基于
llama_index.core.indices源码深度剖析,覆盖全部 14 种索引的构建原理、检索策略、内部组件与实战选型
写在前面
在 RAG(检索增强生成)应用中,索引是连接数据与大模型的桥梁。索引决定了你的数据如何被组织、存储和检索,直接影响回答的质量和效率。LlamaIndex 提供了 14 种各具特色的索引类型,每种都有其独特的数据结构和检索策略。
本文基于 LlamaIndex 源码 llama_index/core/indices/__init__.py 中的 __all__ 列表,逐个深入剖析。
一、VectorStoreIndex --- 向量存储索引
🏆 最核心、最常用,90% 的 RAG 场景首选
构建原理
scss
文档 → 文本分块(Node) → 嵌入模型(Embedding) → 向量 → 存入向量数据库- 文档拆分:原始文档被分割为多个 Node(文本块)
- 向量嵌入:每个 Node 通过嵌入模型转为固定维度的向量
- 向量存储:向量存入向量数据库(内存、Chroma、Qdrant、Pinecone、Milvus 等)
- 语义检索:查询时将问题也转为向量,计算余弦相似度,召回 Top-K 最相关 Node
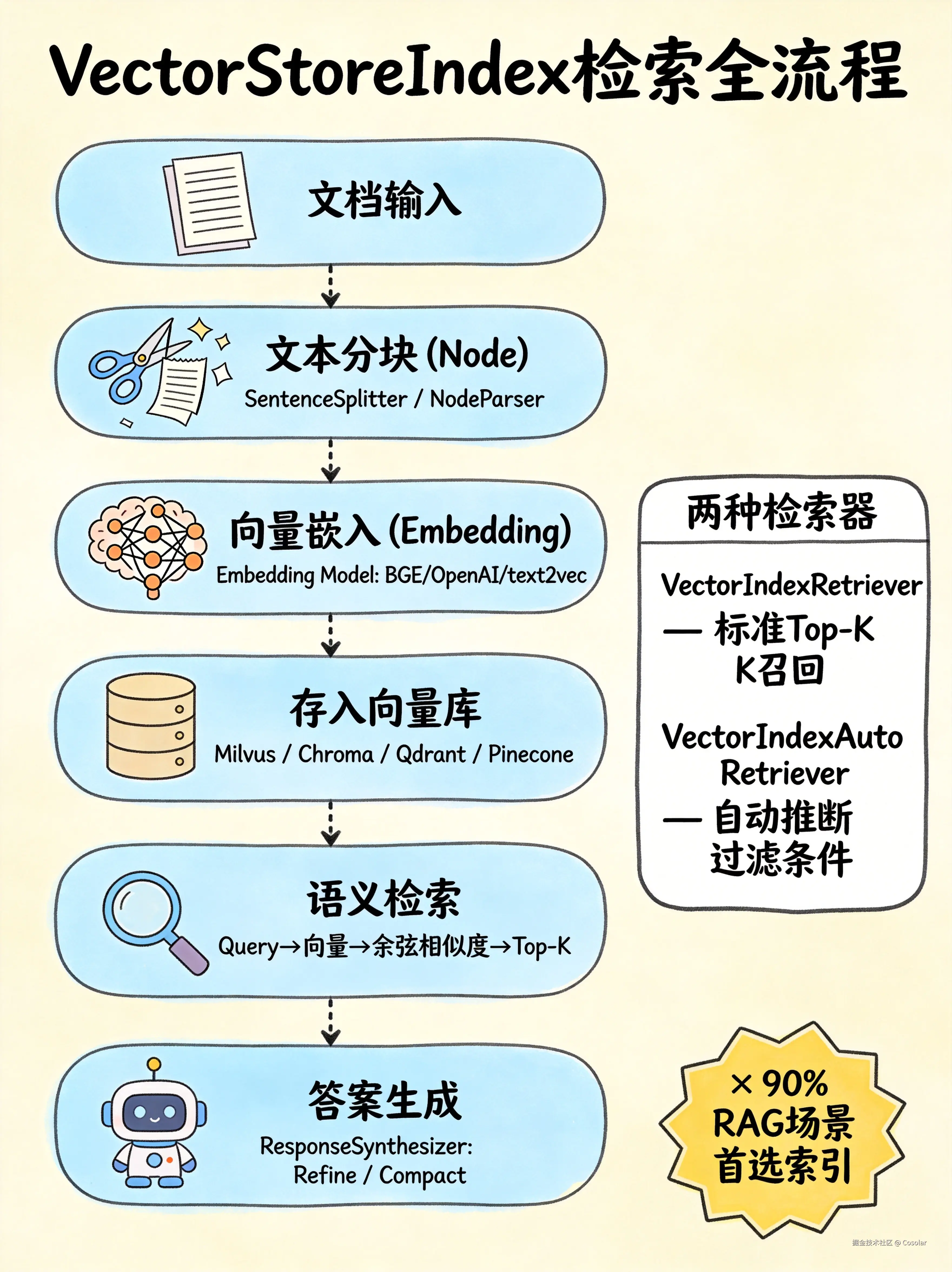
内部检索器
源码中 VectorStoreIndex 配备了两种检索器:
| 检索器 | 说明 |
|---|---|
| VectorIndexRetriever | 标准向量相似度检索,基于 Top-K 召回 |
| VectorIndexAutoRetriever | 自动检索器,能自动推断查询条件(如元数据过滤),无需手动指定 |
核心特点
- ✅ 基于语义相似度,理解"意思相近"而非"字面匹配"
- ✅ 检索速度极快(向量数据库优化到毫秒级)
- ✅ 支持增量插入(
insert)、删除(delete)、文档映射查看(ref_doc_info) - ✅ 支持异步操作(
aadd_nodes、adelete等) - ⚠️ 依赖嵌入模型质量,长文档可能丢失局部细节信息
适用场景
- 通用语义搜索、知识库问答
- 当你不确定用什么索引时,先用它
代码示例
python
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 构建索引
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# 查询
query_engine = index.as_query_engine()
response = query_engine.query("LlamaIndex 支持哪些索引类型?")对接外部向量数据库示例
python
import chromadb
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.vector_stores.chroma import ChromaVectorStore
# 初始化 Chroma 客户端
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("my_collection")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 构建索引(向量存入 Chroma 而非内存)
