目 录
- 背景:为什么做这次升级
- [原始问题:RAGSystem 直接依赖 FAISS](#原始问题:RAGSystem 直接依赖 FAISS)
- [第一步:抽象 VectorStore 接口](#第一步:抽象 VectorStore 接口)
- [第二步:把原 FAISS 逻辑迁移到 FaissVectorStore](#第二步:把原 FAISS 逻辑迁移到 FaissVectorStore)
- [第三步:用 factory 根据配置切换向量库](#第三步:用 factory 根据配置切换向量库)
- [第四步:接入 Milvus Lite](#第四步:接入 Milvus Lite)
- 最终结果
背景:为什么做这次升级
最近准备入职 AI Agent 项目组,公司技术文档中提到 AI 核心服务使用 FastAPI,业务后台使用 SpringBoot,数据层包括 MySQL、Redis 和 Milvus。
当前的 Paper-RAG-Agent-with-LangGraph 系统使用的 FAISS 知识向量数据库,但是和落地场景下的实际项目还有差距,这次升级主要目的是把这个系统往工业落地上靠一靠,同时本人也能学习新的技术栈。
总体来看,通过这次升级我感觉 FAISS 知识向量数据库更像是一种内存级的知识向量数据库,Milvus 像是更像是一种存在文件系统里面的数据库,可能用传统数据库打比方,FAISS 更像是 Redis ,Milvus像是Mysql。
原始问题:RAGSystem 直接依赖 FAISS
先说原来系统的问题,这段时间我有关注一些现有的新技术,其实知识向量数据库不止有 FAISS 和Milvus 还有其他的比如Qdrant、Chroma。我查了一下Geimin得到的个数据库的对比是这样的,所以感觉Milvus综合表现或者说普适性比较高。纯个人感觉。
| 维度指标 | FAISS | Chroma | Qdrant | Milvus |
|---|---|---|---|---|
| 工具定位 | 底层高维向量检索算法库 | 嵌入式轻量级应用数据库 | 生产级高性能向量搜索引擎 | 云原生企业级分布式数据库 |
| 核心开发语言 | C++(提供 Python 接口) | Python / TypeScript | Rust | Go / C++ |
| 部署形态 | 进程内加载,本地文件持久化 | 嵌入式运行(免运维)/ 单机 | 独立 Server / 分布式集群 | K8s 分布式集群 / Lite 本地版 |
| 元数据过滤 | 极弱(通常需在外层应用自行映射) | 中等(小规模好,大规模有明显瓶颈) | 极强(原生高效支持 Payload 过滤) | 强(支持复杂的结构化与标量过滤) |
| 适用数据规模 | 百万级单机或离线静态数据集 | 十万到百万级(中小型数据规模) | 千万到亿级(高性能高并发场景) | 数亿到数百亿级(海量大厂级数据) |
| 内存与硬件 | 极低(内存密集型,支持 GPU 加速) | 中等(随向量增长内存消耗较大) | 极佳(Rust 内存控制极其精准) | 较高(分布式节点多,硬件开销大) |
| 主要优势 | 底层计算速度快,硬件优化到了芯片级 | 零运维成本,开箱即用,开发效率高 | 过滤极快,单机性价比和稳定性口碑极佳 | 天花板级的水平扩展性,企业级特性完备 |
| 主要劣势 | 不是完整数据库,无动态 CRUD 和接口 | 无法承受海量数据,缺乏高可用集群能力 | 国内商业化和全量大厂生态稍逊于 Milvus | 极其沉重,运维难度和算力成本很高 |
| 最佳适用场景 | 学术研究、离线检索、或自研引擎底座 | 快速搭建 RAG 原型、个人或早期的 Demo | 中大型商业生产环境,高频混合条件检索 | 集团级大模型平台、超大规模多租户知识库 |
还是回到原来项目的问题,原来项目的RAG系统中,向量知识库构建和检索的代码和FAISS高度耦合 。这样会有点问题,就是后面如果我想换其他的知识向量数据库,就需要动rag_system.py,所以今天第一个任务需要将rag系统和FAISS解耦,这样方便替换其他的知识向量数据库。也就是需要将:
Question
↓
Embedding
↓
FAISS Retrieval
↓
Rerank
↓
Answer Generation改成:
Question
↓
Embedding
↓
VectorStore.search()
├── FAISS
└── Milvus
↓
Rerank
↓
Answer Generation这样的话可以方便未来扩展其他知识向量数据库,需要动的文件有:
app/rag_system.py # 当前 FAISS 写在这里,要改成调用 vector_store
app/config.py # 增加 VECTOR_STORE / MILVUS_URI / MILVUS_COLLECTION_NAME
app/main.py # /startup 和 /reload_kb 仍然调用 rag.build_index()
新增:
app/vector_store/base.py #这里是知识向量数据库的模板,主要定义一个创建知识向量数据库和搜索知识的方法。
app/vector_store/faiss_store.py
app/vector_store/milvus_store.py第一步:抽象 VectorStore 接口
新建:
