目录
[1. 二叉搜索树(及变种:AVL、红黑树)](#1. 二叉搜索树(及变种:AVL、红黑树))
[2. 哈希表](#2. 哈希表)
[3. B树(N叉搜索树)](#3. B树(N叉搜索树))
[4. B+树(索引的核心数据结构)](#4. B+树(索引的核心数据结构))
[1. 主键索引](#1. 主键索引)
[2. 普通索引](#2. 普通索引)
[3. 唯一索引](#3. 唯一索引)
[4. 全文索引](#4. 全文索引)
[5. 聚集索引 vs 非聚集索引(InnoDB引擎特性)](#5. 聚集索引 vs 非聚集索引(InnoDB引擎特性))
[1. 创建索引的方式(SQL示例)](#1. 创建索引的方式(SQL示例))
[2. 注意:大表加索引的风险](#2. 注意:大表加索引的风险)
[3. 删除索引](#3. 删除索引)
作为一名刚入行的后端开发,最近在啃MySQL索引这块的硬骨头,结合学习时的笔记,把++索引的概念、数据结构选型、B+树原理、索引类型与操作++等核心点整理成这篇博客,方便自己回顾~
一、索引是什么?为什么需要它?(职场视角:性能优化刚需)
索引相当于书的目录 ,核心作用是加快查询速度。但索引不是"免费午餐":
-
代价1:消耗额外存储空间;
-
代价2 :可能拖慢增删改速度(删除/修改常搭配
where条件,若where走索引,索引维护有开销)。
职场中通常索引利大于弊 :存储成本(硬盘便宜)不是核心矛盾;实际开发里读频率远高于写频率(比如"作业表"场景:同学查看作业是读操作,写入记录是写操作,读远多于写)。
二、索引的候选数据结构:为什么最终选B+树?
索引需要高效的数据结构,我们逐一分析常见结构(职场面试高频考点!):
1. 二叉搜索树(及变种:AVL、红黑树)
