Embedding 可以从一个很普通的需求说起:给用户推荐相似酒店,或者在 FAQ 里找到和问题最接近的答案。机器不能直接理解一段文字,第一步就是把文字变成可计算的向量。
向量有了以后,就可以计算相似度,也可以把它们存起来做检索。N-Gram、TF-IDF、Word2Vec、Embedding 模型、FAISS 和向量数据库,对应的正是"向量怎么来、怎么算、怎么存、怎么查"这几个问题。
如果第一次接触这些概念,可以先用一个粗略类比记住它们的关系:Embedding 像是给文本、图片、商品分配坐标;相似度计算是在看两个坐标靠不靠近;向量数据库负责把这些坐标和原始数据一起管起来,方便后面快速查找。
从酒店推荐开始理解 Embedding
假设现在要做一个内容推荐系统:用户选中一家酒店,系统需要推荐描述相似的其他酒店。这个任务的核心就是一句话:把酒店描述变成可以计算的东西,然后找相似。
这里使用的是西雅图酒店数据集,字段主要有三个:name、address 和 desc。desc 是酒店的文本描述,也是后面做文本特征和相似度计算的核心字段。
数据集地址:

最直接的做法是:先把每家酒店的描述转换成特征向量,再计算目标酒店和其他酒店之间的余弦相似度,最后取相似度最高的 Top 10。
相似度:为什么常用余弦相似度
余弦相似度衡量的是两个向量方向是否接近,而不是单纯看向量长度。对文本来说,这一点很重要。两段文本长度可能不同,但只要语义方向接近,就应该被认为相似。
它的取值范围是 [-1, 1]:
- 越接近 1,说明两个向量越相似
- 等于 0,说明两个向量基本正交,相关性弱
- 越接近 -1,说明两个向量方向越相反
公式如下:
a⋅b=∣a∣∣b∣cosθ
similarity=cos(θ)=∣A∣∣B∣A⋅B=∑i=1nAi2 ∑i=1nBi2 ∑i=1nAiBi
用一个很小的中文例子来直观理解。假设有两句话:
句子 A:这个程序代码太乱,那个代码规范
句子 B:这个程序代码不规范,那个更规范
先做分词:
- 句子 A:这个 / 程序 / 代码 / 太乱,那个 / 代码 / 规范
- 句子 B:这个 / 程序 / 代码 / 不 / 规范,那个 / 更 / 规范
把两句话里出现过的词统一列出来:
text
这个,程序,代码,太乱,那个,规范,不,更然后统计词频,就可以得到两个向量:
- 句子 A:
(1, 1, 2, 1, 1, 1, 0, 0) - 句子 B:
(1, 1, 1, 0, 1, 2, 1, 1)
代入余弦相似度公式:
cos(θ)=12+12+22+12+12+12+02+02 ×12+12+12+02+12+22+12+12 1×1+1×1+2×1+1×0+1×1+1×2+0×1+0×1=0.738
这个结果比较接近 1,说明两句话确实比较相似。
这里不用一开始就纠结公式里的每一项。更重要的是理解流程:先把两段文本放到同一套词表下,变成长度相同的向量,再比较两个向量的方向。词数多不一定更相似,方向接近才更相似。
用 N-Gram 和 TF-IDF 做传统文本特征
在没有深度学习 Embedding 之前,文本特征通常会从词频、N-Gram 和 TF-IDF 入手。
N-Gram 的意思是把连续的 N 个词当作一个特征。比如 A B C D E 这段文本,Bi-Gram 就是:
text
A B, B C, C D, D E如果只看单个词,有些语义会丢失。比如 pike 和 place 分开看意义不强,但 pike place 放在一起,就更像一个地点特征。这就是 N-Gram 的价值。
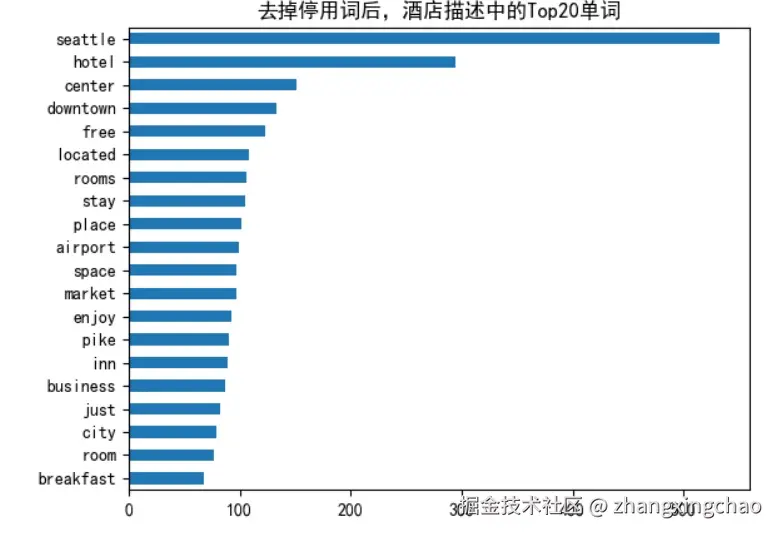
在酒店描述里提取 Top 20 个 Unigram,可以用 CountVectorizer:
python
plt.rcParams['font.sans-serif'] = ['SimHei']
df = pd.read_csv('Seattle_Hotels.csv', encoding="latin-1")
def get_top_n_words(corpus, n=1, k=None):
vec = CountVectorizer(ngram_range=(n, n), stop_words='english').fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq = sorted(words_freq, key=lambda x: x[1], reverse=True)
return words_freq[:k]
common_words = get_top_n_words(df['desc'], 1, 20)
df1 = pd.DataFrame(common_words, columns=['desc', 'count'])