app/vector_store/
├── base.py
├── faiss_store.py
└── factory.py但是这一步的关键是新建base.py,因为在其中要定义向量库的模板:
python
from abc import ABC, abstractmethod
class BaseVectorStore(ABC):
@abstractmethod
def build(self, chunks: list[dict]) -> None:
pass
@abstractmethod
def search(self, query: str, k: int) -> list[dict]:
pass第一个抽象方法的作用是构建数据库,第二个方法是检索Top-K相关的chunk。
第二步:把原 FAISS 逻辑迁移到 FaissVectorStore
有了通用的知识向量库模板,就可以创建具体的库,并且开始将原来的FAISS逻辑迁移过去了。首先是创建faiss_store.py:FaissVectorStore类,然后将写在rag_system.py中的逻辑迁移过去:
RAGSystem.build_index()
↓
FaissVectorStore.build()
RAGSystem.retrieve()
↓
FaissVectorStore.search()同时要修改rag_system.py的逻辑,让他成为一个更通用的模式,这样不管未来是任何知识向量数据库,他都可以执行:
python
class RAGSystem:
def __init__(self, chunks, top_k=20, rerank_k=10, vector_store=None):
self.chunks = chunks
self.top_k = top_k
self.rerank_k = rerank_k
self.vector_store = vector_store or FaissVectorStore()
def build_index(self):
self.vector_store.build(self.chunks)
def retrieve(self, query, k=5):
return self.vector_store.search(query, k)faiss_store.py的具体实现逻辑如下:
python
# app/vector_store/faiss_store.py
import faiss
import numpy as np
from app.llm_utils import get_embedding
from app.logger_config import setup_logger
from app.vector_store.base import BaseVectorStore
logger = setup_logger()
class FaissVectorStore(BaseVectorStore):
def __init__(self):
self.chunks = []
self.index = None
self.embeddings = None
def build(self, chunks: list[dict]) -> None:
"""
Build FAISS index from document chunks.
chunks format:
[
{
"text": "...",
"source": "Paper1.pdf"
}
]
"""
self.chunks = chunks
if not self.chunks:
logger.warning("[FaissVectorStore.build] no chunks provided")
self.index = None
self.embeddings = None
return
texts = [c["text"] for c in self.chunks]
embeddings = [get_embedding(t) for t in texts]
self.embeddings = np.vstack(embeddings).astype("float32")
dim = self.embeddings.shape[1]
self.index = faiss.IndexFlatL2(dim)
self.index.add(self.embeddings)
logger.info(
f"[FaissVectorStore.build] index built, "
f"chunks={len(self.chunks)}, dim={dim}"
)
def search(self, query: str, k: int = 5) -> list[dict]:
"""
Search top-k related chunks from FAISS.
Return format must stay compatible with RAGSystem:
[
{
"text": "...",
"source": "...",
"distance": 1.23,
"retrieval_rank": 1
}
]
"""
if self.index is None:
raise RuntimeError("FAISS index has not been built.")
