本文部分内容AI辅助生成,请谨慎参考
企业在使用Redshift过程中,常会遇到硬件升级效果无法预判、dc2向ra3集群迁移性能未知、节点类型与数量难以合理规划、难以筛选高性价比配置等问题,而传统评估方式存在测试数据脱离真实业务场景、手动执行SQL效率低下、无法还原真实请求时间间隔与并发量、性能对比难以量化的局限。
Amazon Redshift Test Drive 是一套开源的工具集,专门用于帮助客户在 Amazon Redshift 数据仓库环境中进行如下工作
- 工作负载复制:从生产环境提取真实工作负载
- 性能测试:在不同配置上重放工作负载
- 性能对比:评估不同节点类型和配置的性能
- 容量规划:选择最优的集群配置
其中,工作负载重放则可依托生产环境真实查询,保留原始执行时间间隔,实现自动化可重复执行,并输出详尽的性能对比报告。
本文测试的场景为从源集群redshift-cluster-1 (ra3.xlplus, 2节点)提取业务负载并在目标集群redshift-cluster-2 (ra3.4xlarge, 2节点)重放,从而评估从 ra3.xlplus 升级到 ra3.4xlarge 的性能提升。示意图如下
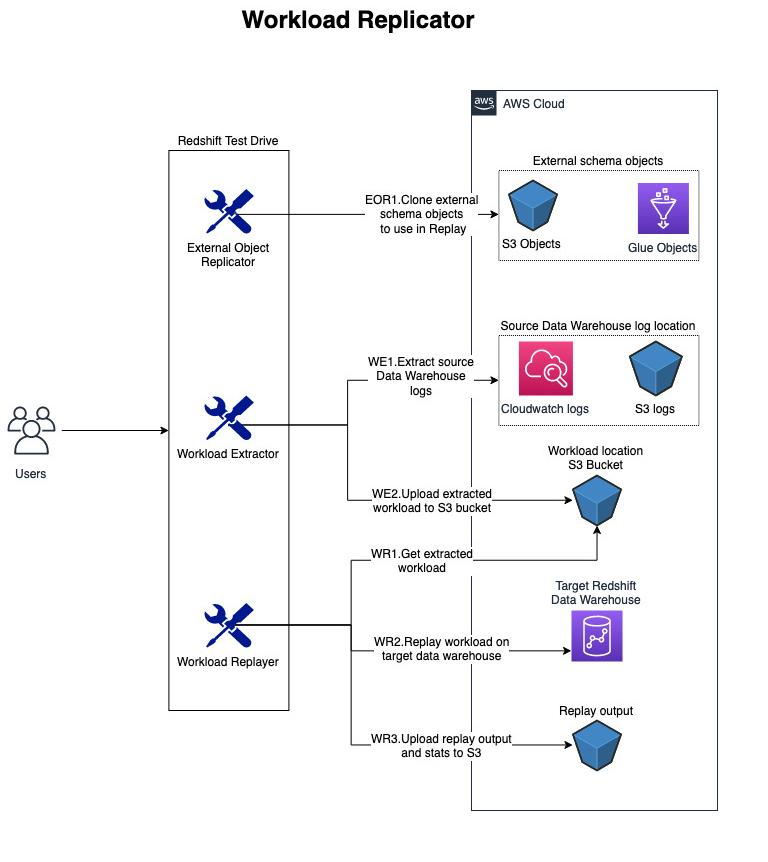
Redshift Test Drive的核心组件如下
Redshift Test Drive
├── Workload Replicator(工作负载复制器)
│ ├── Extract(提取器)
│ └── Replay(重放器)
├── Replay Analysis(重放分析工具)
├── External Object Replicator(外部对象复制器)
└── Node Configuration Compare(节点配置比较工具)工作原理
需要提前在源集群中启用审计日志和用户活动日志 (User Activity Logs)。
用户角色权限如下
- redshift:GetClusterCredentials
- redshift:DescribeClusters
- logs:FilterLogEvents (CloudWatch)
- s3:GetObject / s3:PutObject (工作负载文件)
- secretsmanager:GetSecretValue (可选)
redshfit集群角色权限如下
- s3:PutObject (UNLOAD 到 S3)
- s3:GetObject (COPY 从 S3)
Extract(提取)阶段
通过 boto3 库读取 CloudWatch Logs 日志数据,借助 redshift_connector 实现与 Redshift 数据库的连接,对 JSON 格式的审计日志进行结构化解析,并使用 gzip 压缩技术有效降低数据存储占用。
步骤1
步骤2
步骤3
步骤4
源集群
数据提取模块
从 CloudWatch/S3 读取审计日志
连接源集群获取系统表数据
解析 SQL 查询和连接信息
导出系统表到 S3
S3 存储路径:extracted-workload/
SQLs.json.gz
(压缩的查询)
connections.json
(连接信息)
copy_replacements.csv
(COPY位置)
extract_logs.zip
(日志)
提取阶段数据流
1. CloudWatch Logs (审计日志)
↓
2. Python 脚本 (使用用户 IAM 凭证)
↓
3. S3: extracted-workload/ (使用用户 IAM 凭证)
↓
4. 源集群 UNLOAD 系统表 (使用集群的 IAM 角色)
↓
5. S3: system-tables/Replay(重放)阶段
使用 Python concurrent.futures多线程执行
1
2
3
4
5
6
S3:extracted-workload/
查询重放模块
下载工作负载文件
连接到目标集群
按时间顺序重放查询
保持原始时间间隔
导出目标集群系统表
生成分析数据
目标集群
S3:replay-output/
S3:analysis/
重放阶段数据流
1. S3: extracted-workload/ (使用用户 IAM 凭证)
↓
2. 目标集群执行查询 (使用集群的 IAM 角色)
↓
3. S3: replay-output/ (使用集群的 IAM 角色)
↓
4. S3: analysis/ (使用集群的 IAM 角色)
↓
5. Replay Analysis Web UI (使用用户 IAM 凭证)环境准备
克隆仓库
bash
git clone https://github.com/aws/redshift-test-drive.git
cd redshift-test-drive/
export REDSHIFT_TEST_DRIVE_ROOT=$(pwd)创建虚拟环境
bash
python3 -m venv testDriveEnv
source testDriveEnv/bin/activate安装依赖
bash
cd $REDSHIFT_TEST_DRIVE_ROOT && make setup源集群配置
启用审计日志
sql
aws redshift enable-logging \