df1.groupby('desc').sum()['count'].sort_values().plot(
kind='barh',
title='去掉停用词后,酒店描述中的Top20单词'
)
plt.show()从结果看,seattle、hotel、center、downtown、free、stay、room、breakfast 这类词出现频率很高。
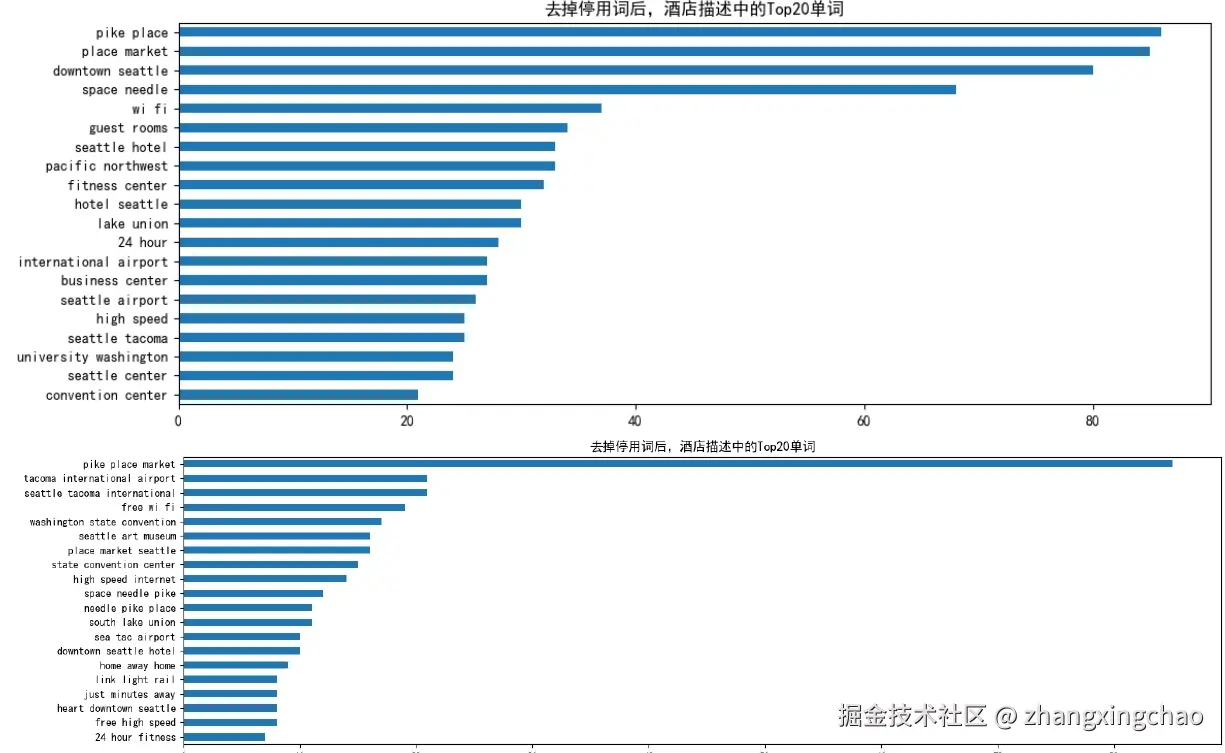
同样的函数也可以提取 Bi-Gram 和 Tri-Gram:
python
# Bi-Gram
common_words = get_top_n_words(df['desc'], 2, 20)
# Tri-Gram
common_words = get_top_n_words(df['desc'], 3, 20)这时结果就更接近酒店场景本身了,比如 pike place、downtown seattle、space needle、free wi fi、pike place market、seattle tacoma international 等。
词频本身还不够,因为有些词在所有文档里都很常见,区分度并不高。TF-IDF 正好处理这个问题。
TF 表示词频,一个词在当前文档里出现越多,TF 越高:
TF=文档中总单词数单词次数
IDF 表示逆文档频率,一个词出现在越少的文档里,区分度越高,IDF 越大:
IDF=log单词出现的文档数+1文档总数
在酒店推荐里,可以把 1-Gram、2-Gram、3-Gram 一起放进 TF-IDF:
python
def clean_text(text):
text = text.lower()
...
return text
df['desc_clean'] = df['desc'].apply(clean_text)
tf = TfidfVectorizer(
analyzer='word',
ngram_range=(1, 3),
min_df=0,
stop_words='english'
)
tfidf_matrix = tf.fit_transform(df['desc_clean'])
cosine_similarities = linear_kernel(tfidf_matrix, tfidf_matrix)这里会得到一个酒店之间的相似度矩阵。之后根据指定酒店名称,取相似度最高的 Top 10 即可:
python
def recommendations(name, cosine_similarities=cosine_similarities):
recommended_hotels = []
idx = indices[indices == name].index[0]
score_series = pd.Series(cosine_similarities[idx]).sort_values(ascending=False)
top_10_indexes = list(score_series.iloc[1:11].index)
for i in top_10_indexes:
recommended_hotels.append(list(df.index)[i])
return recommended_hotels
print(recommendations('Hilton Seattle Airport & Conference Center'))
print(recommendations('The Bacon Mansion Bed and Breakfast'))清洗文本、提取 N-Gram 和 TF-IDF、计算余弦相似度、返回 Top-K,这套流程可以跑通一个基础的内容推荐。但它也有明显问题:特征矩阵很稀疏,维度高,而且只能表达词面共现,很难处理更深一层的语义。比如"退票"和"退款"在词面上不同,但语义上很接近,传统词频方法就不一定能处理好。
所以这部分更适合理解"文本如何变成向量"的基本思路。真正做 RAG、语义搜索或智能问答时,通常不会手写这么多特征,而是直接用训练好的 Embedding 模型生成向量。
因此需要一种更稠密、更能表达语义的向量表示,这就是 Word Embedding 要解决的问题。
Word Embedding:把词放进语义空间
Embedding 可以理解为一种降维后的表示方式。原来一个离散对象可能只能用 one-hot 表示,维度高、稀疏、彼此之间没有语义关系;Embedding 会把它映射到一个固定维度的稠密向量里。
这些维度不一定都能被人明确命名。它们更像是模型从大量数据里学出来的隐含特征。单独看某一维可能不好解释,但整体距离是有意义的:语义接近的内容会靠得更近,语义差异大的内容会离得更远。
简单说,任何对象只要能被表示成向量,就可以计算相似度,也就可以被检索、推荐、聚类和排序。
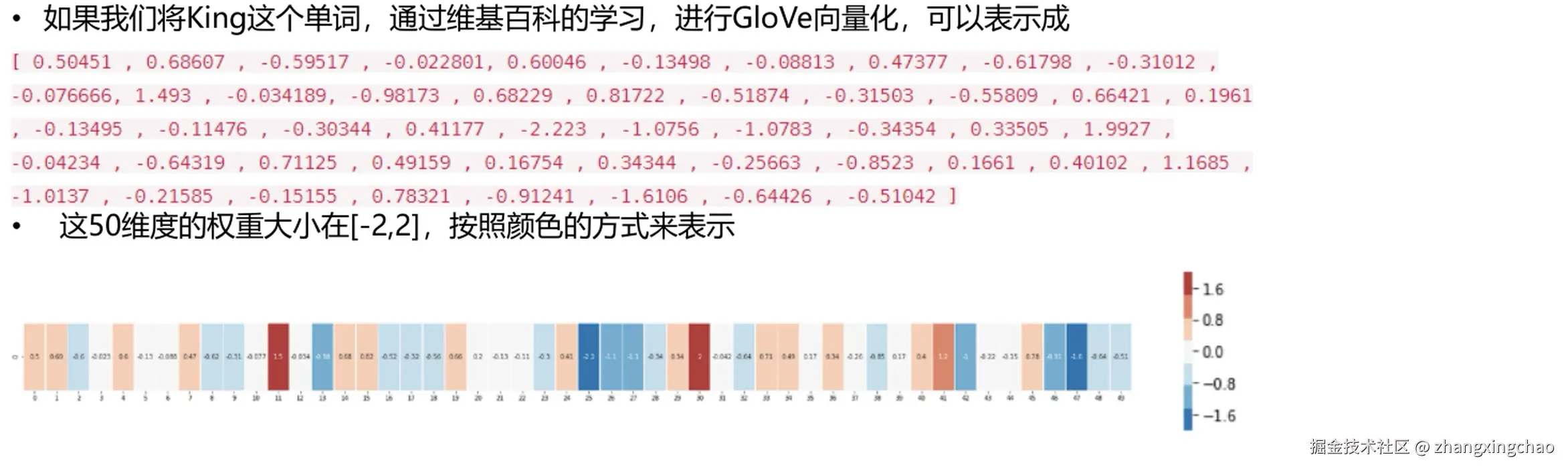
