
很多 AI 聊天产品都有联网搜索、读取文件、记忆功能。表面上看,好像模型本身变得更强了,但工程上通常是模型和外部系统配合完成的。
联网搜索
大模型有训练数据截止日期,无法天然知道最新新闻、实时价格、当天政策变化。联网搜索的本质是:系统识别到用户的问题需要外部信息,然后调用搜索工具,把搜索结果整理成上下文,再交给模型总结。
也就是说,模型不是凭空"知道最新内容",而是拿到了工具返回的新材料。
读取文件
AI 读文件也不是简单打开文件。不同格式要先转换成模型能处理的结构。
- PDF 或扫描件:通常要 OCR,再做版式分析,识别标题、段落、表格和双栏排版。
- Word/Excel:可以解析底层结构,保留表格、公式、样式和大纲。
- 图片:通过多模态模型提取视觉特征,做图表理解、OCR 或视觉问答。
- 音频/视频:先通过 ASR 转成文本,或者提取关键帧再交给视觉模型。
记忆功能
LLM 本身是无状态的。每次 API 调用都是一次新的请求,它不会天然记得前面的聊天。
短期记忆通常是把最近几轮对话一起放进上下文窗口。长期记忆则需要系统提取用户偏好或重要事实,存到外部数据库里,后续对话再取出来放进上下文。
比如用户说"我喜欢简洁的回答风格",系统可以把这个偏好存起来。下次用户提问时,再把偏好作为上下文传给模型,模型就会更倾向于给出短答案。
API 使用:本地代码调用云端模型
使用大模型 API 时,本地电脑通常并没有运行完整大模型。代码只是向云端模型服务发送 HTTP 请求,对方完成推理后返回 JSON。
可以把它理解成点外卖:你不需要自己在厨房备菜,而是向商家下单,商家做好后把结果送回来。

API 使用时有几个基本概念:
- API Key:身份凭证,相当于门禁卡,不能泄露。
- Base URL:模型服务的接口地址。
- messages:传给模型的对话列表,包含系统、用户、助手、工具等角色。
- model:指定调用哪个模型。
- temperature/top_p/max_tokens:控制生成稳定性和输出长度。
- stream:是否使用流式输出,让内容像打字机一样逐步返回。
DashScope、Base URL、API Key 的关系
调用大模型时,经常会看到几个概念:
- base_url
- api_key
- model
- SDK
API Key 可以理解为调用模型服务的钥匙。没有 API Key,平台不知道你是谁,也不会允许你调用模型。
Base URL 是模型服务的接口地址。如果使用 OpenAI 兼容格式,通常会配置:
text
base_url + api_key + modelDashScope 是阿里云的大模型服务 SDK。
如果你使用:
python
import dashscope它其实帮你封装了一些请求逻辑,比如默认服务地址、鉴权方式、请求格式和响应格式。
所以,使用 SDK 和手动配置 base_url,本质上都是为了完成同一件事:
向模型服务发送请求,并拿到模型返回结果。
用 DashScope 调用 Qwen 时,基本结构大概是这样:
python
import dashscope
dashscope.api_key = "your-api-key"
messages = [
{"role": "system", "content": "你是一个严谨的助手。"},
{"role": "user", "content": "帮我总结这段内容。"}
]
response = dashscope.Generation.call(
model="qwen-turbo",
messages=messages,
result_format="message",
temperature=0.7,
top_p=0.8,
max_tokens=1500,
stream=False
)
result = response.output.choices[0].message.content
print(result)
response.output.choices[0].message.content 看起来很长,其实就是从模型返回对象里取第一条回复的正文。很多模型 API 都是类似结构:外层是请求结果,里面是候选回复列表,再往里才是具体文本。
System、User、Assistant、Tool 四种角色
调用大模型 API 时,经常会看到 messages 结构。messages 不是简单的一段文本,而是一组对话消息。
常见 role 有四种。
system
system 用来定义模型的角色、职责和规则。
例如:
json
{
"role": "system",
"content": "你是一名舆情分析师,只判断正向或负向。"
}system 不是必须的,但强烈建议使用。它可以让模型更稳定地知道自己应该做什么。
user