-
二叉搜索树:查找时间复杂度平均O(logN) ,但最坏O(N)(退化成链表)。
-
AVL树:要求++严格平衡++(任何节点左右子树高度差≤1),查询快,但插入/删除需频繁调整树结构,开销大。
-
红黑树:做了权衡,++不要求严格平衡++,把查询稍慢一点(几乎感知不到),换取插入/删除效率提升。
但二叉搜索树(包括AVL、红黑树)作为索引的问题:++树高过高++(元素多时),IO访问次数多(数据库从硬盘读数据,IO是瓶颈)。
2. 哈希表
哈希表查找时间复杂度O(1),但缺陷明显:
-
仅支持相等条件查询 (如
=),不支持范围查询(< >)、模糊匹配; -
hash函数将key转为数组下标,无法利用数据的"有序性"。
3. B树(N叉搜索树)
B树是多叉搜索树,改进了二叉树的树高问题:
-
每个节点存
N个值,划分N+1个区间; -
一次IO操作可读取一个节点,拿到
N个key比较,减少IO次数。
但B树仍有不足,于是有了B+树(索引的专属数据结构)。
4. B+树(索引的核心数据结构)
B+树是B树的改进版,也是N叉搜索树,核心特点(职场面试必背!):
-
叶子节点是数据全集 ,并通过双向链表串起来(方便范围查询);
-
非叶子节点只存索引key 和子节点位置,叶子节点存完整数据行;
-
所有数据都在叶子节点,查询必须到叶子节点,中间过程开销稳定(查询开销稳定);
-
N叉树,树高更低(和红黑树比较,IO次数更少)。
++B+树相比B树的优势:++
-
叶子节点数据全集+链表连接,范围查询极方便;
-
非叶子节点只存key,空间更小,更适合内存缓存;
-
查询必须到叶子,开销稳定;
-
树高更低,IO次数更少。
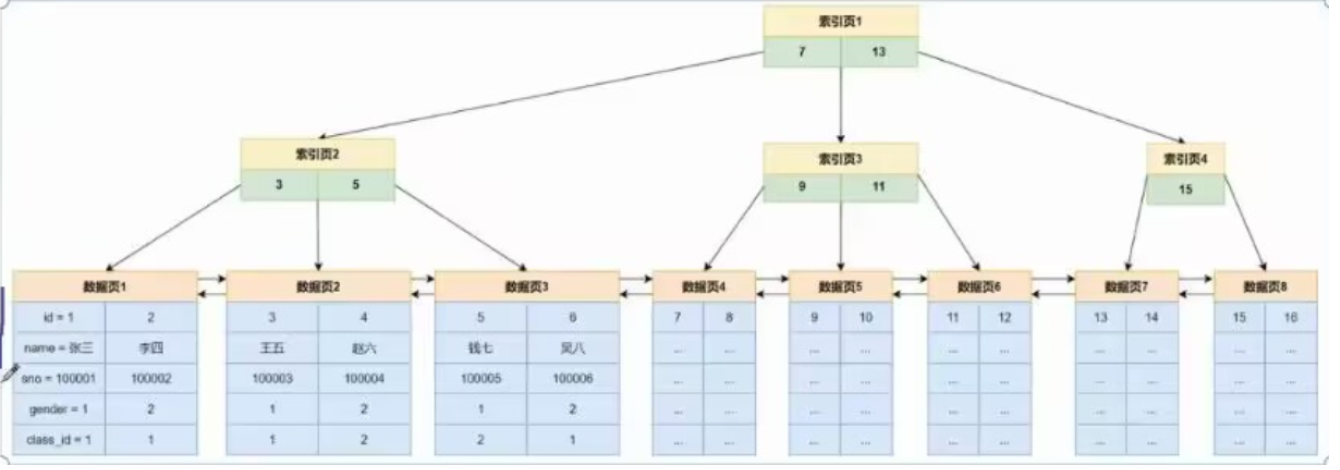