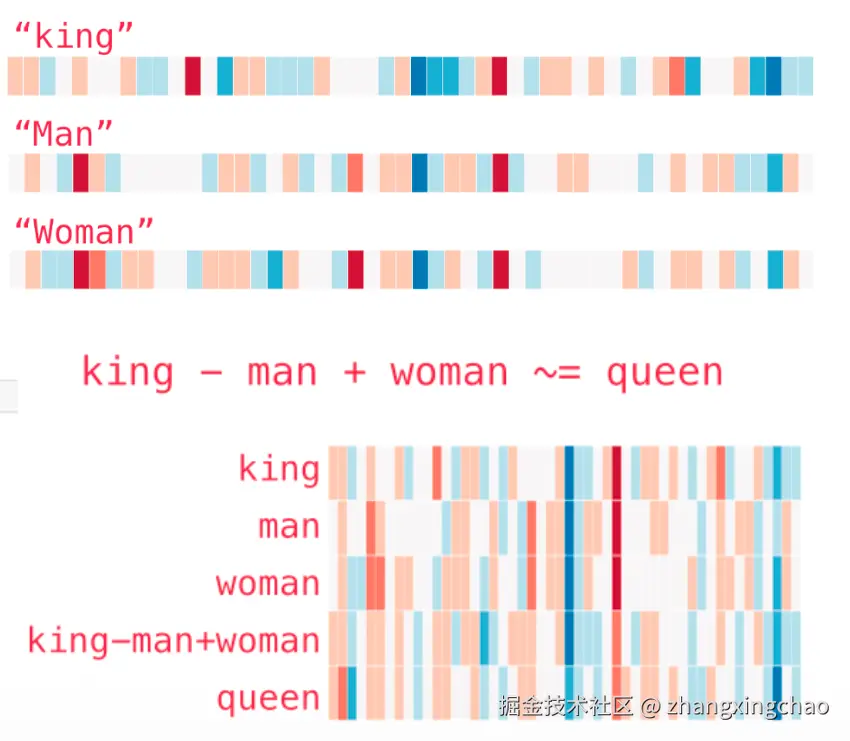
一个经典例子是 King。如果用 GloVe 这类方法对它做向量化,King 会被表示成一组数字。每个维度都可以看成模型学到的某种隐含特征,权重有正有负。
有了这样的向量以后,词之间不仅能比较相似度,还能做一些语义方向上的运算。最常见的例子就是:
text
king - man + woman ≈ queen这不是魔法,而是因为模型在训练过程中把"性别""王室身份"等语义关系编码进了向量空间。
Word2Vec 的直觉
Word2Vec 的核心想法是:一个词的意义,可以从它的上下文里学出来。
它会把词从原来的 one-hot 空间映射到一个新的稠密向量空间里。语义相近的词,在这个空间里距离也更近。
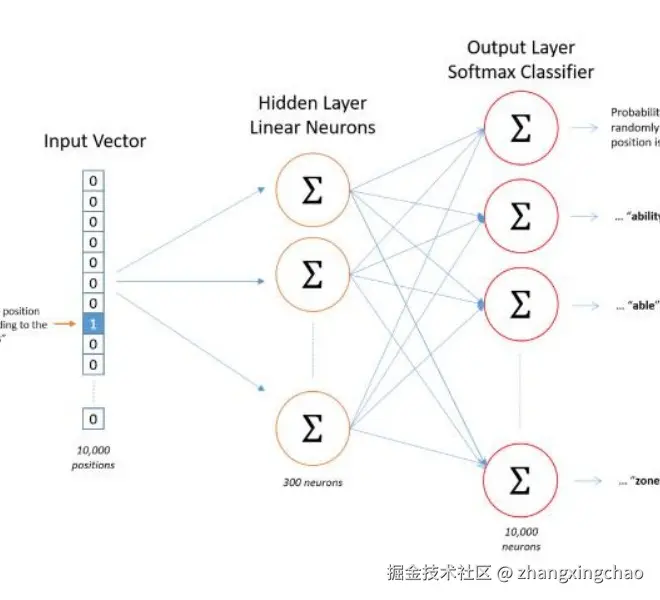
从结构上看,Word2Vec 本质上是在学习输入层到隐藏层之间的权重矩阵:
- 输入层是 one-hot 编码
- 隐藏层大小就是 Embedding Size
- 输入层到隐藏层的权重矩阵
W大小是[vocab_size, hidden_size] - 输出层大小是
[vocab_size],每个位置表示输出某个词的概率
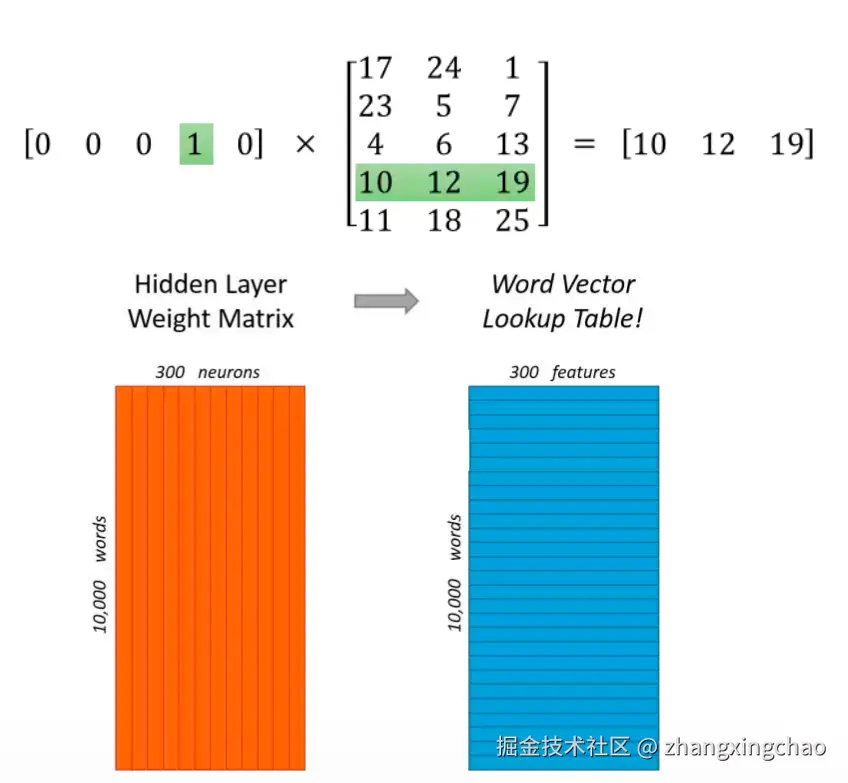
当 one-hot 向量和矩阵相乘时,其实就是从矩阵里取出某一行。这一行就是当前词的向量表示。所以从工程角度看,Word2Vec 也可以理解成一个查找表。
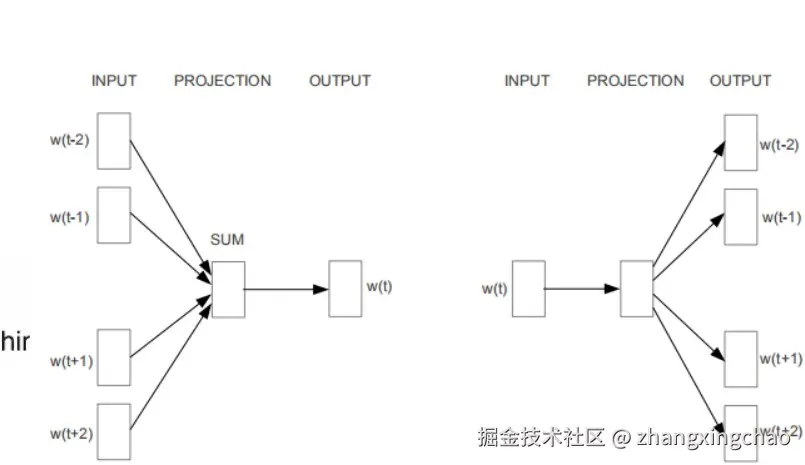
Word2Vec 主要有两种训练方式:
- Skip-Gram:给定中心词,预测上下文
- CBOW:给定上下文,预测中心词
用 Gensim 跑一个 Word2Vec 小实验
如果只是学习和实验,Gensim 是一个很方便的工具。它支持 TF-IDF、LDA、LSA、Word2Vec 等主题模型和向量模型。
安装方式:
bash
pip install gensim最基本的调用方式如下:
python
from gensim.models import word2vec
model = word2vec.Word2Vec(sentences)几个常用参数:
window:当前词和上下文词之间的最大距离min_count:词出现多少次才参与训练size:词向量维度,老版本 Gensim 用这个参数workers:训练线程数
这个例子使用《西游记》做训练,目标是看看小说人物之间的相似度,比如"孙悟空"和"猪八戒"、"孙悟空"和"孙行者"。
第一步是分词,把原始文本切成训练语料:
python
def segment_lines(file_list, segment_out_dir, stopwords=[]):
for i, file in enumerate(file_list):
segment_out_name = os.path.join(segment_out_dir, 'segment_{}.txt'.format(i))
with open(file, 'rb') as f:
document = f.read()
document_cut = jieba.cut(document)
sentence_segment = []
for word in document_cut:
if word not in stopwords:
sentence_segment.append(word)
result = ' '.join(sentence_segment)
result = result.encode('utf-8')
with open(segment_out_name, 'wb') as f2:
f2.write(result)
file_list = files_processing.get_files_list('./source', postfix='*.txt')
segment_lines(file_list, './segment')然后训练 Word2Vec,并计算词之间的相似度:
python
from gensim.models import word2vec
import multiprocessing
sentences = word2vec.PathLineSentences('./segment')
model = word2vec.Word2Vec(sentences, size=100, window=3, min_count=1)
print(model.wv.similarity('孙悟空', '猪八戒'))
print(model.wv.similarity('孙悟空', '孙行者'))
model2 = word2vec.Word2Vec(
