第一次让"未来预测"真正向"控制优化"靠拢
------VLA 体系下 VAM 再升级
在具身智能迈向通用化的进程中,VLA系统已然成为核心技术路线。传统机器人策略局限于「当前观测+语言指令→直接输出动作」的单向映射,面对长时序、高精度操控任务时频频失效。
研究者逐渐达成共识:机器人不仅要理解当下,更要精准预测未来。
由此,Video Action Model(视频动作模型,VAM)应运而生。
它先预测未来视觉状态/潜在表示,再基于「未来信息」生成动作,为机器人赋予「世界模型」级的前瞻推理能力。
但行业长期存在核心痛点:模型能生成逼真的未来画面,却未必生成对操控有用的未来表示。
近期,OpenHelix Robotics、浙江大学、西湖大学等团队联合提出
VAMPO彻底打破「生成逼真度」与「操控精准度」的目标错位,让机器人的「未来预测」真正服务于动作决策。

核心痛点:视频动作模型的"生成目标"与"控制目标"长期错位
当前主流视频预测模型,尤其是扩散模型,通常采用 ELBO 或 MSE 形式的似然代理目标进行训练。
这类目标的作用是鼓励模型逼近真实数据分布,生成在整体上真实、连贯、符合统计规律的未来结果。
但机器人操作真正需要的,不是一个"整体看起来像"的未来,而是一个在关键状态变量上足够精确的未来。
简单来说:
生成模型:只要「看起来像」就行;而机器人控制:必须「用起来准」才行。
这种目标错配,是视频动作模型落地机器人操控的最大瓶颈。VAMPO的核心意义 ,就是把模型优化目标从"拟合数据分布"转向"优化操控关键视觉动态"。
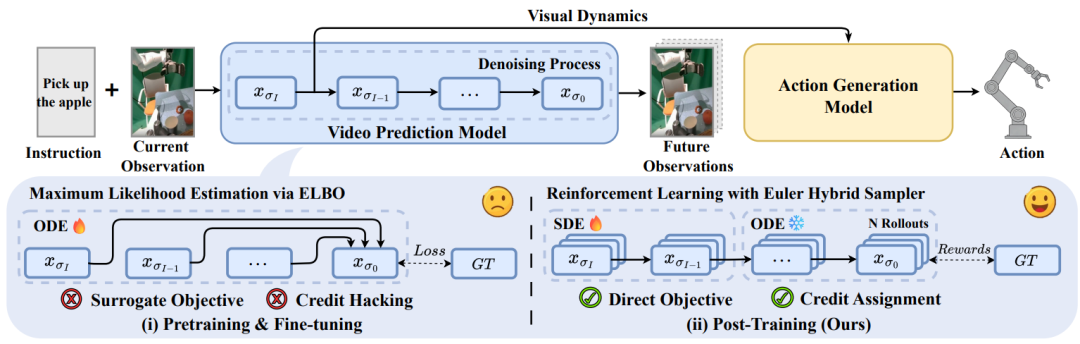
▲图| VAMPO 问题背景与整体动机示意图©️【深蓝具身智能】编译

技术破局:策略优化重构范式,精准适配机器人操控
针对上述问题,VAMPO将扩散模型的"多步去噪过程建模为序贯决策过程",把每一步去噪视为一次「动作」,通过专家视觉动态奖励直接优化模型,无需修改原有架构,仅通过后训练即可完成升级。
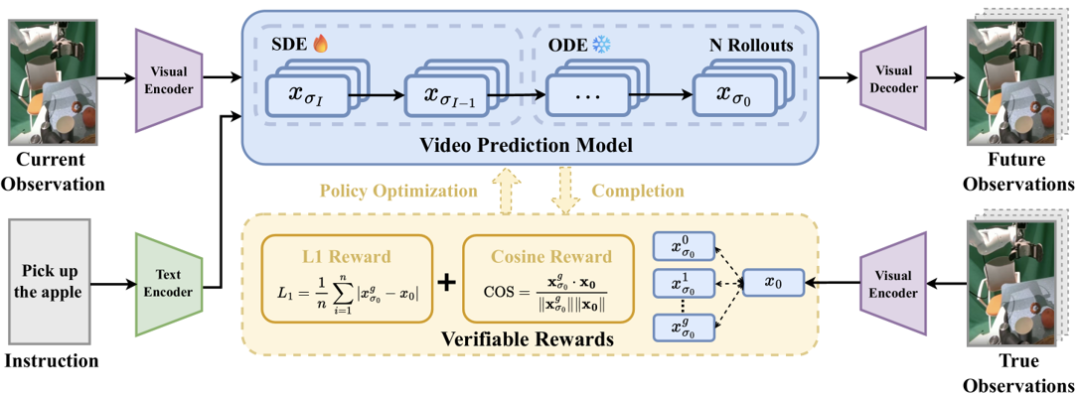
