生成式任务的应用
图像领域: 图像/视频生成,图像补全
语音邻域: 语音合成等 TTS,又或者地铁上的广播
文本领域: 机器翻译等
seq2seq任务 (生成式任务的另一个简称)
输入输出均为不定长的序列
如:
机器翻译
机器作诗
自动摘要等
自回归语言模型训练的本质任务就是生成式任务
像豆包和deepseek的预训练用的就是自回归语言模型训练
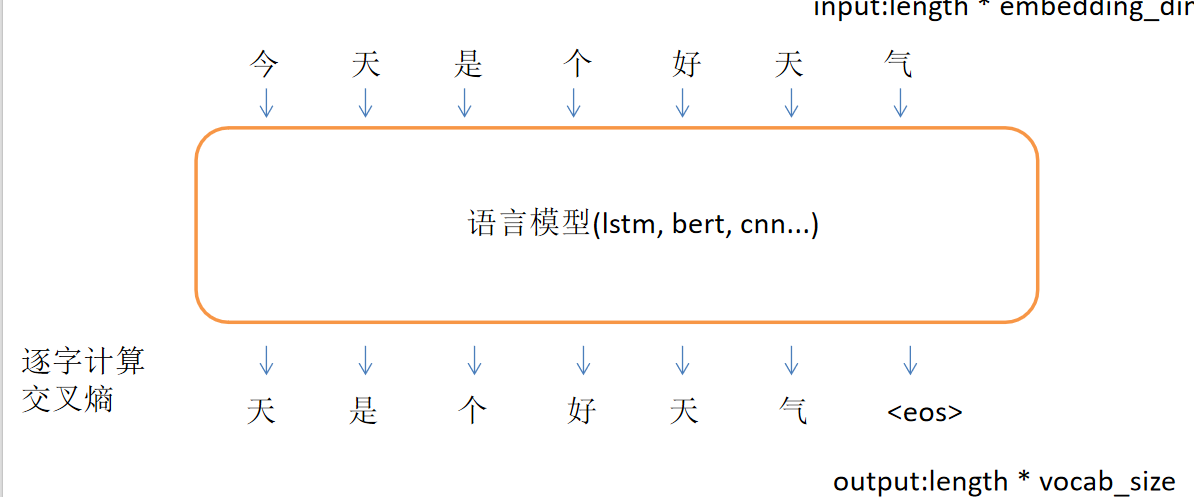
文本生成最基本的方法也是最常用的方法
基于语言模型和 一段引言,生成后后续文本
采样策略是干啥的? 如何从这个分布里选下一个token。
如果永远挑概率最大的(argmax / greedy):输出会非常确定、重复,缺乏多样性。同一个 prompt 每次生成的结果完全一样。
如果纯粹按概率随机采样:低概率的 token 也会偶尔被选中,可能引入语法错误或不合理的词。4
实际用的策略都是在"确定性"和"随机性"之间找平衡:
温度(Temperature):在 softmax 之前把 logits 除以温度值。温度 > 1 让分布更平坦(更随机),温度 < 1
让分布更尖锐(更确定)。
Top-k:只在概率最高的 k 个 token 里采样,直接砍掉尾部噪声。
Top-p(nucleus sampling):累加概率直到达到阈值 p,只在这组 token 里采样。相比 top-k更灵活,因为分布可能是"尖峰"或"扁平"的,top-p 能自适应。