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)二、SummaryIndex --- 摘要索引
📋 最简单的索引,遍历全部内容做汇总
构建原理
scss
文档 → 文本分块(Node) → 拼接为线性列表(构建时无需调用 LLM)SummaryIndex 原名 ListIndex,是最基础的索引结构。构建阶段完全不调用 LLM,只是将所有 Node 按顺序存入列表。
查询策略
查询时采用 "创建-精炼"(Create and Refine) 范式:
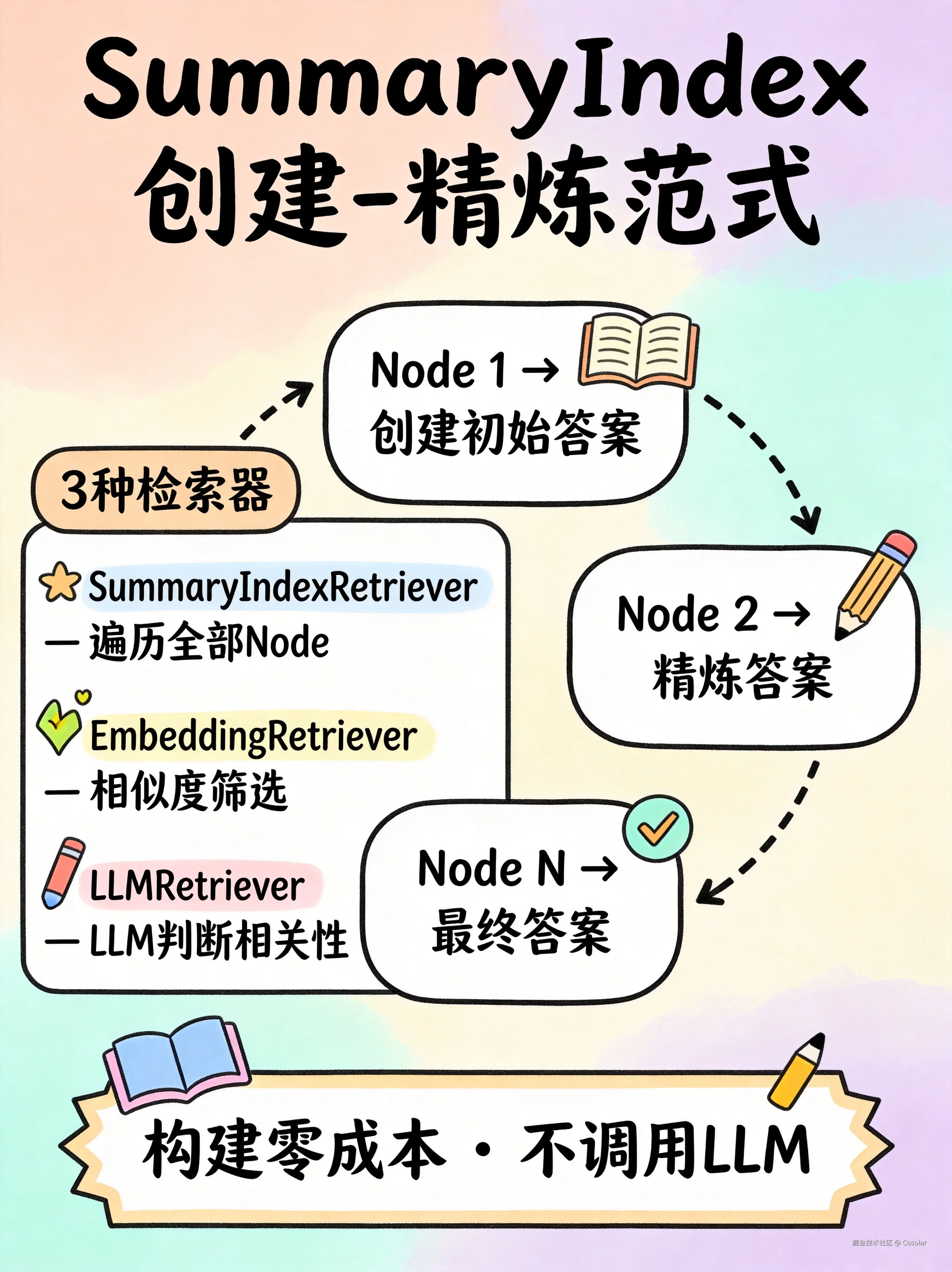
- 用第一个 Node 构建初始答案
- 依次将后续 Node 作为上下文,不断精炼答案
- 精炼可能是:保持原答案、微调、或完全重写
内部检索器
| 检索器 | 说明 |
|---|---|
| SummaryIndexRetriever | 默认检索器,遍历所有 Node |
| SummaryIndexEmbeddingRetriever | 基于嵌入相似度筛选 Node(而非遍历全部) |
| SummaryIndexLLMRetriever | 让 LLM 判断哪些 Node 与查询相关 |
💡 关键洞察:SummaryIndex 不一定遍历全部 Node!通过 EmbeddingRetriever 或 LLMRetriever,也可以实现选择性检索,避免 Token 浪费。
核心特点
- ✅ 构建零成本(不调用 LLM)
- ✅ LLM 能看到所有内容,不会遗漏信息
- ⚠️ 默认检索模式下,文档越多 Token 消耗越大
- ⚠️ 大文档集合检索速度慢
适用场景
- 全局摘要汇总("请总结所有文档的主要内容")
- 少量文档的完整浏览
- 邮件汇总、日报周报汇总
三、TreeIndex --- 树索引
🌲 自底向上构建摘要树,O(log N) 检索
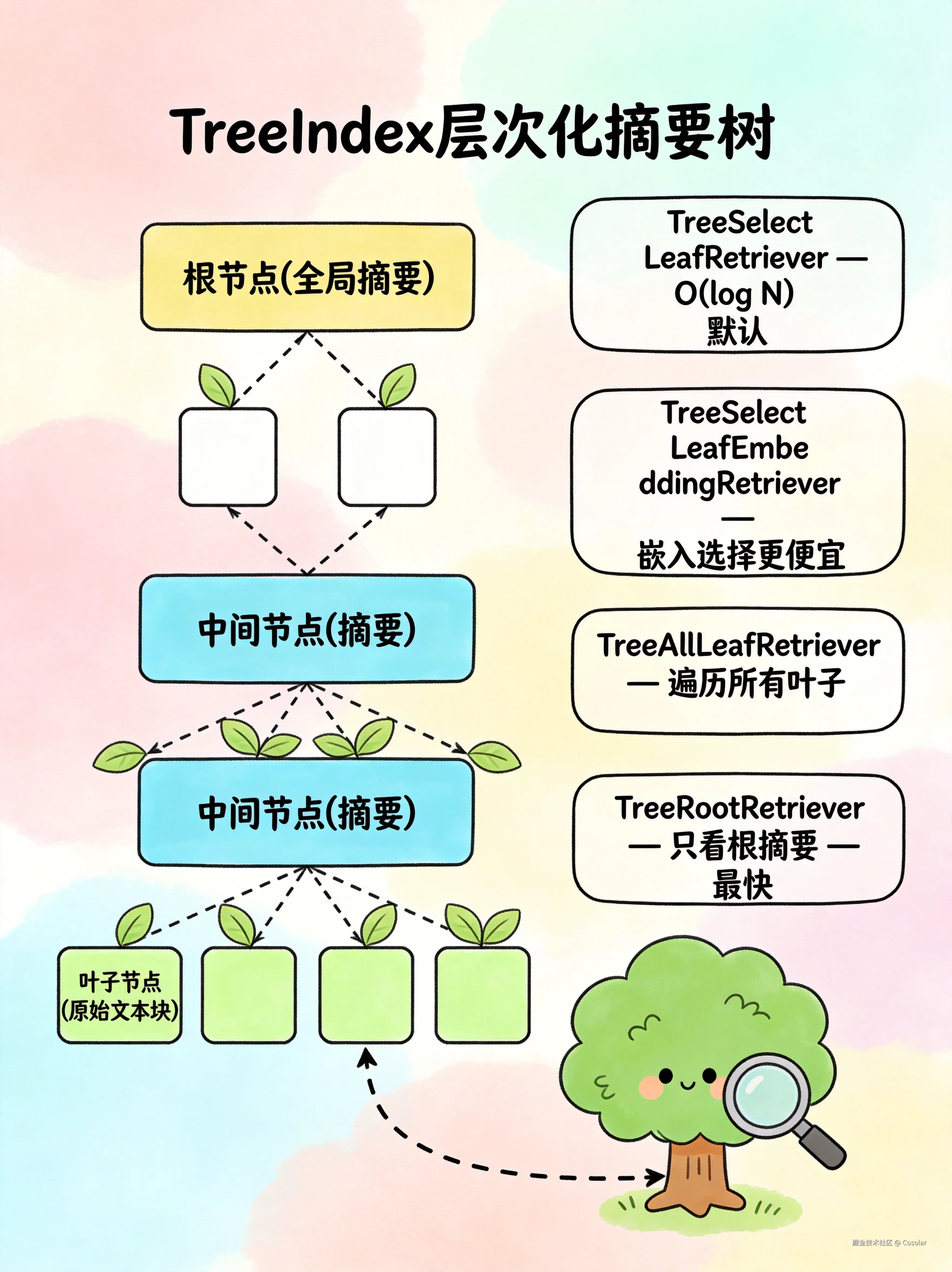
构建原理
scss
叶子节点(原始文本块)
↓ 逐层摘要
中间节点(子节点摘要)
↓ 逐层摘要
根节点(全局摘要)- 叶子节点是原始文档块
- 从底层开始,每层用 LLM 对子节点生成摘要,形成父节点
- 逐层向上,直到根节点
- 构建成本约为 O(N·log(N))
查询策略
TreeIndex 提供了四种检索器,对应不同的查询模式:
| 检索器 | 查询模式 | 说明 |
|---|---|---|
| TreeSelectLeafRetriever | 默认模式 | 从根节点开始,LLM 选择最相关的子节点,递归向下直到叶子节点,O(log N) |
| TreeSelectLeafEmbeddingRetriever | 嵌入模式 | 与默认类似,但用嵌入相似度代替 LLM 做节点选择,更便宜 |
| TreeAllLeafRetriever | 全叶模式 | 直接遍历所有叶子节点,类似 SummaryIndex |
| TreeRootRetriever | 根节点模式 | 只用根节点摘要作为上下文回答,速度最快但最粗略 |
核心特点
- ✅ 层次化结构,支持摘要引导的逐步精化检索