--cluster-identifier redshift-cluster-1 \
--bucket-name your-audit-log-bucket \
--region cn-northwest-1启用用户活动日志
sql
ALTER PARAMETER GROUP enable_user_activity_logging SET true;附加 IAM 角色
bash
aws redshift modify-cluster-iam-roles \
--cluster-identifier redshift-cluster-1 \
--iam-roles-ToAdd arn:aws-cn:iam::<accountid>:role/redshift-role \
--region cn-northwest-1创建快照
bash
aws redshift create-snapshot \
--cluster-identifier redshift-cluster-1 \
--snapshot-identifier before-workload-capture \
--region cn-northwest-1目标集群配置
从快照恢复
bash
aws redshift restore-from-cluster-snapshot \
--cluster-identifier redshift-cluster-2 \
--snapshot-identifier before-workload-capture \
--node-type ra3.4xlarge \
--number-of-nodes 2 \
--region cn-northwest-1附加相同的 IAM 角色
bash
aws redshift modify-cluster-iam-roles \
--cluster-identifier redshift-cluster-2 \
--iam-roles-ToAdd arn:aws-cn:iam::<accountid>:role/redshift-role \
--region cn-northwest-1配置详解
extract.yaml 配置
yaml
# 【必需】提取的工作负载保存位置(S3 或本地目录)
workload_location: "s3://redshift-test-drive-<username>-20260514-001/extracted-workload"
# 【可选】源集群 endpoint
# 提供后可以:
# - 自动获取审计日志位置
# - 从系统表获取精确的查询时间
source_cluster_endpoint: "redshift-cluster-1.xxxxxxxxxxx.cn-northwest-1.redshift.amazonaws.com.cn:5439/dev"
# 【必需,如果提供了 source_cluster_endpoint】主用户名
master_username: "awsuser"
# 【必需】区域
region: "cn-northwest-1"
# 【必需】提取的时间范围(ISO 8601 格式)
start_time: "2026-05-14T07:00:00+00:00"
end_time: "2026-05-14T07:10:00+00:00"
# 【可选】COPY 命令的 S3 替换位置和 IAM 角色
replacement_copy_location: ""
replacement_iam_location: ""
# 【可选】ODBC 驱动(留空使用 Python driver)
odbc_driver: ""
# 【可选】审计日志位置
# 留空则自动从源集群获取,或指定本地/S3位置
log_location: ""
# 【可选】系统表 UNLOAD SQL 文件位置
unload_system_table_queries: "core/replay/unload_system_tables.sql"
# 【可选】系统表导出的 S3 位置
source_cluster_system_table_unload_location: "s3://redshift-test-drive-<username>-20260514-001/system-tables"
# 【必需,如果要导出系统表】UNLOAD 使用的 IAM 角色
# 这个角色必须与集群在同一账户
source_cluster_system_table_unload_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"
log_level: "info"
backup_count: 1
external_schemas: []replay.yaml 配置
yaml
# 【可选】自定义标识符
tag: "test-replay-10min"
# 【必需】提取的工作负载位置
workload_location: "s3://redshift-test-drive-<username>-20260514-001/extracted-workload/Extraction_redshift-cluster-1_2026-05-14T07:20:10.211896+00:00"