sentences,
size=128,
window=5,
min_count=5,
workers=multiprocessing.cpu_count()
)
model2.save('./models/word2Vec.model')
print(model2.wv.similarity('孙悟空', '猪八戒'))
print(model2.wv.similarity('孙悟空', '孙行者'))
print(model2.wv.most_similar(positive=['孙悟空', '唐僧'], negative=['孙行者']))Word2Vec 不只适用于自然语言。只要能把某种行为序列看成"句子",也可以训练类似的向量。
比如:
- 大 V 推荐里,可以把大 V 看作词,把用户关注大 V 的顺序看作句子
- 商品推荐里,可以把商品看作词,把用户浏览、收藏、购买商品的顺序看作句子
这也是 Embedding 在推荐系统里很常见的原因。
如果继续练习,可以用《三国演义》做同样的事:分析和"曹操"最相近的词,或者尝试类似 曹操 + 刘备 - 张飞 这样的向量运算。
现代 Embedding 模型怎么选
Word2Vec 说明了 Embedding 的基本思想。做应用时,通常会直接使用训练好的 Embedding 模型,把文本、文档甚至图片转成向量。
一个 Embedding 模型的核心价值,是把离散数据转换成低维、稠密、可比较的向量。向量空间里的距离,就可以反映语义上的相似度。
选模型时,MTEB 是一个常见参考。MTEB 全称是 Massive Text Embedding Benchmark,覆盖分类、聚类、检索、重排序等多类任务。它不能替代业务评测,但可以初步反映不同模型的大致能力。
榜单地址:
榜单示例如下:
| 排名 | 模型 | Zero-shot | Embedding 维度 | Max Tokens | Mean |
|---|---|---|---|---|---|
| 1 | gemini-embedding-001 | 99% | 3072 | 2048 | 68.37 |
| 2 | Qwen3-Embedding-8B | 99% | 4096 | 32768 | 70.58 |
| 3 | Qwen3-Embedding-4B | 99% | 2560 | 32768 | 69.45 |
| 4 | Qwen3-Embedding-0.6B | 99% | 1024 | 32768 | 64.34 |
| 5 | Linq-Embed-Mistral | 99% | 4096 | 32768 | 61.47 |
| 6 | gte-Qwen2-7B-instruct | N/A | 3584 | 32768 | 62.51 |
| 7 | multilingual-e5-large-instruct | 99% | 1024 | 514 | 63.22 |
| 8 | SFR-Embedding-Mistral | 96% | 4096 | 32768 | 60.90 |
| 9 | text-multilingual-embedding-002 | 99% | 768 | 2048 | 62.16 |
| 10 | GritLM-7B | 99% | 4096 | 32768 | 60.92 |
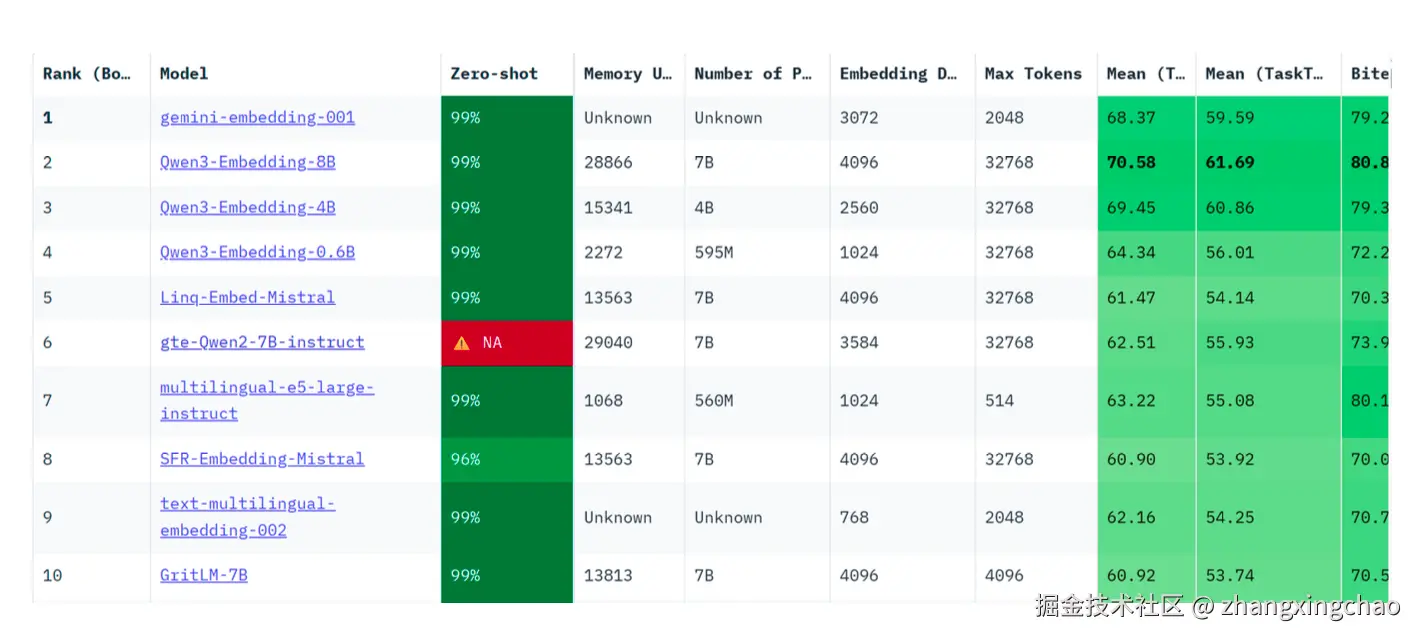
MTEB 的任务类型大致包括:
- 检索(Retrieval):从文档库里找出和 Query 最相关的文档
- 语义文本相似度(STS):判断两句话的语义相似程度
- 重排序(Reranking):对初步召回的结果重新排序
- 分类(Classification):把文本划分到预定义类别
- 聚类(Clustering):把语义相近的文本聚在一起
- 对分类(Pair Classification):判断一对文本是否具有某种关系
- 双语挖掘(Bitext Mining):找出不同语言中互为翻译的句子
- 摘要(Summarization):比较生成摘要和参考摘要的语义相似度
选模型不能只看榜单,还要看几个更贴近业务的问题:
- 任务是检索、分类、聚类,还是 RAG 问答?
- 文本主要是中文、英文,还是多语言混合?
- 业务更看重召回率、准确率、NDCG,还是延迟和成本?
- 模型维度和上下文长度是否适合当前数据?
- 有没有自己的小规模黄金测试集?
向量维度不是越大越好
向量维度会影响表达能力,也会影响计算和存储成本。
高维向量,比如 1024、4096 维,通常能编码更丰富的语义信息,适合复杂检索和细粒度分类。但维度越高,索引体积越大,检索成本也更高。
低维向量,比如 256、512 维,速度更快、存储更省,更适合资源有限或者实时性要求高的场景。
