1. 背景:为什么要做这件事
1.1 真实痛点:三端并行迭代下的回归之痛
转转B2B业务同时存在 PC 后台、APP、小程序三端,每个迭代各端都在并行发版。质量保障上有几个长期难解的问题:
- 每次发版前的回归全靠人肉点击:核心链路 case 几十上百条,测试同学一遍遍按用例手动操作,单次回归动辄半天起。
- 修过的 bug 容易复发:上个迭代修好的问题,下个迭代回归没覆盖到,又被线上用户撞上。
- 自测沉淀不下来:研发自测往往是"测完即焚"------这次点过的路径,下次需求来了还是要重新点一遍。
我们想解决的核心问题其实只有一个:让回归测试这件事,从"反复消耗人力"变成"一次投入、长期复用"的资产。
1.2 为什么是现在
两个条件同时成熟,让"前端/客户端自建自动化平台"这件事第一次变得 ROI 正向:
- AI 视觉识别打破了维护成本天花板:过去自动化最大的成本是"选择器维护",现在多模态模型可以直接"看界面",UI 改版只要语义没变,脚本就不需要修改。
- 多端业务的回归压力足够大:三端并行 + 高频迭代 + 强回归依赖,自动化的收益放大效应足够明显,值得专门建一套平台。
1.3 对测试框架的两个核心要求
结合过往踩坑经验,我们认为适合团队的测试框架必须同时满足:
- 高容错性:对 UI 变动脱敏,打破"写脚本 → 挂脚本 → 修脚本"的死循环。
- 低使用门槛:研发和测试同学都能上手,不需要专门学一套新 API。
带着这两个要求,我们进入框架选型。
2. 框架选型:为什么是 Midscene?
2.1 几类主流方案的横向对比
我们对市面上几类主流自动化方案做了横向对比,重点看长期维护成本 和研发上手门槛:
| 方案 | 优点 | 缺点 |
|---|---|---|
| Playwright / Appium | 生态成熟、API 稳定、社区方案多 | 强依赖选择器/文案,UI 改版后部分脚本会失效,研发要持续维护选择器 |
| 录制回放(如 Selenium IDE) | 上手快、无需写代码 | 录制脚本与 DOM 强耦合,复用性差;动态内容支持弱 |
| AI 视觉识别(Midscene 等) | 对 UI 变动脱敏、自然语言驱动、维护成本低 | 依赖大模型能力,单次执行成本略高,对复杂场景需调试 prompt |
结论:选择整体成本最低的一条路
短期写脚本的速度 Playwright 不慢,但放到一年甚至更长的周期看,维护成本才是真正的大头。Midscene 这类 AI 方案让脚本对 UI 改动脱敏,把"写一次、长期可用"变成可能,单次执行成本的小幅增加,远低于持续维护选择器的人力消耗。
放到上一节提到的两个核心要求上,三类方案的对照如下:
| 维度 | Playwright / Appium | 录制回放 | Midscene.js |
|---|---|---|---|
| 核心逻辑 | 搭积木(DOM 选择器) | 录制 DOM 操作回放 | 看界面(AI+视觉识别) |
| 抗变动性 | 弱(改结构即挂) | 弱(脚本与 DOM 强耦合) | 强(关注语义) |
| 维护成本 | 高 | 高 | 低 |
| 学习门槛 | 中(需熟悉选择器 API) | 低 | 低(自然语言) |
综合下来,Midscene 是同时命中"抗造 + 低门槛"的唯一选项,所以我们最终选择它作为底层引擎,并在它之上做平台化封装。
2.2 核心优势:从代码看差异
传统方式 (Playwright):依赖选择器/文案定位
javascript
// 这类代码前端改个样式或文案就可能跑不通
await page.locator('.ant-modal-content >> .ant-btn-primary').click();
await page.locator('div.order-list > div:nth-child(3) span.price').innerText();
await page.waitForSelector('.ant-message-success');Playwright 本身也提供了 getByRole / getByText 等语义化 API,即便用语义化 API(getByRole('button', { name: '确认' })),文案变更或多语言场景下脚本仍需要同步修改,维护成本依然真实存在。
Midscene (YAML):只要自然语言
yaml
# 同样的逻辑,只要界面语义没变,脚本就不用改
- aiAct: 点击"确认"按钮
- aiAssert: 第三个订单的价格是 99 元
- aiAssert: 出现"操作成功"的提示低维护成本 :前端改样式/改 DOM 结构 → 只要界面语义没变 → 脚本无需修改。
降低准入门槛 :不需要背 page.locator / xpath / getByRole 这些 API,只要写中文。
2.3 原理解析:它是怎么工作的?