# 【必需】目标集群 endpoint
target_cluster_endpoint: "redshift-cluster-2.xxxxxxxxxxx.cn-northwest-1.redshift.amazonaws.com.cn:5439/dev"
target_cluster_region: "cn-northwest-1"
master_username: "awsuser"
# 【可选】NLB/NAT endpoint(用于跨 VPC 访问)
nlb_nat_dns: ""
# 【可选】ODBC 驱动
odbc_driver: ""
# 【必需】默认接口
default_interface: "psql"
# 【可选】时间间隔控制
# "all on" = 保持原始时间间隔
# "all off" = 尽快执行(批量模式)
time_interval_between_transactions: ""
time_interval_between_queries: ""
# 【必需】是否执行 COPY 语句
execute_copy_statements: "true"
# 【必需】是否执行 UNLOAD 语句
execute_unload_statements: "true"
# 【必需】重放输出位置
replay_output: "s3://redshift-test-drive-<username>-20260514-001/replay-output"
# 【必需】分析输出位置
analysis_output: "s3://redshift-test-drive-<username>-20260514-001/analysis"
# 【必需】UNLOAD IAM 角色
unload_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"
# 【必需】分析 IAM 角色
analysis_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"
# 【可选】系统表 UNLOAD SQL 文件
unload_system_table_queries: "core/replay/unload_system_tables.sql"
# 【必需】目标集群系统表 UNLOAD IAM 角色
target_cluster_system_table_unload_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"
# ============================================================
# 过滤器配置
# ============================================================
filters:
include:
database_name: ['']
username: ['']
pid: ['']
exclude:
database_name: []
username: []
pid: []
# 高级配置
log_level: "DEBUG"
num_workers: ~
connection_tolerance_sec: 300
backup_count: 1
drop_return: true
limit_concurrent_connections: ~
split_multi: true
secret_name: ""执行流程
激活虚拟环境
bash
cd /home/<username>/redshift-test-drive-main
source testDriveEnv/bin/activate创建 S3 存储桶
bash
aws s3 mb s3://redshift-test-drive-<username>-20260514-001 \
--region cn-northwest-1编辑 extract.yaml关键配置项:
yaml
workload_location: "s3://redshift-test-drive-<username>-20260514-001/extracted-workload"
source_cluster_endpoint: "redshift-cluster-1.xxxxxxxxxxx.cn-northwest-1.redshift.amazonaws.com.cn:5439/dev"
region: "cn-northwest-1"
start_time: "2026-05-14T07:00:00+00:00"
end_time: "2026-05-14T07:10:00+00:00"
source_cluster_system_table_unload_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"编辑 replay.yaml关键配置项
yaml
tag: "test-replay-10min"
workload_location: "s3://redshift-test-drive-<username>-20260514-001/extracted-workload/Extraction_redshift-cluster-1_2026-05-14T07:20:10.211896+00:00"
