
上一篇我们掌握了文件系统的三大核心抽象:块(文件系统最小存取单位)、分区(磁盘逻辑载体)、inode(文件属性仓库),这三个概念让磁盘从 "裸硬件" 具备了存储文件的基础条件。但新的问题随之而来:在一个几十 GB 甚至上百 GB 的分区中,如何高效组织这些块和 inode?inode 又是如何精准指向存储文件内容的数据块?小文件和大文件的存储方式有何不同?
答案就藏在 Linux 最经典的Ext 系列文件系统 中 ------Ext2、Ext3、Ext4 作为 Linux 原生的文件系统,是块、分区、inode 三大抽象的完美落地实现,其中 Ext2 是基础核心,Ext3 和 Ext4 在其之上做了功能增强,核心的底层结构完全不变 。这篇我们就以 Ext2 为核心,拆解 Ext 系列文件系统的整体架构,讲清块组的设计逻辑、块组内部七大核心组件的作用,重点解析inode 与数据块的映射机制,并揭开 "目录也是文件" 的底层本质,让你彻底看懂 Linux 文件系统如何管理文件的属性和内容。
文章目录
-
- [一、Ext 文件系统整体架构:分区→块组(Block Group)的分治思想](#一、Ext 文件系统整体架构:分区→块组(Block Group)的分治思想)
-
- [1.1 块组的设计目的与核心特性](#1.1 块组的设计目的与核心特性)
-
- [1.1.1 核心设计目的](#1.1.1 核心设计目的)
- [1.1.2 核心特性](#1.1.2 核心特性)
- [1.2 Ext2/Ext3/Ext4 的演进与核心区别](#1.2 Ext2/Ext3/Ext4 的演进与核心区别)
- [1.3 块组的整体布局](#1.3 块组的整体布局)
- 二、块组内部七大核心组件拆解:从元数据到数据块
-
- [2.1 启动块(Boot Block):固定的引导区域](#2.1 启动块(Boot Block):固定的引导区域)
- [2.2 超级块(Super Block):文件系统的 "总控制台"](#2.2 超级块(Super Block):文件系统的 “总控制台”)
-
- [2.2.1 超级块存储的核心信息](#2.2.1 超级块存储的核心信息)
- [2.2.2 超级块的多份备份:防止单点故障](#2.2.2 超级块的多份备份:防止单点故障)
- [2.3 GDT(Group Descriptor Table):块组的 "信息索引卡"](#2.3 GDT(Group Descriptor Table):块组的 “信息索引卡”)
-
- [GDT 存储的核心信息(单个组描述符)](#GDT 存储的核心信息(单个组描述符))
- [GDT 的备份特性](#GDT 的备份特性)
- [2.4 块位图(Block Bitmap):数据块的 "使用状态清单"](#2.4 块位图(Block Bitmap):数据块的 “使用状态清单”)
- [2.5 inode 位图(inode Bitmap):inode 的 "使用状态清单"](#2.5 inode 位图(inode Bitmap):inode 的 “使用状态清单”)
-
- [inode 位图的工作原理](#inode 位图的工作原理)
- [2.6 inode 表(inode Table):文件的 "属性仓库集合"](#2.6 inode 表(inode Table):文件的 “属性仓库集合”)
-
- [inode 表的核心特性](#inode 表的核心特性)
- [关键要点:inode 表与文件的关联](#关键要点:inode 表与文件的关联)
- [2.7 数据块(Data Blocks):文件的 "实际内容存储区域"](#2.7 数据块(Data Blocks):文件的 “实际内容存储区域”)
- [三、核心重点:inode 与数据块的映射机制(直接块 + 间接块)](#三、核心重点:inode 与数据块的映射机制(直接块 + 间接块))
-
- [3.1 核心基础:i_block 数组与块号的作用](#3.1 核心基础:i_block 数组与块号的作用)
- [3.2 四层映射结构:12 直接 + 1 一级 + 1 二级 + 1 三级](#3.2 四层映射结构:12 直接 + 1 一级 + 1 二级 + 1 三级)
-
- [3.2.1 第一层:12 个直接块(i_block 0 ~ i_block 11)](#3.2.1 第一层:12 个直接块(i_block [0] ~ i_block [11]))
- [3.2.2 第二层:1 个一级间接块(i_block 12)](#3.2.2 第二层:1 个一级间接块(i_block [12]))
- [3.2.3 第三层:1 个二级间接块(i_block 13)](#3.2.3 第三层:1 个二级间接块(i_block [13]))
- [3.2.4 第四层:1 个三级间接块(i_block 14)](#3.2.4 第四层:1 个三级间接块(i_block [14]))
- [3.3 不同大小文件的映射实例](#3.3 不同大小文件的映射实例)
- [3.4 该设计的核心优势](#3.4 该设计的核心优势)
- 四、目录的本质:存储「文件名:inode」映射的特殊文件
-
- [4.1 目录的文件属性:与普通文件一致](#4.1 目录的文件属性:与普通文件一致)
- [4.2 目录的数据块:存储「文件名:inode」的映射关系](#4.2 目录的数据块:存储「文件名:inode」的映射关系)
- [4.3 特殊的目录项:. 和 ..](#4.3 特殊的目录项:. 和 ..)