user 就是用户输入的问题。
例如:
json
{
"role": "user",
"content": "这个产品体验太差了。"
}assistant
assistant 是模型自己的回复。
例如:
json
{
"role": "assistant",
"content": "负向"
}tool
tool 是工具返回的结果。
例如:
json
{
"role": "tool",
"content": "{\"连接数\": 78}"
}模型实际看到的是这些消息组成的上下文,然后根据上下文生成回复。
情感分析案例:让模型做分类
第一个实战案例是情感分析。目标是判断用户评论是正向还是负向。
比如有这样一条评论:
text
这款音效特别好 给你意想不到的音质。这种任务不需要模型长篇发挥,关键是让它稳定输出一个分类标签。因此系统提示词要明确角色和输出格式:
python
review = "这款音效特别好 给你意想不到的音质。"
messages = [
{
"role": "system",
"content": "你是一名舆情分析师,帮我判断产品口碑的正负向,回复请用一个词语:正向 或者 负向"
},
{
"role": "user",
"content": review
}
]这里的关键不是代码本身,而是任务设计:
- 系统提示词限定角色:舆情分析师。
- 用户提示词提供原始评论。
- 输出格式限定为一个词:正向或负向。
如果要批量处理 Excel 里的商品评论,就可以逐行读取评论,把每条评论放进 user 消息里,再把模型返回的分类结果写回表格。
系统提示词和用户提示词
系统提示词和用户提示词的职责不同。
系统提示词更像全局规则,用来设定模型角色、行为边界和输出格式。比如:
text
你是一个资深程序员,请直接提供代码,并用 Markdown 格式包裹。不要解释,不要说任何无关的话。用户提示词是本次具体问题,比如"帮我写一个 Retrofit 请求封装"。
系统提示词有几个注意点:
- 它会消耗 Token。
- 不应该频繁变化,否则模型行为会不稳定。
- 不要把用户具体问题写死在系统提示词里。
- 输出格式要求最好写清楚,比如 JSON、表格、一个词、Markdown。
对新人来说,可以先把提示词理解成"API 调用时传给模型的配置 + 问题"。只不过这个配置不是传统程序里的参数,而是自然语言写成的行为约束。
输入 Token 和输出 Token 限制
API 调用时要同时关注输入 Token 和输出 Token。
输入 Token 包括:
- 系统提示词
- 历史对话
- 当前用户问题
- 工具返回结果
- 文档片段或图片描述
如果总输入超过模型上下文窗口,API 可能报错,或者模型无法完整处理。
输出 Token 是模型最多能生成多少内容。设置太低,回答可能中途截断;设置太高,调用时间和费用都会增加。
比如让模型写一首诗,但输出限制只给 5 个 Token,模型可能只返回第一句。做摘要、抽取和 JSON 生成时,最好根据任务预估合理上限。
Function Call 是什么
Function Call 可以理解为:
你提前在代码里注册好一些函数,让大模型在需要时决定是否调用。
例如你有一个函数:
python
def get_current_status():
return {
"连接数": 78,
"CPU使用率": "93.9%",
"内存使用率": "95.6%"
}然后你告诉大模型:
你现在可以使用一个工具,名字叫 get_current_status,它可以获取系统当前状态。
当用户输入:
text
告警:数据库连接数超过设定阈值
时间:2024-08-03 15:30:00模型可能会判断:
我需要知道当前系统状态,所以我要调用 get_current_status。
于是模型不会直接回答,而是先返回一个 tool call。
Function Call 的完整流程
Function Call 的关键流程如下:
text
用户提出问题
↓
程序把用户问题、System Prompt、工具说明一起发给 LLM
↓
LLM 判断是否需要调用工具
↓
如果需要,LLM 返回 tool_calls
↓
本地程序截取 tool_calls 里的函数名和参数
↓
本地程序真正执行函数
↓
工具返回结果
↓
程序把工具结果加入 messages
↓
再次发送给 LLM
↓
LLM 基于工具结果生成最终回答模型返回的不是最终自然语言答案,而是一个工具调用请求。程序要把这个请求截出来,识别函数名和参数,然后在本地真正执行函数。
换句话说,真正执行函数的是我们的程序,不是模型。模型只负责理解意图和生成调用参数。

Function Call 示例:运维告警分析
用户输入:
text
告警:数据库连接数超过设定阈值
时间:2024-08-03 15:30:00messages 可能是:
python
messages = [
{
"role": "system",
"content": "我是运维分析师,用户会告诉我们告警内容。我会基于告警内容,判断当前的异常情况(告警对象、异常模式)"
},
{
"role": "user",
"content": "告警:数据库连接数超过设定阈值\n时间:2024-08-03 15:30:00\n"
}
]模型第一次返回的可能不是自然语言答案,而是:
json
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"function": {
"arguments": "{}",
"name": "get_current_status"
},
"type": "function"
}
]
}这表示模型想调用:
text
get_current_status本地程序执行这个函数后,得到:
json
{
"连接数": 78,
"CPU使用率": "93.9%",
"内存使用率": "95.6%"
}然后把工具结果放回 messages:
json
{
"name": "get_current_status",
"role": "tool",
"content": "{\"连接数\": 78, \"CPU使用率\": \"93.9%\", \"内存使用率\": \"95.6%\"}"
}最后再让模型基于这个结果生成回答:
text
当前数据库连接数为 78,已超过设定阈值。同时,CPU 使用率和内存使用率也分别达到了 93.9% 和 95.6%,说明系统可能处于较高负载状态。
建议检查是否存在异常查询或连接请求,必要时优化数据库连接池配置,并持续监控系统资源使用情况。这就是一次完整的 Function Call 流程。
运维事件处置:大模型加工具链
运维事件处置很适合说明一件事:大模型不能单独解决所有问题,它必须和工具、数据、流程结合起来。
还是以数据库连接数超过阈值为例。大模型可以参与几个环节:
-
告警内容理解
从告警文本里识别告警对象和异常模式,比如"数据库服务器""连接数超过阈值"。
-
分析方法建议
结合应急预案、运维文档和已有经验,给出排查思路,比如查看连接数、CPU、内存、历史趋势和相关日志。
-
分析内容自动提取
调用监控系统、日志系统、事件管理系统等接口,拿到实时数据和历史数据。
-
处置方法推荐和执行
根据上下文推荐处理动作,比如调整连接池、排查异常会话、扩容资源、通知负责人。

这类系统通常会注册多个 Function Tool:
- 查询性能监控系统,获取连接数和系统负载。
- 检索日志管理系统,查看相关错误日志。
- 调用事件管理系统,获取历史类似事件和处理记录。
- 对比历史数据,判断是否异常波动。
- 生成自动化执行函数,比如重启服务、调整配置、通知值班人员。

这里要特别谨慎:建议和执行是两回事。让模型给建议风险较低,让模型自动执行运维动作风险就高很多。真实项目里通常要把执行动作分级:低风险动作可以自动化,高风险动作必须人工确认。
多模态表格提取
表格提取需要多模态模型,比如 Qwen-VL 系列,因为输入不只是文本,还包含表格图片。
Qwen-VL 这类模型常见能力包括:
- 图像描述
- 视觉问答
- OCR
- 文档理解
- 视觉定位
表格提取的输入通常由两部分组成:
python
content = [
{"image": "https://example.com/pdf_table.jpg"},
{"text": "这是一个表格图片,帮我提取里面的内容,输出 JSON 格式"}
]
这个案例的价值在于把非结构化图片转成结构化数据。比如从一张表格截图里提取客户名称、联系方式、产品型号、生产日期、原因归属、临时措施、改善措施等字段。
实际使用时要特别注意:
- 日期要解析成统一格式。
- 缺失值可以用
null或空字符串。 - 模型输出的 JSON 要做二次校验。
- 表格里如果有合并单元格,要检查字段是否错位。
多模态模型可以减少人工录入成本,但不能完全跳过校验。尤其是合同、财务、医疗、工单这类场景,最好把模型输出放进一个人工确认流程。
LLM、Function Call、RAG、Agent 的关系
可以先用几个简化公式理解。
普通 LLM
text
LLM = 大模型本身普通 LLM 只能根据自己的参数和当前上下文回答问题。
AI 产品
text
AI 产品 = LLM + Function Call现实中的 AI 产品通常不只是一个大模型,而是会接入各种工具。
比如:
- Web Search
- 数据库查询
- 天气接口
- 订单系统
- 支付系统
- 文件解析
- 图片识别
- 内部业务系统
这些能力通常通过 Function Call 或类似机制接入。
Agent
可以先做一个简化理解:
text