target_cluster_endpoint: "redshift-cluster-2.xxxxxxxxxxx.cn-northwest-1.redshift.amazonaws.com.cn:5439/dev"
target_cluster_region: "cn-northwest-1"
execute_copy_statements: "true"
execute_unload_statements: "true"
replay_output: "s3://redshift-test-drive-<username>-20260514-001/replay-output"
analysis_output: "s3://redshift-test-drive-<username>-20260514-001/analysis"
unload_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"
analysis_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"
target_cluster_system_table_unload_iam_role: "arn:aws-cn:iam::<accountid>:role/redshift-role"执行提取
bash
make extract
output:
([INFO] ...): Starting the extract
([INFO] ...): Extract ID: 2026-05-14T07:20:10..._redshift-cluster-1_c1c26
([INFO] ...): Time range: 2026-05-14 07:00:00+00:00 to 2026-05-14 07:10:00+00:00
([INFO] ...): Extracting logs from source cluster endpoint...
([INFO] ...): Parsing connection logs...
([INFO] ...): Parsing user activity logs...
([INFO] ...): Retrieving info from redshift-cluster-1...
([INFO] ...): Exporting system tables to S3...
([INFO] ...): Uploading extract logs...
([INFO] ...): Extract completed in 0:00:33.474105验证提取结果
bash
aws s3 ls s3://redshift-test-drive-<username>-20260514-001/extracted-workload/ \
--recursive --region cn-northwest-1预期文件:
2026-05-14 07:20:44 6336 extracted-workload/Extraction_.../SQLs.json.gz
2026-05-14 07:20:44 6481 extracted-workload/Extraction_.../connections.json
2026-05-14 07:20:44 60 extracted-workload/Extraction_.../copy_replacements.csv
2026-05-14 07:20:44 1205 extracted-workload/Extraction_.../extract_logs.zip执行重放
bash
make replay
output:
([INFO] ...): Starting the replay
([INFO] ...): Replay ID: 2026-05-14T07:21:23..._redshift-cluster-2_test-replay-10min_52ec8
([INFO] ...): Downloading workload files...
([INFO] ...): Parsing connections...
([INFO] ...): Parsing transactions...
([INFO] ...): Preparing target cluster...
([INFO] ...): Starting replay...
([INFO] ...): Progress: 10% (5/50 queries)
([INFO] ...): Progress: 50% (25/50 queries)
([INFO] ...): Progress: 100% (50/50 queries)
([INFO] ...): Exporting system tables from target cluster...
([INFO] ...): Generating analysis data...
([INFO] ...): Uploading analysis files to S3...