- [4.4 目录的存储优化:Ext4 的 HTree 索引](#4.4 目录的存储优化:Ext4 的 HTree 索引)
- [五、实战:解析 Ext 文件系统的核心信息与格式化本质](#五、实战:解析 Ext 文件系统的核心信息与格式化本质)
-
- [5.1 实战 1:dumpe2fs ------ 查看 Ext 文件系统的核心元数据](#5.1 实战 1:dumpe2fs —— 查看 Ext 文件系统的核心元数据)
- [5.2 实战 2:mkfs.ext4 ------ 格式化创建 Ext4 文件系统](#5.2 实战 2:mkfs.ext4 —— 格式化创建 Ext4 文件系统)
- [5.3 核心本质 1:Ext 文件系统格式化的本质](#5.3 核心本质 1:Ext 文件系统格式化的本质)
- [5.4 核心本质 2:Ext 文件系统删除文件的本质](#5.4 核心本质 2:Ext 文件系统删除文件的本质)
- [六、常见坑 & 避坑指南](#六、常见坑 & 避坑指南)
-
- [误区 1:Ext2/3/4 的核心底层结构不同](#误区 1:Ext2/3/4 的核心底层结构不同)
- [误区 2:超级块只有一份,存储在块组 0](#误区 2:超级块只有一份,存储在块组 0)
- [误区 3:inode 的 15 个 i_block 元素都直接指向数据块](#误区 3:inode 的 15 个 i_block 元素都直接指向数据块)
- [误区 4:目录是特殊的硬件结构,不是文件](#误区 4:目录是特殊的硬件结构,不是文件)
- [5. 误区 5:格式化会彻底删除分区中的所有数据](#5. 误区 5:格式化会彻底删除分区中的所有数据)
- [误区 6:块位图和 inode 位图的标记规则相反](#误区 6:块位图和 inode 位图的标记规则相反)
- [误区 7:Ext 文件系统的 inode 总数固定,无法修改](#误区 7:Ext 文件系统的 inode 总数固定,无法修改)
- 七、总结与下一篇预告
一、Ext 文件系统整体架构:分区→块组(Block Group)的分治思想
如果把一个 Ext 文件系统的分区比作一座大型图书馆,那么直接对整个分区的块和 inode 进行管理,就像图书馆没有分区,所有书籍杂乱堆放在一起,找书和管理的效率极低。Ext 文件系统采用了 "分而治之"的核心设计思想,将整个分区划分为多个大小相等的块组(Block Group),每个块组包含独立的管理元数据和数据存储区域,管理一个块组就可以复用到所有块组,大幅降低了大分区的管理复杂度。
1.1 块组的设计目的与核心特性
1.1.1 核心设计目的
- 降低管理复杂度:将大分区拆分为多个小的块组,每个块组的元数据(超级块、GDT、位图等)独立管理,避免单份元数据管理海量块和 inode 的性能瓶颈;
- 提升 IO 局部性:文件的 inode 和对应的数据块会尽量分配在同一个块组中,磁头无需跨块组频繁移动,提升文件的读写效率;
- 故障隔离:单个块组的元数据损坏,不会影响其他块组的正常使用,降低了整个文件系统崩溃的风险。
1.1.2 核心特性
- 大小均等 :同一个分区内的所有块组大小完全相同,块组的大小由文件系统的块大小 和每个块组的块数决定(默认每个块组包含 8192 个块);
- 结构一致:所有块组的内部组件完全相同,均包含启动块、超级块、GDT、块位图、inode 位图、inode 表、数据块七大核心部分;
- 独立管理:每个块组有自己的位图(标记块和 inode 的使用状态)、inode 表和数据块,可独立进行块和 inode 的分配与释放。
1.2 Ext2/Ext3/Ext4 的演进与核心区别
Ext 系列文件系统的发展是一个 "兼容增强、性能优化" 的过程,Ext2 是基础,Ext3 和 Ext4 均基于 Ext2 的块组架构开发,核心的底层结构(块组、inode、数据块映射)完全不变,仅在功能上做了补充和优化。我们用一张表格清晰区分三者的核心差异,让你快速掌握其适用场景:
| 特性 / 版本 | Ext2 | Ext3 | Ext4 |
|---|---|---|---|
| 核心架构 | 块组架构,无日志 | 基于 Ext2,增加日志功能 | 基于 Ext3,深度性能优化 |
| 日志功能 | 无 | 有(日志式文件系统) | 有(支持日志校验、延迟分配) |
| 最大文件大小 | 2TB | 16TB | 16TB-1EB(依块大小而定) |
| 最大分区大小 | 32TB | 16TB | 1EB |
| 最大 inode 数量 | 无硬限(依分区大小) | 同 Ext2 | 支持无限 inode(动态分配) |