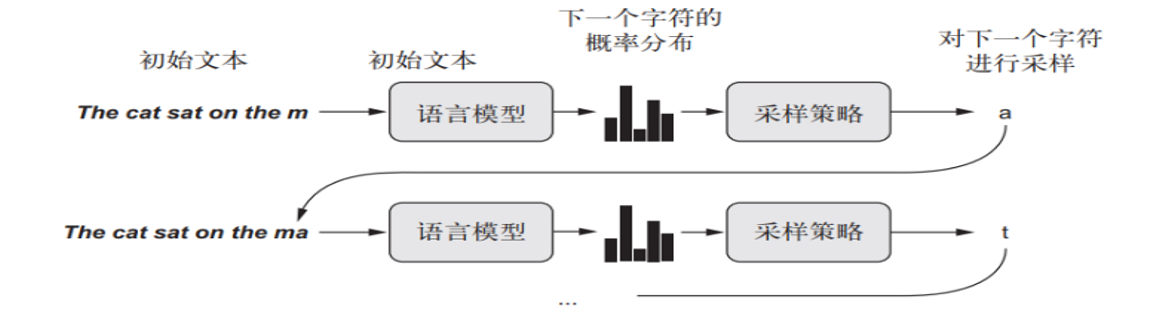
Encoder-Decoder 结构
Encoder - Decoder结构是一种基于神经网络完成seq2seq任务的常用方案
Encoder将输入转化为向量或矩阵,其中包含了输入中的信息
Decoder利用这些信息输出目标值
ENCODER和DECODER的词表是不一样的(LSTM时代)
后来,Transformer出现后,一开始就默认采用共享词表了
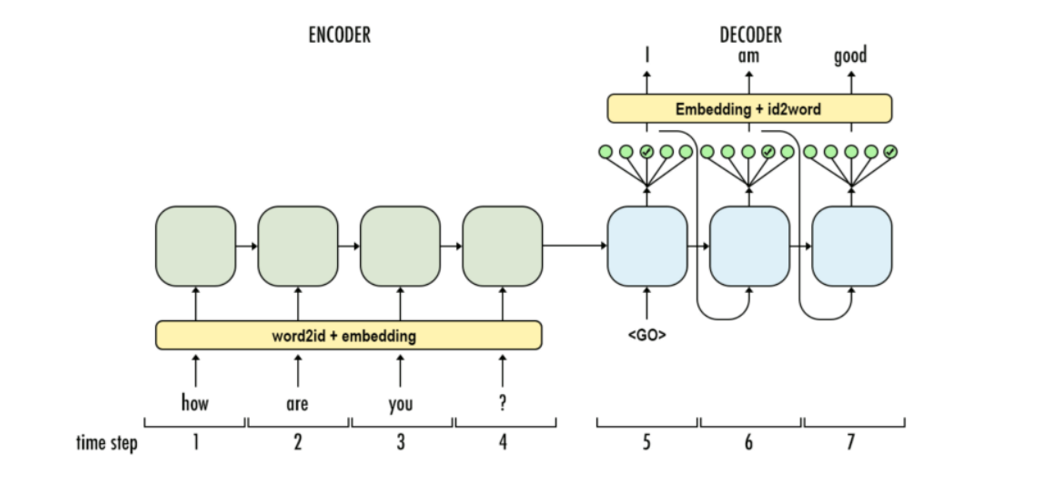
Attention机制(这个不是self-attention,这个是在Transformer结构出现之前就出现的)
e0知和e1识的英文是do(Knowledge),那我们怎么让这两个关系到一起的,就是通过Attention机制关系到一起,在Encoder和Decoder之间其实会有张量,e0和e1之间和do权重很高,而其他e2e3则很低
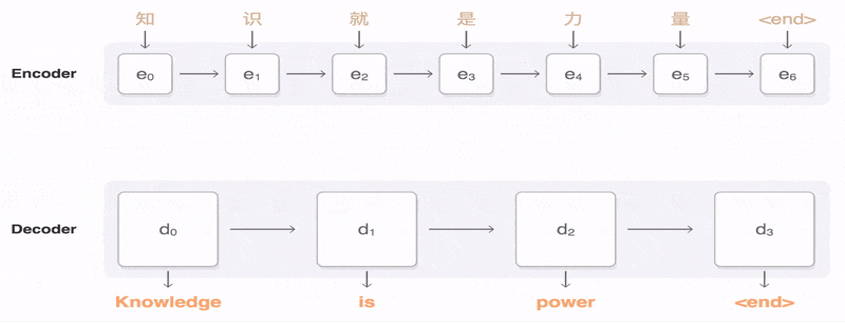

soft-attention
这里就类似于transformer里面的self-attention softmax(Q*K的转置/根号dk) *V
在生成式问题中,我们经常出现一个问题:
在训练过程,我们从一个输入,得到输出这个句子
s1: x1,x2,x3...xn,<sos> ------->y1 这里的y1有可能是错的