- ✅ 默认查询复杂度 O(log N),远优于 SummaryIndex 的 O(N)
- ✅ 适合非常大规模的文档集合
- ⚠️ 构建慢(每层都需要 LLM 生成摘要)
- ⚠️ 上层摘要可能丢失底层细节
适用场景
- 大规模文档集合(数千到数万篇)
- 需要分层浏览的知识库
- 书籍、手册等层级化内容
代码示例
python
from llama_index.core import TreeIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = TreeIndex.from_documents(documents)
# 默认模式:树遍历选择叶子节点
query_engine = index.as_query_engine()
response = query_engine.query("这本书的核心观点是什么?")四、KeywordTableIndex --- 关键词表索引
🔑 哈希表思想,关键词 → Node 倒排映射
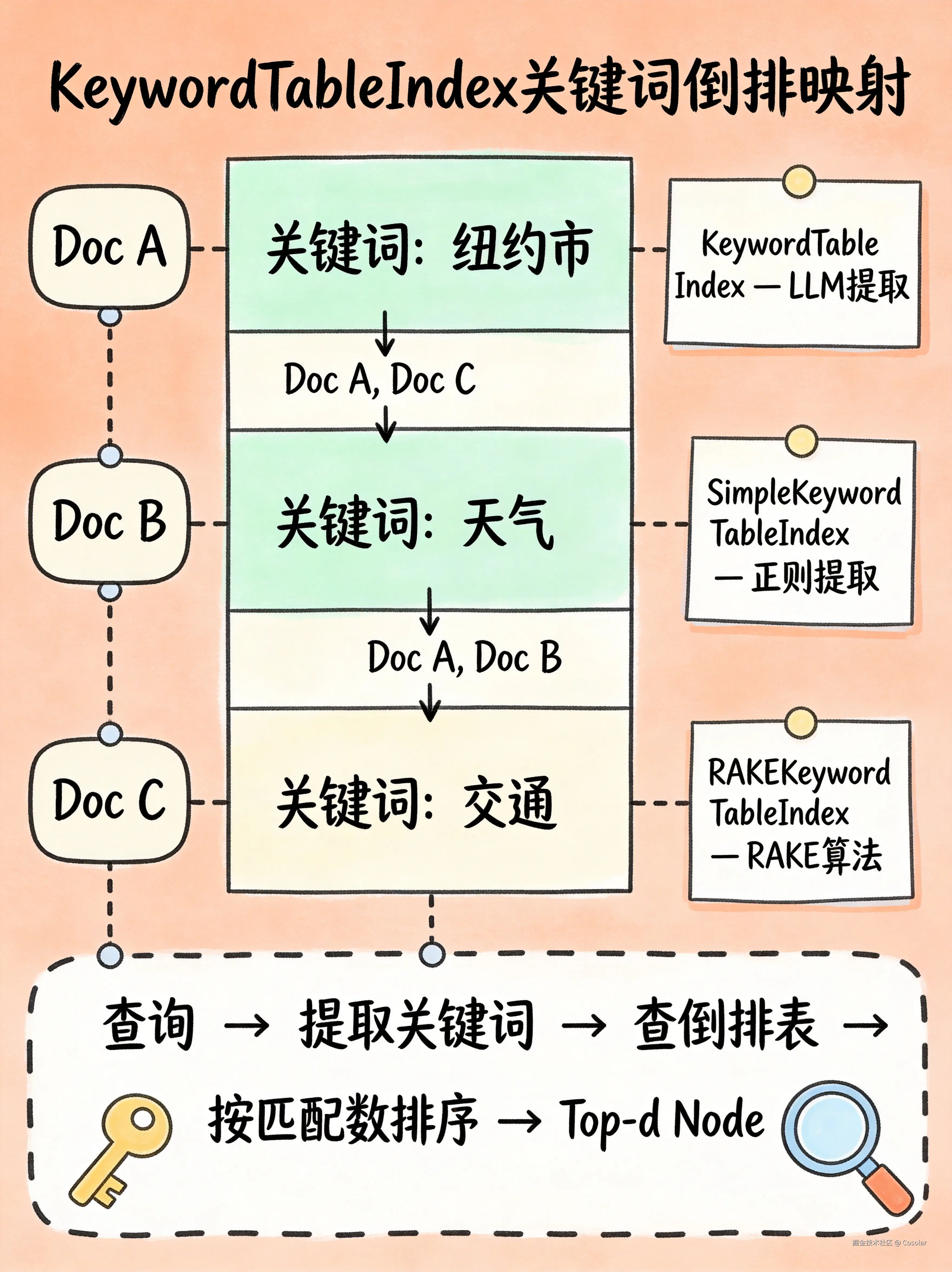
构建原理
arduino
文档 → 文本分块(Node) → 每个Node提取关键词 → 建立"关键词→Node列表"倒排表灵感来自哈希表(Hash Table)。构建时,对每个 Node 用 LLM 提取关键词(关键词可以是短语,如"纽约市"),然后存入倒排索引表。
三种变体
| 变体 | 关键词提取方式 | 成本 |
|---|---|---|
| KeywordTableIndex | LLM 提取关键词 | 高(需要 LLM 调用) |
| SimpleKeywordTableIndex | 正则表达式提取,过滤停用词 | 低(无需 LLM) |
| RAKEKeywordTableIndex | RAKE 算法自动提取 | 低(无需 LLM) |
三种检索器
| 检索器 | 说明 |
|---|---|
| KeywordTableGPTRetriever | 用 LLM 从查询中提取关键词,查表匹配 |
| KeywordTableSimpleRetriever | 用正则从查询中提取关键词,查表匹配 |
| KeywordTableRAKERetriever | 用 RAKE 从查询中提取关键词,查表匹配 |
查询流程
- 从查询中提取关键词
- 在倒排表中查找匹配的 Node ID
- 按匹配关键词数量排序(从多到少)
- 截取前 d 个 Node(d 为用户指定参数)
- 用"创建-精炼"范式生成答案
核心特点
- ✅ 关键词精确匹配,符合传统搜索习惯
- ✅ 查询复杂度 O(k·c),k 为关键词数,c 为每关键词匹配的 Node 数
- ⚠️ 不理解语义,同义词问题严重
- ⚠️ 关键词提取质量直接影响效果
适用场景
- 关键词驱动的精确查找
- FAQ 系统
- 需要严格匹配关键词的场景
- 成本敏感(用 Simple 或 RAKE 变体)
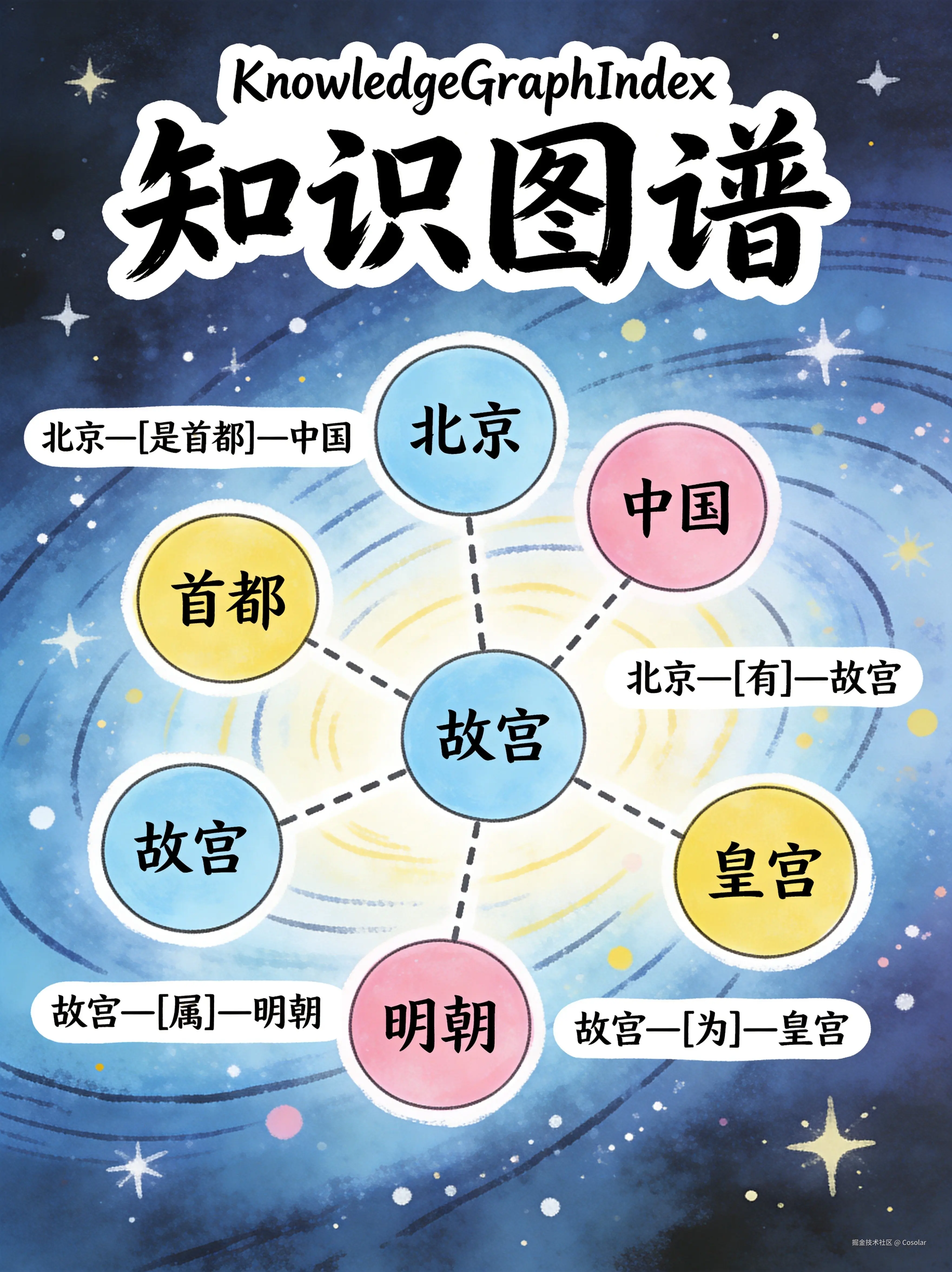
五、KnowledgeGraphIndex --- 知识图谱索引
🕸️ 三元组构建图谱,支持关系推理
构建原理
scss
文档 → LLM抽取三元组(实体, 关系, 实体) → 构建知识图谱 → 存储节点和边从文档中抽取 (主体实体, 关系, 对象实体) 三元组,构建知识图谱。节点是实体,边是关系。