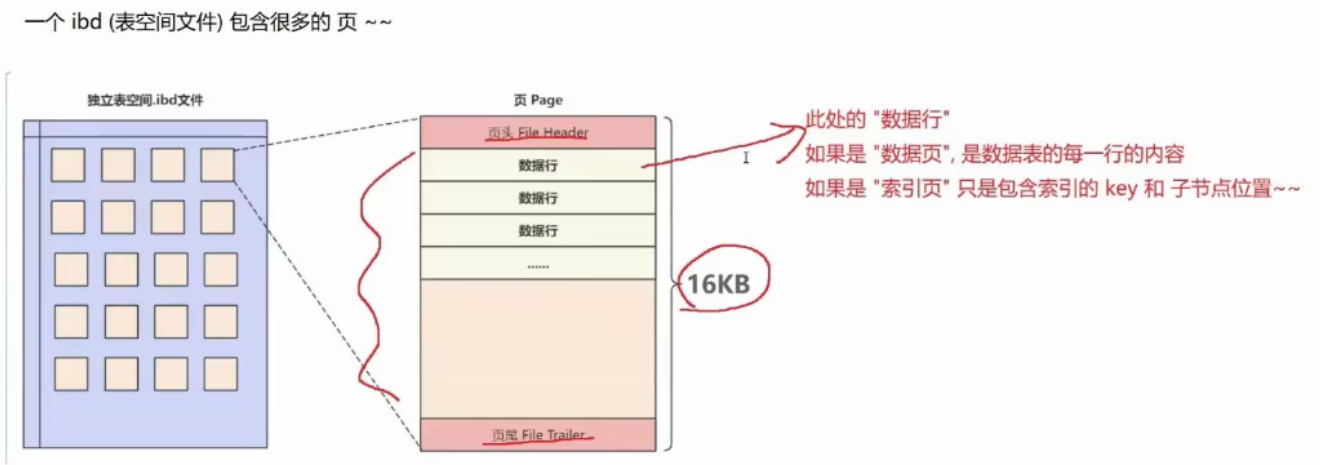
三、MySQL的"页"机制:B+树的物理载体
MySQL中,"页(page)"是B+树上的节点 ,也是数据库读写硬盘的基本单位。默认大小为16KB,可通过命令查看:
SHOW VARIABLES LIKE 'innodb_page_size';一个.ibd(表空间文件)包含很多页:
-
索引页(非叶子节点):存key和子节点位置;
-
数据页(叶子节点):存具体数据行。
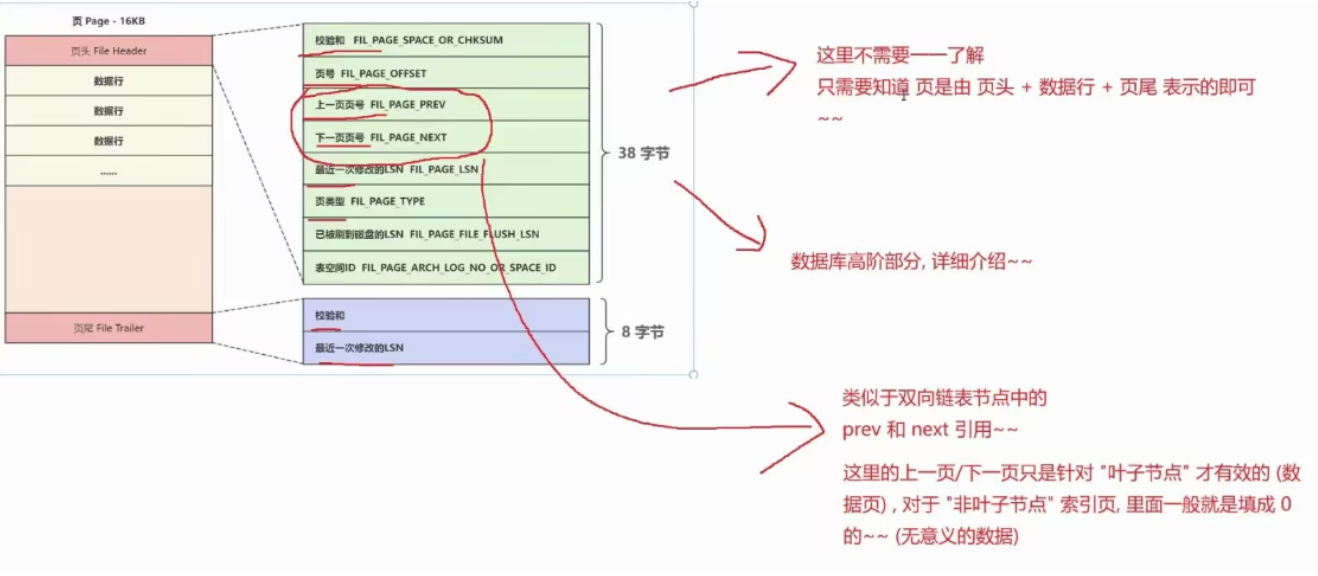
页的结构设计利用了++局部性原理++ (程序大概率会连续访问附近数据),数据库每次从硬盘读数据时,++以页为单位读取++,减少IO次数。
四、索引的类型:职场常用分类(面试高频)
1. 主键索引
创建主键时,数据库自动建立的索引。如果表没有主键,数据库会自动创建"隐藏列"作为主键,围绕隐藏列设索引。
2. 普通索引
针对普通列,手动创建的索引。一个表可以有多个普通索引(类似字典里的"拼音目录""部首目录")。
3. 唯一索引
列上设unique时,自动创建唯一索引。与普通索引类似,但不允许重复值,内部结构和主键有一定差别。
4. 全文索引
针对字符串类型列,支持模糊查询(如文章关键词搜索)。
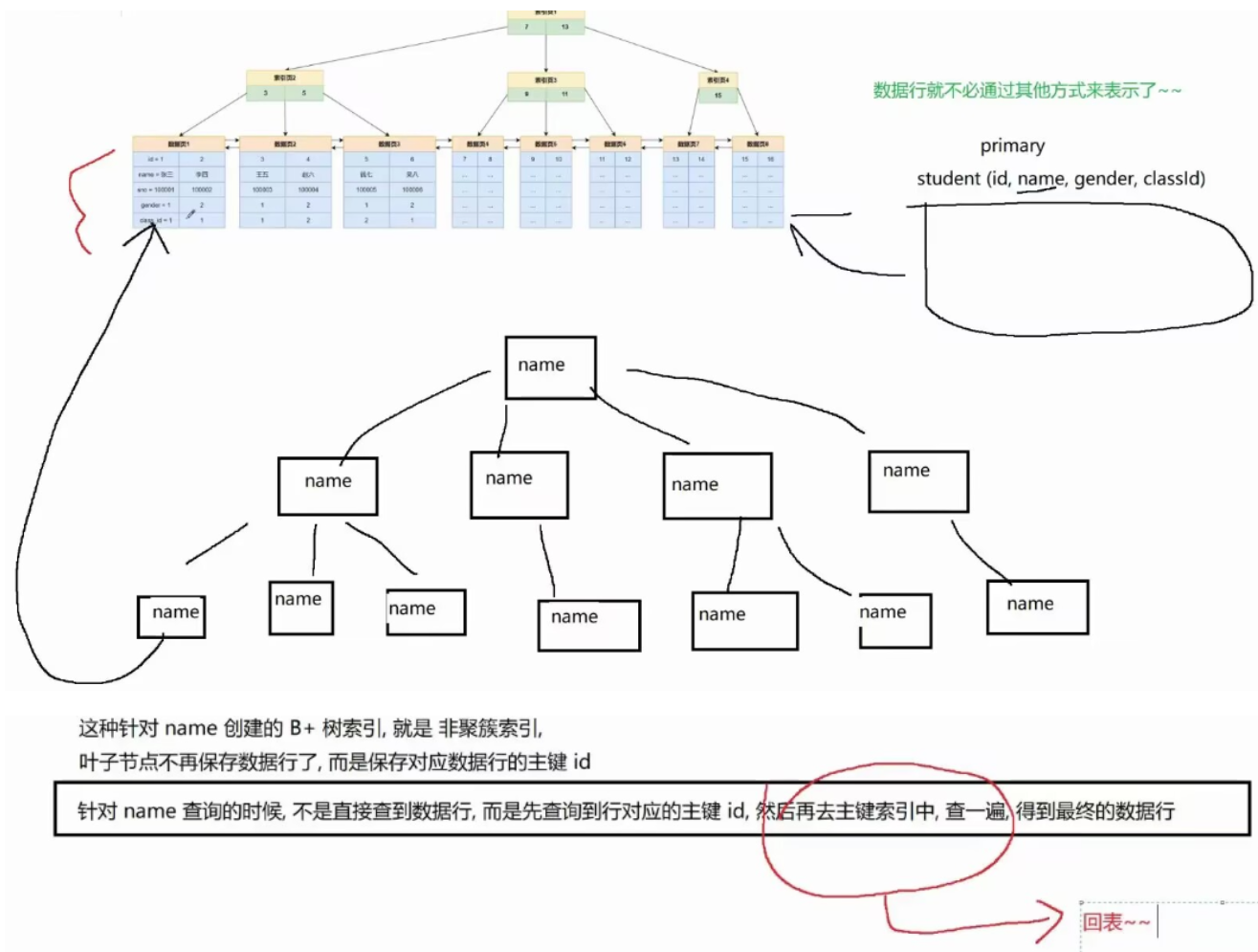
5. 聚集索引 vs 非聚集索引(InnoDB引擎特性)
-
聚集索引:主键索引就是聚集索引,叶子节点保存++数据行++,整个数据表通过聚集索引组织;
-
非聚集索引:叶子节点不保存数据行,而是保存对应数据行的++主键id++ ,再回表查主键索引得到数据(比如
name列建非聚集索引,查询时需先查name的索引,拿到主键,再查主键索引)。