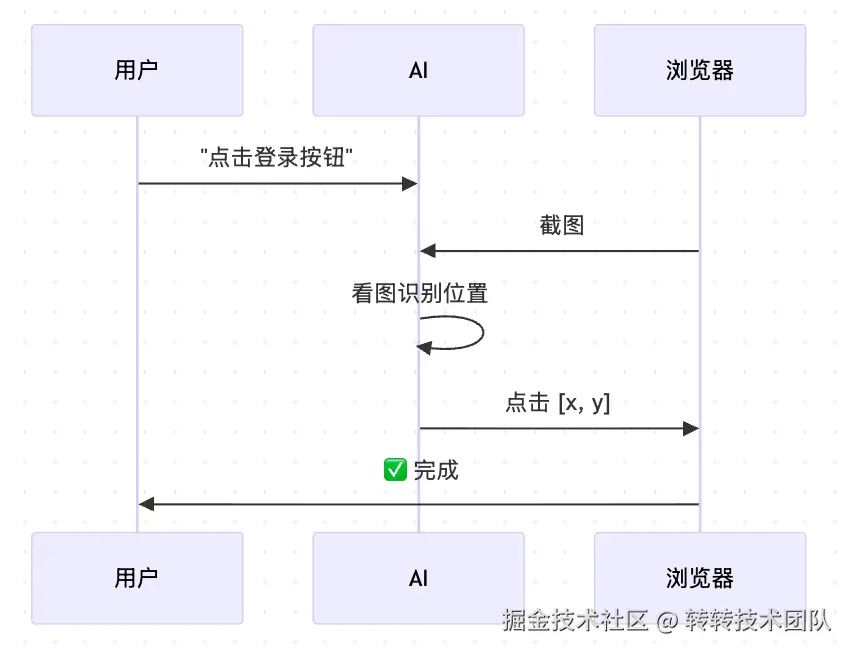
如流程图所示,整个执行链路本质上就是 "截图 → 多模态模型识别 → 输出操作指令 → 执行" 的循环。
Midscene 当前采用的是纯视觉方案------不再依赖 DOM 树、accessibility 树等结构化信息,所有页面理解全部交给多模态大模型从截图中完成:
- 把当前页面截图 + 自然语言指令(如"点击确认按钮")一并喂给多模态模型;
- 模型在视觉层面定位到目标元素,输出目标元素在截图上的坐标;
- 框架把坐标换算成实际操作(点击、输入、滑动)下发给浏览器或真机。
这样做的关键意义在于:彻底脱离了 DOM 选择器的世界 ------这也意味着 Midscene 不仅可以跑 Web,任何能截图的载体都能跑(APP、小程序、Electron 桌面端、甚至画面投屏),这是它能成为我们多端统一引擎的根本原因。
3. 整体方案设计
有了这个强大的引擎,下一步就是怎么把它用好。
我们调研后发现,直接用 Midscene 对环境有一定要求(Node 版本、Playwright、AI Key 配置、ADB/WDA 等底层驱动)。所以我们决定把它做成了平台化------一个面向研发和测试同学的智能自动化测试平台。
3.1 设计目标
- 解决环境问题:环境无感------不需要大家在本机装各种工具,开箱即用。
