目录


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》《笔试算法》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、水果成篮
904. 水果成篮
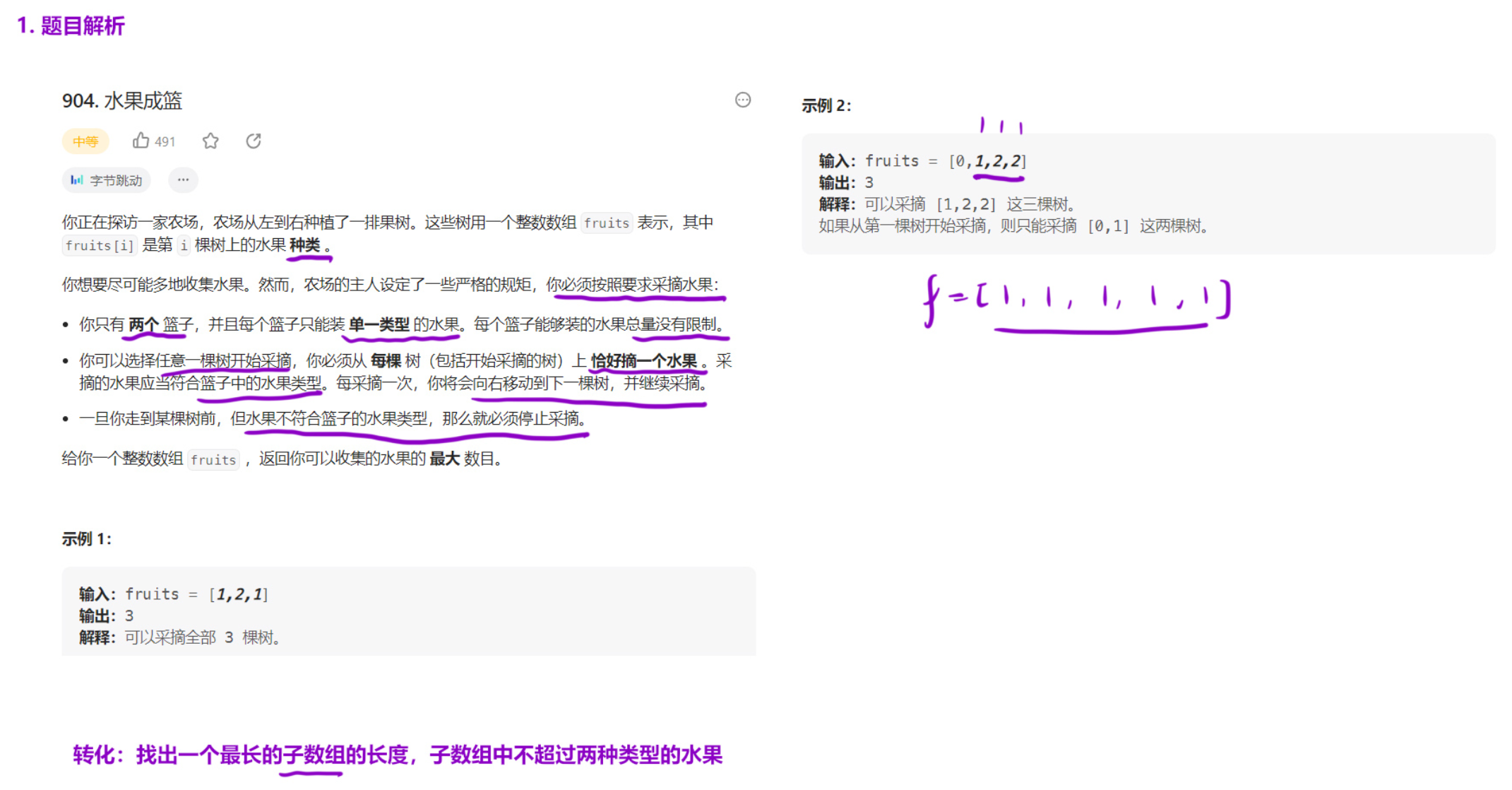
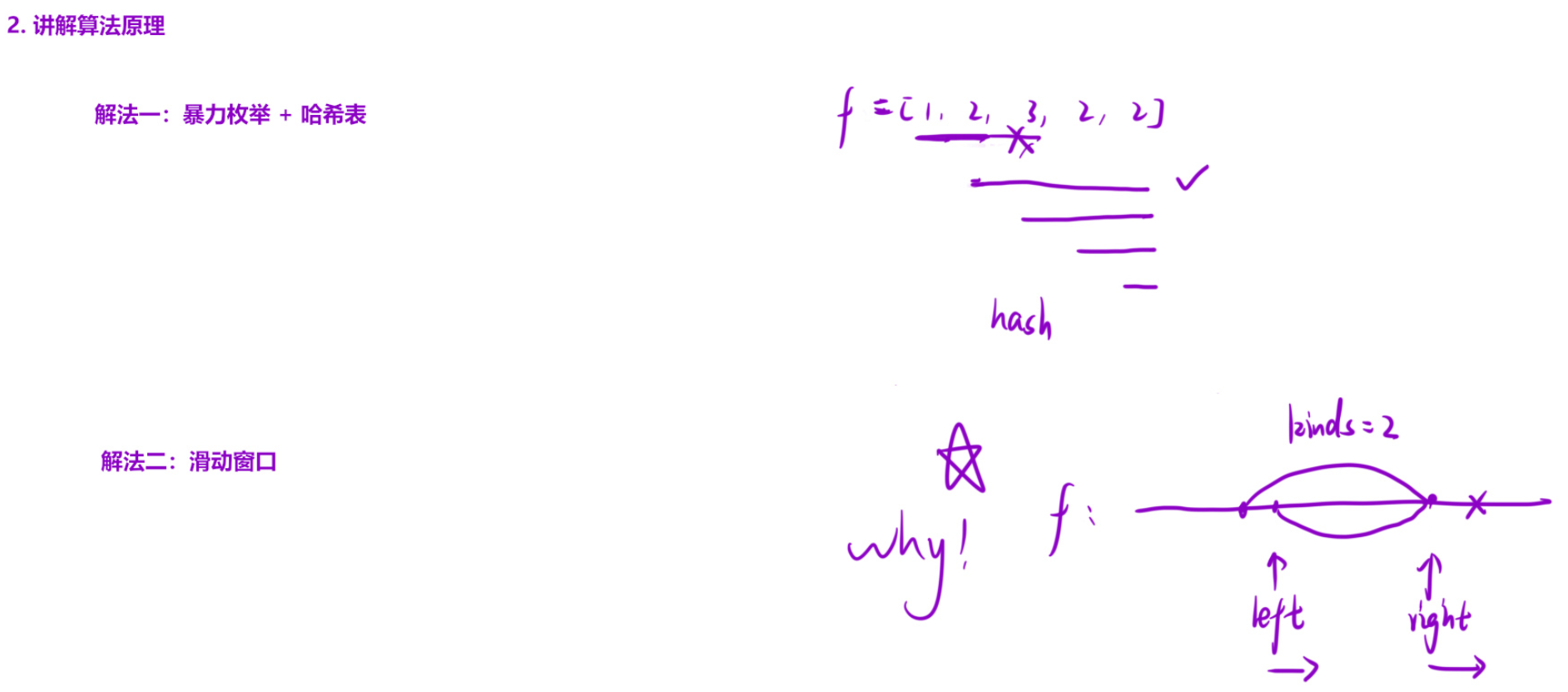
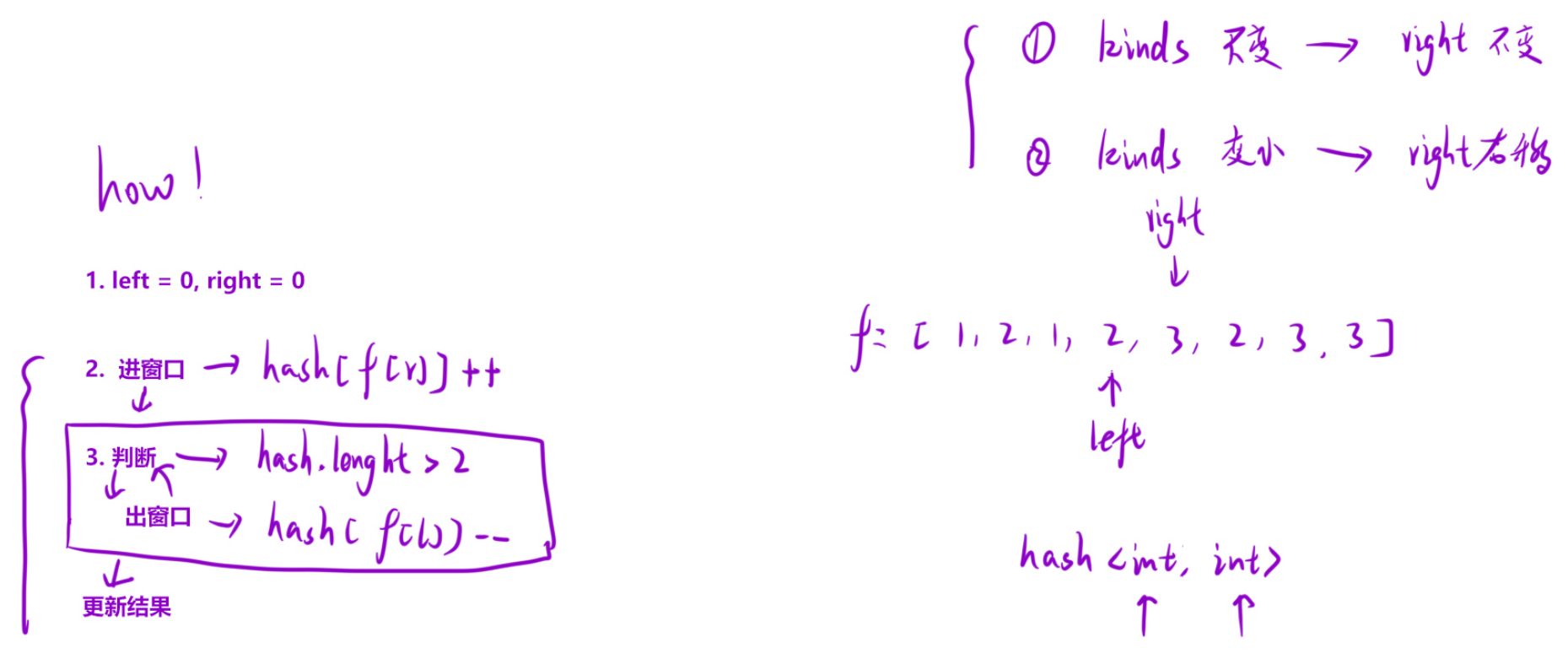
解法(滑动窗口) :
算法思路 :
研究的对象是一段连续的区间,可以使用「滑动窗口」思想来解决问题。
让滑动窗口满足 :窗口内水果的种类只有两种。
做法:右端水果进入窗口的时候,用哈希表统计这个水果的频次。这个水果进来后,判断哈希表的大小:
- 如果大小超过 2:说明窗口内水果种类超过了两种。那么就从左侧开始依次将水果划出窗口,直到哈希表的大小小于等于 2,然后更新结果;
- 如果没有超过 2,说明当前窗口内水果的种类不超过两种,直接更新结果 ret。
算法流程 :
a. 初始化哈希表 hash 来统计窗口内水果的种类和数量;
b. 初始化变量:左右指针 left = 0,right = 0,记录结果的变量 ret = 0;
c. 当 right 小于数组大小的时候,一直执行下列循环:
-
i. 将当前水果放入哈希表中;
-
ii. 判断当前水果进来后,哈希表的大小:
-
- 如果超过 2:
-
-
- 将左侧元素滑出窗口,并且在哈希表中将该元素的频次减一;
-
-
-
- 如果这个元素的频次减一之后变成了 0,就把该元素从哈希表中删除;
-
-
-
- 重复上述两个过程,直到哈希表中的大小不超过 2;
-
-
iii. 更新结果 ret;
-
iv. right++,让下一个元素进入窗口;
d. 循环结束后,ret 存的就是最终结果。
这道题目我提供两种解答代码,但是思路都是一样的,任选其一理解思路即可
cpp
class Solution {
public:
//这里变量名太长可以自己修改
//vector<int>& fruits
int totalFruit(vector<int>& f) {
int n = f.size(), ret = 0;
unordered_map<int, int> hash;
for(int left = 0, right = 0; right < n; right++)
{
//进窗口
hash[f[right]]++;
//判断
while(hash.size() > 2)
{
//出窗口
hash[f[left]]--;
if(hash[f[left]] == 0)
hash.erase(f[left]);
left++;
}
//更新结果
ret = max(ret, right - left + 1);
}
return ret;
}
};还可以用数组模拟哈希表来提效
cpp
class Solution {
public:
//这里变量名太长可以自己修改
//vector<int>& fruits
int totalFruit(vector<int>& f) {
int n = f.size(), ret = 0;
//题目中水果种类是1~10^5,想要效率更高也可以用一个数组来模拟哈希表
int hash[100001] = { 0 };
for(int left = 0, right = 0, kinds = 0; right < n; right++)
{
//进窗口
if(hash[f[right]]++ == 0) kinds++;
//判断
while(kinds > 2)
{
//出窗口
if(hash[f[left]]-- == 1) kinds--;
left++;
}
//更新结果
ret = max(ret, right - left + 1);
}
return ret;
}
};二、找到字符串中所有字母异位词

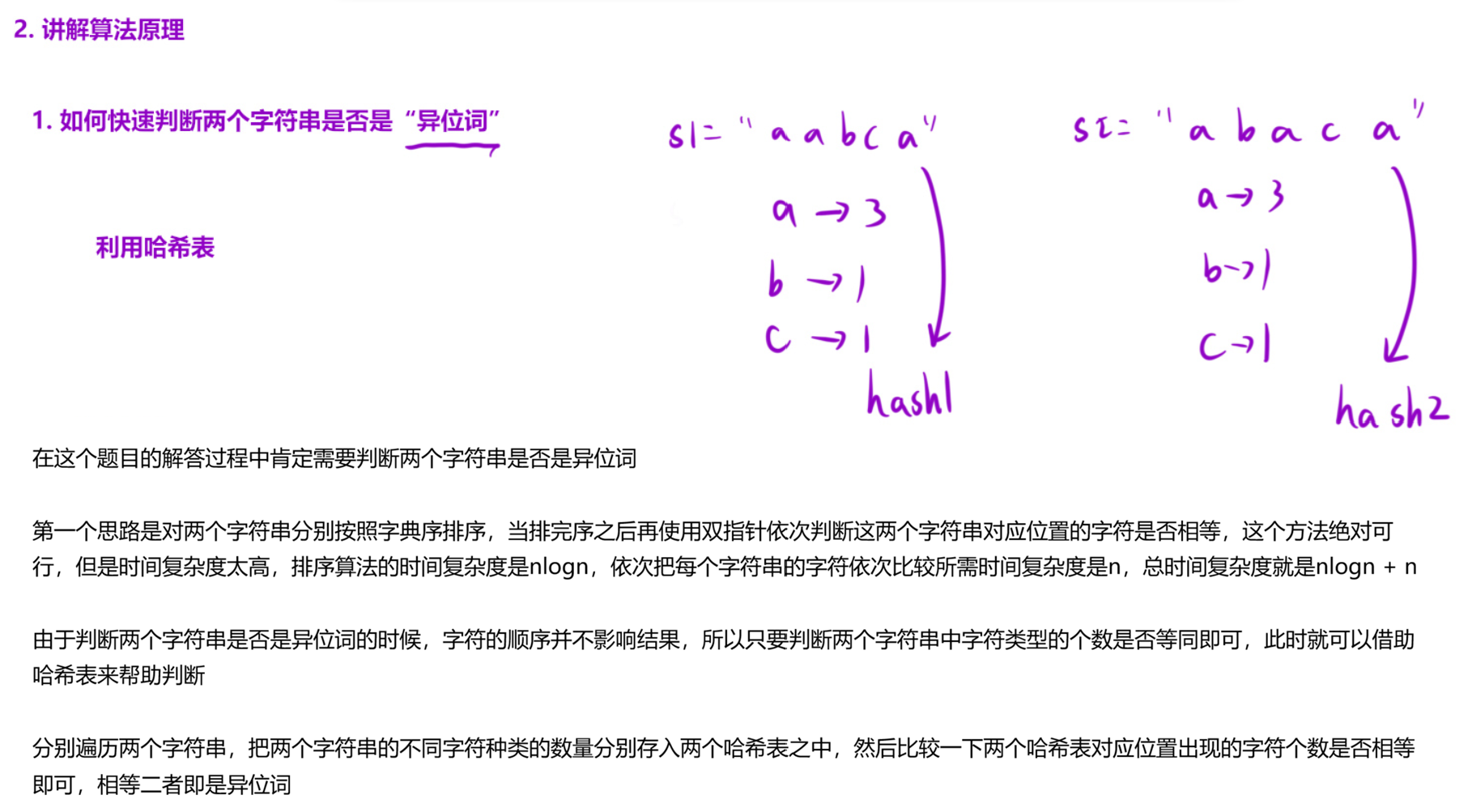
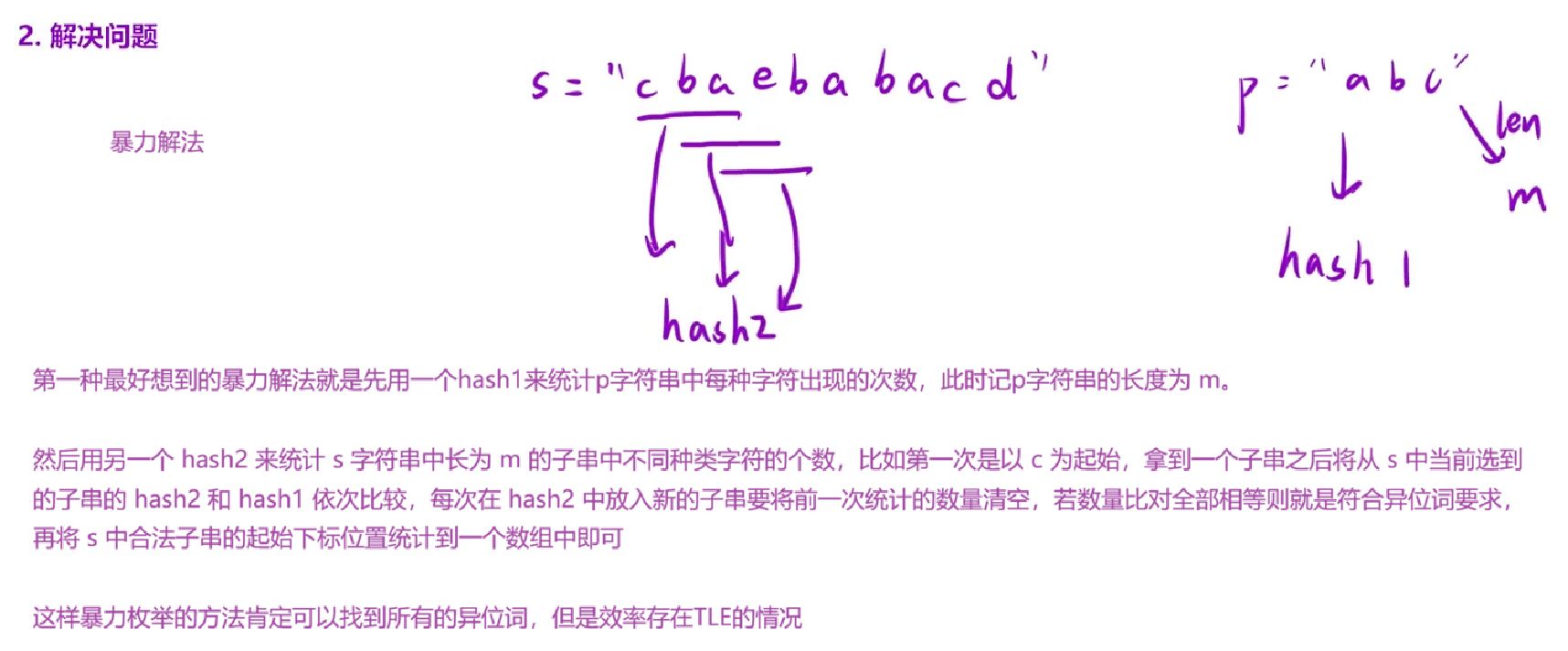
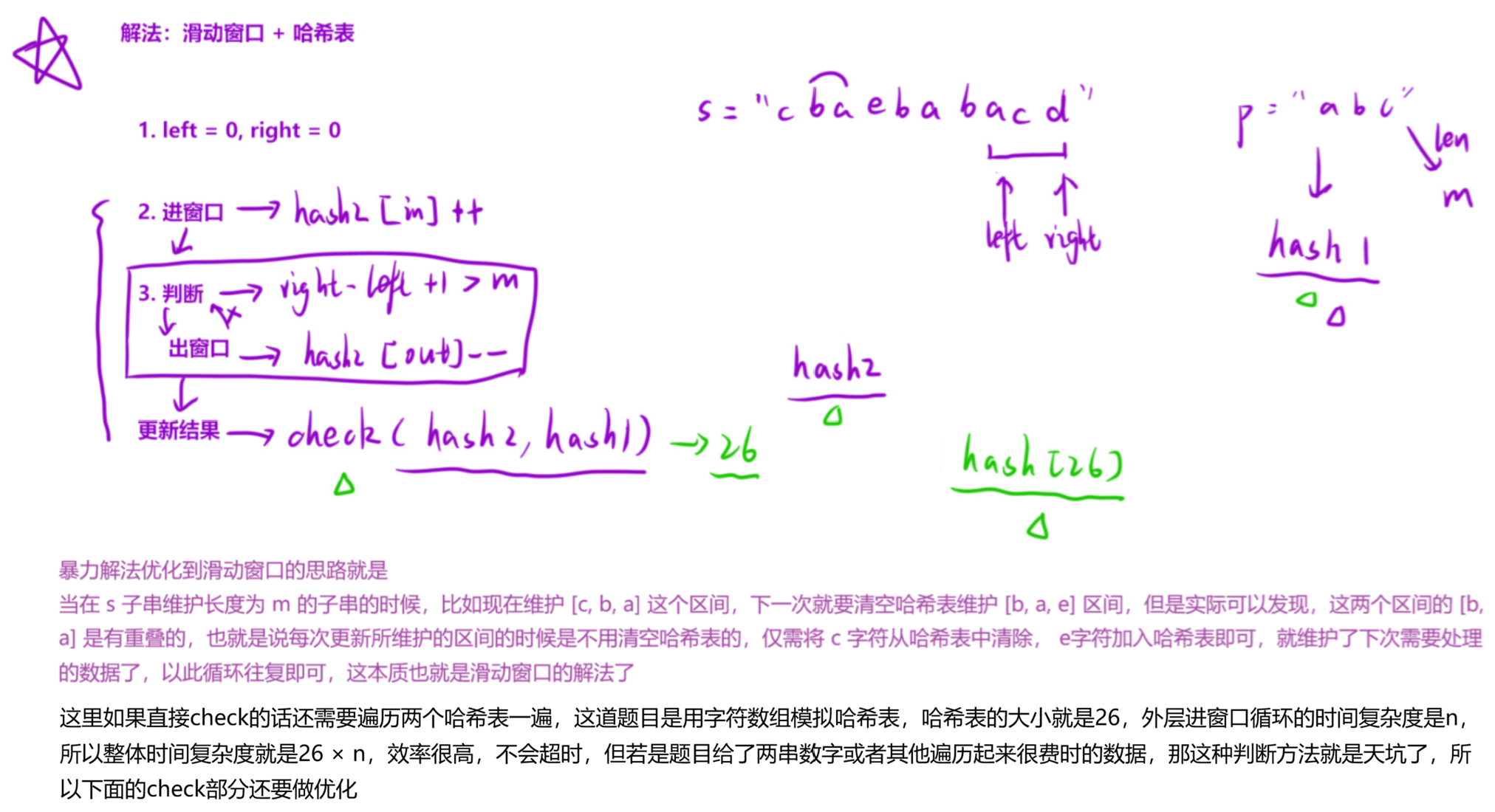

解法(滑动窗口 + 哈希表) :
算法思路:
- 因为字符串 p 的异位词的长度一定与字符串 p 的长度相同,所以我们可以在字符串 s 中构造一个长度为与字符串 p 的长度相同的滑动窗口,并在滑动中维护窗口中每种字母的数量;