比如从 768 维升到 1024 维,检索指标只提升不到 1%,但内存多占 35%,这种情况通常不值得。反过来,如果压到 768 维后指标下降超过 5%,那就说明信息损失比较明显,继续使用更高维度更合理。
Jina Embedding 和"俄罗斯套娃"
Jina AI 的 jina-embeddings-v4 是一个多模态、多语言检索模型,适合处理复杂文档检索,尤其是带图表、表格、插图的文档。
模型地址:
它一个很实用的点是支持灵活的嵌入大小。默认密集向量是 2048 维,但可以截断到 128、256、512、1024 等维度,同时尽量保持可用的语义质量。
| 特性 | Jina-Embedding-V4 |
|---|---|
| 基础模型 | Qwen2.5-VL-3B-Instruct |
| 支持的任务 | 检索、文本匹配、代码 |
| 模型数据类型 | BFloat 16 |
| 最大序列长度 | 32768 |
| 单向量维度 | 2048 |
| 多向量维度 | 128 |
| 套娃维度 | 128、256、512、1024、2048 |
| 池化策略 | 平均池化 |
| 注意力机制 | FlashAttention2 |
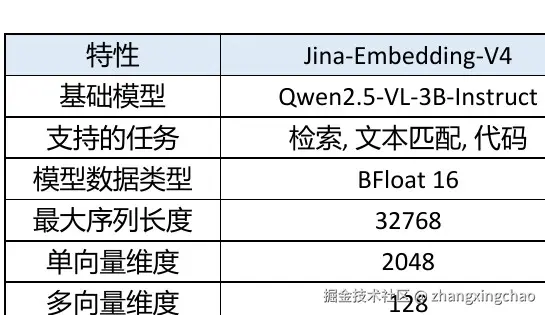
这里的"套娃"指的是 Matryoshka Representation Learning,也就是 MRL。它的直觉是:模型先生成一个完整的高维向量,比如 2048 维;这个向量的前 128 维、前 256 维、前 512 维,也都可以作为相对完整的短向量使用。

这样做的好处是可以按场景动态调整维度。
比如社交媒体情感分析,文本短、实时性强、资源有限,用 128 维可能就够了。再比如投资分析报告,文本长、术语多、细节重要,就更适合用 2048 维。
单语言和多语言模型怎么选
如果业务几乎全是中文,比如电商客服 FAQ,那么单语言中文模型通常更合适。它对中文语义、表达习惯、业务词的理解会更深入,比如"七天无理由退货""订单何时送达""如何办理退换货"。
如果业务天然是多语言,比如国际酒店评论分析,那就需要多语言模型。用户可能用英文查询 Loud music at night,系统需要同时找出日文的"夜に音楽がうるさい"和中文的"晚上音乐很吵"。这要求不同语言的表达能映射到同一个语义空间。
text
"clean room"、"部屋が綺麗"、"干净的房间"这些表达的向量足够接近,跨语言检索和聚类才有意义。
Embedding 模型选型不能只看"榜单排名最高"。比较稳的做法是:先明确业务任务和指标,再构建一套小规模黄金测试集,然后挑几款候选模型做 Benchmark。最终选型要同时考虑效果、延迟、成本和部署复杂度。
向量数据库:给大模型一个可检索的外部记忆
Embedding 解决的是"怎么把内容变成向量",向量数据库解决的是"怎么把这些向量存好、查快、管起来"。
这里容易误会:向量数据库不是用来替代 MySQL、PostgreSQL 这类传统数据库的。它更像一个专门负责"按语义相似度找东西"的检索层。用户、订单、权限、状态这些业务数据,通常仍然要放在传统数据库里管理。
在 RAG、知识库问答、推荐系统里,大模型不可能把所有私有知识都放进上下文窗口。更常见的做法是:把文档提前切分、向量化、存入向量数据库;用户提问时,先检索相关内容,再把检索结果交给大模型生成回答。
向量数据库主要有三点价值:
- 给大模型提供长期记忆,弥补上下文窗口长度和知识更新延迟的问题
- 支撑私有知识库问答和语义搜索,把内部文档、产品信息转成可检索向量
- 支撑推荐、以图搜图等应用,通过向量相似度找到相近对象
常见向量数据库可以这样看:
- FAISS:更像一个高性能向量检索算法库,不是完整数据库,适合研究和需要自己搭服务层的场景
- Elasticsearch:传统搜索能力强,适合关键词搜索和向量搜索结合的混合搜索场景
- Milvus:开源向量数据库,功能完整,适合大规模向量数据和企业级部署
- Pinecone:托管云服务,部署简单,适合快速上线和少运维团队
向量数据库和传统数据库的差异可以简单对比一下:
| 对比项 | 传统数据库 | 向量数据库 |
|---|---|---|
| 数据类型 | 存储结构化数据,如表格、行、列 | 存储高维向量数据,适合非结构化数据 |
| 查询方式 | 依赖精确匹配,如 =、<、> |
基于相似度或距离度量,如欧几里得距离、余弦相似度 |
| 应用场景 | 适合事务记录和结构化信息管理 | 适合语义搜索、内容推荐等需要相似性计算的场景 |
数据怎么导入向量数据库
向量数据库不是直接吃原始文档的。导入数据通常是这个流程:
- 清洗原始数据,比如文档、网页、图片、音视频
- 使用 Embedding 模型把数据转换成向量
- 把向量、唯一 ID、元数据一起写入存储系统
- 查询时把 Query 也转成向量,再做相似度检索
