前言
在刷大厂面试题时,经常看到"为什么数据库设计要尽量避免使用NULL?"
很多小伙伴答不上来,或者只回答"因为NULL查询慢"。
其实,MySQL中NULL的坑远比表面复杂。
今天就跟大家专门聊聊MySQL中的NULL值问题,希望对你会有所帮助。
更多项目实战在我的技术网站:susan.net.cn/project
1.NULL的含义
NULL不是空字符串,也不是0。
在MySQL中,NULL表示**"未知的值"**,它是一种状态,而不是一个具体的值。
它与空字符串 ''、数字 0 完全不同。
| 值 | 含义 | 是否占用存储空间 |
|---|---|---|
NULL |
未知、不存在 | 是(需额外标志位) |
'' |
空字符串,已知为空 | 是 |
0 |
数字零,已知为零 | 是 |
最大的区别在于:任何值与NULL进行运算的结果都是NULL,比较结果既不是TRUE也不是FALSE,而是NULL。
sql
SELECT NULL = 0; -- 结果 NULL
SELECT NULL = ''; -- 结果 NULL
SELECT NULL != NULL; -- 结果 NULL这就引出了MySQL特有的三值逻辑。
2. 三值逻辑
在普通布尔逻辑中,只有 TRUE 和 FALSE 两种结果。
而MySQL引入NULL后,出现了第三种结果:UNKNOWN。
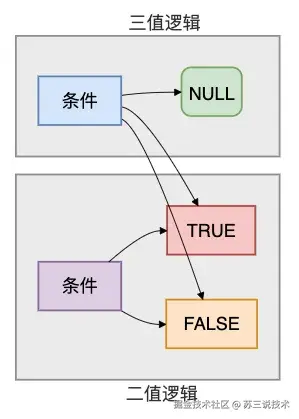
当查询条件中出现NULL时,WHERE子句只返回条件为 TRUE 的行,而 FALSE 和 UNKNOWN 都会被过滤掉。
这就是为什么NOT IN子查询中一旦有NULL,结果集就会变为空的原因!
示例:NOT IN 陷阱
sql
-- 表结构
CREATE TABLE users (id INT, name VARCHAR(20));
INSERT INTO users VALUES (1, 'Alice'), (2, 'Bob'), (3, NULL); -- 注意有个NULL
-- 查询ID不在另一个子查询中的用户
SELECT * FROM users WHERE id NOT IN (SELECT id FROM users WHERE name = 'Alice');
-- 预期结果:只有Bob,但实际返回空!原因分析:子查询(SELECT id FROM users WHERE name = 'Alice')返回1,没问题。但NOT IN (1)会与表中每一行比较,当遇到NULL时,NOT IN 的逻辑变成 id NOT IN (1)。
由于子查询中一旦包含NULL,整个NOT IN条件会变成UNKNOWN(三值逻辑),最终导致所有行被过滤。
解决方案 :子查询中使用WHERE column IS NOT NULL排除NULL,或改用NOT EXISTS。
sql
SELECT * FROM users u
WHERE NOT EXISTS (SELECT 1 FROM users WHERE id = u.id AND name = 'Alice');3.NULL如何让索引失效?