| 目录存储 | 线性存储(查找慢) | 同 Ext2 | 支持 HTree 索引(大目录查找快) |
| 块分配 | 连续块分配(简单) | 同 Ext2 | 支持延迟分配、多块预分配 |
| 兼容性 | 无日志,与 Ext3/4 双向兼容 | 向下兼容 Ext2,向上兼容 Ext4 | 向下兼容 Ext2/3(需格式化时指定) |
| 适用场景 | 临时存储、嵌入式设备(无需日志) | 通用服务器、个人主机(追求稳定性) | 高性能服务器、大数据存储(追求高 IO) |
补充:日志功能的核心作用
Ext2 没有日志功能,若发生突然断电、系统崩溃,文件系统的元数据可能处于不一致状态,恢复时需要扫描整个分区,耗时极长;Ext3 引入日志(Journal),将元数据的修改先写入日志,再写入实际分区,崩溃后只需恢复日志,大幅提升恢复速度,这也是 Ext3 取代 Ext2 成为主流的核心原因。Ext4 对日志做了进一步优化,支持日志校验、延迟分配,让性能和稳定性更优。
1.3 块组的整体布局
一个 Ext2 文件系统分区的整体布局遵循 **"启动块 + 块组 0 + 块组 1+...+ 块组 N"的结构,其中块组 0 是核心 **,包含完整的超级块和 GDT,后续块组会按需备份超级块和 GDT,所有块组的内部布局一致,简化为:
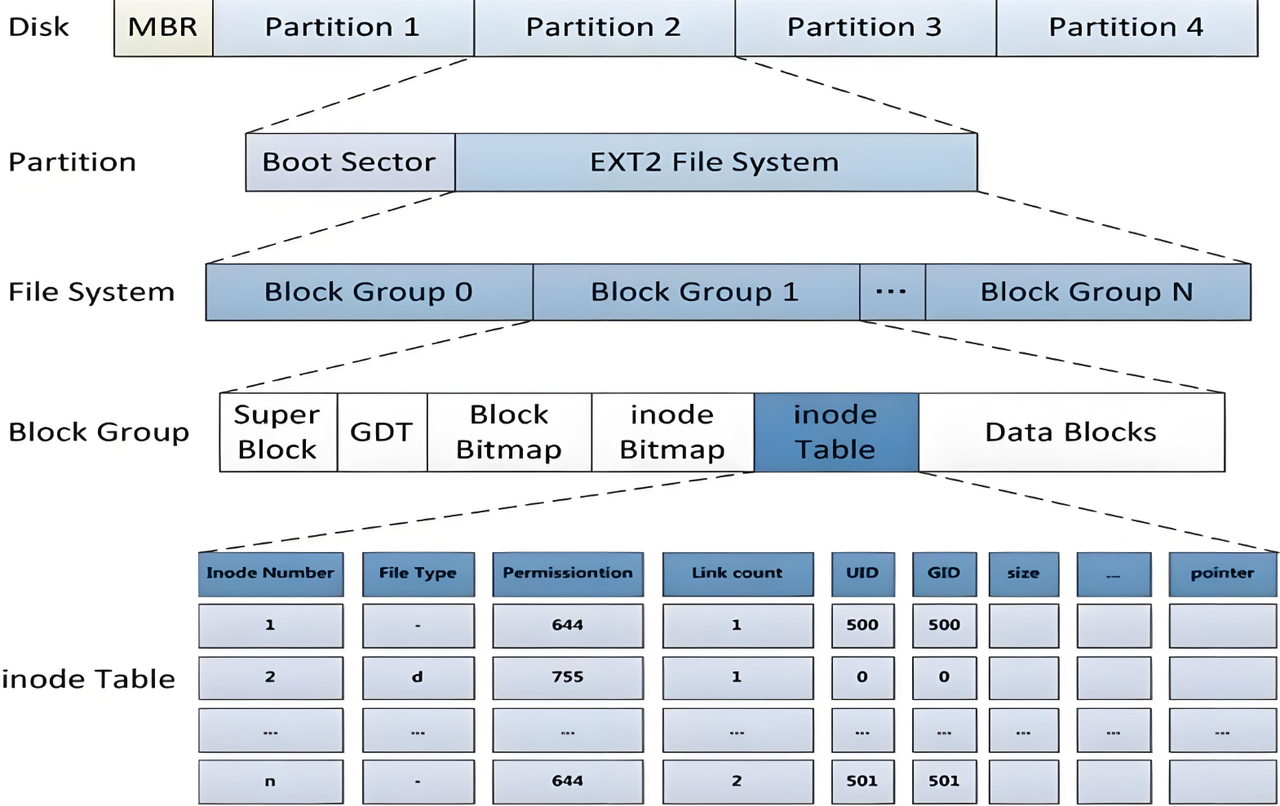
[启动块] → [超级块] → [GDT组描述符表] → [块位图] → [inode位图] → [inode表] → [数据块]所有块组按此布局依次排列,构成整个 Ext 文件系统的分区,这也是我们后续拆解块组内部组件的基础。
二、块组内部七大核心组件拆解:从元数据到数据块
块组是 Ext 文件系统的最小管理单位,其内部的七大核心组件分为元数据组件 和数据存储组件 两类:超级块、GDT、块位图、inode 位图、inode 表为元数据组件 ,负责文件系统的管理;数据块为数据存储组件 ,负责存储文件的实际内容;启动块为引导组件,负责系统启动。每个组件分工明确,协同完成文件的存储和管理,我们逐个拆解其核心作用、特性和工作原理。
2.1 启动块(Boot Block):固定的引导区域
启动块是 Ext 文件系统分区的第一个块 ,大小为固定的 1KB ,由 PC 硬件标准规定,不属于任何块组,也无法被文件系统修改。
- 核心作用:存储磁盘的分区信息和系统的引导程序(如 GRUB),当计算机启动时,BIOS 会读取该块的引导程序,完成系统的引导加载;
- 关键特性:所有 Ext 系列文件系统的启动块结构和大小完全相同,即使分区未格式化,启动块也依然存在;
- 实操要点:若启动块损坏,磁盘将无法被 BIOS 识别,系统无法启动,需通过引导修复工具(如 grub-install)恢复。
2.2 超级块(Super Block):文件系统的 "总控制台"
超级块是 Ext 文件系统的核心元数据 ,相当于整个文件系统的 "总控制台" 和 "身份信息卡",存储了文件系统的全局基础信息 ,是文件系统能否正常识别的关键 ------超级块损坏,整个文件系统将无法使用。
2.2.1 超级块存储的核心信息
超级块的大小为 1 个块(默认 4KB),存储的信息涵盖文件系统的所有全局参数,核心分为四类:
- 基础参数:文件系统的块大小、inode 大小、每个块组的块数、每个块组的 inode 数;
- 资源统计:分区的总块数、总 inode 数、空闲块数、空闲 inode 数、已使用的目录数;
- 时间戳:文件系统的创建时间、最近一次挂载时间、最近一次写入时间、最近一次磁盘检查时间;
- 状态与配置:文件系统的状态(干净 / 脏)、错误处理方式、挂载次数、最大挂载次数(达到后自动检查)。
2.2.2 超级块的多份备份:防止单点故障
这是超级块最关键的设计特性 ------超级块并非只有一份,而是在多个块组中进行备份 ,块组 0 包含主超级块 ,后续的块组(如块组 1、3、5、7...)会包含备份超级块,所有备份超级块的内容与主超级块完全一致。
- 设计原因:若超级块只有一份,一旦块组 0 的超级块因磁盘坏道、系统崩溃损坏,整个文件系统将无法识别;多份备份让系统在主超级块损坏后,可从备份超级块中恢复,保证文件系统的可用性;
- 备份位置 :超级块的备份位置由文件系统的块大小决定,可通过
dumpe2fs命令查看(后续实战讲解); - 实操要点 :若主超级块损坏,可通过
fsck命令指定备份超级块的位置进行修复,如fsck.ext4 -b 32768 /dev/vda1(32768 为备份超级块的块号)。
2.3 GDT(Group Descriptor Table):块组的 "信息索引卡"