- 0 代码编写用例:Midscene 本身还是有一点门槛(需要写 YAML),利用 AI 把这个门槛降低,达成真正的 0 代码编写用例脚本(用 Xmind 维护 case)。
- 支持全环境:目前我们的前端项目有多种类型,包括 PC 端项目、APP、小程序,需要支持各种环境跑自动化脚本的能力。
3.2 整体架构
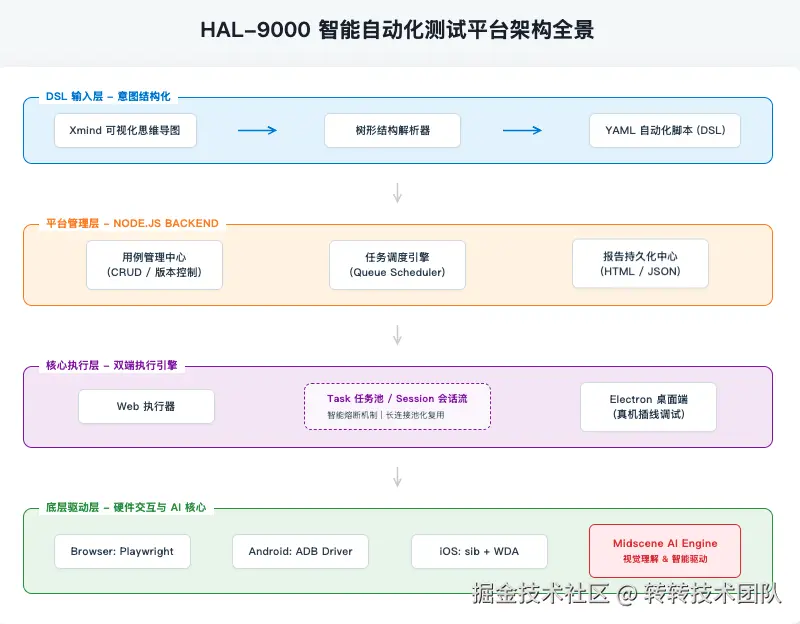
平台采用分层架构,每一层只关心自己的职责边界,互相通过明确的契约通信。下面逐层拆解。
1. DSL 输入层:把"测试意图"结构化
DSL(Domain-Specific Language,领域特定语言),这里指 Midscene 定义的 YAML 用例格式。
输入层的设计有一个非常现实的出发点------贴合团队当前的协作现状。
我们的测试同学一直在用 Xmind 维护测试用例,已经形成了非常成熟的写作习惯和案例资产。如果我们要求大家改写 YAML 或学一套新工具,迁移成本极高,平台也很难推得动。所以我们没有"另起炉灶",而是顺着团队现有的工作流,把"Xmind 直接转 YAML"做成平台能力------让测试同学几乎零成本就能复用已有的用例资产,是降低使用成本最有效的方式。
实现上,系统内置 xmind2yaml 解析器(基于 adm-zip 解包 + fast-xml-parser 解析 content.xml),将思维导图转换为标准化 AST,再经"双通道"产出 Midscene DSL:
[模版]节点 → 规则转换:列表筛选、分页、表单提交等高频通用动作,按预置规则直接生成 YAML,毫秒级产出,几乎零成本。[流程]节点 → AI 转换 :业务相关的复杂场景,通过 LLM 把自然语言描述翻译成 Midscene 的aiAct / aiAssert / aiQuery等指令。
这一层只做"语义转换",不关心后续在哪跑、怎么跑------这是分层解耦的关键。
这样做的好处:把高频可枚举的动作交给规则(稳定、便宜、快),把"千人千面"的业务流程交给 AI(灵活),既保住质量也控制了成本。
2. 平台管理层:中控中心
基于 Egg.js + Sequelize + socket.io 搭建的服务,承担三件事:
- 用例管理:CRUD、版本控制、Xmind 文件托管。
- 任务调度 :双层模型
AitestTask(任务定义)+AitestSession(每次执行的会话快照),级联删除避免脏数据;任务状态机待执行/执行中/成功/失败/已取消,并通过 socket.io 实时把执行进度推送到前端。 - 报告与回溯:执行完毕后持久化测试结果,生成直观的 HTML/JSON 测试报告,支持失败用例的截图与 AI 决策日志回放。
3. 核心执行层:双端执行引擎
支持 Web 执行器和基于 Electron 的桌面端真机执行能力。Web 端默认走平台内嵌的 Playwright 池;桌面端则把 Electron 当作宿主,把当前用户的真实设备纳管进来,做到"插线即用"。内置 Task 任务池与 Session 会话流,负责长连接的池化复用,保障执行过程的稳定性。