如果是文本,可以使用 bge-m、Qwen3-Embedding、Jina-Embedding、text-embedding-v4 等模型;如果是图片,可以使用 CLIP、ResNet 等模型。
下面是一个用百炼兼容 OpenAI SDK 计算 Embedding 的例子:
python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
completion = client.embeddings.create(
model="text-embedding-v4",
input='我想知道迪士尼的退票政策',
dimensions=1024,
encoding_format="float"
)
print(completion.model_dump_json())返回结果里会包含一个 embedding 数组:
json
{
"data": [
{
"embedding": [
0.00954423751682043,
-0.11166470497846603,
0.0002610872033983469,
-0.04448245093226433,
0.018730206415057182,
"...省略后续向量..."
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-v4",
"object": "list",
"usage": {
"prompt_tokens": 23,
"total_tokens": 23
},
"id": "84faa227-2672-94df-87d3-a1648dc7aea7"
}还有一点要单独记下来:向量本身不够用,还必须保存元数据。 向量数据库里通常不是只存向量,而是会同时存三类东西:
| 类型 | 示例 | 作用 |
|---|---|---|
| 原文内容 | "迪士尼门票一经售出......" | 最后给大模型参考 |
| 向量 | [0.012, -0.034, ...] |
用来做相似度检索 |
| 元数据 | source=官网, page=3, title=退票政策 |
用来过滤、溯源、引用 |
比如一条向量背后对应哪篇文档、哪个章节、哪个 URL、哪个商品、哪个作者,这些都不是向量能直接提供的信息。实际系统里,检索返回的是向量 ID,还要根据 ID 找回原始文本和元数据。
小规模练习时,用一个 Python 列表保存元数据已经够了。到了真实项目里,向量 ID、文档 ID、业务 ID 之间的关系要提前设计清楚。否则即使找到了最相似的向量,系统也不知道该把哪段原文、哪个商品或哪篇文档返回给用户。
用 FAISS 存 Embedding 和元数据
FAISS 本身只负责向量索引和检索,不负责存元数据。所以要把 FAISS 和一个外部元数据存储搭配起来。最简单的方式是维护一个 metadata_store,并通过向量 ID 关联。
下面准备 4 条迪士尼相关文档,每条文档都有 text 和 metadata:
python
documents = [
{
"id": "doc1",
"text": "迪士尼乐园的门票一经售出,原则上不予退换。但在特殊情况下,如恶劣天气导致园区关闭,可在官方指引下进行改期或退款。",
"metadata": {
"source": "official_faq_v1.pdf",
"category": "退票政策",
"author": "Admin"
}
},
{
"id": "doc2",
"text": "购买"奇妙年卡"的用户,可以享受一年内多次入园的特权,并且在餐饮和购物时有折扣。",
"metadata": {
"source": "annual_pass_rules.docx",
"category": "会员权益",
"author": "MarketingDept"
}
},
{
"id": "doc3",
"text": "对于在线购买的迪士尼门票,如果需要退票,必须在票面日期前48小时通过原购买渠道提交申请,并可能收取手续费。",
"metadata": {
"source": "online_policy.html",
"category": "退票政策",
"author": "E-commerceTeam"
}
},
{
"id": "doc4",
"text": "园区内餐厅支持提前预约,热门餐厅建议至少提前一周预约。",
"metadata": {
"source": "restaurant_guide.pdf",
"category": "餐饮服务",
"author": "OpsTeam"
}
}
]然后逐条生成向量,同时把元数据和向量 ID 存下来:
python
metadata_store = []
vectors_list = []
vector_ids = []
print("正在为文档生成向量...")