内部检索器
| 检索器 | 说明 |
|---|---|
| KGTableRetriever | 基于关键词在图谱表中查找相关实体和关系 |
| KnowledgeGraphRAGRetriever | RAG 风格检索,在图谱中沿关系路径遍历,支持多跳推理 |
核心特点
- ✅ 能捕捉实体间关系,支持多跳推理("A 和 B 是什么关系?")
- ✅ 适合结构化知识问答
- ⚠️ 三元组抽取需要大量 LLM 调用,构建成本高
- ⚠️ 抽取错误会传播到整个图谱
适用场景
- 关系密集型领域知识问答
- 人物关系、企业关系查询
- 知识图谱构建与问答
六、PropertyGraphIndex --- 属性图索引
🏗️ 知识图谱的增强版,节点和边带属性,支持 Cypher 查询
PropertyGraphIndex 是 LlamaIndex 中最复杂、最强大的图索引。它在知识图谱基础上,允许节点和边附加属性键值对,并支持多种检索策略。
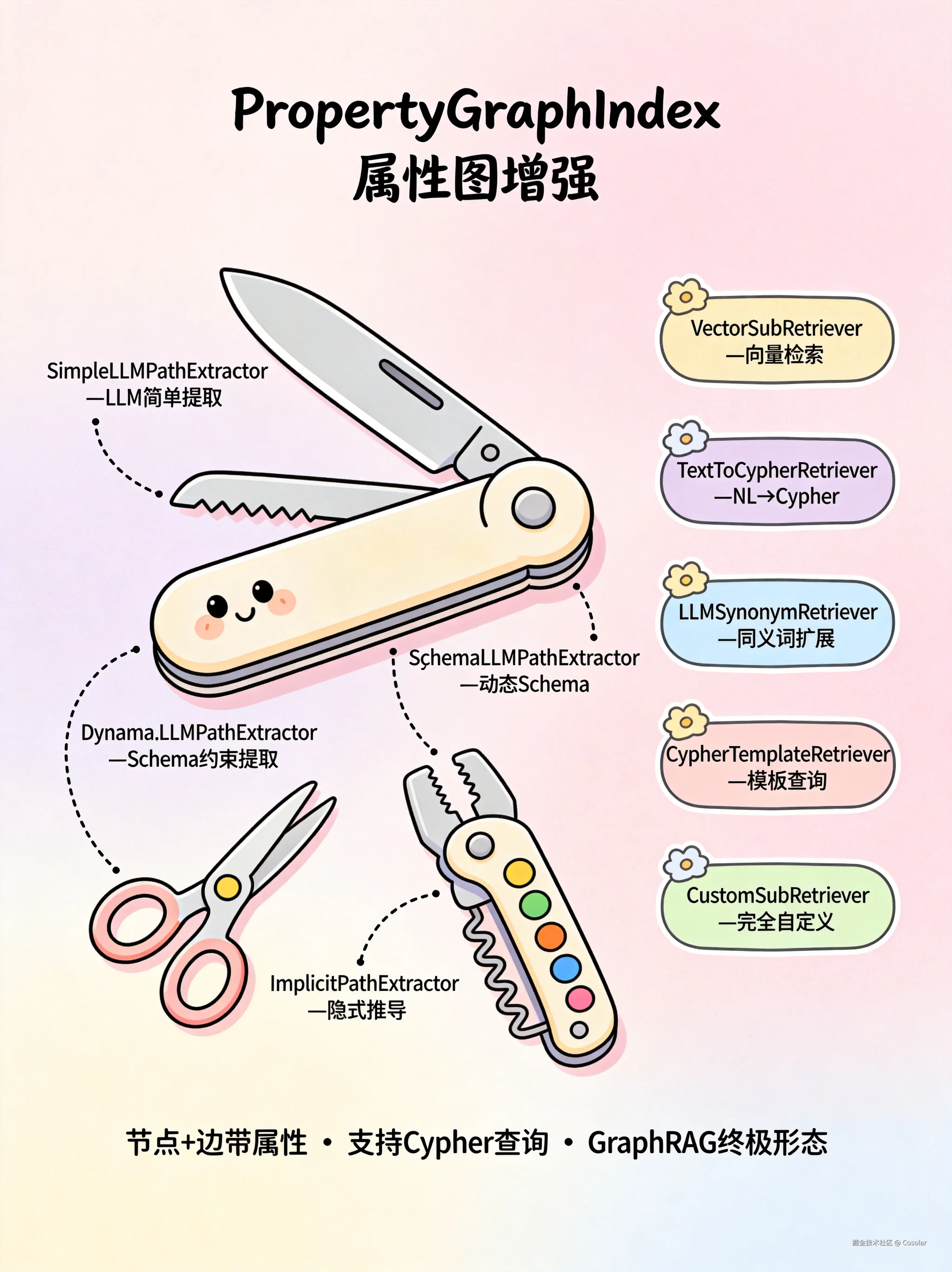
构建原理
css
文档 → 路径提取器抽取(实体-[关系]-实体) → 构建属性图 → 节点/边附加属性 → 存入图数据库四种路径提取器(Transformations)
| 提取器 | 说明 |
|---|---|
| SimpleLLMPathExtractor | 用 LLM 简单提取实体关系路径 |
| SchemaLLMPathExtractor | 基于预定义 Schema 约束 LLM 提取,确保输出符合规范 |
| DynamicLLMPathExtractor | 动态 Schema,LLM 自由提取并自动推断实体类型和关系类型 |
| ImplicitPathExtractor | 隐式路径提取,不依赖 LLM,从已有数据结构中推导关系 |
五种子检索器(Sub-Retrievers)
| 检索器 | 说明 |
|---|---|
| VectorSubRetriever | 基于向量相似度在图谱中检索节点 |
| TextToCypherRetriever | 将自然语言查询转为 Cypher 查询语言,在图数据库中执行 |
| LLMSynonymRetriever | 用 LLM 生成查询的同义词/相关实体,扩展检索范围 |
| CypherTemplateRetriever | 基于预定义 Cypher 模板检索,适合固定查询模式 |
| CustomSubRetriever | 完全自定义检索逻辑 |
核心特点
- ✅ 最灵活的图索引,支持属性、多种检索策略
- ✅ 支持 Cypher 查询(Neo4j 等)
- ✅ 可从已有图数据库创建索引(
from_existing) - ⚠️ 复杂度最高,学习曲线陡峭
- ⚠️ 需要图数据库支持
适用场景
- 复杂实体关系建模(人物画像、产品信息图谱)
- 需要 Cypher 查询的图数据库应用
- GraphRAG 高级场景
七、DocumentSummaryIndex --- 文档摘要索引
📄 两阶段检索:先粗筛文档,再细搜片段
构建原理
markdown
文档 → 为每篇文档生成摘要 → 摘要向量化 → 存入向量库
↓