▲图 | VAMPO 方法整体框架与后训练流程©️【深蓝具身智能】编译
在方法设计上,VAMPO 主要包含两个关键点:
- 一是引入欧拉混合采样器:解决信用分配难题
为避免奖励投机(Reward Hacking)与长程信用分配失效,VAMPO首创
欧拉混合采样器(Euler Hybrid Sampler):
(1)仅在**第一步去噪**注入SDE随机噪声,保留探索空间;
(2)后续步骤采用ODE确定性更新,保证时序连贯性;
(3)聚焦优化与动作强相关的早期视觉表示,训练更稳定。
因此,VAMPO 通过限制随机性只作用于与下游动作最相关的时间步,既缓解了信用分配问题,也确保优化聚焦在 Action-relevant 的视觉表示上。
- 二是采用 GRPO +潜空间中的可验证奖励:精准对齐专家动态
采用GRPO(分组相对策略优化)算法,搭配潜空间一致性奖励(L1距离+余弦相似度):
(1)同一条件下生成多组候选轨迹,通过相对比较捕捉细微优劣
(2)无需额外奖励模型,直接用专家潜空间表示构造奖励
(3)摒弃像素级冗余细节,聚焦操控核心语义,对齐更精准

仿真+真机双验证
VAMPO通过仿真基准(CALVIN/L-CALVIN)与真实机器人平台双重验证,证实"优化视觉动态"可直接转化为"操控性能提升"。
视觉动态优化→动作生成的正向传导
实验设置三组对照:基础策略、仅优化VPM+冻结AGM、优化VPM+重训AGM。
-
冻结动作模型,仅优化视频预测模块,性能即可稳定提升
-
联合优化后,任务连续完成率、平均轨迹长度大幅跃升
-
有效秩(ER)、有效秩比(ERR)指标证明:
视觉-动作耦合度显著增强,视觉信息被更高效地转化为动作指令

▲图| VAMPO优化效果实验结果©️【深蓝具身智能】编译
仿真基准:长时序任务优势拉满
在CALVIN ABC→D泛化基准与L-CALVIN长时序(10步)任务中:
-
全面超越VLM-based、VPM-based各类SOTA方法
-
任务序列越长,提升幅度越显著,完美解决误差累积问题