for i, doc in enumerate(documents):
try:
completion = client.embeddings.create(
model="text-embedding-v4",
input=doc["text"],
dimensions=1024,
encoding_format="float"
)
vector = completion.data[0].embedding
vectors_list.append(vector)
metadata_store.append(doc)
vector_ids.append(i)
print(f" - 已处理文档 {i + 1}/{len(documents)}")
except Exception as e:
print(f"处理文档 '{doc['id']}' 时出错: {e}")
continue
vectors_np = np.array(vectors_list).astype('float32')
vector_ids_np = np.array(vector_ids)接下来创建 FAISS 索引。这里用 IndexIDMap 包一层,是为了给每个向量指定自定义 ID。这个 ID 就是向量和元数据之间的桥。
python
dimension = 1024
k = 3
index_flat_l2 = faiss.IndexFlatL2(dimension)
index = faiss.IndexIDMap(index_flat_l2)
index.add_with_ids(vectors_np, vector_ids_np)
print(f"\nFAISS 索引已成功创建,共包含 {index.ntotal} 个向量。")查询时,把用户问题也转成向量,再到 FAISS 里搜索最相似的向量:
python
query_text = "我想了解一下迪士尼门票的退款流程"
print(f"\n正在为查询文本生成向量: '{query_text}'")
try:
query_completion = client.embeddings.create(
model="text-embedding-v4",
input=query_text,
dimensions=1024,
encoding_format="float"
)
query_vector = np.array(
[query_completion.data[0].embedding]
).astype('float32')
distances, retrieved_ids = index.search(query_vector, k)
except Exception as e:
print(f"执行搜索时发生错误: {e}")最后根据返回的 ID,从 metadata_store 里取回原始文本和元数据:
python
print("\n--- 搜索结果 ---")
for i in range(k):
doc_id = retrieved_ids[0][i]
if doc_id == -1:
print(f"\n排名 {i + 1}: 未找到更多结果。")
continue
retrieved_doc = metadata_store[doc_id]
print(f"\n--- 排名 {i + 1} (相似度得分/距离: {distances[0][i]:.4f}) ---")
print(f"ID: {doc_id}")
print(f"原始文本: {retrieved_doc['text']}")
print(f"元数据: {retrieved_doc['metadata']}")示例结果里,和"退款流程"最相似的是在线退票政策,其次是官方 FAQ 里的退换说明:
text
--- 排名 1 (相似度得分/距离: 0.3222) ---
ID: 2
原始文本: 对于在线购买的迪士尼门票,如果需要退票,必须在票面日期前48小时通过原购买渠道提交申请,并可能收取手续费。
元数据: {'source': 'online_policy.html', 'category': '退票政策', 'author': 'E-commerceTeam'}
--- 排名 2 (相似度得分/距离: 0.3312) ---
ID: 0
原始文本: 迪士尼乐园的门票一经售出,原则上不予退换。但在特殊情况下,如恶劣天气导致园区关闭,可在官方指引下进行改期或退款。
元数据: {'source': 'official_faq_v1.pdf', 'category': '退票政策', 'author': 'Admin'}
--- 排名 3 (相似度得分/距离: 1.0135) ---
ID: 1
原始文本: 购买"奇妙年卡"的用户,可以享受一年内多次入园的特权,并且在餐饮和购物时有折扣。
元数据: {'source': 'annual_pass_rules.docx', 'category': '会员权益', 'author': 'MarketingDept'}到这里,完整检索链路已经跑通:准备文档,生成向量,建立 FAISS 索引,查询时生成 Query 向量,FAISS 返回最相似的向量 ID,再通过 ID 找回原始文本和元数据。
在真实生产环境里,metadata_store 不会一直用 Python 列表。更常见的选择是:
- Redis:适合通过 ID 快速查询,性能高
- PostgreSQL:适合结构化元数据和复杂查询
- MongoDB:适合存 JSON 结构的元数据
FAISS 继续专注高速向量检索,元数据交给更适合的数据库,这样架构会更清晰。
常见向量数据库怎么选
几个常见方案的对比如下:
| 数据库 | 核心特点 | 性能表现 | 适用场景 |
|---|---|---|---|
| FAISS | 核心算法库,非数据库。由 Meta AI 开发,提供最广泛、最前沿的 ANN 索引算法,支持 CPU 和 GPU | 纯粹的性能标杆。在内存中进行裸向量检索时速度极快,尤其是 GPU 版本,是衡量其他数据库性能的基准 | 算法研究者;需要将向量检索能力深度集成到现有系统中的团队;可以自行构建服务层,如 API、元数据管理 |