Agent = LLM + Function Call + RAG更完整地说,Agent 通常包括:
- LLM
- 工具调用
- 外部知识库
- 任务规划
- 多步骤执行
- 结果反馈
- 记忆系统
- 有时还包括多 Agent 协作
Agent 和普通聊天机器人的区别在于:
Agent 不只是回答问题,还可以拆解任务、调用工具、执行步骤,并根据结果继续行动。
Function Call 和 MCP 的区别
Function Call 和 MCP 很容易混淆。
可以先简单区分:
text
Function Call = 模型调用你代码里注册好的函数
MCP = 标准化的模型上下文协议,用来接入第三方工具或服务Function Call
Function Call 更像是你自己写工具,然后提供给模型调用。
特点是:
- 函数通常由开发者自己写。
- 工具能力由业务系统决定。
- 适合内部系统定制。
- 和具体代码实现绑定较强。
MCP
MCP 是 Model Context Protocol,模型上下文协议。
它的目标是让模型能够通过标准协议接入各种外部工具和服务。
可以理解为:
MCP 是一种更标准化、更通用的工具接入方式。
所以,说 MCP 和 Function Call 完全无关并不准确。更准确的理解是:
Function Call 是模型调用工具的一种机制,MCP 是让工具接入模型上下文的一套标准协议。
LLM 怎么知道什么时候该调用工具
模型本身并不会凭空知道有哪些工具。
是开发者在请求里告诉模型:
- 你现在有哪些工具可以用
- 每个工具叫什么
- 每个工具能做什么
- 每个工具需要什么参数
- 什么时候适合调用这个工具
例如,工具定义里可能会告诉模型:
text
工具名称:get_weather
工具描述:查询指定城市的实时天气
参数:location,表示城市名称当用户问:
text
大连今天多少度?模型会根据工具描述判断:
这个问题需要实时天气信息,应该调用 get_weather。
于是它可能返回:
json
{
"name": "get_weather",
"arguments": {
"location": "大连"
}
}本地程序再根据这个函数名和参数真正执行工具调用。
为什么一开始不用 LangChain
很多人会问:
调用大模型为什么不用 LangChain?
原因是,初学阶段更适合先理解底层逻辑。
如果一上来就用 LangChain、LangGraph、Qwen-Agent 这类框架,很容易只会调框架,但不理解背后到底发生了什么。
建议学习顺序是:
text
先理解 messages
-> 再理解 API 调用
-> 再理解 Function Call
-> 再理解 RAG
-> 最后再用 LangChain / LangGraph 等框架常见框架包括:
- LangChain
- LangGraph
- Qwen-Agent
- DeepAgent
- OpenClaw
- Spring AI
- LangChain4j
这些框架不是不能用,而是最好在理解底层原理后再用。
Workflow Agent 和 Multi-Agent
Workflow Agent 并没有过时,只是现在 Agent 的形态更丰富了。
可以这样理解:
text
Workflow Agent:流程相对固定,更稳定
Autonomous Agent:自主规划能力更强,更灵活
Multi-Agent:多个 Agent 分工协作在真实业务中,固定流程并不是缺点。很多企业级场景反而更需要稳定、可控、可审计的 Workflow。
所以不是 Workflow Agent 过时了,而是要根据任务选择合适的 Agent 形态。
单 Agent 是一个智能体负责完整任务。它要完成:
- 理解需求
- 规划步骤
- 调用工具
- 执行任务
- 输出结果
Multi-Agent 是多个智能体分工协作。
比如:
| Agent | 职责 |
|---|---|
| Planning Agent | 拆解任务 |
| Search Agent | 检索资料 |
| Coding Agent | 编写代码 |
| Review Agent | 检查结果 |
| Summary Agent | 汇总输出 |
Multi-Agent 的优势是分工更清晰,但系统也更复杂。
Python 环境和 API Key 问题
如果要跑代码,建议 Python 版本不低于 3.10,更推荐 Python 3.11。
安装时注意勾选:
text
Add to PATH否则命令行可能无法识别 python 命令。
在 Cursor 或 VS Code 中运行 Python 代码,一般步骤是:
text
1. 安装 Python
2. 打开 Cursor / VS Code
3. 打开课程代码所在文件夹
