摘要
我们首先提出了一种新颖的 Transformer 蒸馏方法,该方法专为基于 Transformer 模型的知識蒸馏(Knowledge Distillation, KD)而设计。借助这一新的 KD 方法,大型"教师"BERT 中编码的大量知识可以有效地迁移到小型"学生"TinyBERT 中。随后,我们引入了一种新的两阶段学习框架,用于 TinyBERT,该框架在预训练阶段和特定任务学习阶段均执行 Transformer 蒸馏。该框架确保了 TinyBERT 能够捕获 BERT 中通用领域知识以及特定任务知识。
introduce
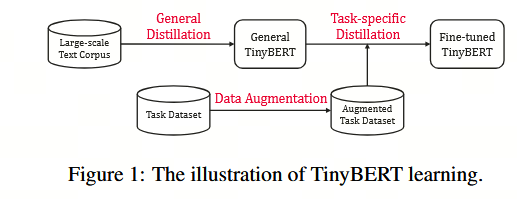
为了构建具有竞争力的小型 BERT(TinyBERT),我们首先提出了一种新的 Transformer 蒸馏方法,以蒸馏嵌入在教师 BERT 中的知识。具体而言,我们设计了三种类型的损失函数,以拟合来自 BERT 不同层的多种表示:1)嵌入层的输出;2)由 Transformer 层派生的隐藏状态和注意力矩阵;3)由预测层输出的 logit 值。基于注意力的拟合方法受到最新研究(Clark 等,2019)的启发,该研究发现 BERT 所学得的注意力权重能够捕捉大量的语言学知识,因此有助于将语言学知识从教师 BERT 有效地迁移至学生模型 TinyBERT。随后,我们提出了一种新颖的两阶段学习框架,包括通用蒸馏和任务特定蒸馏,如图 1 所示。在通用蒸馏阶段,未经微调的原始 BERT 作为教师模型。学生模型 TinyBERT 通过在通用领域语料库上应用所提出的 Transformer 蒸馏方法,来模仿教师模型的行为。此后,我们获得了一个通用 TinyBERT,并将其用作进一步蒸馏任务中 student 模型的初始化。在任务特定蒸馏阶段,我们首先进行数据增强,然后使用微调后的 BERT 作为教师模型,在增强后的数据集上进行蒸馏。需要指出的是,这两个阶段对于提升 TinyBERT 的性能和泛化能力均至关重要。
本项工作的主要贡献如下:1)我们提出了一种新的 Transformer 蒸馏方法,旨在促使教师 BERT 中编码的语言知识能够充分迁移至 TinyBERT;2)我们提出了一种新颖的两阶段学习框架,在预训练和微调两个阶段均执行所提出的 Transformer 蒸馏,从而确保 TinyBERT 能够同时吸收教师 BERT 的通用领域知识与特定任务知识。
2 Preliminaries
知识蒸馏(KD)旨在将大型教师网络 T 的知识迁移至小型学生网络 S。学生网络通过模仿教师网络的行为进行训练。令 fTf^TfT 和 fSf^SfS 分别表示教师网络和学生网络的行为函数。行为函数的目标是将网络输入转换为具有信息性的表示,其可以定义为网络中任意层的输出。在 Transformer 蒸馏的语境下,MHA 层或 FFN 层的输出,或某些中间表示(例如注意力矩阵 A)均可用作行为函数。形式上,知识蒸馏可建模为最小化以下目标函数:
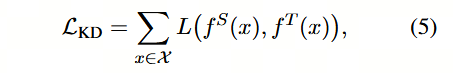
3 Method
3.1 Transformer Distillation
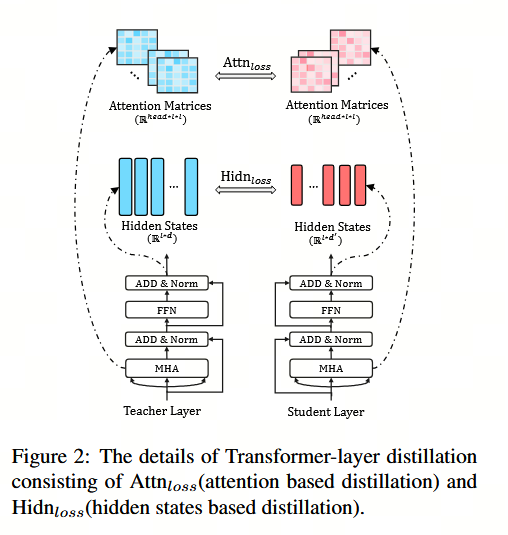