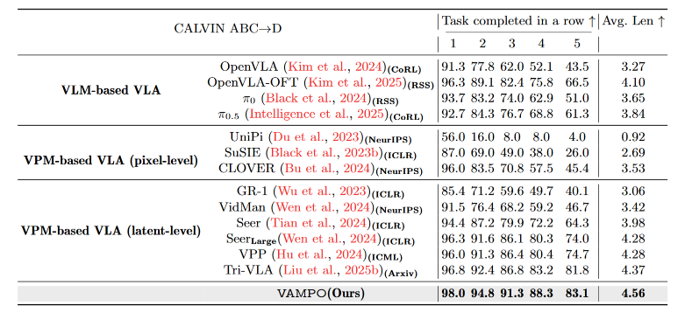
▲图 | VAMPO在CALVIN基准上的实验结果©️【深蓝具身智能】编译
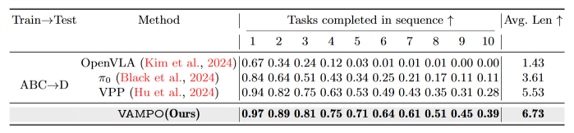
▲图 | VAMPO在L-CALVIN长时序任务上的实验结果©️【深蓝具身智能】编译
真机实验:复杂真实场景稳定增效
在Agibot Genie 01、Flexiv、VidowX等商用机器人平台实测三大任务:
-
杂乱环境目标抓取(摘苹果)
-
单臂精准放置(碗入盒)
-
双臂协同操控(双瓶抓取放置)
真机场景感知噪声大、环境扰动强,VAMPO仍实现稳定性能增益。
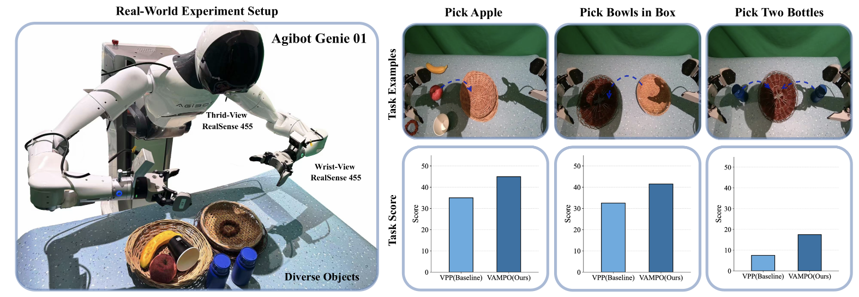
▲图 | VAMPO在真实机器人平台上的实验表现©️【深蓝具身智能】编译

消融实验
团队基于 CALVIN ABC→D 基准完成严格对照实验,验证 VAMPO 核心设计的必要性和奖励的选择,全面证实方法鲁棒性与普适性:
后训练步数优化
-
400 步即可显著超越基线,1400 步达到峰值性能
-
强化学习训练存在小幅波动,但全程优于基础策略
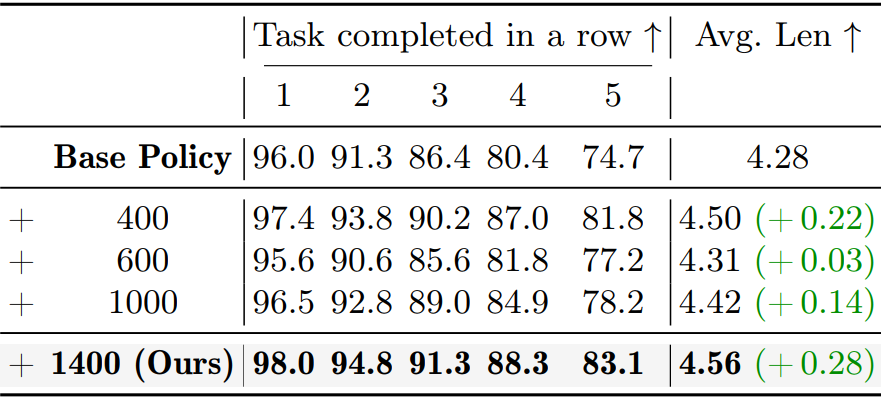
▲图 | 消融实验-后训练步数优化©️【深蓝具身智能】编译
优化算法对比
-
GRPO 完胜 DDPO:梯度更新更稳定,能充分利用候选轨迹多样性
-
对奖励噪声鲁棒性更强,长时序任务优化效果更突出
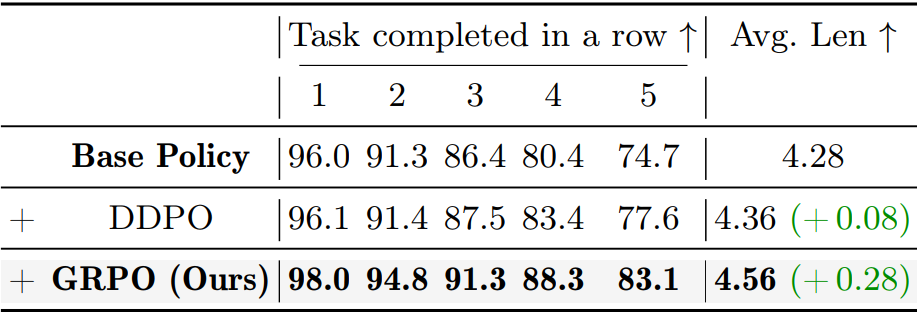
▲图 | 消融实验-优化算法对比©️【深蓝具身智能】编译
混合去噪策略验证
-
仅 1 步 SDE 随机化 远优于 5 步 SDE 随机化
-
多步随机化易引发奖励投机,1 步设计精准聚焦动作相关动态
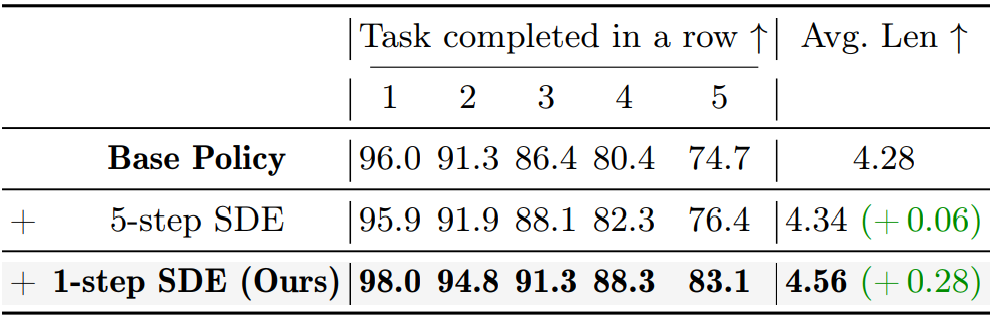
▲图 | 消融实验-混合去噪策略验证©️【深蓝具身智能】编译
奖励类型选择
-
潜空间奖励远优于像素级奖励
-