GDT 全称组描述符表 ,由多个组描述符 组成,每个块组对应一个组描述符 ,组描述符的大小为 32 字节,存储了对应块组的局部元数据信息,相当于每个块组的 "信息索引卡",让系统能快速找到块组内的各类组件。
GDT 存储的核心信息(单个组描述符)
每个组描述符仅描述一个块组的信息,核心包括:
- 组件位置:块位图的块号、inode 位图的块号、inode 表的起始块号;
- 资源统计:该块组的空闲块数、空闲 inode 数、已使用的目录数;
- 预留字段:用于兼容后续的 Ext3/Ext4 文件系统,保证扩展性。
GDT 的备份特性
与超级块类似,GDT 也会在多个块组中进行多份备份,主 GDT 位于块组 0,后续块组的备份超级块旁会同步备份 GDT,防止 GDT 损坏导致块组无法被识别。
2.4 块位图(Block Bitmap):数据块的 "使用状态清单"
块位图是 Ext 文件系统管理数据块 的核心工具,用二进制位(bit) 来标记块组内所有数据块的使用状态,相当于数据块的 "使用状态清单",系统通过块位图快速分配和释放空闲数据块。
块位图的工作原理
- 位与块的映射 :块位图中的每一个二进制位 对应块组内的一个数据块,位的编号与数据块的编号一一对应;
- 状态标记规则 :
0表示对应的数据块空闲可用 ,1表示对应的数据块已被占用; - 分配与释放 :分配数据块时,系统在块位图中找到第一个值为
0的位,将其置为1,并分配对应的块;释放数据块时,将对应位的值置为0即可。
块位图的大小计算
块位图的大小由块组内的总数据块数决定:1 个字节 = 8 位,可标记 8 个数据块的状态,因此:
块位图大小(字节)= 块组内总数据块数 ÷ 8实例:若一个块组有 10 万个数据块,块位图大小 = 100000÷8=12500 字节≈12.2KB,仅需占用 4 个 4KB 的块,极大节省了元数据的存储空间。
2.5 inode 位图(inode Bitmap):inode 的 "使用状态清单"
inode 位图与块位图的设计原理完全相同 ,唯一的区别是:inode 位图用二进制位 标记块组内所有inode的使用状态,是 inode 的 "使用状态清单",系统通过 inode 位图快速分配和释放空闲 inode。
inode 位图的工作原理
- 位与 inode 的映射 :inode 位图中的每一个二进制位 对应块组内的一个 inode,位的编号与 inode 的编号一一对应;
- 状态标记规则 :
0表示对应的 inode空闲可用 ,1表示对应的 inode已被占用; - 分配与释放 :创建文件时,系统在 inode 位图中找到第一个值为
0的位,将其置为1,并分配对应的 inode;删除文件时,将对应位的值置为0即可。
关键关联:inode 的编号规则
inode 的编号在分区内连续递增,且按块组分发,如块组 0 的 inode 编号为 1~1024,块组 1 的为 1025~2048,以此类推。系统通过 inode 编号可快速计算出该 inode 所属的块组,再到对应块组的 inode 位图中验证其状态。
2.6 inode 表(inode Table):文件的 "属性仓库集合"
inode 表是块组内所有 inode 的存储区域 ,由多个连续的块组成,相当于文件的 "属性仓库集合"------每个文件对应的 inode 都存储在 inode 表中,inode 表的位置和大小由 GDT 中的组描述符指定。
inode 表的核心特性
- 连续存储:inode 表由多个连续的块组成,保证 inode 的读取效率,磁头无需频繁寻道;
- 固定大小:每个 inode 的大小固定为 128 字节(Ext2/3)或 256 字节(Ext4),因此 inode 表的大小 = 块组内的 inode 总数 ×inode 大小;
- 预分配 :文件系统格式化时,会根据分区大小和块大小预分配 inode 表的大小和 inode 总数,Ext4 支持动态分配 inode,解决了 Ext2/3inode 总数固定的问题;
- 存储计算 :以 4KB 块、128 字节 inode 为例,一个块可存储
4096÷128=32个 inode,这是文件系统格式化时计算 inode 表块数的基础。
关键要点:inode 表与文件的关联
创建文件时,系统会完成三个与 inode 表相关的操作:
- 在 inode 位图中找到空闲 inode,将其置为 1;
- 在 inode 表中初始化该 inode 的属性(如权限、UID、GID、创建时间);
- 将该 inode 的编号与文件名建立映射(存储在目录的数据块中)。
2.7 数据块(Data Blocks):文件的 "实际内容存储区域"
数据块是块组内最后一个组件 ,也是文件系统的核心数据存储区域 ,所有文件的实际内容 都存储在数据块中,数据块的分配和释放由块位图管理,数据块与文件的关联由 inode 中的数据块指针指定。