- 当窗口中每种字母的数量与字符串 p 中每种字母的数量相同时,则说明当前窗口为字符串 p 的异位词;
- 因此可以用两个大小为 26 的数组来模拟哈希表,一个来保存 s 中的子串每个字符出现的个数,另一个来保存 p 中每一个字符出现的个数。这样就能判断两个串是否是异位词。
这里我依旧提供两种解法,第一种是按数组比较的方式更新结果
cpp
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int n = s.size(), m = p.size();
int hash1[26] = { 0 }, hash2[26] = { 0 };
for(auto& e : p) hash2[e - 'a']++;
vector<int> ret;
for(int left = 0, right = 0; right < n; right++)
{
char ch = s[right];
//进窗口
hash1[ch - 'a']++;
//判断
if(right - left + 1 > m)
{
//出窗口
hash1[s[left++] - 'a']--;
}
int flag = 1;
//检查并更新结果
for(int i = 0; i < 26; i++)
{
if(hash2[i] != hash1[i])
{
flag = 0; break;
}
}
if(flag == 1) ret.push_back(left);
}
return ret;
}
};使用count变量帮助更新结果的时候提效
cpp
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int n = s.size(), m = p.size(), count = 0;
int hash1[26] = { 0 }, hash2[26] = { 0 };
for(auto& e : p) hash2[ch - 'a']++;
vector<int> ret;
for(int left = 0, right = 0; right < n; right++)
{
char in = s[right];
//进窗口
if(++hash1[in - 'a'] <= hash2[in - 'a']) count++;
//判断
if(right - left + 1 > m)
{
char out = s[left++];
//出窗口
if(hash1[out - 'a']-- <= hash2[out - 'a']) count--;
}
//检查并更新结果
if(count == m) ret.push_back(left);
}
return ret;
}
};之前文章的滑动窗口题目还需证明单调性之类的东西,这道题就不用了,因为单调性一目了然,之前的题目窗口大小并不固定,有时候只移动 right,有时候只移动 left,而这个题目维护的窗口大小就是 p 串的长度,right 右移的同时 left 也右移
三、串联所有单词的子串