s2: x1,x2,x3...xn,<sos>,y1 ------->y2
s3:x1,x2,x3...xn,<sos>,y1,y2 ------->y3
红字部分使用真实标签,则称作teacher forcing
信息泄露问题,就是预测出的y1哪怕试错的,下次用y1的时候我们用的是正确的
自回归语言模型训练的时候也是这样训练的,但是也存在问题,就是双向LSTM和bert因为前文能看到后文,那么它们就可能学到输出这个字的下一字,就不再是预测了
那问题怎么解决,就是mask
在transformer中 q*kT 会得到L*L的矩阵,这也是bert能够做到前文看到后文的原因,那我们可以当矩阵 i<j的时候将它置成-inf即可
这里的0是做了近似处理的,因为是softmax不可能出现0这种情况


另外mask不止这一个用法还有其他用法
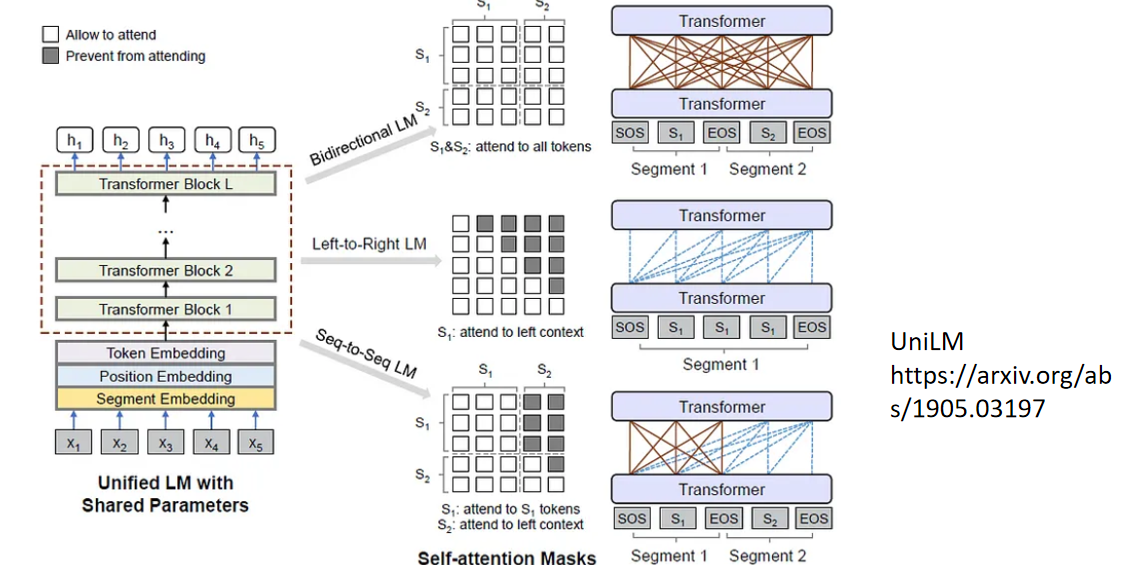
通过mask控制训练方式
第一种,完全不加mask
双向语言模型训练,bert
第二作种
单向语言模型训练
第三种
输入是个双向,输出是个单向,输入看不到输出,输入和输入可以计算attention,输出和输入,以及之前的字可以计算attention但不能计算之后的
常见的评价指标
一般生成式文本很难评价,因为把中文翻译成英文,答案并不唯一,不像分类任务,哪一类就是哪一类,类似的还有生成一篇文章。
BLEU公式是怎么计算的
P是啥?