不同文件类型的数据块存储规则
Ext 文件系统中,一切皆文件,普通文件、目录、设备文件等不同类型的文件,其数据块的存储规则不同,核心分为三类:
- 普通文件(如.txt、.c、二进制可执行文件) :数据块中直接存储文件的实际二进制内容,是最常见的存储方式;
- 目录文件(如 /home、/etc) :数据块中不存储目录内容,而是存储该目录下所有文件 / 子目录的 **「文件名:inode 编号」映射关系 **(核心重点,后续详细讲解);
- 特殊文件(如设备文件、管道文件、符号链接) :这类文件无实际内容,或内容极小(如软链接的路径),其内容直接存储在 inode 中,无需占用数据块。
数据块的分配原则
为了提升 IO 效率,Ext 文件系统分配数据块时遵循 "局部性原则":
- 同块组分配 :文件的 inode 和对应的数据块尽量分配在同一个块组中,减少磁头跨块组移动;
- 连续分配 :尽量为一个文件分配连续的物理数据块,减少磁头的寻道次数,提升文件的顺序读写效率;
- 预分配 :Ext4 支持多块预分配,为大文件提前分配连续的空闲块,避免后续写入时产生碎片。
三、核心重点:inode 与数据块的映射机制(直接块 + 间接块)
这是 Ext 文件系统最核心的设计亮点,也是解答 "inode 如何精准指向文件内容的数据块"的关键。Ext2/3/4 的 inode 中包含一个 i_block 数组 ,该数组有15 个元素 ,每个元素是一个块号,通过 "直接块 + 一级间接块 + 二级间接块 + 三级间接块" 的四层设计,实现了对数据块的灵活映射,既保证了小文件的高效访问,又支持大文件的海量存储。
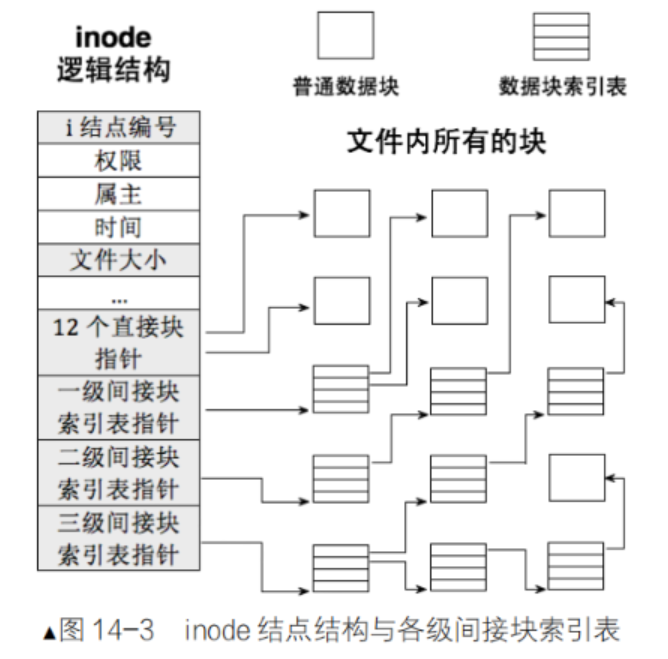
3.1 核心基础:i_block 数组与块号的作用
inode 的固定结构中,有一个名为i_block 的数组,定义为__le32 i_block[EXT2_N_BLOCKS],其中EXT2_N_BLOCKS=15,即数组有 15 个元素,每个元素是一个32 位的无符号整数 ,代表一个数据块的块号。
- 直接块 :数组元素直接存储文件内容的数 - 据块号,系统通过块号可直接找到文件内容,访问效率最高;
- 间接块 :数组元素不存储文件内容的数据块号,而是存储索引块的块号 ------ 索引块中存储的是文件内容的数据块号集合,系统需要先找到索引块,再从索引块中找到文件内容的块号,属于 "间接访问"。
为了方便理解,我们以1KB 的块大小 为例进行讲解(块大小不影响设计逻辑,仅影响映射的容量),且规定:32 位的块号可存储在 4 个字节中,因此 1 个 1KB 的索引块可存储1024÷4=256个块号。
3.2 四层映射结构:12 直接 + 1 一级 + 1 二级 + 1 三级
i_block 数组的 15 个元素按功能分为四层,前 12 个为直接块,后 3 个分别为一级、二级、三级间接块,四层结构层层嵌套,实现了从 "小文件高效访问" 到 "大文件海量存储" 的全覆盖,我们逐个拆解每层的映射原理和存储容量。
3.2.1 第一层:12 个直接块(i_block 0 ~ i_block 11)
- 映射原理 :数组的前 12 个元素直接存储文件内容的数据块号,每个元素对应一个实际存储文件内容的数据块,系统通过块号可直接访问文件内容,无中间环节;
- 存储容量 :12 个直接块 × 1KB / 块 = 12KB;
- 适用场景 :小文件(如配置文件、日志碎片),占 Linux 系统中文件的绝大多数,直接块的设计让小文件的访问效率达到最高。
3.2.2 第二层:1 个一级间接块(i_block 12)
当文件大小超过 12KB,直接块无法满足存储需求,此时会用到一级间接块,这是第一层间接映射。
- 映射原理 :i_block 12 不存储文件内容的块号,而是存储一个一级索引块的块号 ;该一级索引块中存储了256 个文件内容的数据块号,系统需要先通过 i_block 12 找到一级索引块,再从索引块中找到文件内容的块号;
- 存储容量 :1 个一级索引块 × 256 个块号 / 索引块 × 1KB / 块 = 256KB;
- 累计容量 :12KB + 256KB = 268KB;
- 适用场景 :中等大小文件(如普通的文本文件、小型程序)。
3.2.3 第三层:1 个二级间接块(i_block 13)
当文件大小超过 268KB,一级间接块也无法满足需求,此时会用到二级间接块,是第二层间接映射,通过 "索引块嵌套索引块" 实现更大的存储容量。
- 映射原理 :i_block 13 存储一个二级索引块的块号 ;该二级索引块中存储的不是文件内容的块号,而是256 个一级索引块的块号;每个一级索引块又能存储 256 个文件内容的块号,形成 "二级索引";