文档内部 → 文本分块(Node) → Node 向量化 → 存入向量库- 第一阶段(粗筛):为每整篇文档生成摘要,对摘要做 Embedding,基于摘要相似度粗筛出最相关的几篇文档
- 第二阶段(精搜):只对粗筛出来的文档做内部 Node 级别的细粒度检索
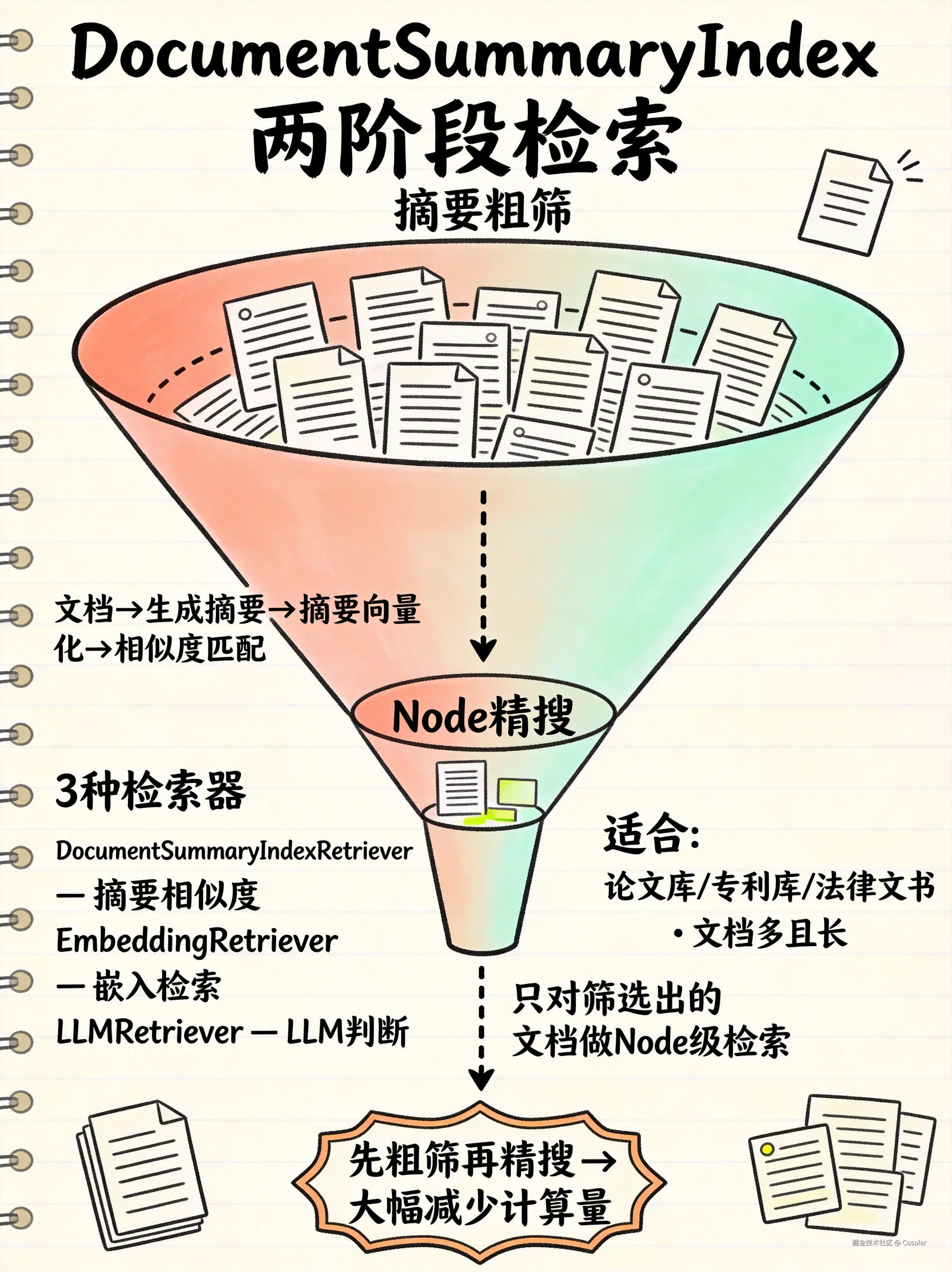
内部检索器
| 检索器 | 说明 |
|---|---|
| DocumentSummaryIndexRetriever | 默认检索器,基于摘要相似度粗筛文档 |
| DocumentSummaryIndexEmbeddingRetriever | 嵌入检索器,用摘要嵌入做文档级检索 |
| DocumentSummaryIndexLLMRetriever | LLM 检索器,让 LLM 判断哪些文档与查询相关 |
核心特点
- ✅ 大大减少 embedding 和相似度计算量
- ✅ 先筛选文档再检索,减少噪声干扰
- ✅ 适合文档数量多、文档本身也长的场景
- ⚠️ 如果摘要写得不好,第一阶段可能漏掉正确文档
适用场景
- 论文库、专利库、法律文书库
- 每篇文档都很长(几十页),文档数量也多(上千篇)
- 检索资源有限,需要优化速度和成本
八、PandasIndex --- Pandas 数据索引
📊 让自然语言查询 DataFrame
构建原理
将 Pandas DataFrame 作为数据源,自然语言查询 → 转成 Pandas 操作 → 执行 → 返回结果。
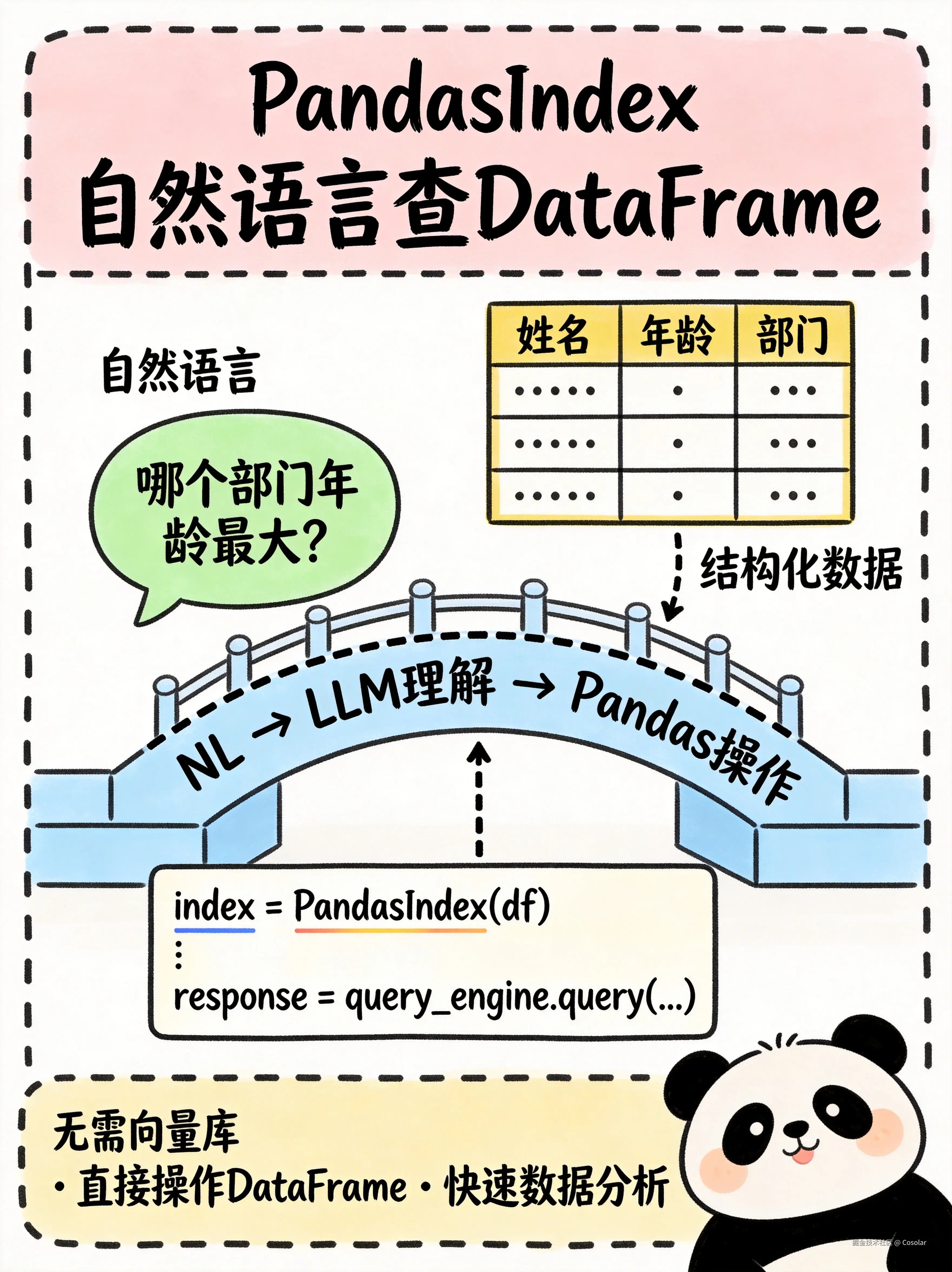
核心特点
- ✅ 无需向量数据库,直接操作 DataFrame
- ✅ 适合快速数据分析
- ⚠️ DataFrame 过大时 Token 消耗高(需要把 schema 传给 LLM)
适用场景
- CSV、Excel 文件加载的表格数据
- 让用户用自然语言查询结构化表格
- 快速数据分析、报表查询
代码示例
python
import pandas as pd
from llama_index.core import PandasIndex
df = pd.DataFrame({
"姓名": ["张三", "李四", "王五"],
"年龄": [28, 35, 42],
"部门": ["工程", "市场", "财务"],
})
index = PandasIndex(df)
query_engine = index.as_query_engine()
response = query_engine.query("哪个部门的人年龄最大?")九、SQLStructStoreIndex --- SQL 结构化存储索引
🗄️ 自然语言转 SQL,查询关系型数据库
构建原理
sql
自然语言查询 → LLM 生成 SQL → 执行 SQL → 返回结果 → LLM 转自然语言回答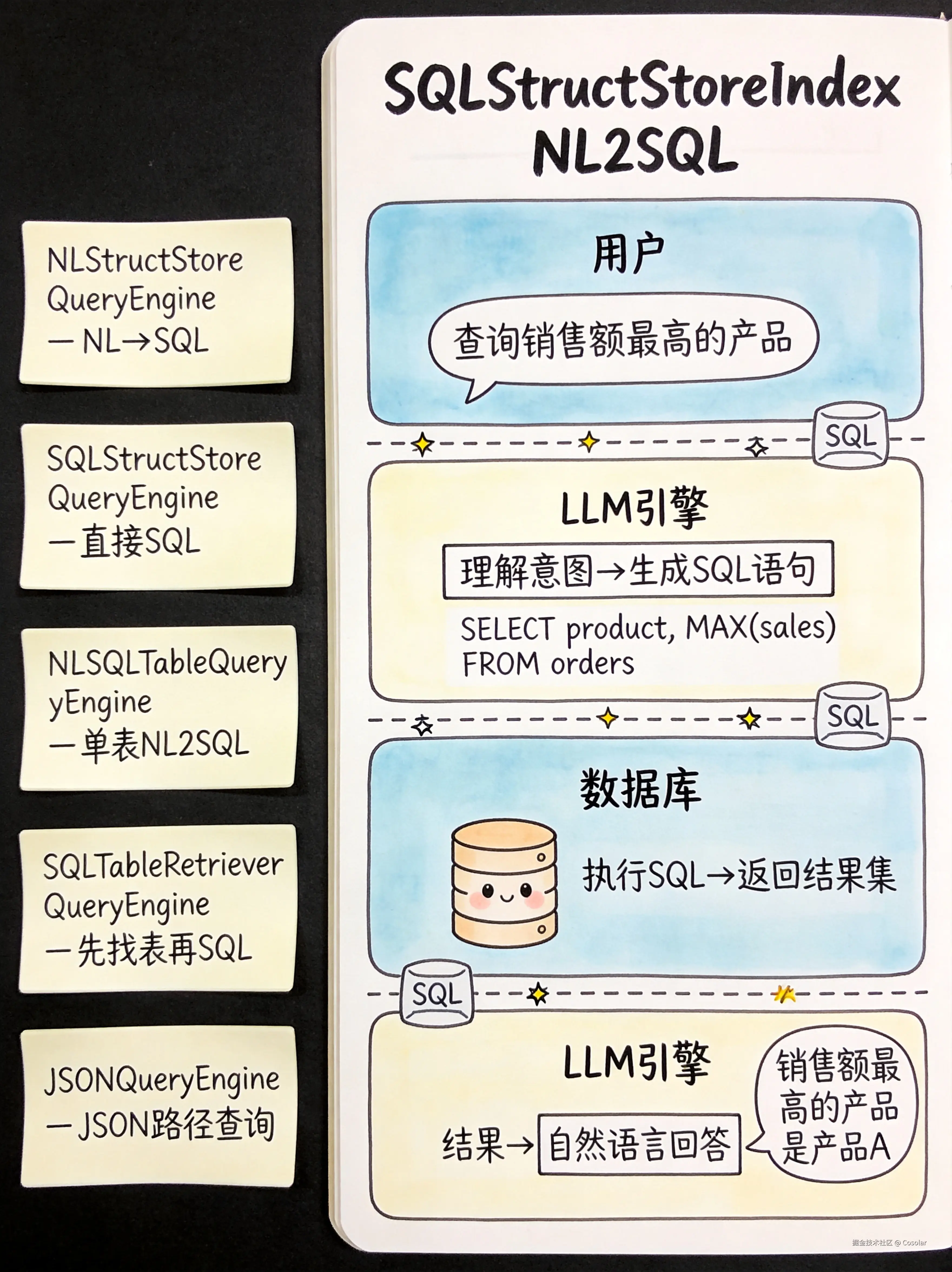
内部组件
| 组件 | 说明 |
|---|---|
| SQLStructStoreIndex | 索引本体,存储数据库 schema 信息 |
| SQLContextContainerBuilder | 构建 SQL 上下文容器,包含表结构、示例数据等 |