if not self.chunks:
logger.warning("[FaissVectorStore.search] no chunks available")
return []
k = min(k, len(self.chunks))
query_vec = get_embedding(query).reshape(1, -1).astype("float32")
distances, indices = self.index.search(query_vec, k)
results = []
for rank, (idx, distance) in enumerate(zip(indices[0], distances[0]), start=1):
idx = int(idx)
if idx < 0 or idx >= len(self.chunks):
continue
chunk = dict(self.chunks[idx])
chunk["distance"] = float(distance)
chunk["retrieval_rank"] = rank
results.append(chunk)
if results:
best_distance = min(c["distance"] for c in results)
logger.info(
f"[FaissVectorStore.search] query='{query}', "
f"returned={len(results)}, best_distance={best_distance:.4f}"
)
else:
logger.warning(
f"[FaissVectorStore.search] query='{query}', no valid chunks returned"
)
return resultsFaissVectorStore 主要负责:
- 接收 chunks;
- 调用 embedding;
- 构建 FAISS IndexFlatL2;
- 查询 query embedding;
- 返回统一格式。
返回结构必须保持,才能保证后面的 rerank、context sufficiency、Retrieved Context、Agent Trace 都不用改:
source
text
distance
retrieval_rank第三步:用 factory 根据配置切换向量库
随后添加config.py的配置:
python
VECTOR_STORE = os.getenv("VECTOR_STORE", "faiss").lower()
# 注意:不要命名为 MILVUS_URI,避免和 pymilvus 内部配置冲突
MILVUS_LITE_URI = os.getenv("MILVUS_LITE_URI", "./milvus_demo.db")
MILVUS_COLLECTION_NAME = os.getenv("MILVUS_COLLECTION_NAME", "paper_rag_chunks")
MILVUS_METRIC_TYPE = os.getenv("MILVUS_METRIC_TYPE", "L2")相应的添加.env配置:
python
VECTOR_STORE=milvus
#VECTOR_STORE=faiss # 通过调整这里可以切换faiss或者milvus
MILVUS_LITE_URI=./milvus_demo.db
MILVUS_COLLECTION_NAME=paper_rag_chunks
MILVUS_METRIC_TYPE=L2第四步:接入 Milvus Lite
新增app/vector_store/milvus_store.py,Milvus 里使用 collection 存储论文 chunks。Milvus 的 collection 可以粗略类比 MySQL 里的表,只不过它主要存的是向量和向量对应的元数据。
字段包括:
id
vector
text
source
chunk_id检索返回仍然保持:
source
text
distance
retrieval_rankMilvus向量数据库构建:
python
from pymilvus import MilvusClient
from app.llm_utils import get_embedding
from app.logger_config import setup_logger
from app.vector_store.base import BaseVectorStore
from app.config import (
MILVUS_LITE_URI,
MILVUS_COLLECTION_NAME,
MILVUS_METRIC_TYPE,
)
logger = setup_logger()
class MilvusVectorStore(BaseVectorStore):
def __init__(
self,
uri: str = MILVUS_LITE_URI,
collection_name: str = MILVUS_COLLECTION_NAME,
metric_type: str = MILVUS_METRIC_TYPE,
drop_old: bool = True,
):
self.uri = uri
self.collection_name = collection_name
self.metric_type = metric_type
self.drop_old = drop_old
self.client = MilvusClient(uri=self.uri)
self.chunks = []
def build(self, chunks: list[dict]) -> None:
"""
Build Milvus collection from document chunks.
Current experiment version:
- rebuilds the whole collection each time
- keeps the same output format as FaissVectorStore.search()
"""
self.chunks = chunks
if not self.chunks:
logger.warning("[MilvusVectorStore.build] no chunks provided")
return
texts = [c["text"] for c in self.chunks]
embeddings = [get_embedding(t).tolist() for t in texts]
dim = len(embeddings[0])
if self.drop_old and self.client.has_collection(
collection_name=self.collection_name
):
self.client.drop_collection(
collection_name=self.collection_name
)
logger.info(
f"[MilvusVectorStore.build] dropped old collection: "
f"{self.collection_name}"
)
if not self.client.has_collection(collection_name=self.collection_name):
try:
self.client.create_collection(
collection_name=self.collection_name,
dimension=dim,
metric_type=self.metric_type,
)
except TypeError:
# Compatible fallback for pymilvus versions that do not accept metric_type here.
self.client.create_collection(
collection_name=self.collection_name,
dimension=dim,
)
logger.info(
f"[MilvusVectorStore.build] collection created: "
f"{self.collection_name}, dim={dim}"
)
data = []
for i, (chunk, vector) in enumerate(zip(self.chunks, embeddings)):
data.append(
{
"id": i,
"vector": vector,
"text": chunk.get("text", ""),
"source": chunk.get("source", "unknown"),
"chunk_id": i,
}
)
self.client.insert(
collection_name=self.collection_name,
data=data,
)
logger.info(
f"[MilvusVectorStore.build] inserted chunks={len(data)} "
f"into collection={self.collection_name}"
)
def search(self, query: str, k: int = 5) -> list[dict]:
"""
Search top-k related chunks from Milvus.