([INFO] ...): Replay completed in 0:15:23.123456
([INFO] ...): Summary:
Total queries: 50
Successful: 48
Failed: 2
Duration: 15:23分析结果
bash
aws s3 ls s3://redshift-test-drive-<username>-20260514-001/replay-output/ \
--recursive --region cn-northwest-1
aws s3 ls s3://redshift-test-drive-<username>-20260514-001/analysis/ \
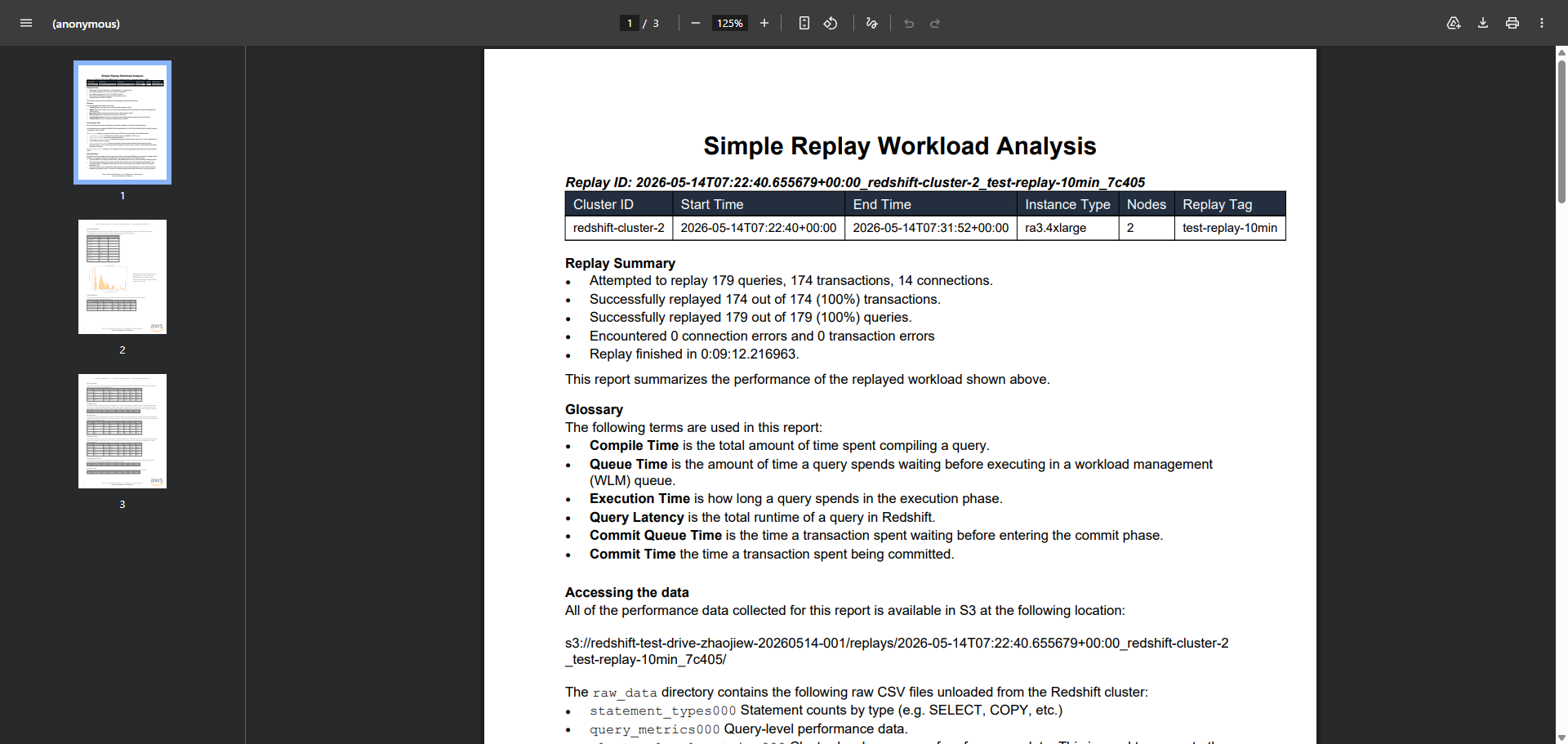
--recursive --region cn-northwest-1最终的重放报告如下
参考资料