| NLStructStoreQueryEngine | 自然语言查询引擎,NL → SQL → 执行 |
| SQLStructStoreQueryEngine | SQL 查询引擎,直接执行 SQL |
| NLSQLTableQueryEngine | 针对单表的 NL2SQL 查询引擎 |
| SQLTableRetrieverQueryEngine | 先检索相关表,再生成 SQL 查询 |
| JSONQueryEngine | JSON 路径查询引擎,用于 JSON 结构化数据 |
核心特点
- ✅ 真正的 NL2SQL 能力
- ✅ 支持多种数据库(MySQL、PostgreSQL、SQLite 等)
- ✅ 支持 PGVector 扩展(PostgreSQL 向量搜索)
- ⚠️ SQL 生成质量依赖 LLM 能力
- ⚠️ 复杂查询可能生成错误 SQL
适用场景
- NL2SQL 应用
- 让业务人员用自然语言查询数据库
- 企业内部数据自助查询
十、MultiModalVectorStoreIndex --- 多模态向量索引
🖼️ 图文跨模态检索,一个索引搜文本和图片
构建原理
css
文本 → 文本嵌入模型 → 向量 ─┐
├→ 同一向量空间 → 跨模态检索
图像 → 图像嵌入模型(如CLIP) → 向量 ─┘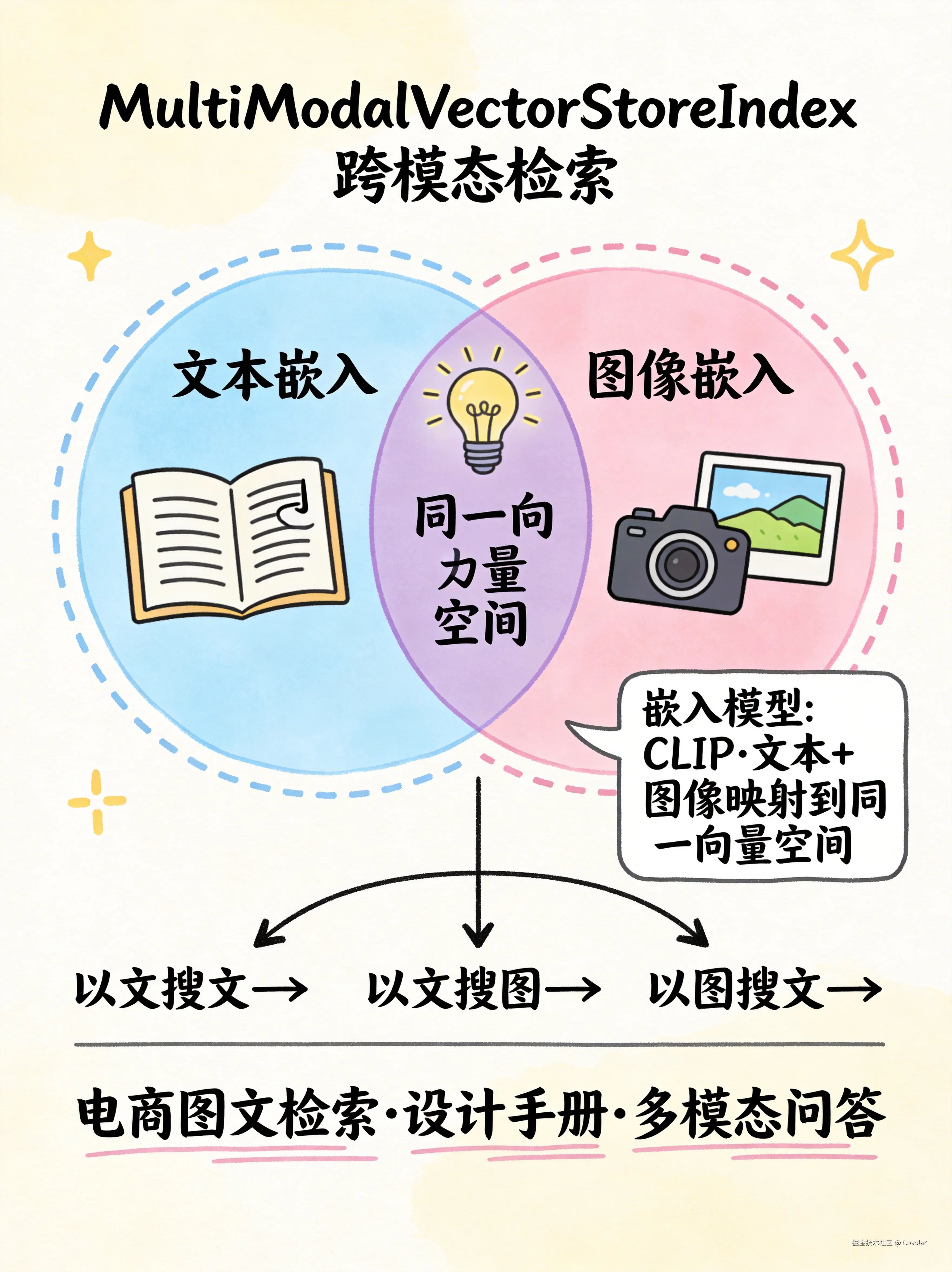
内部检索器
| 检索器 | 说明 |
|---|---|
| MultiModalVectorIndexRetriever | 多模态向量检索器,支持文本和图像混合检索 |
核心特点
- ✅ 真正的多模态能力:以文搜图、以图搜文、图文混合检索
- ✅ 文本和图像嵌入到同一向量空间
- ⚠️ 需要多模态嵌入模型(如 CLIP),资源消耗大
- ⚠️ 图像处理需要额外的嵌入计算
适用场景
- 电商商品图文检索
- 文档含大量图片的知识库(设计手册、教材)
- 多模态问答系统
十一、ComposableGraph --- 可组合图
🔀 多级索引路由,粗筛+精搜的组合拳
构建原理
css
顶层索引(如 KeywordTableIndex 做路由)
├── 分支1:VectorStoreIndex(部门A的文档)
├── 分支2:VectorStoreIndex(部门B的文档)
└── 分支3:SummaryIndex(部门C的文档)ComposableGraph 允许在已有索引之上构建新的索引,形成多级索引结构。查询时先在顶层索引做路由,找到最相关的分支,再进入分支内的索引做精细检索。
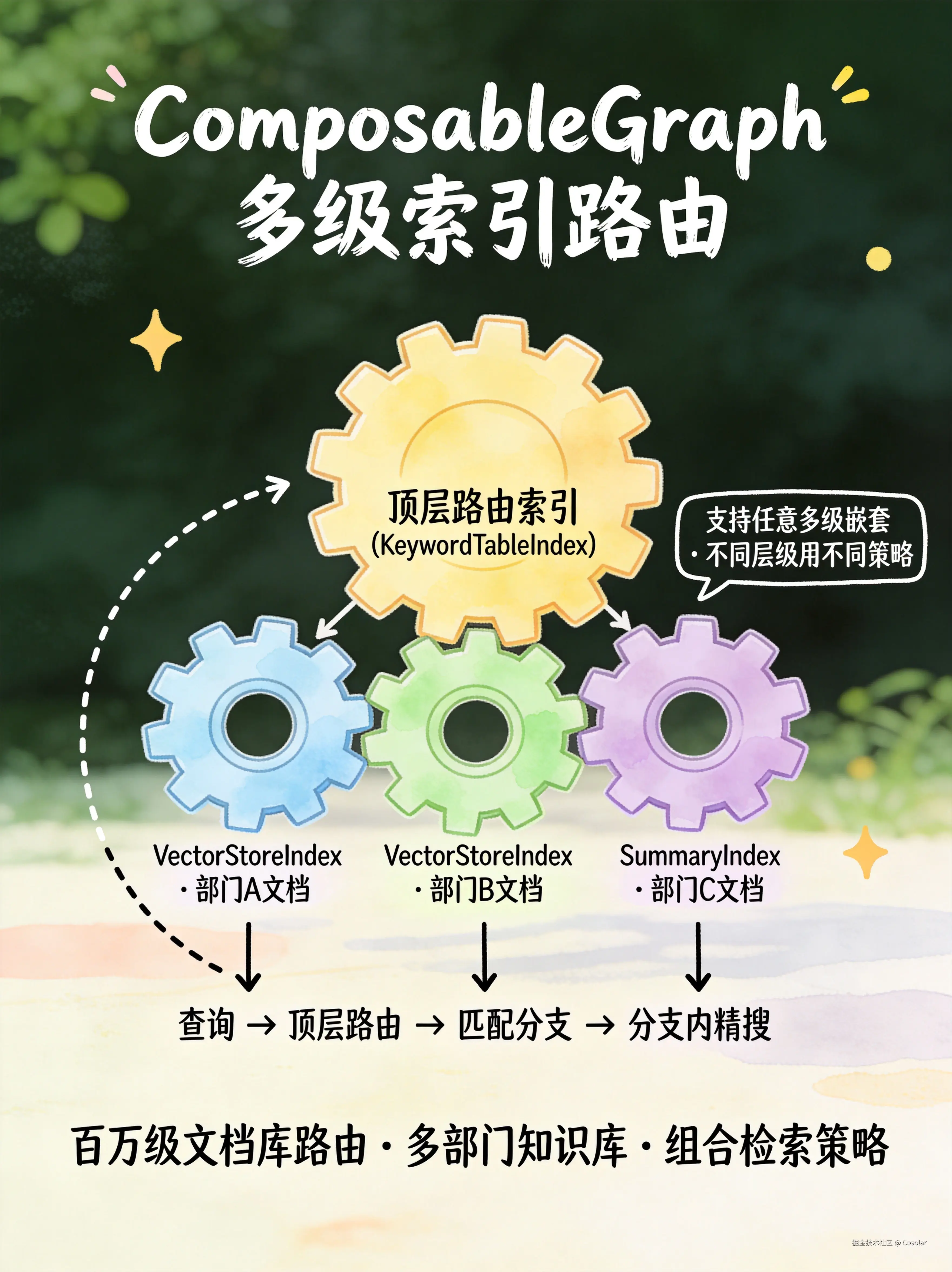
核心特点
- ✅ 分级检索,解决大规模文档的"先粗筛后精搜"问题
- ✅ 灵活组合,不同层级用不同索引策略
- ✅ 支持任意多级嵌套
- ⚠️ 实现复杂度高,调试麻烦
- ⚠️ 路由层选择错误会导致下游检索完全偏离
适用场景
- 百万级文档库的多级路由检索
- 多部门知识库(每个部门维护自己的索引,顶层做路由)
- 需要组合多种检索策略的场景
十二、EmptyIndex --- 空索引
🧩 空白画布,完全自由定制
构建原理
EmptyIndex 不预设任何结构,是一个空壳索引。开发者可以自由插入 Node、自定义检索逻辑。
内部检索器
| 检索器 | 说明 |
|---|---|