Return format must stay compatible with RAGSystem:
[
{
"text": "...",
"source": "...",
"distance": 1.23,
"retrieval_rank": 1
}
]
"""
if not self.client.has_collection(collection_name=self.collection_name):
raise RuntimeError(
f"Milvus collection has not been built: {self.collection_name}"
)
query_vec = get_embedding(query).tolist()
raw_results = self.client.search(
collection_name=self.collection_name,
data=[query_vec],
limit=k,
output_fields=["text", "source", "chunk_id"],
)
results = []
if not raw_results:
logger.warning(
f"[MilvusVectorStore.search] query='{query}', empty search result"
)
return results
for rank, item in enumerate(raw_results[0], start=1):
entity = item.get("entity", {})
chunk = {
"source": entity.get("source", "unknown"),
"text": entity.get("text", ""),
"chunk_id": entity.get("chunk_id"),
"distance": float(item.get("distance", 0.0)),
"retrieval_rank": rank,
}
results.append(chunk)
if results:
best_distance = min(c["distance"] for c in results)
logger.info(
f"[MilvusVectorStore.search] query='{query}', "
f"returned={len(results)}, best_distance={best_distance:.4f}"
)
else:
logger.warning(
f"[MilvusVectorStore.search] query='{query}', no valid chunks returned"