| Milvus | 开源领导者,功能全面。云原生架构,高度可扩展。支持多种 ANN 索引和丰富的调优参数 | 在多个公开 ANN 基准测试中,尤其是在大规模数据集上表现优异,吞吐量和延迟控制得很好 | 需要处理海量数据、对性能和扩展性有高要求的企业级应用。适合有一定运维能力的团队进行私有化部署 |
| Pinecone | 全托管的商业先驱。主打 Serverless 和易用性,API 设计简洁。性能稳定,专注于提供极致的低延迟检索 | 性能非常出色,尤其在低延迟方面有优势。由于是闭源托管服务,其内部优化细节不透明,但用户体验顺滑 | 追求快速上线、希望将运维负担降至最低的团队。适合初创公司和需要快速验证 AI 应用可行性的场景 |
| Weaviate | 开源,内置数据向量化模块。能够连接各种 Embedding 模型,实现数据自动向量化,简化开发流程 | 性能良好,易用性强。自动向量化功能在开发效率上是一大亮点 | 希望简化 ETL 流程,快速构建从数据到向量再到检索的全链路应用的开发者 |
| Qdrant | 开源,以性能和内存安全著称,使用 Rust 开发。过滤查询能力强大且高效 | 性能强劲,尤其在过滤条件复杂的混合查询场景下表现突出。内存使用效率高 | 对检索性能和资源利用率有极致要求的场景。金融、电商等需要复杂过滤规则的应用 |
| Elasticsearch | 通用搜索巨头,扩展向量检索能力。将向量检索 KNN 作为功能之一,可以无缝结合全文检索、聚合分析能力 | 作为通用数据库,其向量检索性能通常弱于专门的向量数据库。但在混合搜索(关键词 + 向量)场景下表现优异 | 业务需求是"以文本搜索为主,向量搜索为辅",希望在一个统一平台中解决所有搜索问题,而非追求极致向量检索性能 |
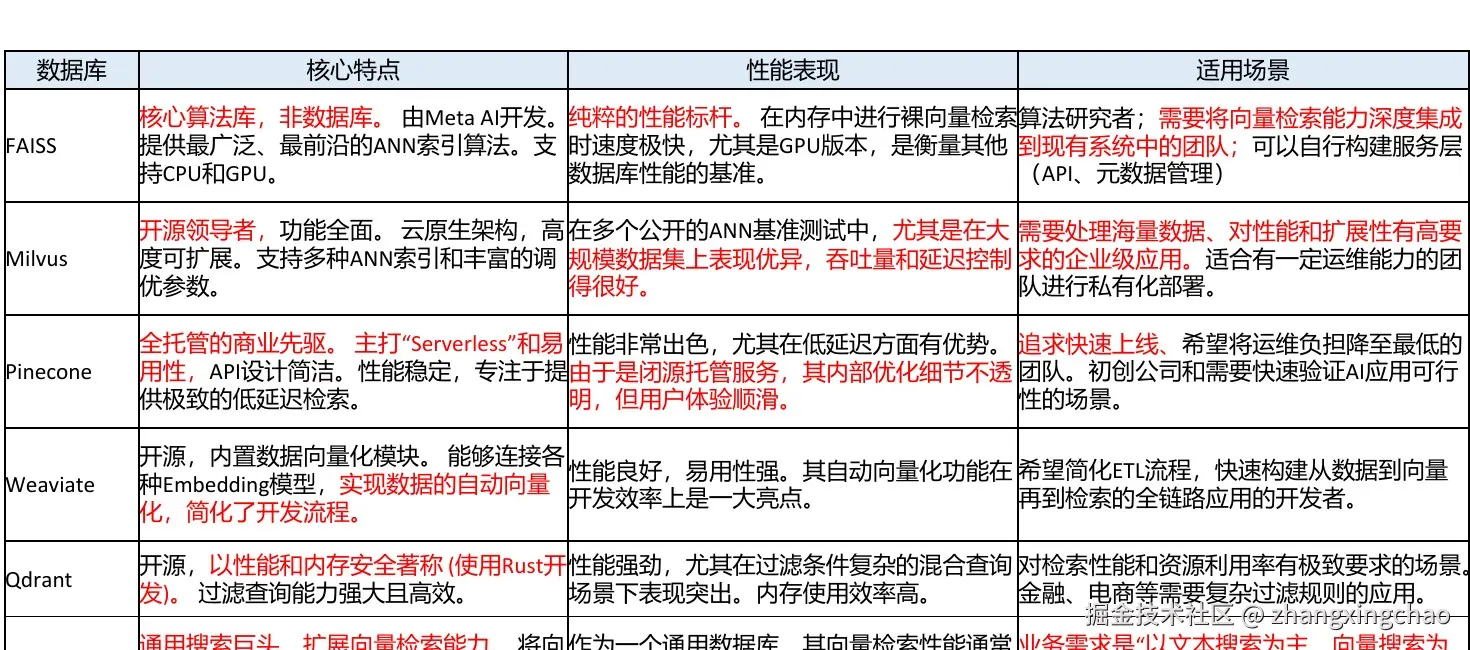
如果只是学习和做算法实验,FAISS 很合适。如果要做企业级向量检索服务,可以重点看 Milvus、Qdrant、Weaviate。想快速上线、少做运维,Pinecone 这种托管服务会更省事。如果团队原本就大量使用 Elasticsearch,并且关键词搜索仍然是主需求,那么在 ES 上叠加向量检索也很自然。
小结
整理到最后,几个关键点是:
- 原始文本不能直接做语义计算,需要先变成向量。
- 传统的 N-Gram、TF-IDF 可以做基础推荐,但语义表达能力有限。
- Word Embedding 把词放进语义空间,让相似度和向量运算变得可行。
- 现代 Embedding 模型进一步把句子、文档、图片等内容变成高质量向量。
- 向量数据库负责高效存储和检索这些向量。
- 业务落地时,向量和元数据必须一起管理,否则检索结果很难回到业务数据。
Embedding 解决"怎么表示",向量数据库解决"怎么检索和管理"。这两块接起来,才是 RAG、语义搜索、推荐系统这类 AI 应用的基础设施。
总结
怎么把文本、图片、文档这些原始内容变成向量,然后用向量做相似度检索,最后用向量数据库支撑搜索、推荐和 RAG。
简单说,不是单独讲 Embedding,也不是单独讲向量数据库,而是在讲完整链路:
js
准备文档
↓
文档切分 chunk
↓
调用 Embedding 模型,把 chunk 转成向量
↓
向量 + 原文 + 元数据 存入向量数据库
↓
用户提问
↓
用户问题转成向量
↓
去向量数据库检索相似内容
↓
取回相关原文片段
↓
把"原文片段 + 用户问题"发给大模型
↓
大模型生成答案外部知识库 → 检索 → 拼进 Prompt → 大模型回答
按内容看,大概分成几块:
-
从酒店推荐开始
用西雅图酒店数据集举例:如果想推荐相似酒店,就要先把酒店描述文本变成可计算的特征,再计算酒店之间的相似度,最后取最相似的 Top 10。
-
传统文本特征怎么做
先讲 N-Gram、词频、TF-IDF。
这些方法可以把文本变成向量,但它们主要看词面,比如词有没有出现、出现几次。问题是语义理解比较弱,比如"退票"和"退款"意思接近,但词面不同。
-
为什么需要 Word Embedding
Word Embedding 是把词映射到稠密向量空间里。
这样语义相近的词距离更近,还能做类似:
king - man + woman ≈ queenWord2Vec、Skip-Gram、CBOW、Gensim 训练实验
-
现代 Embedding 模型怎么选
后面从 Word2Vec 过渡到现在常用的 Embedding 模型,比如看 MTEB 榜单、模型维度、最大 token、中文/多语言能力、成本和延迟。
Jina Embedding 和"俄罗斯套娃"向量,也就是同一个向量可以截成不同维度来用。
-
向量数据库是干什么的
Embedding 解决"怎么表示内容",向量数据库解决"怎么存、怎么查、怎么管理"。
在 RAG、知识库问答、语义搜索里,流程通常是:先把文档切块、向量化、存进去;用户提问时,再把问题向量化,查出最相关的内容。
-
FAISS 怎么和元数据一起用
FAISS 本身更像高性能向量检索库,不是完整数据库。
它负责查"哪个向量最相似",但不知道这个向量对应哪篇文档、哪个章节、哪个 URL。
所以还要维护 metadata_store,把向量 ID 和原始文本、来源、分类等元数据关联起来。
-
常见向量数据库怎么选
对比 FAISS、Milvus、Pinecone、Weaviate、Qdrant、Elasticsearch。
学习和实验可以用 FAISS;企业级向量检索可以看 Milvus/Qdrant/Weaviate;想少运维可以用 Pinecone;如果原本就重度依赖 ES,也可以做混合搜索。
AI 应用里,原始内容不能直接被检索和推理,必须先变成向量;向量能表达语义相似度;向量数据库负责把这些向量高效存起来、查出来,并通过元数据回到真实业务数据。