4. 安装 Python 插件
5. 选择 Python 解释器
6. 运行 .py 文件.py 文件就是 Python 源代码文件,可以通过 IDE 或命令行运行。
配置环境变量后,如果还是提示没有 API Key,常见原因有几个:
- 环境变量名称写错。
- 代码读取的变量名和你配置的不一致。
- 配置后没有重启终端。
- 配置后没有重启 Cursor、Trae 或 VS Code。
- Notebook 内核没有重启。
- 当前运行环境和你配置环境变量的环境不是同一个。
更完整地说,配置完环境变量后,最好重启终端、IDE 和 Notebook Kernel。
Transformer 为什么还没有被完全替代
Transformer 已经出现多年,但它仍然是主流架构。
可以从几个角度理解。
第一,Transformer 的扩展性很好。它可以通过增加数据、参数和算力持续提升效果。
第二,Transformer 很适合并行训练。这对大规模 GPU 训练非常重要。
第三,Transformer 的工程生态非常成熟。现在大量训练框架、推理框架、硬件优化、模型结构改进,都是围绕 Transformer 展开的。
第四,新架构即使在某些局部任务上更好,也很难在综合能力、成本、生态和稳定性上全面超过 Transformer。
所以目前不是没人研究新架构,而是:
Transformer 仍然是综合性价比最高、工程验证最充分的主流架构。
本地部署小模型做编程可行吗
可行。
例如 Qwen3-Coder-30B-A3B-Instruct 这类模型,就可以用于本地部署编程任务。
本地部署的优点是:
- 数据更安全。
- token 成本更低。
- 可以离线使用。
- 可以针对特定业务场景优化。
缺点是:
- 需要显卡和算力。
- 部署复杂度更高。
- 效果不一定超过顶级云端模型。
- 上下文长度和工具生态可能受限。
所以,本地模型适合对隐私、成本、可控性要求较高的场景。如果只是日常开发和学习,云端模型通常更方便。
高频问题
Q1:大模型怎么知道自己什么时候需要调用 Web Search?
因为系统在工具定义里告诉了模型有哪些工具,以及每个工具适合什么场景。模型根据用户问题和工具描述判断是否需要调用。
Q2:Temperature 和 Top P 在哪一层实现?
它们不是在模型初始化时实现的,而是在模型输出 logits 之后、选择下一个 token 之前的采样阶段实现的。
Q3:奖励模型怎么参与新问题评分?
奖励模型不是简单记录固定排序,而是学习一种"什么答案更好"的评分模式。遇到新问题时,它会根据学到的偏好规律,对候选答案进行评分。
主线
核心主线可以总结为:
text
Prompt Engineering
-> Context Engineering
-> RAG
-> Function Call
-> MCP
-> Agent
-> Multi-Agent
-> AI 编程工具生态它讲的不是单纯"怎么让 AI 写代码",而是:
如何从一个会聊天的大模型,逐步搭建出一个能调用工具、能接入业务系统、能完成复杂任务的 AI 应用。
最关键的一条链路是:
text
用户需求
-> system prompt
-> user prompt
-> messages
-> LLM
-> 判断是否调用工具
-> Function Call / MCP
-> 工具返回结果
-> 放回上下文
-> LLM 生成最终答案关键点
如果只记几个关键点,可以记这几句话:
- 大模型本质上是 next token 生成器。
- 模型知识不是数据库,而是压缩在权重里。
- Prompt 是提问方式,Context 是给模型看的材料。
- RAG 是先检索,再回答。
- Function Call 是让模型调用代码里的工具。
- MCP 是标准化的工具接入协议。
- Agent 是 LLM 加工具、知识、规划和执行能力。
- Temperature 控制随机性,Top P 控制候选范围。
- AI 编程不是完全不懂代码,而是要能看懂、能判断、能 review。
- 代码不是终点,解决业务问题才是终点。
结语
从 Prompt 到 Context,从 RAG 到 Function Call,从 MCP 到 Agent,再到 AI 编程工具生态,其实都在回答同一个问题:
怎么把一个会聊天的大模型,变成一个能完成真实任务的 AI 应用?
对初学者来说,不需要一开始就掌握所有框架,也不需要马上写复杂系统。更重要的是先理解:
text
大模型如何接收上下文
-> 如何生成 token
-> 如何调用工具
-> 如何把工具结果重新放回上下文
-> 如何最终形成一个可运行的 AI 应用理解了这条主线,再去学 Cursor、Trae、LangChain、LangGraph、Spring AI、LangChain4j,都会清晰很多。