3.1 索引不存储NULL值
在InnoDB的B+Tree索引中,NULL值不会被存储在二级索引中(唯一索引除外)。
这意味着,使用IS NULL查询时,MySQL无法利用二级索引快速定位,只能扫描全表。
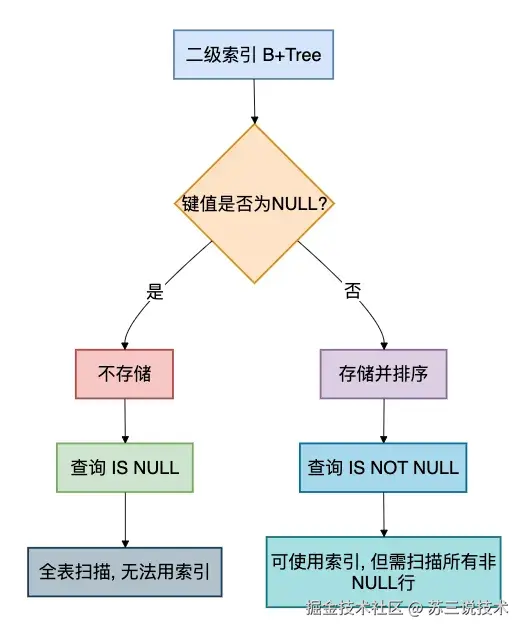
实际测试 :一张100万行的表,status列有90%是NULL,10%非NULL。
查询WHERE status = 'ACTIVE'可以用到索引(因为非NULL部分值很多)。
但查询WHERE status IS NULL会走全表扫描,性能极差。
3.2 复合索引中的NULL问题
复合索引(a, b)中,如果a为NULL,则这一行不会出现在索引中。
因此,WHERE a = 1 AND b IS NULL可能只能用到索引的前半部分,但无法通过索引过滤b的NULL。
4.聚合函数的"隐形陷阱"
sql
-- 表数据: amount 列有 (100, 200, NULL, 400)
SELECT AVG(amount) FROM orders; -- 结果 (100+200+400)/3 = 233.33,不是 (700/4)=175
SELECT COUNT(amount) FROM orders; -- 结果 3,NULL被忽略
SELECT SUM(amount) FROM orders; -- 结果 700,忽略NULL如果你期望COUNT(*)统计所有行数,而COUNT(列名)统计非NULL行数,这可能导致报表数据错误。
当你在应用中用查询结果做除法时,如果分母是COUNT(列)且忽略了NULL,就会得到错误平均值。
5.存储空间与性能开销
在InnoDB的行格式中,每一行有一个NULL标志位,用于标记哪些列为NULL。每列占用1位(8列用一个字节)。
虽然额外空间不大,但当表有几十个NULL列且数据量巨大时,浪费依然可观。
更重要的是,NULL值会阻止存储引擎的某些优化,例如列压缩、页内预处理等。
对于频繁更新的表,NULL值可能导致行溢出页,降低缓存命中率。
6.应用层的"空指针噩梦"
在Java中,从ResultSet获取NULL列时:
java
Long amount = rs.getLong("amount");
if (rs.wasNull()) {
// 需要特殊处理
}如果不检查wasNull(),getLong()返回0,但业务上0可能代表有效值,导致逻辑错误。
此外,将NULL值映射到POJO的Long属性时,需要做好判空,否则容易产生NullPointerException。
7.解决方案
绝大多数场景都可以用NOT NULL约束加合理的默认值来避免NULL:
| 原设计 | 优化方案 |
|---|---|
age INT NULL |
age INT NOT NULL DEFAULT 0(0表示未知,业务上约定) |
name VARCHAR(20) NULL |
name VARCHAR(20) NOT NULL DEFAULT '' |
status TINYINT NULL |
status TINYINT NOT NULL DEFAULT 0,用0代表默认状态 |
price DECIMAL(10,2) NULL |
price DECIMAL(10,2) NOT NULL DEFAULT 0.00 |
注意:默认值要符合业务语义。比如年龄用 -1 表示未知可能比 0 更合理,因为0岁是真实存在。
八、什么时候可以适当使用NULL?
虽然大厂极力避免NULL,但有些场景NULL自然就具有语义:
- 可选外键 :比如订单表中的
coupon_id(优惠券ID),如果没有使用优惠券,NULL恰好表达了"无关联"。 - 未知信息 :用户注册时未填写的中间名字段,
middle_name NULL比空字符串更能表达"未提供"。 - 数据缺失 :ETL中某些字段确实不存在。 在这些场景中,使用NULL比魔数(如 -1)更清晰,但查询时要注意
IS NULL的性能,可以考虑加WHERE column IS NULL的索引过滤。
更多项目实战在我的技术网站:susan.net.cn/project
总结
大厂不推荐使用NULL,核心原因可归纳为五点:
| 原因 | 解释 |
|---|---|
| 三值逻辑陷阱 | 导致查询结果异常,尤其NOT IN子查询 |
| 索引性能差 | IS NULL无法走二级索引,必须全表扫描 |
| 聚合函数忽略NULL | AVG、COUNT等可能造成统计错误 |
| 额外存储开销 | 每行有NULL标志位,且阻止压缩优化 |
| 应用层复杂性 | Java中需要处理wasNull(),易引发空指针 |
绝大多数业务场景都能通过NOT NULL + 默认值规避NULL。
我们设计表时,优先思考"这个字段是否可以没有默认值?
如果答案是否定的,就给一个合理的默认值。
只有当下游逻辑明确需要"未知"语义时,再谨慎使用NULL。
你在实际项目中遇到过NULL引发的生产事故吗?
欢迎评论区分享经历,一起避坑~