| EmptyIndexRetriever | 空检索器,不返回任何结果(需自定义覆盖) |
核心特点
- ✅ 完全自由,不受预设结构约束
- ✅ 适合实验和原型验证
- ⚠️ 需要自己实现所有逻辑
适用场景
- 高度定制化索引需求
- 研究和实验新的检索算法
- 特殊业务场景,现有索引都不满足
十三、索引持久化与加载
所有索引都支持持久化到磁盘和重新加载,避免每次重启都重建索引:
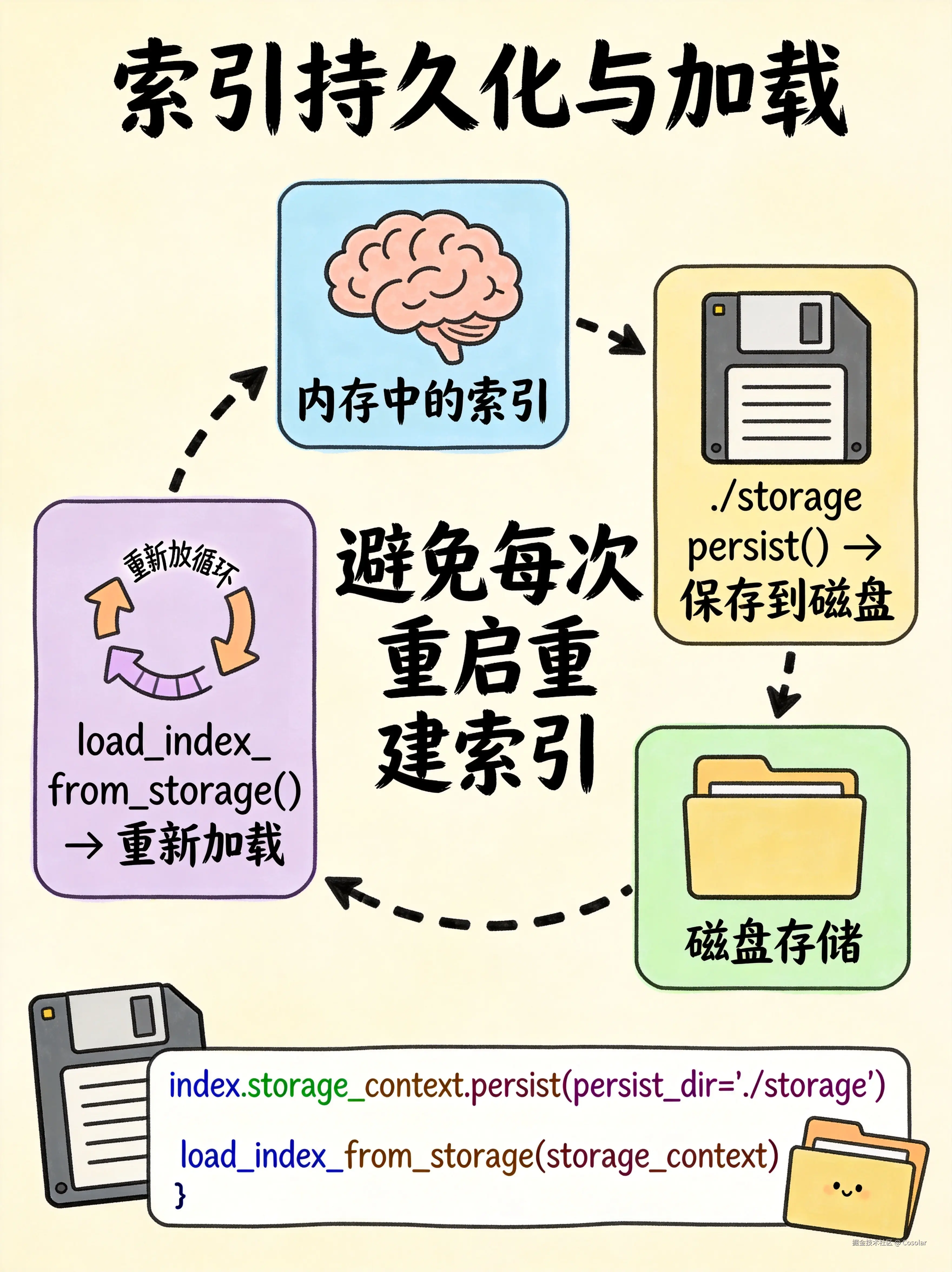
python
# 保存索引到磁盘
index.storage_context.persist(persist_dir="./storage")
# 从磁盘加载索引
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)十四、Legacy 命名对照表
LlamaIndex 在 v0.10+ 版本对索引类名做了统一重命名,旧名称仍保留兼容:
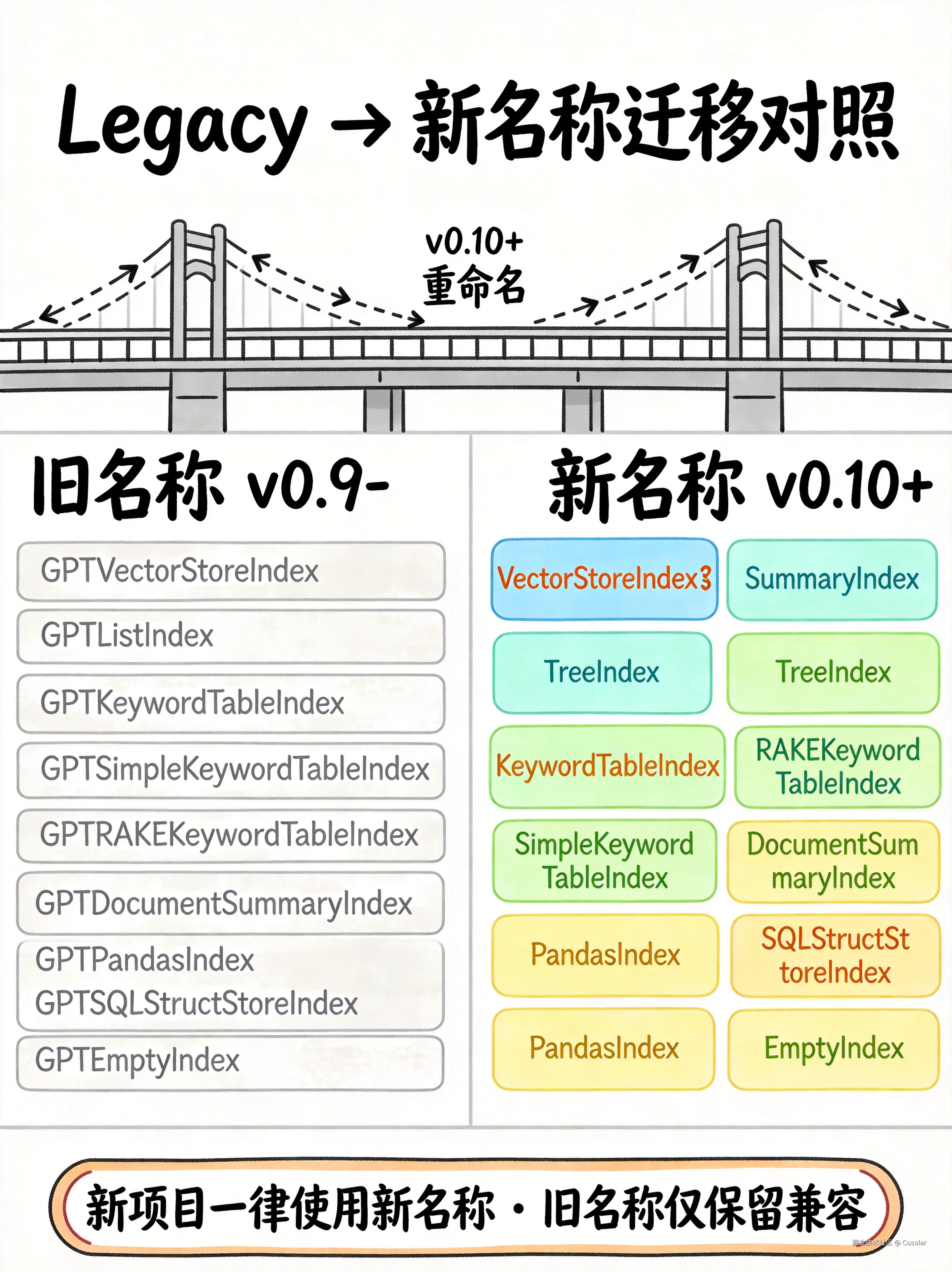
| Legacy 旧名称 | → 当前新名称 |
|---|---|
GPTVectorStoreIndex |
→ VectorStoreIndex |
GPTListIndex / ListIndex |
→ SummaryIndex |
GPTTreeIndex |
→ TreeIndex |
GPTKeywordTableIndex |
→ KeywordTableIndex |
GPTSimpleKeywordTableIndex |
→ SimpleKeywordTableIndex |
GPTRAKEKeywordTableIndex |
→ RAKEKeywordTableIndex |
GPTDocumentSummaryIndex |
→ DocumentSummaryIndex |
GPTPandasIndex |
→ PandasIndex |
GPTSQLStructStoreIndex |
→ SQLStructStoreIndex |
GPTEmptyIndex |
→ EmptyIndex |
💡 新项目一律使用新名称,便于维护和升级。
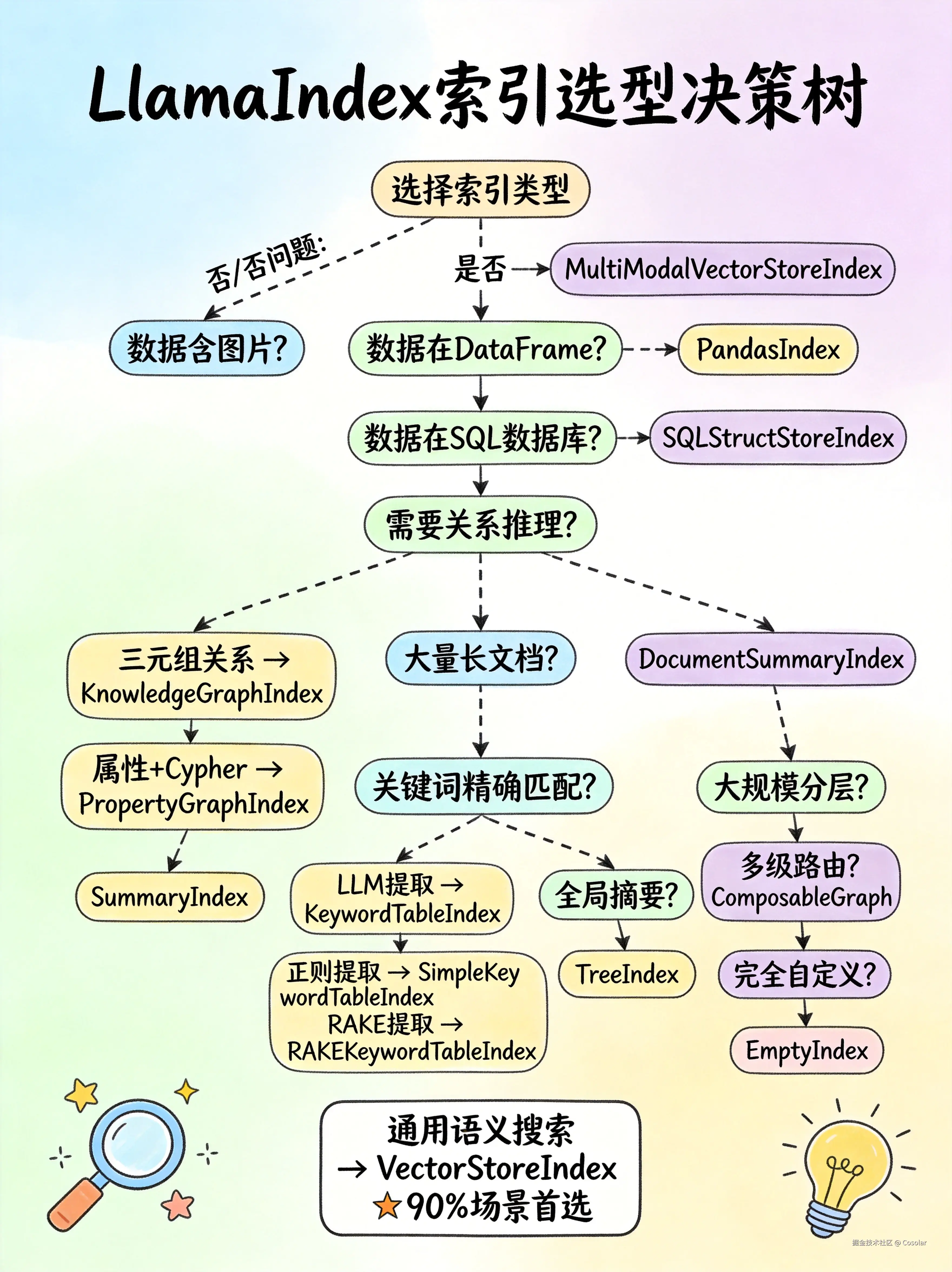
十五、索引选型决策树
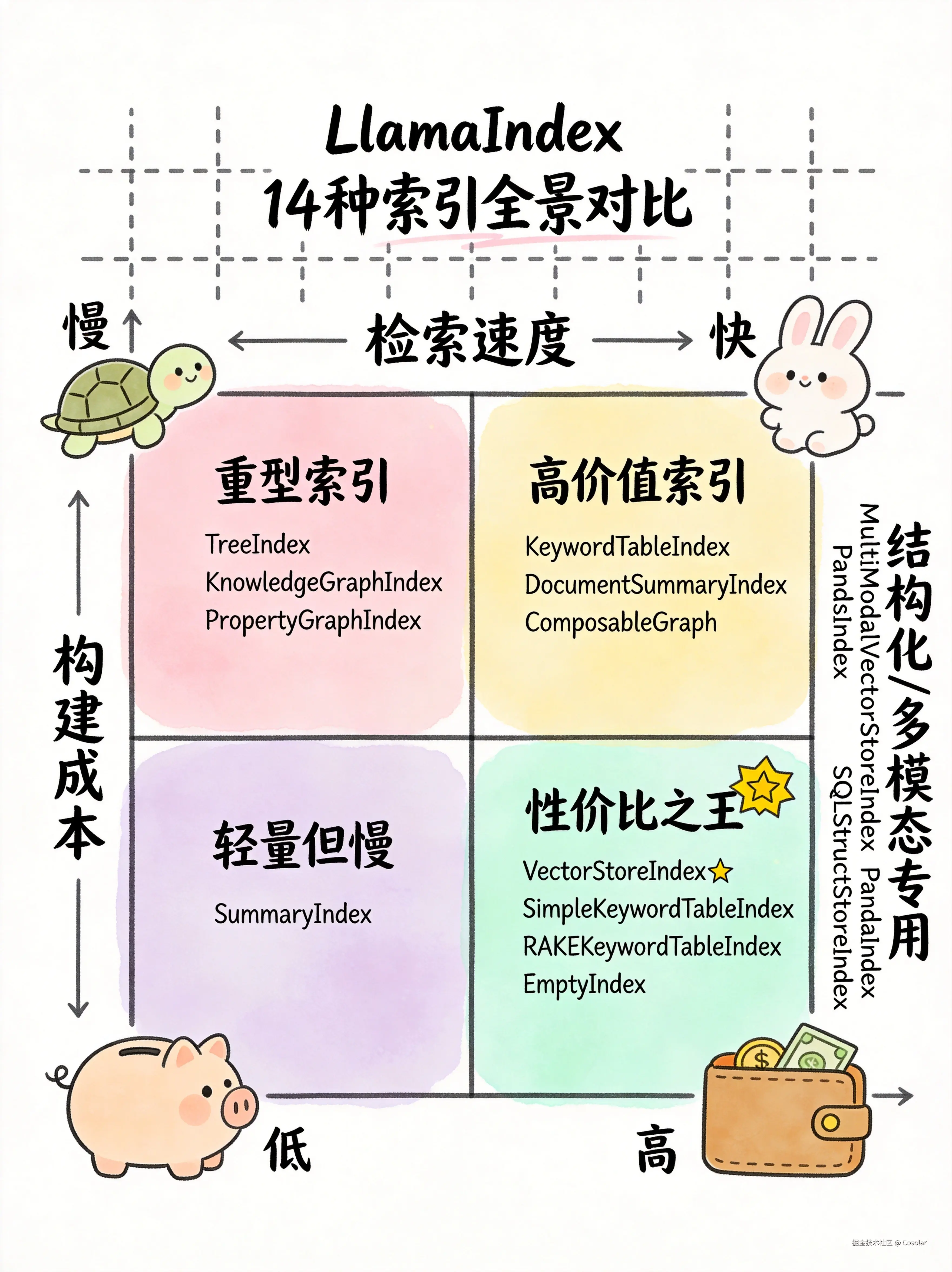
十六、全景对比总表
| 分类 | 索引 | 构建是否需要LLM | 检索方式 | 检索速度 | 构建成本 | 适用规模 |
|---|---|---|---|---|---|---|
| 向量语义 | VectorStoreIndex | ❌ | 向量相似度 | ⚡快 | 中 | 任意 |
| 列表摘要 | SummaryIndex | ❌ | 遍历/嵌入/LLM筛选 | 🐢慢~⚡快 | 低 | 小~中 |
| 树结构 | TreeIndex | ✅ | 树遍历/嵌入/根节点 | 🚀中~快 | 高 | 大 |
| 树结构 | ComposableGraph | ✅ | 多级路由 | 🚀中 | 高 | 超大 |
| 关键词 | KeywordTableIndex | ✅ | LLM关键词匹配 | ⚡快 | 中 | 中 |