- 存储容量 :1 个二级索引块 × 256 个一级索引块 / 块 × 256 个块号 / 一级索引块 × 1KB / 块 = 65536KB(64MB);
- 累计容量 :268KB + 64MB ≈ 64.26MB;
- 适用场景 :大文件(如大型程序、视频片段、数据库文件)。
3.2.4 第四层:1 个三级间接块(i_block 14)
当文件大小超过 64.26MB,二级间接块达到存储上限,此时会用到三级间接块,是第三层间接映射,也是 Ext 文件系统的最后一层映射。
- 映射原理 :i_block 14 存储一个三级索引块的块号 ;该三级索引块中存储256 个二级索引块的块号;每个二级索引块存储 256 个一级索引块的块号;每个一级索引块存储 256 个文件内容的块号,形成 "三级索引";
- 存储容量 :1 个三级索引块 × 256 个二级索引块 / 块 × 256 个一级索引块 / 块 × 256 个块号 / 一级索引块 × 1KB / 块 = 16777216KB(16GB);
- 累计容量 :64.26MB + 16GB ≈ 16.06GB;
- 适用场景 :超大文件(如高清视频、大型数据库、虚拟机镜像)。
3.3 不同大小文件的映射实例
结合上述四层结构,我们以 1KB 块大小为例,看不同大小的文件如何通过 i_block 数组映射数据块,直观理解其设计逻辑:
- 8KB 的小文件:仅使用前 8 个直接块(i_block 0~i_block 7),直接映射 8 个数据块,高效访问;
- 200KB 的中等文件:使用 12 个直接块(12KB) + 188 个一级间接块的块号(188KB),一级索引块仅使用部分空间;
- 100MB 的大文件:使用 12 个直接块 + 256 个一级间接块 + 97 个二级间接块的块号,用到二级索引;
- 20GB 的超大文件:使用 12 个直接块 + 256 个一级间接块 + 65536 个二级间接块 + 部分三级间接块的块号,用到三级索引。
补充:4KB 块大小的总存储容量
若文件系统的块大小为默认的 4KB,1 个索引块可存储
4096÷4=1024个块号,此时三级间接块的累计存储容量可达12×4KB + 1×1024×4KB + 1×1024×1024×4KB + 1×1024×1024×1024×4KB ≈ 4TB,完全满足绝大多数场景的大文件存储需求。
3.4 该设计的核心优势
inode 与数据块的 "直接 + 三级间接" 映射设计,是 Ext 文件系统的经典设计,核心优势体现在两点:
- 兼顾小文件效率和大文件扩展性:小文件使用直接块,无中间环节,访问效率拉满;大文件通过多级间接块实现海量存储,突破了直接块的容量限制;
- 元数据开销小:仅用 15 个数组成员就实现了从 KB 级到 GB/TB 级的文件存储,inode 的大小仍保持 128 字节,无需额外扩容,大幅节省了元数据的存储空间。
四、目录的本质:存储「文件名:inode」映射的特殊文件
在上一篇中我们提到:inode 中不存储文件名 ,而 Linux 中我们通过 "路径 + 文件名" 访问文件,那么文件名到底存储在哪里?答案就是目录 ------Ext 文件系统中,目录也是一种特殊的文件 ,有自己的 inode 和数据块,其核心特殊性在于:目录的数据块中不存储任何实际内容,仅存储该目录下所有文件 / 子目录的「文件名:inode 编号」映射关系。
4.1 目录的文件属性:与普通文件一致
目录作为特殊文件,拥有和普通文件完全一致的属性:
- 有自己的inode,存储在 inode 表中,包含目录的权限、UID、GID、创建时间、数据块指针等属性;
- 有自己的数据块,由块位图管理,数据块的位置由 inode 中的 i_block 数组指定;
- 有自己的inode 编号 ,分区内唯一,可通过
ls -li命令查看; - 目录的硬链接数有特殊规则(下一篇讲解软硬链接时详细说明),新建目录的硬链接数默认为 2。
4.2 目录的数据块:存储「文件名:inode」的映射关系
这是目录最核心的特性,其数据块中存储的是一系列的目录项(directory entry) ,每个目录项对应一个文件 / 子目录,包含文件名 、inode 编号 、文件名长度 、文件类型等信息,核心结构为:
目录项 = 文件名 + inode编号 + 文件名长度 + 文件类型系统通过 "路径 + 文件名" 访问文件时,就是通过逐层解析目录的数据块,找到文件名对应的 inode 编号,再通过 inode 编号找到文件的属性和内容(下一篇路径解析详细讲解)。
4.3 特殊的目录项:. 和 ...