比如 上面截图种 参考答案有很多种 就是那个reference,模型给出的答案就是candidate
P1就是 看this 上上面参考答案出现的次数,P2 就是 this is 在参考答案中出现的概率,P3则是 this is a P4则是 this is a test,n就是答案的长度
BP则是惩罚系数,如果文本长度低于reference预测长度的话,说明预测有问题
这个有弊端就是
如果模型给出个你,原文章是您,意思相同,但是P会降低

生成式模型有时会出现段落不断重复的现象,不够灵活变通

模型本质上是概率预测,假如A-B-C经常出现,那么由A生成B,由B生成C,那怎么避免这种现象
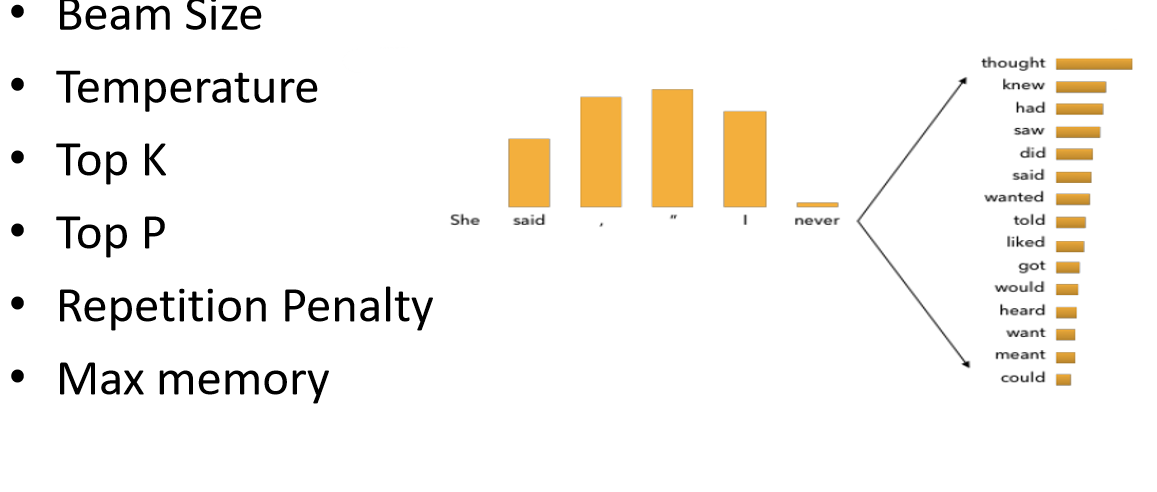
采样策略问题
因为模型本质上是概率预测,如图,由never预测下一个词的时候,会出现很多可选词的概率,在这里如果选概率最高的那个,就容易出现不断重复的问题,在这里我们可以选择其他的采样
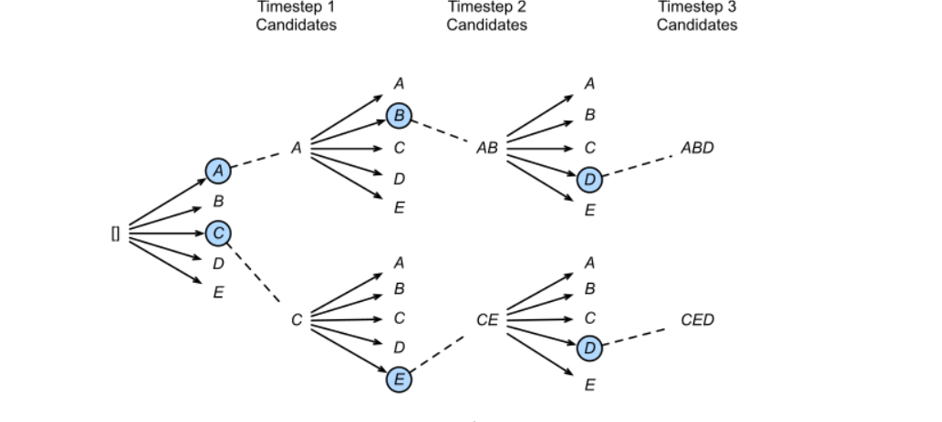
第一个就是Beam Size