五、索引的操作与注意事项(职场实战)
1. 创建索引的方式(SQL示例)
sql
-- 方式一:创建表时指定索引列
create table t_test_index (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10),
index(sno) -- 普通索引
);
-- 方式二:修改表添加索引
alter table t_test_index add index(sno);
-- 方式三:单独创建索引并指定名称
create index index_name on t_test_index(sno);2. 注意:大表加索引的风险
如果表已有千万级数据,再创建索引是++危险操作++(索引操作会在硬盘构建新的B+树,耗时久)。设计时应在建表初期规划好索引,生产环境加索引需谨慎(如停机维护、分批处理)。
3. 删除索引
数据库虽提供alter table 表名 drop index 索引名;,但一般很少手动删除(索引利大于弊,除非冗余或无效索引)。
4.展示索引
sql
show index from 表名;六、面试进阶:索引与数据库层级(从基础到高阶)
-
数据库基础:SQL使用、Java操作数据库;
-
数据库进阶:索引设计、高可用、分布式方案;
-
数据库高阶:InnoDB底层结构(如B+树)、深入面试题(如"页结构""聚簇/非聚簇索引区别")。
总结(新人成长感悟)
索引是MySQL性能优化的核心,理解其++数据结构(B+树)、物理载体(页)、类型与操作++,是后端开发的必备技能。职场中遇到"查询慢""增删改"等问题,优先考虑索引是否合理;面试时,索引的底层原理(B+树、页、聚簇索引)也是高频考点。