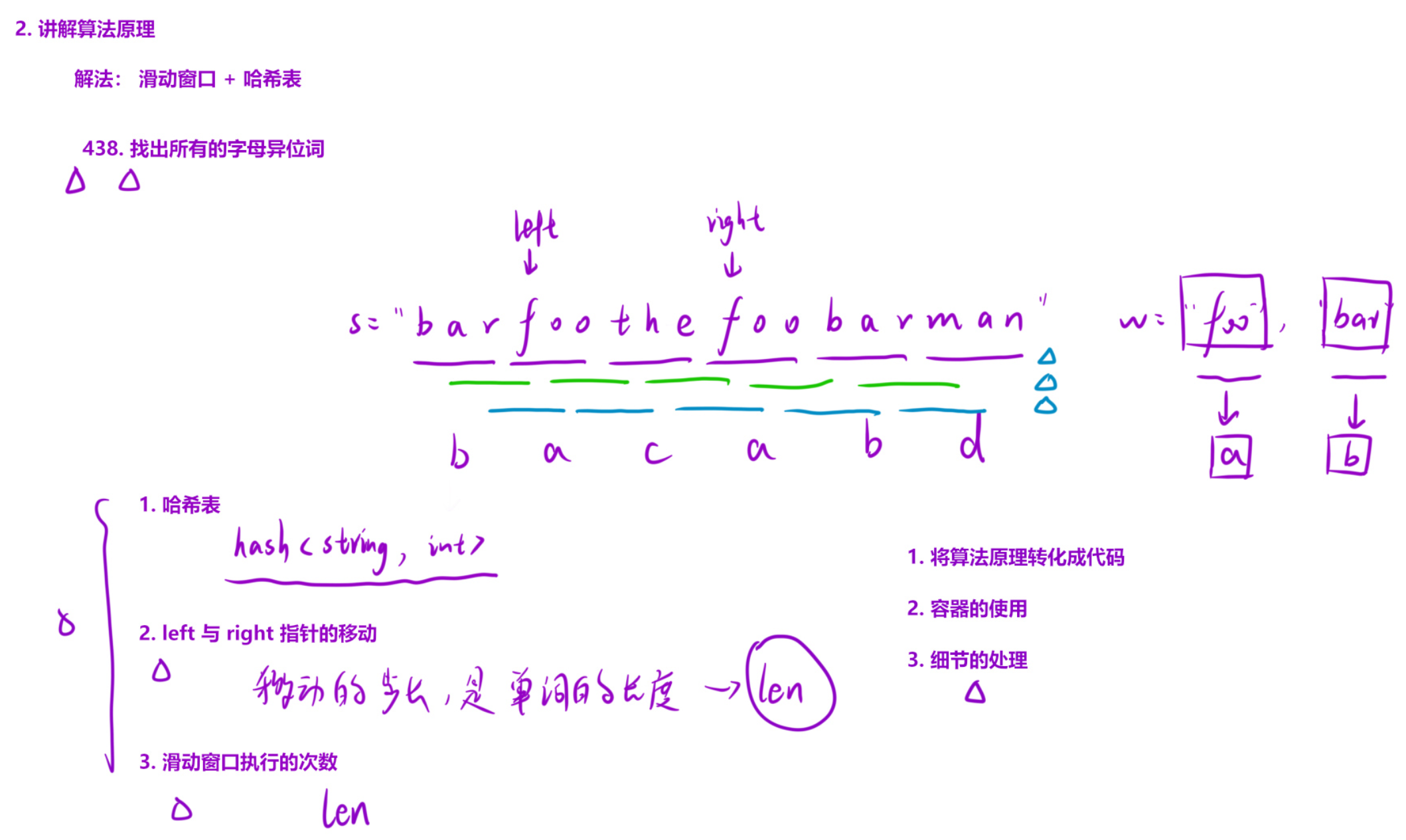
解法(滑动窗口):
算法思路:如果我们把每一个单词看成一个一个字母,问题就变成了找到「字符串中所有的字母异位词」。无非就是之前处理的对象是一个一个的字符,我们这里处理的对象是一个一个的单词。
cpp
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
int n = s.size(), len = words[0].size(), m = words.size();
unordered_map<string, int> hash2;
vector<int> ret;
for(auto& s : words) hash2[s]++;
//执行 len 次滑动窗口的操作
for(int i = 0; i < len; i++)
{
//维护窗口内单词的频次
unordered_map<string, int> hash1;
//count统计窗口中有效字符串的个数
for(int left = i, right = i, count = 0; right + len <= s.size(); right += len)
{
//进窗口
//裁剪出要进窗口的子串,从right位置开始,向后len长度的子串
string in = s.substr(right, len);
if(++hash1[in] <= hash2[in]) count++;
//判断