像素一致性≠操控动态精准,潜空间更贴合动作生成需求
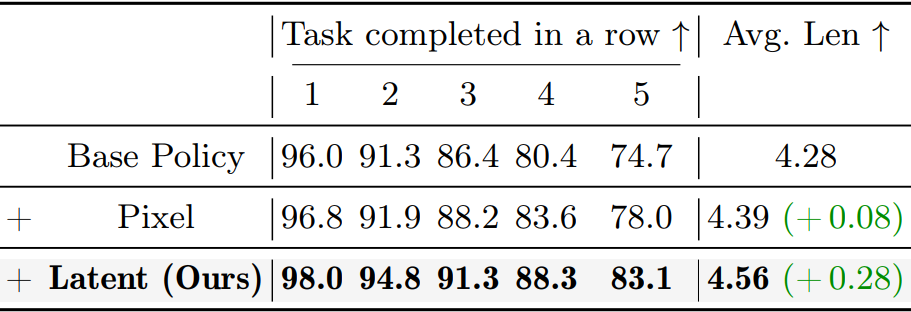
▲图 | 消融实验-奖励类型选择©️【深蓝具身智能】编译
奖励权重敏感性分析
-
单一奖励即可大幅增效,双奖励组合效果优于单一奖励
-
权重配比鲁棒性强,1:1 均衡设置为最优稳定参数
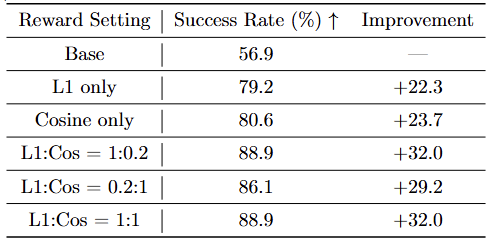
▲图 | 消融实验-奖励权重敏感性分析©️【深蓝具身智能】编译
替代奖励形式探索
潜空间内测试了 L1、L2、余弦相似度、潜空间光流等多种单奖励形式,所有奖励均能带来稳定性能提升,优化视频预测器的核心策略,远比奖励的具体代数形式更关键。
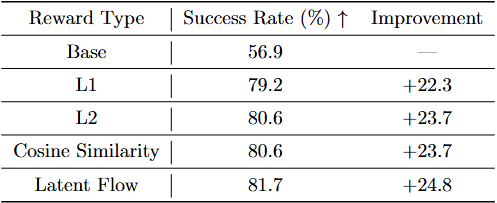
▲图 | 消融实验-替代奖励形式探索©️【深蓝具身智能】编译

核心价值:重新定义视频动作模型的机器人应用范式
VAMPO的价值,不止于刷新CALVIN基准,更"颠覆"了视频动作模型的训练逻辑:
目标对齐:从"看着像"转向"做得准",解决行业核心矛盾
轻量落地:无架构侵入式后训练,兼容现有VAM系统,低成本升级
通用适配:仿真、真机迁移,长时序、高精度任务均适用
视频动作模型的瓶颈,未必在于模型还不够大、结构还不够复杂,而可能在于训练目标根本没有对齐机器 人真正需要的视觉动态。
如果说视频动作模型让机器人开始具备"想象未来"的能力,那么 VAMPO 则进一步让机器人开始学会:想象一个更适合行动的未来。
对于正在快速演进的具身智能而言,这可能是一个非常重要的信号------
未来的世界模型,不只是要生成逼真的世界,更要生成可用于决策的世界。
论文题目:VAMPO: Policy Optimization for Improving Visual Dynamics in Video Action Models
论文地址:https://arxiv.org/pdf/2603.19370
项目地址:https://vampo-robot.github.io/VAMPO