)
return results最终结果
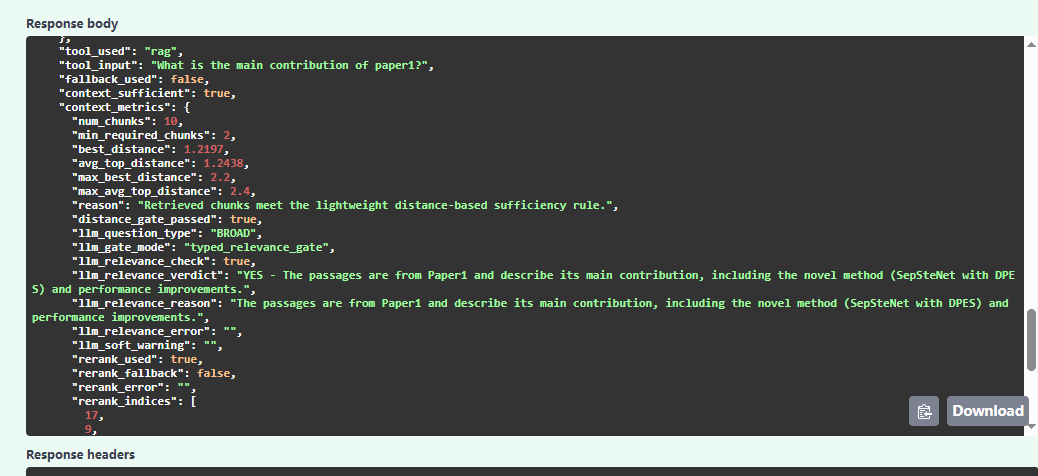
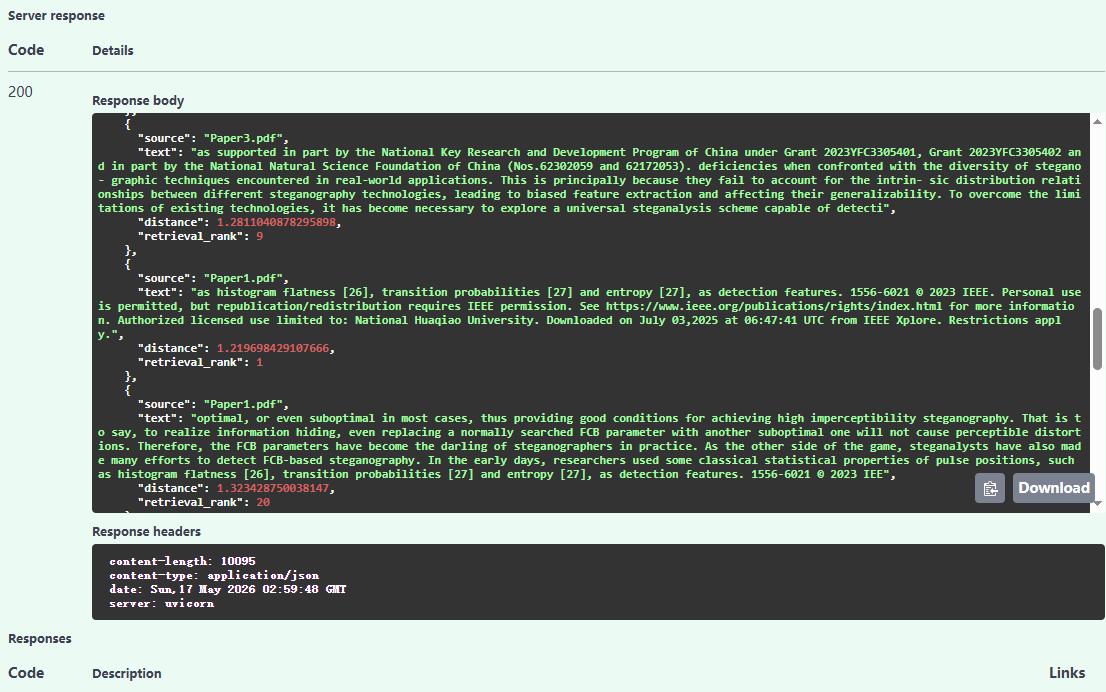
基于FAISS的检索结果:
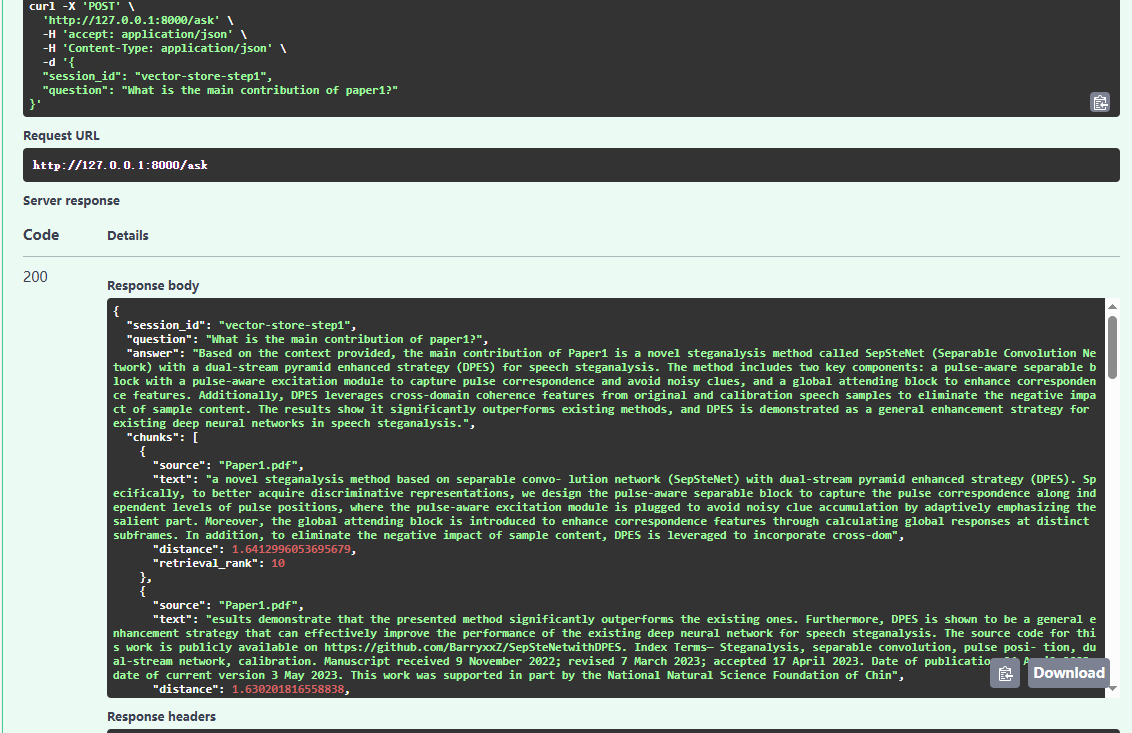
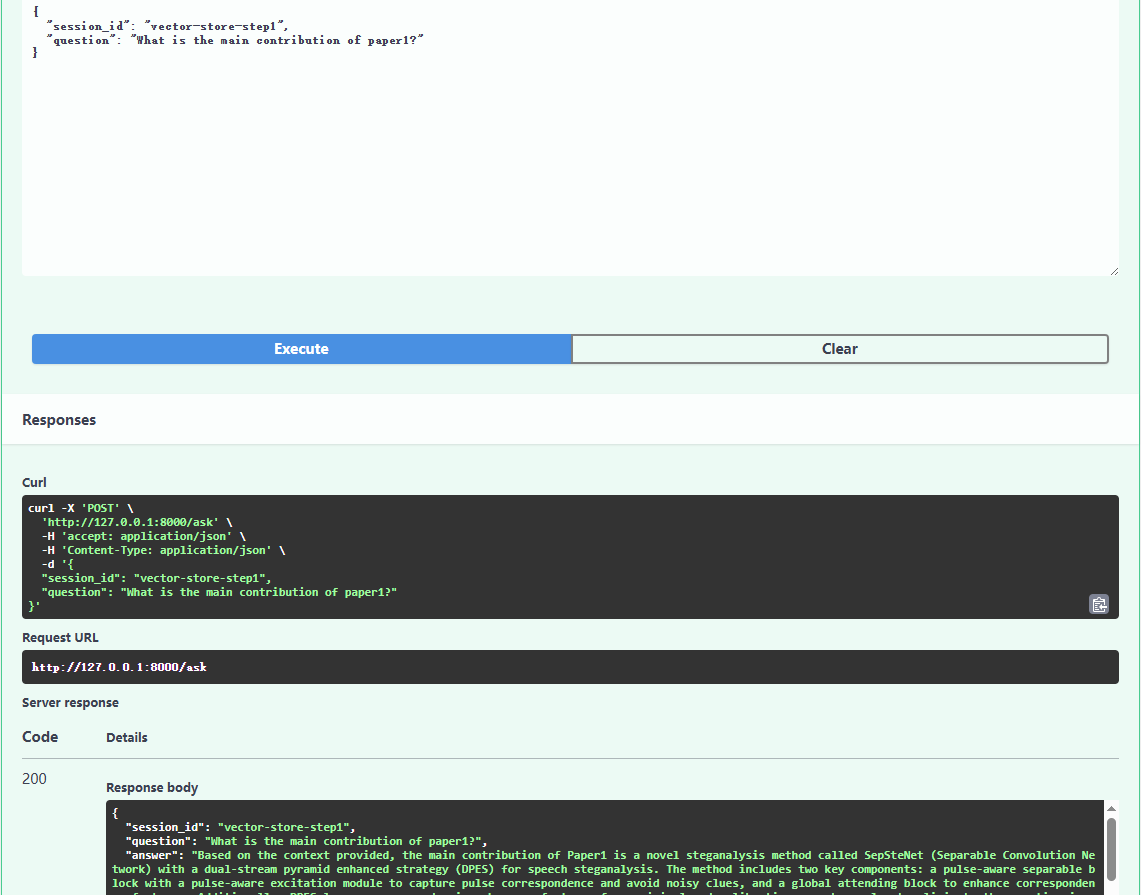
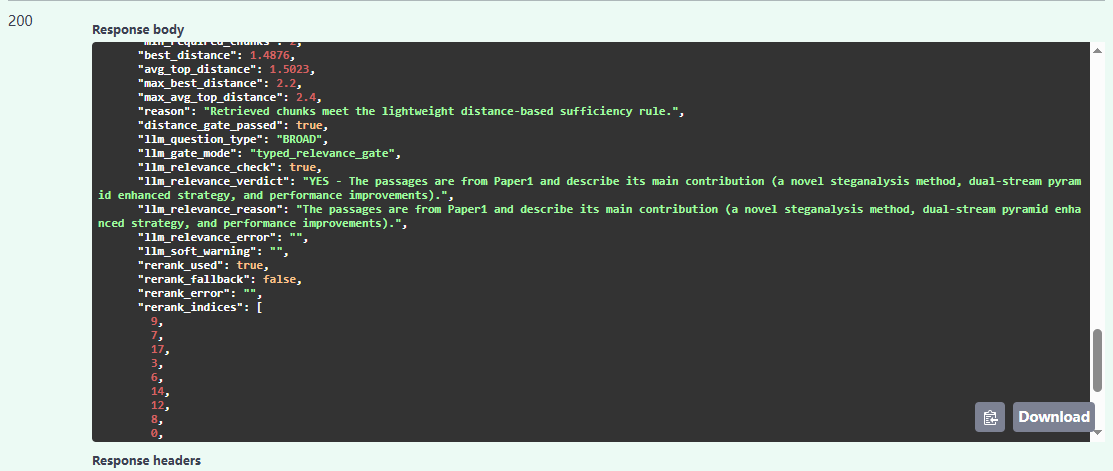
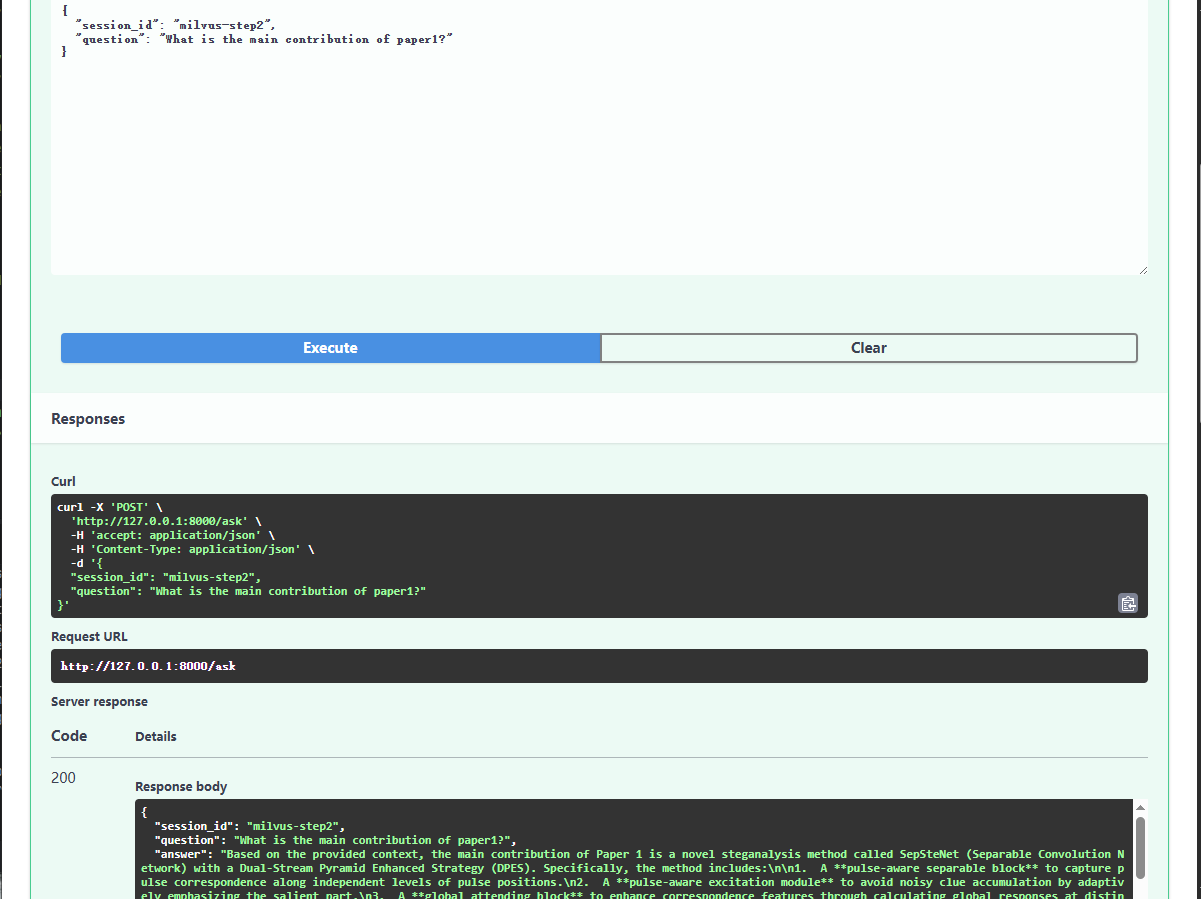
基于Milvus的检索结果:
如果这篇文章对你有帮助,可以点个赞~
完整代码地址:https://github.com/1186141415/Paper-RAG-Agent-with-LangGraph