这一层有一个我们重点投入、也是平台区别于通用方案的差异点:内置 Whistle 多实例管理。
线上回归经常需要做"环境切换、接口 mock、灰度抓包",传统做法是研发本地装 Whistle、配规则,但多个用户同时跑同一台执行机时,规则会互相覆盖。平台在 8800--8899 端口段动态分配空闲端口,按用户/任务隔离 Whistle 实例:
- 每个任务起一个独立 Whistle,规则互不污染;
- 执行完自动回收端口,避免资源泄漏;
- 平台层提供规则模板,业务侧可以一键应用常用 mock 规则。
这是把"原本属于本地工具链的能力"平台化的关键一步------也是用例稳定性能撑起来的底盘。
4. 底层驱动层:硬件交互与 AI 核心
封装了各端的底层驱动(Web 依赖 Playwright,Android 依赖 ADB,iOS 依赖 sib + WDA),并通过 @midscene/cli 和 @midscene/web 接入 Midscene,提供视觉理解与智能驱动能力。
3.3 平台使用流程一览
讲完了架构,我们换一个视角,从用户实际操作的链路上看一下平台长什么样。一次完整的回归任务大致经历四步:写用例 → 看脚本 → 跑任务 → 看结果。
Step 1. 用例管理:在平台上托管全部测试用例
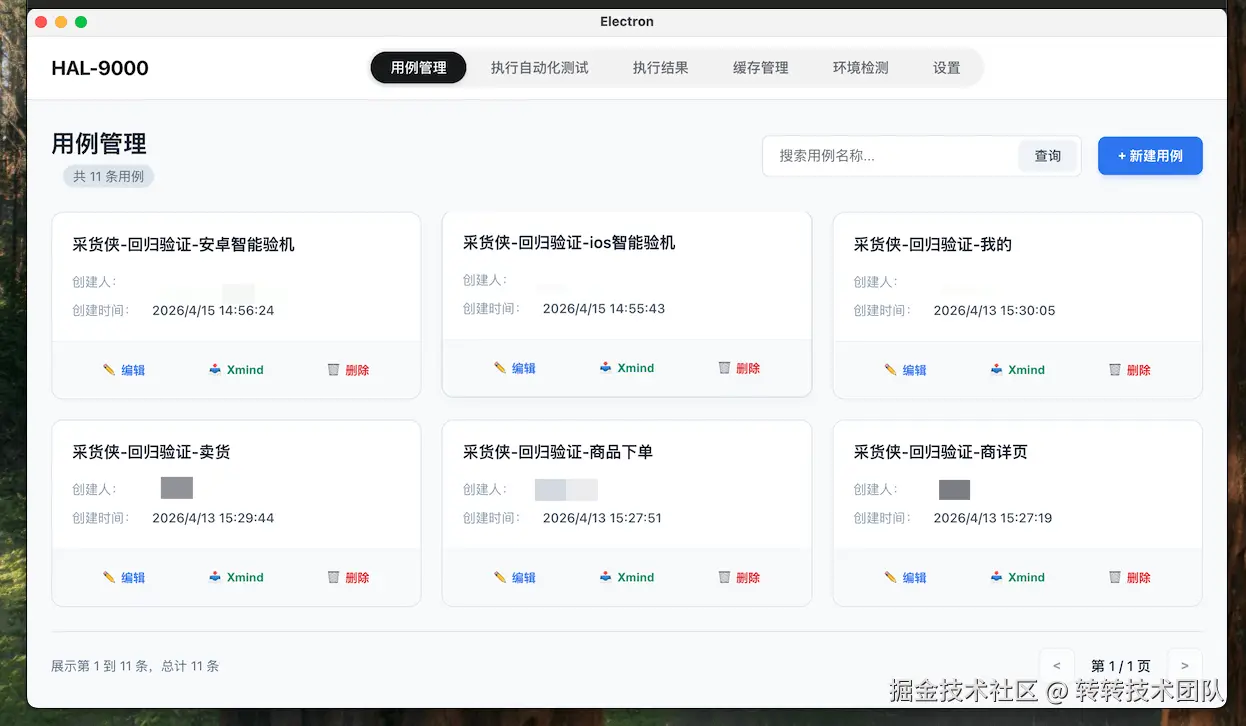