| 关键词 | SimpleKeywordTableIndex | ❌ | 正则关键词匹配 | ⚡快 | 低 | 中 |
| 关键词 | RAKEKeywordTableIndex | ❌ | RAKE关键词匹配 | ⚡快 | 低 | 中 |
| 图结构 | KnowledgeGraphIndex | ✅ | 图谱遍历/RAG | 🚀中 | 高 | 中 |
| 图结构 | PropertyGraphIndex | ✅ | Cypher/向量/同义词 | 🚀中 | 高 | 中~大 |
| 长文档 | DocumentSummaryIndex | ✅ | 摘要粗筛+Node精搜 | ⚡快 | 中 | 大 |
| 结构化 | PandasIndex | ❌ | NL→Pandas操作 | 🚀中 | 低 | 小 |
| 结构化 | SQLStructStoreIndex | ✅ | NL→SQL→执行 | 🚀中 | 低 | 任意 |
| 多模态 | MultiModalVectorStoreIndex | ❌ | 多模态向量检索 | ⚡快 | 高 | 任意 |
| 特殊 | EmptyIndex | ❌ | 自定义 | - | - | - |
十七、实战建议
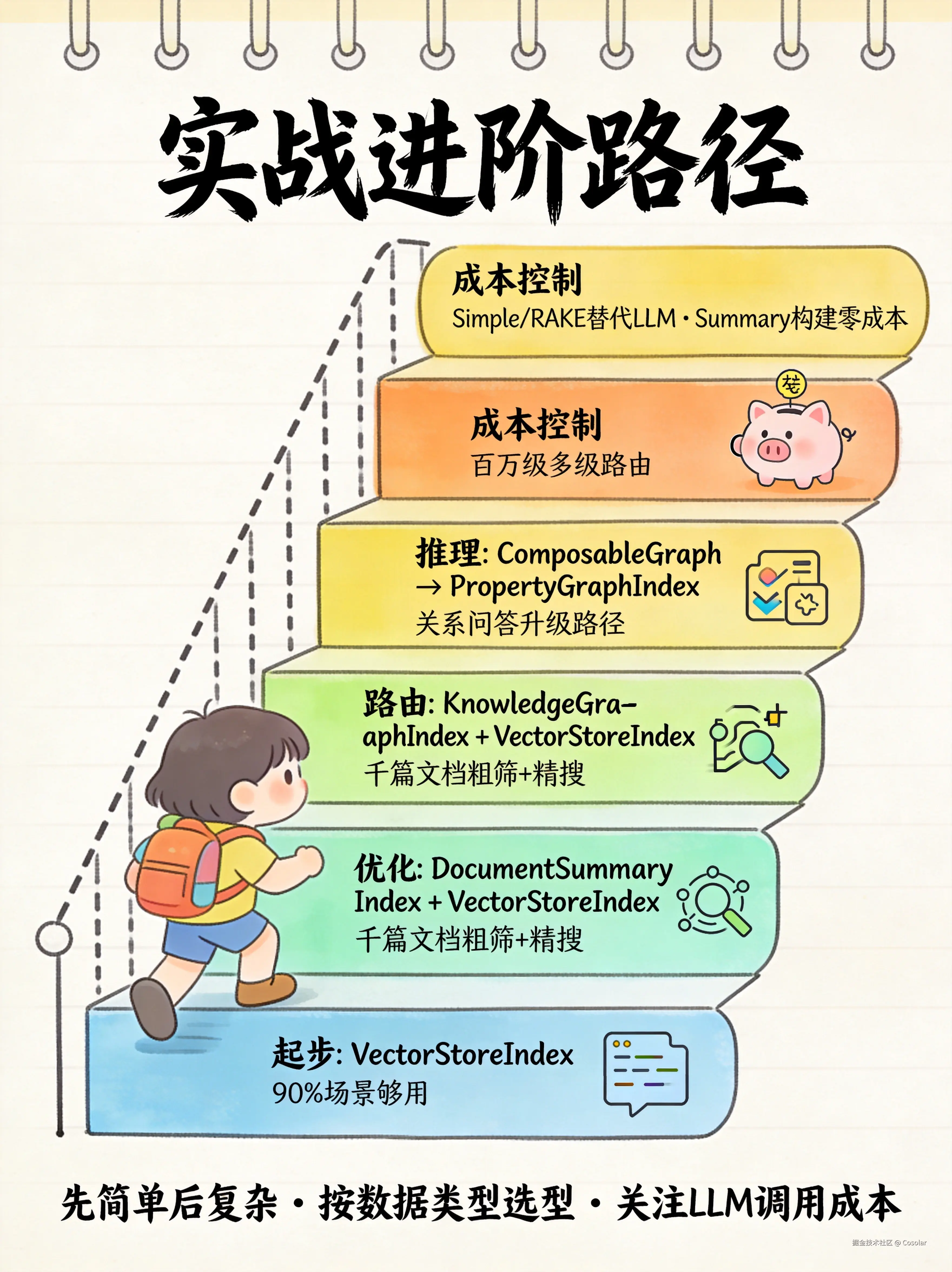
1. 起步阶段:先用 VectorStoreIndex
python
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("你的问题")2. 性能优化:DocumentSummaryIndex + VectorStoreIndex
当文档数量超过千篇时,先用 DocumentSummaryIndex 粗筛,再在匹配文档内用 VectorStoreIndex 精搜。
3. 关系推理:KnowledgeGraphIndex → PropertyGraphIndex
简单三元组关系用 KnowledgeGraphIndex;需要属性、Cypher 查询、多种检索策略时升级到 PropertyGraphIndex。
4. 大规模路由:ComposableGraph
百万级文档库,用 ComposableGraph 做多级路由:顶层 KeywordTableIndex 按分类路由,底层 VectorStoreIndex 做语义检索。
5. 成本控制
- 关键词索引用 Simple 或 RAKE 变体(无需 LLM 调用)
- SummaryIndex 构建零成本(不调用 LLM)
- TreeIndex 构建成本 O(N·log(N)),查询成本 O(log(N))
结语
LlamaIndex 的 14 种索引类型,覆盖了从简单到复杂、从文本到多模态、从非结构化到结构化的各种场景。选择索引的核心原则:
- 先简单后复杂:先用 VectorStoreIndex 验证流程,再根据痛点切换
- 按数据类型选型:表格用 PandasIndex,数据库用 SQLStructStoreIndex,图片用 MultiModalVectorStoreIndex
- 组合使用:通过 ComposableGraph 组合多种索引策略,扬长避短
- 关注成本:LLM 调用是主要成本来源,能用无 LLM 方案就别用有 LLM 的
希望本文能帮助你在 LlamaIndex 的索引生态中找到最适合你的那一款。