Beam Search会提供多条路径选择
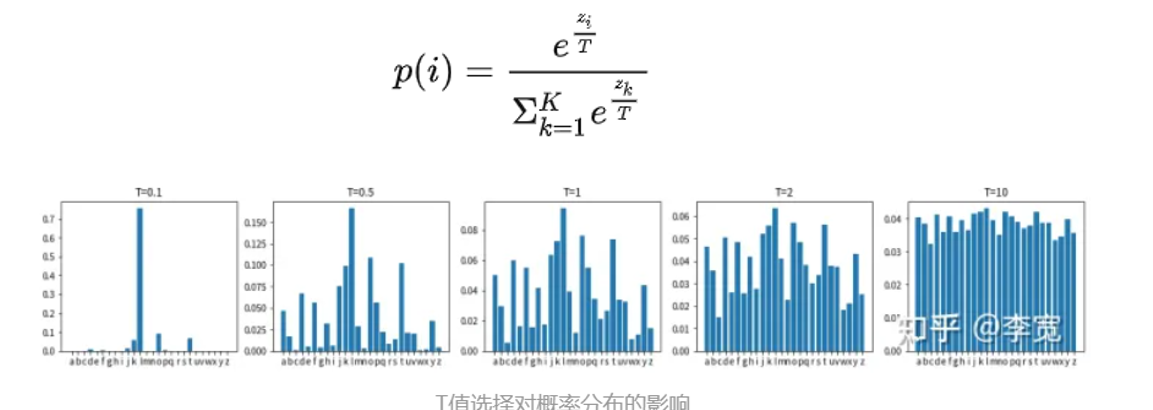
第二个就是 Temperature Sampling
输出每个字的概率分布时,通过参数T,对softmax部分作特殊处理temperature越大,结果越随机,反之则越固定 为啥?
在做softmax时是进行 e的x方,当T=1时就是正常的结果,可是当0<T<1的时候,x除以T之后会变大,e的指数函数会随着x的增大会变得更大,原来的差距只会越来越大,这样的话就会造成模型的选择更加确定,适合需要正确率
而当T>1的时候,T不能过大,T在适当大的时候,e的x方,在x小的时候值是相差较小的,那么x除以T之后,softmax就会更大可能出现概率分布差不多的情况,那么模型的选择就多了,适合一些对话类的
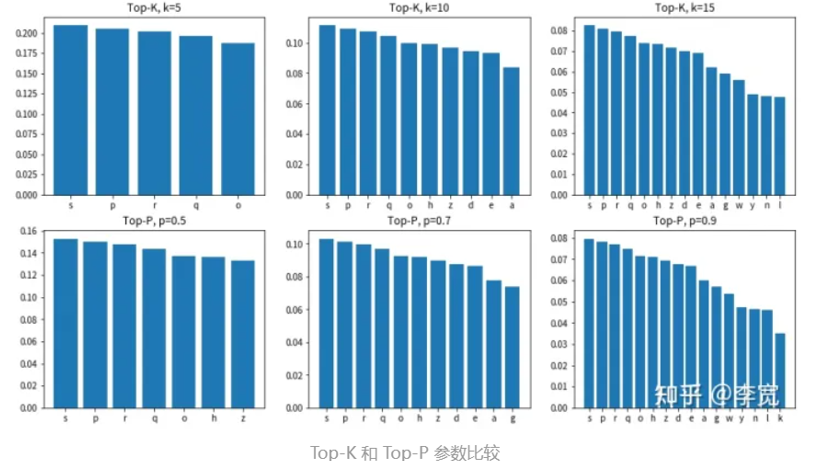
第三种 Top-P/Top-K
Top-k采样: 采样时从概率最高的k个字选择
Top-p采样(动态): 采样时,先按概率从高到低排序,从累加概率不超过P的范围内选择取值范围0-1