平台提供统一的用例管理入口,支持按业务模块组织、版本化维护,所有 Xmind 思维导图、生成后的 YAML 脚本都集中托管。测试同学日常维护用例的姿势保持不变,只是承载位置从本地文件挪到了平台。
Step 2. YAML 脚本:从思维导图自动转换出来
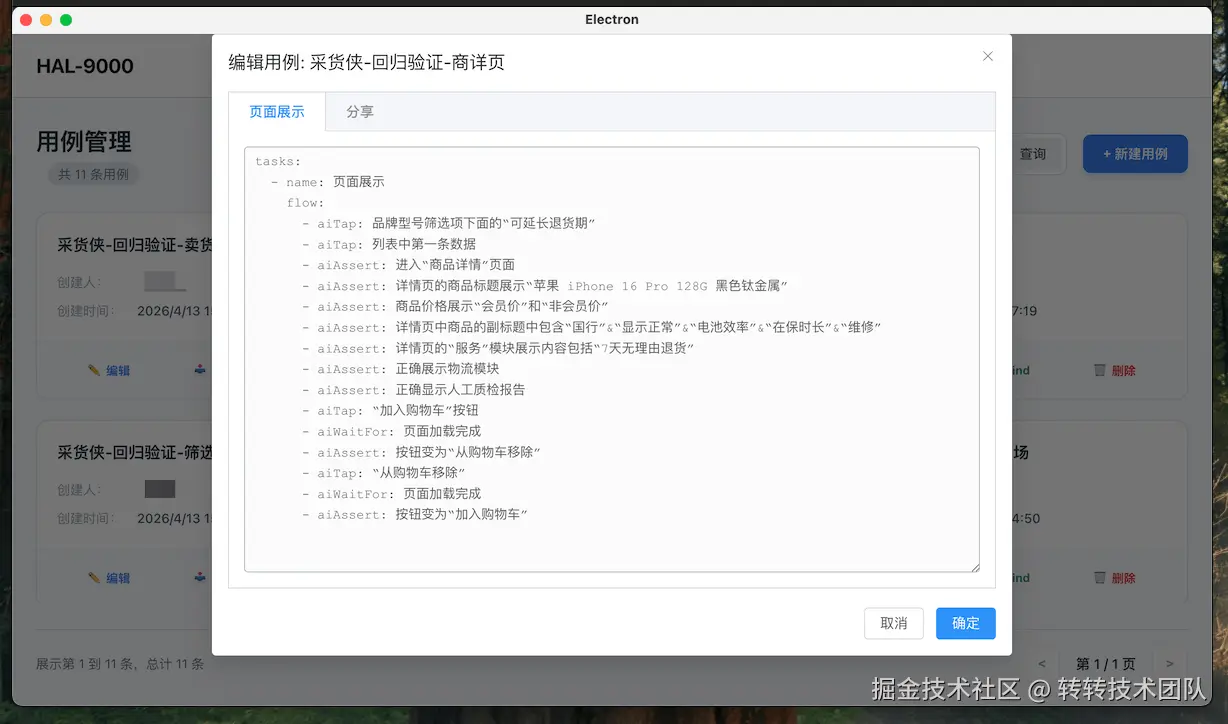
xmind2yaml 解析后产出的 Midscene YAML 直接在平台展示------aiAct(动作)、aiAssert(断言)、aiQuery(查询)一目了然。脚本完全可读、可手动微调,相当于"AI 写完初稿、人补几笔精修"。
Step 3. 执行面板:一键触发,实时回看
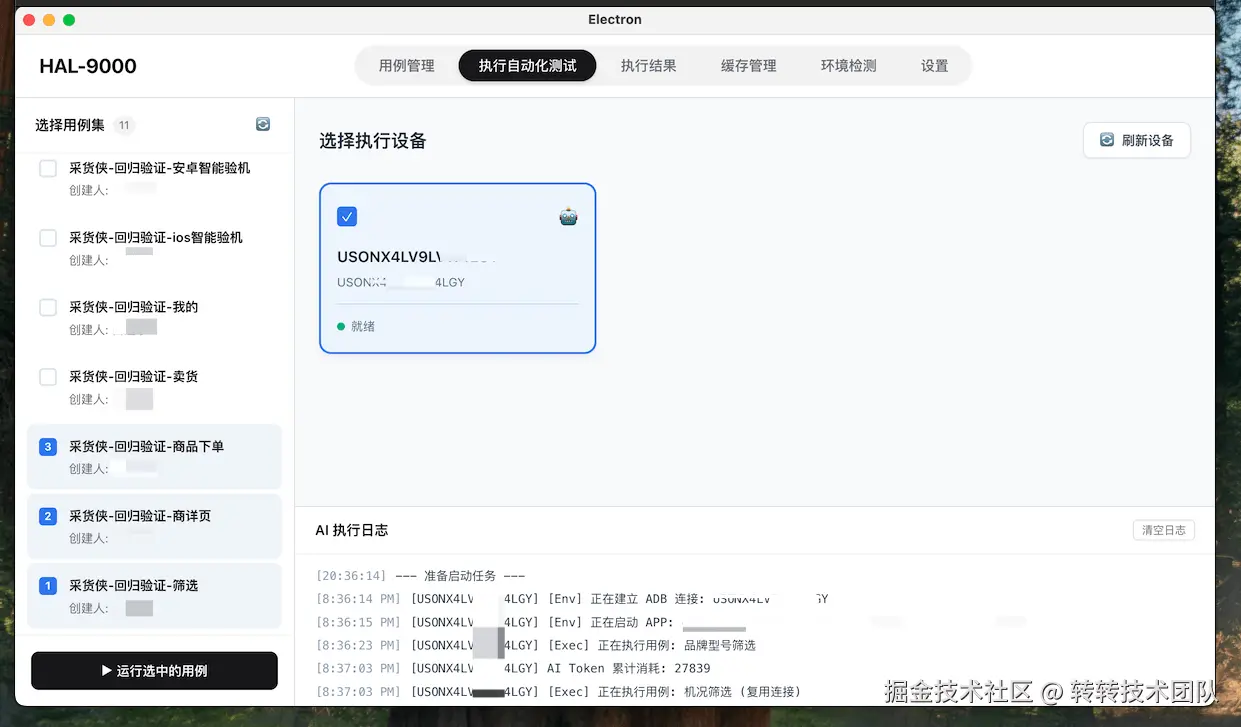
选好用例和环境(PC/APP/小程序)即可一键触发。执行过程中,平台通过 socket.io 把每一步的进度、AI 决策、截图实时推送到面板,过程透明可观测,出错即时定位。
Step 4. 执行结果:可追溯的完整报告
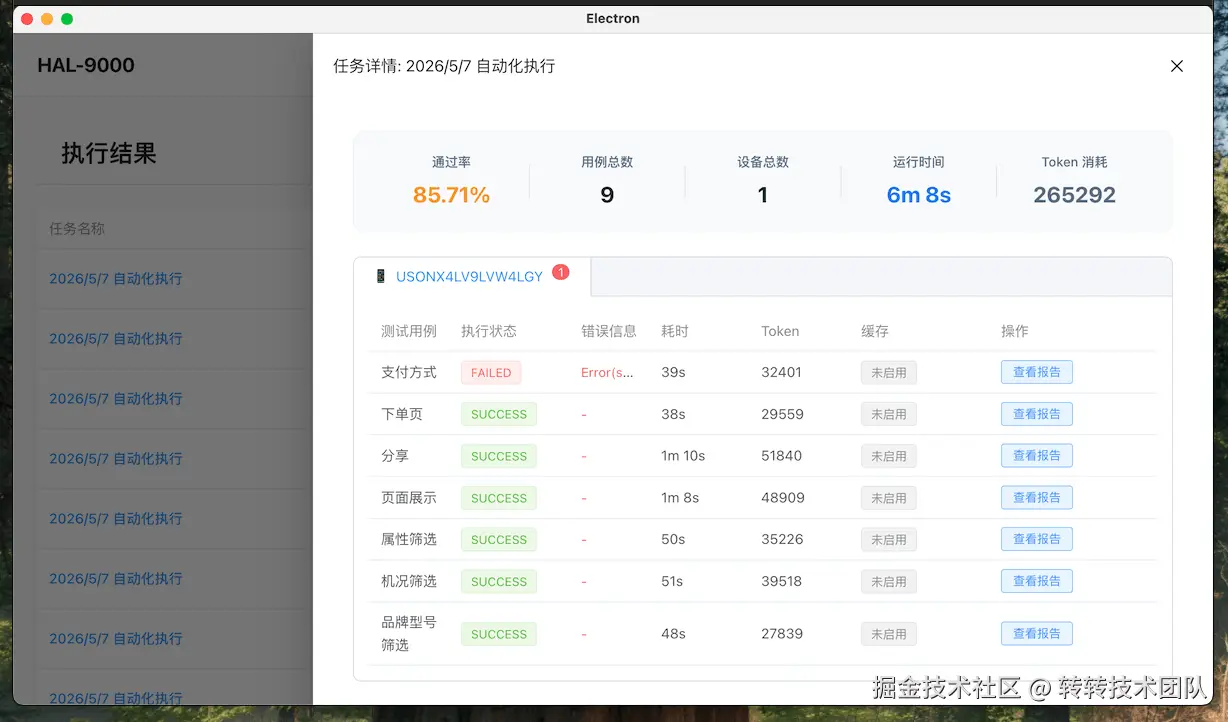
执行完成后产出结构化报告:用例通过率、失败步骤的截图与 AI 决策日志、断言失败点等都被持久化保存。回溯一次失败,不再依赖"凭印象复现",而是看截图+日志直接定位。
4. 研发自测探索:把 YAML 生成接入 AI Coding 流程
平台跑顺之后,我们发现它不只适合发版回归,也可以进一步前置到研发自测环节。这里的关键问题是:研发自测阶段是否还需要先画一份 Xmind?