每个目录的数据块中都包含两个特殊的目录项 :. 和.. ,这是系统自动创建的,用于实现目录的层级关系,其映射关系为:
- . :表示当前目录,其对应的 inode 编号就是当前目录自身的 inode 编号**;
- ... :表示父目录 ,其对应的 inode 编号就是当前目录的父目录的 inode 编号。
实例 :若/home/whb目录的 inode 编号为 1052007,其父目录/home的 inode 编号为 786433,则/home/whb目录的数据块中,. 对应 1052007,.. 对应 786433。
这两个特殊目录项是 Linux 目录层级结构的基础,也是路径解析中 "相对路径" 的实现依据。
4.4 目录的存储优化:Ext4 的 HTree 索引
Ext2 和 Ext3 的目录数据块采用线性存储 方式,目录项按创建顺序依次存储,当目录下有大量文件(如上万甚至十万个)时,查找文件名需要遍历整个数据块,效率极低;Ext4 引入了HTree 索引 ,将目录项按文件名进行哈希排序,构建成哈希树,让大目录的查找效率从O(n) 提升到O(logn),大幅优化了大目录的访问性能。
五、实战:解析 Ext 文件系统的核心信息与格式化本质
理论终究要落地实操,Linux 提供了 dumpe2fs和 mkfs.ext4两个核心命令,分别用于查看 Ext 文件系统的详细元数据信息 和格式化创建 Ext 文件系统 ,本节我们通过这两个命令,将前面的块组、超级块、inode 等理论知识与实操结合,同时讲清 Ext 文件系统格式化和删除文件的本质。
5.1 实战 1:dumpe2fs ------ 查看 Ext 文件系统的核心元数据
dumpe2fs命令用于查看 Ext2/3/4 文件系统的详细元数据信息,包括超级块、GDT、块组、块位图、inode 位图等所有组件的信息,是分析 Ext 文件系统的核心工具,执行需要 root 权限。
命令执行与核心输出解析
# 查看/dev/vda2分区的Ext4文件系统信息(需root权限)
sudo dumpe2fs /dev/vda2命令输出内容较多,我们提取超级块 和块组的核心信息进行解析,与前文理论对应:
-
超级块核心信息:
Block count: 10485760 # 总块数 Inode count: 2621440 # 总inode数 Block size: 4096 # 块大小(4KB) Inode size: 256 # inode大小(256字节,Ext4) Free blocks: 8388608 # 空闲块数 Free inodes: 2457600 # 空闲inode数 First block: 0 Block group size: 32768 # 每个块组的块数 -
块组核心信息:
Block group 0: (Blocks 0-32767) Superblock at 0, Group descriptors at 1-1 # 主超级块在块0,GDT在块1 Block bitmap at 2, Inode bitmap at 3 # 块位图在块2,inode位图在块3 Inode table at 4-327 # inode表在块4-327 Free blocks: 28672-32767 # 空闲块范围 Free inodes: 1-262144 # 空闲inode范围
实操小技巧
- 用
dumpe2fs /dev/vda1 | grep -i superblock可快速过滤出超级块的信息,包括备份超级块的位置; - 用
dumpe2fs /dev/vda1 | grep -i "block group"可快速过滤出所有块组的信息。
5.2 实战 2:mkfs.ext4 ------ 格式化创建 Ext4 文件系统
mkfs.ext4命令用于将磁盘分区格式化为 Ext4 文件系统 ,格式化的过程就是初始化 Ext 文件系统的块组、超级块、GDT、位图、inode 表等所有元数据组件的过程,执行需要 root 权限。
核心命令格式与常用参数
# 基础格式:将分区/dev/vda1格式化为Ext4文件系统
sudo mkfs.ext4 /dev/vda1
# 常用参数:指定块大小、inode大小、卷标
sudo mkfs.ext4 -b 4096 -i 256 -L MY_DISK /dev/vda1常用参数解析:
-b:指定文件系统的块大小,可选 1024/2048/4096 字节,默认 4096;-i:指定 inode 大小,Ext2/3 默认 128,Ext4 默认 256;-L:指定文件系统的卷标,方便识别;-m:指定预留的超级用户空间比例,默认 5%,用于系统维护。
5.3 核心本质 1:Ext 文件系统格式化的本质
很多人认为格式化会 "删除分区中的所有数据",这是一个误区 ------Ext 文件系统格式化的核心是「初始化元数据」,而非删除数据。
格式化的具体操作:
- 将分区划分为多个大小相等的块组;
- 初始化超级块和 GDT,写入文件系统的基础参数;
- 将块位图和 inode 位图全部置 0,表示所有块和 inode 都空闲可用;
- 初始化 inode 表,创建默认的 inode(如根目录的 inode);
- 创建根目录的 inode 和数据块,写入
.和..特殊目录项。
关键要点 :格式化不会修改数据块中的实际内容,仅对元数据进行初始化,因此格式化后的分区数据仍有机会通过数据恢复工具找回(前提是未写入新数据)。