(1)Transformer 层蒸馏包括基于注意力机制的蒸馏和基于隐藏状态的蒸馏,如图 2 所示。具体而言,学生模型学习拟合教师网络中的多头注意力权重矩阵, 在本工作中,我们使用(未归一化的 )注意力矩阵 AiA_iAi 作为拟合目标,而非其 softmax 输出 softmax(Ai)\text{softmax}(A_i)softmax(Ai),因为我们的实验表明,前者具有更快的收敛速度和更优的性能。
(2)Embedding-layer Distillation
在本文中,它们与隐藏状态矩阵具有相同的形状。矩阵 W_e 是一种线性变换,其作用类似于 W_h。
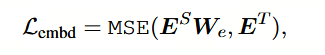
(3)输出蒸馏
预测层蒸馏。除了模仿中间层的行为之外,我们还采用知识蒸馏的方法,使学生模型拟合教师模型的预测结果,如 Hinton 等人(2015)所述。具体而言,我们通过惩罚学生网络 logits 与教师网络 logits 之间的CE损失来实现这一目标。
3.2 TinyBERT Learning
General Distillation-->然而,由于隐藏层/嵌入层大小以及网络层数的显著减少,通用 TinyBERT 的整体性能通常劣于 BERT。
Task-specific Distillation. --> 为此,我们提出通过任务特定蒸馏来生成具有竞争力的微调版 TinyBERT。在任务特定蒸馏中,我们在增强的任务特定数据集上重新执行所提出的 Transformer 蒸馏过程。具体而言,微调后的 BERT 作为教师模型,并提出一种数据增强方法以扩充任务特定的训练集。通过利用更多与任务相关的样本进行训练,学生模型的泛化能力可得到进一步提升。
Data Augmentation.--> 我们将预训练的语言模型 BERT 与 GloVe (Pennington 等, 2014) 词嵌入相结合,以进行用于数据增强目的的词级替换。
具体而言,我们使用语言模型为单字词预测替换词(Wu et al., 2019),并利用词嵌入为多字词检索最相似的词语作为替换词3。我们定义了一些超参数,以控制句子的替换比例以及增强数据集的大小。数据增强过程的更多细节如算法1所示。在所有实验中,我们将 pt 设置为 0.4,Na 设置为 20,K 设置为 15。
上述两个学习阶段相互补充:通用蒸馏为特定任务蒸馏提供了良好的初始化,而基于增强数据的特定任务蒸馏则通过聚焦于学习任务特定知识,进一步提升了 TinyBERT 的性能。尽管模型规模显著减小,但通过在预训练和微调阶段结合数据增强以及提出的 Transformer 蒸馏方法,TinyBERT 在多种自然语言处理任务中均能取得具有竞争力的性能。
6 结论与未来工作
在本文中,我们提出了一种基于 Transformer 的蒸馏新方法,并进一步为 TinyBERT 设计了一个两阶段框架。大量实验表明,TinyBERT 在取得具有竞争力的性能的同时,显著缩减了 BERTBASE 的模型大小与推理时间,为在边缘设备上部署基于 BERT 的自然语言处理模型提供了有效途径。在未来的工作中,我们将研究如何更有效地将更宽更深的教师模型(例如 BERTLARGE)中的知识迁移到学生模型 TinyBERT 中。此外,将知识蒸馏与量化/剪枝相结合,将是进一步压缩预训练语言模型的另一个有前景的方向。