4.1 问题:研发自测需要 Xmind 吗?
最初引入 Xmind 是为了让非研发同学也能"画"用例,这一层在测试同学 那里是有价值的------他们的存量资产都在 Xmind 里。但放到研发同学身上,链路就变得偏重了:
- 多了一层人工产物:写需求 → 画 Xmind → 转 YAML → 跑用例,链路偏长。
- 重复成本:研发同学其实在写代码时,已经把功能点、边界条件想了一遍,再去 Xmind 里手动重述一次,是重复劳动。
- 推广阻力:要先教大家怎么画 Xmind、按什么规范画,才能跑起来。
所以我们正在试用一种分层方式:测试同学继续维护现有 Xmind 资产,保障发版回归的稳定沉淀;研发新增需求则尝试直接走 AI Coding 生成 YAML,用更轻的方式完成提测前自测。
4.2 试用方案:让 Claude 直接产出 YAML
我们把 YAML 生成这一步挂载到团队基于 Claude 的 AI Coding 流程里,做成一个 Skill / Subagent:
markdown
需求文档 + AI Coding 产出的代码改动
│
▼
┌────────────────────┐
│ Claude Skill │
│ (读需求 + 读 diff)│
└────────────────────┘
│
▼
直接生成 Midscene YAML 用例- 输入:本次需求文档(PRD / 大神文档)+ 当前分支的代码 diff。
- 过程:Claude 自动识别本次改动涉及的页面、交互、关键断言点,结合需求里的验收标准,产出对应的 Midscene YAML。
- 输出:可直接在平台执行的用例文件。
4.3 试用中的价值
这条链路目前在团队内小范围试用,现阶段更明确的价值主要有三点:
- 减少重复表达:研发同学不再需要"先画图再转 YAML",可以直接基于需求和代码改动生成自测用例。
- 让自测可沉淀:过去自测更多依赖个人经验和临时点击,现在可以沉淀为可执行的 YAML 用例和平台报告。
- 降低试用门槛:不需要额外学习一套新工具,只要在日常 AI Coding 流程里补充生成用例的动作即可。
如果这条链路持续跑通,平台的定位就不只是"发版前的回归工具",而是可以进一步成为研发自测阶段的质量辅助能力。
5. 落地成果
5.1 当前落地情况
目前,该平台最成熟的落地场景是发版回归与自动化巡检,已覆盖 PC 后台、APP 与小程序三端。其中最具代表性的成果是:
- APP 发版回归场景已 100% 接入 ------ 发版必跑的核心模块全部实现自动化落地。
研发/测试同学完全脱手------平台自动触发、自动产出可追溯的执行报告,人只需要在跑完后看报告。相比"全程盯着点",省下来的不只是时间,还有原本被回归占用的注意力。这就是发版前质量底线被真正"机器化"的意义。
6. 写在最后
这套平台的价值,不只是把几条回归链路自动化,而是把原本依赖人工经验的测试过程,逐步变成可执行、可追溯、可复用的质量资产。
回归测试是当前最确定的落地点,研发自测是正在试用的下一步。我们希望它最终能融入日常开发流程,让质量保障不再只发生在发版前,而是前置到每一次需求开发的过程中。