5.4 核心本质 2:Ext 文件系统删除文件的本质
Linux 中用rm命令删除文件,其核心本质与格式化类似 ------仅修改元数据,不删除实际内容。
删除文件的具体操作:
- 在 inode 位图中,将该文件对应的 inode 位置 0,标记为空闲;
- 在块位图中,将该文件占用的所有数据块位置 0,标记为空闲;
- 在父目录的数据块中,删除该文件的「文件名:inode」目录项。
关键要点 :删除文件后,文件的实际内容仍存储在数据块中,直到新的数据覆盖这些块。因此,若不小心删除了重要文件,应立即停止对该分区的所有写入操作,并通过数据恢复工具(如 extundelete)恢复,否则新数据会覆盖原有内容,导致无法恢复。
六、常见坑 & 避坑指南
学习 Ext2/3/4 文件系统的核心实现时,很多人会因混淆元数据 / 数据 、直接块 / 间接块 、目录 / 普通文件的概念陷入误区,这里整理了最常见的 7 个误区,帮你精准避坑:
误区 1:Ext2/3/4 的核心底层结构不同
错误认知:Ext2、Ext3、Ext4 是完全不同的文件系统,底层结构差异很大;
正确认知 :Ext3 是 Ext2 的 "日志增强版",Ext4 是 Ext3 的 "性能优化版",三者的核心底层结构(块组、inode、数据块映射)完全一致,Ext3/4 仅在 Ext2 的基础上增加了功能,未改变底层设计。
误区 2:超级块只有一份,存储在块组 0
错误认知:超级块仅在块组 0 有一份,是文件系统的唯一核心;
正确认知 :超级块在多个块组中存在多份备份,块组 0 是主超级块,后续块组按需备份,防止主超级块损坏导致文件系统崩溃。
误区 3:inode 的 15 个 i_block 元素都直接指向数据块
错误认知:i_block 数组的 15 个元素都直接存储文件内容的数据块号;
正确认知 :前 12 个为直接块 ,直接指向数据块;后 3 个为间接块,指向索引块,通过索引块间接指向数据块,用于大文件存储。
误区 4:目录是特殊的硬件结构,不是文件
错误认知:Linux 中的目录是独立的硬件 / 系统结构,与文件无关;
正确认知 :目录是一种特殊的文件,有自己的 inode 和数据块,其数据块仅存储「文件名:inode」的映射关系,无实际内容。
5. 误区 5:格式化会彻底删除分区中的所有数据
错误认知:格式化分区后,分区中的所有数据都会被彻底删除,无法恢复;
正确认知 :格式化仅初始化元数据 (位图置 0、初始化超级块 / GDT),不会修改数据块中的实际内容,未被新数据覆盖前,数据可通过恢复工具找回。
误区 6:块位图和 inode 位图的标记规则相反
错误认知:块位图中 1 表示空闲,0 表示占用;inode 位图则相反;
正确认知 :块位图和 inode 位图的标记规则完全一致 ,均为0表示空闲可用,1表示已被占用,无任何区别。
误区 7:Ext 文件系统的 inode 总数固定,无法修改
错误认知:Ext 文件系统格式化后,inode 总数固定,若 inode 用完,即使有空闲块也无法创建新文件;
正确认知 :Ext2/3 的 inode 总数确实固定,但Ext4 支持动态分配 inode,可在使用过程中根据需求创建新的 inode,解决了 inode 耗尽的问题。
七、总结与下一篇预告
本节核心总结
本篇我们以 Ext2 为核心,拆解了 Linux 最经典的 Ext 系列文件系统的核心实现,完成了从文件系统抽象 到实际落地的跨越,核心知识点可以总结为 7 点:
- Ext 系列文件系统采用 ** 块组(Block Group)** 的分治思想,将分区划分为多个大小均等、结构一致的块组,降低管理复杂度,提升 IO 效率;
- Ext2/3/4 的核心底层结构一致,Ext3 增加日志功能,Ext4 做了高性能优化,适用场景各有不同;
- 块组内部包含七大核心组件:启动块(引导)、超级块(全局元数据)、GDT(块组索引)、块位图 /inode 位图(使用状态)、inode 表(属性集合)、数据块(内容存储);
- 超级块和 GDT 有多份备份,防止单点故障,是文件系统正常使用的关键;
- inode 与数据块通过12 个直接块 + 3 个三级间接块的四层映射结构关联,兼顾小文件效率和大文件扩展性,1KB 块大小下最大支持约 16GB 文件存储;
- 目录是特殊的文件,其数据块中存储的是 **「文件名:inode 编号」的映射关系 **,
.和..是系统自动创建的特殊目录项,实现目录层级关系; - Ext 文件系统的格式化和删除文件仅修改元数据,不删除实际内容,未被覆盖的数据可通过恢复工具找回。
下一篇预告
通过本篇的学习,我们懂了 Ext 文件系统如何存储文件的属性(inode)和内容(数据块),也知道了目录存储着文件名与 inode 的映射关系,但新的核心问题又来了:
- 我们在 Linux 中通过 **"路径 + 文件名"访问文件,系统如何逐层解析路径 **,找到最终的 inode 编号?
- 不同分区的 inode 编号可重复,系统如何区分不同分区的文件?
- 格式化后的分区为何无法直接使用,** 挂载(Mount)** 的本质是什么?
下一篇我们将讲解 Linux 文件系统的路径解析与挂载机制 ,揭开struct dentry路径缓存的神秘面纱,讲清挂载的本质是 "分区与目录的绑定",并通过 loop 设备实战模拟磁盘分区的挂载与卸载,让你看懂 Linux 如何跨分区、高效率地访问文件,敬请期待!