另外 Top-k或者Top-p + Beam Search 结合会好点,会减少很多的运算,Top-p和Top-k会先筛去点,然后BeamSearch再选
第四种 Repetition Penalty
用于限制语言模型输出的重复内容,我们根据前四个字预测第五个词时,会出现许多词的概率选择,我们会调整前4个词的概率,让他们降低,避免重复出现,这样问题也有了,就是比如像的这个词,一句话就可能经常出现
第五种 Max memory(不常用)
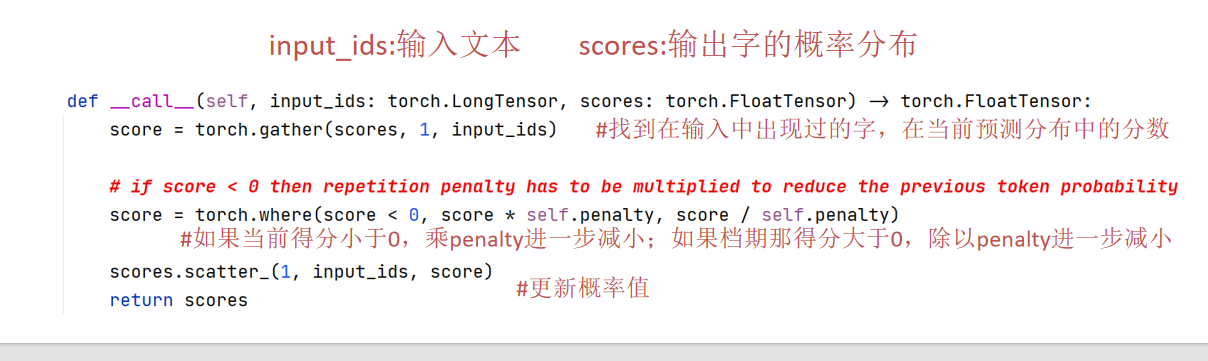

指针网络 pointer-network(曾经特殊的做法)
适合做摘要的任务,会把之前出现过的字的概率提高
输出的字一定来源于输入
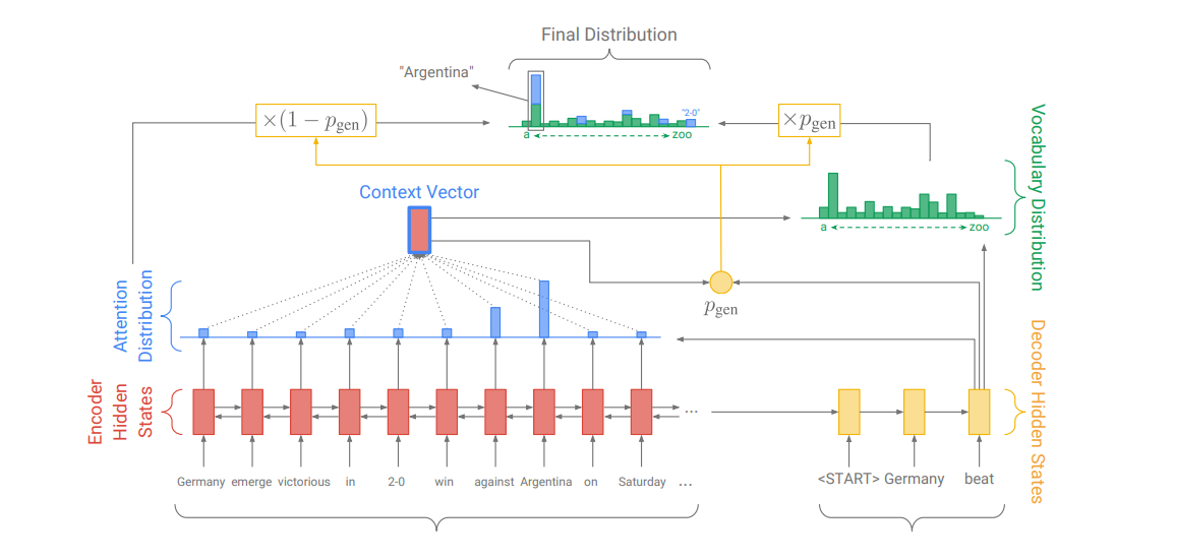
基于seq2seq预训练
基于seq2seq也可进行模型预训练
bert是一个encoder
seq2seq训练可以得到encoder+decoder
代表:T5 (谷歌20年提出的)