if(right - left + 1 > m * len)
{
//出窗口,裁剪出窗口的单词
string out = s.substr(left, len);
if(hash1[out]-- <= hash2[out]) count--;
left += len;
}
//判断结果
if(count == m) ret.push_back(left);
}
}
return ret;
}
};
虽然这道题目通过了,但是可以发现执行运时分布并不理想,算法的效率时绝对没有问题的,问题出现在语法上
if(++hash1[in] <= hash2[in]) count++;这句代码使用了哈希表的[]接口,这个接口的特性就是如果哈希表中没有in这个字符串则会重新创建一个加入到哈希表当中,这是有一定时间消耗的,当执行进窗口操作++hash1[in],这个单词是一定会出现在第一个哈希表当中,但是第二个哈希表就不一定有in这个字符串了,所以在执行这条语句之前还可以特判一下
hash2.count(in),如果in出现在第二个哈希表当中,再进行维护count的操作,同理下面的代码也是如此
cpp
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
int n = s.size(), len = words[0].size(), m = words.size();
unordered_map<string, int> hash2;
vector<int> ret;
for(auto& s : words) hash2[s]++;
//执行 len 次滑动窗口的操作
for(int i = 0; i < len; i++)
{
//维护窗口内单词的频次
unordered_map<string, int> hash1;
//count统计窗口中有效字符串的个数
for(int left = i, right = i, count = 0; right + len <= s.size(); right += len)
{
//进窗口
//裁剪出要进窗口的子串,从right位置开始,向后len长度的子串
string in = s.substr(right, len);
hash1[in]++;
if(hash2.count(in) && hash1[in] <= hash2[in]) count++;
//判断
if(right - left + 1 > m * len)
{
//出窗口,裁剪出窗口的单词
string out = s.substr(left, len);
if(hash2.count(out) && hash1[out] <= hash2[out]) count--;
hash1[out]--;
left += len;
}
//判断结果
if(count == m) ret.push_back(left);
}
}
return ret;
}
};四、最小覆盖子串
76. 最小覆盖子串
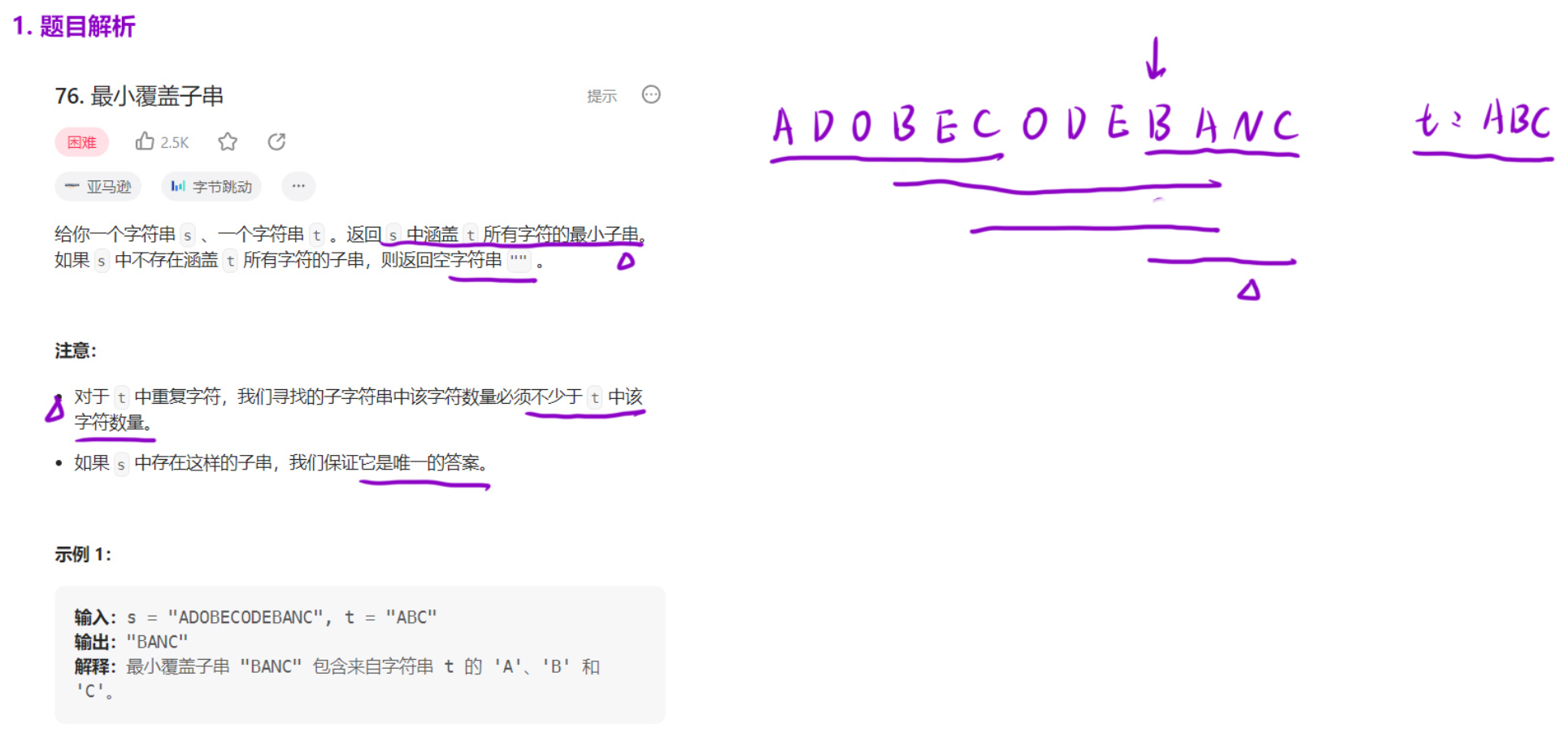
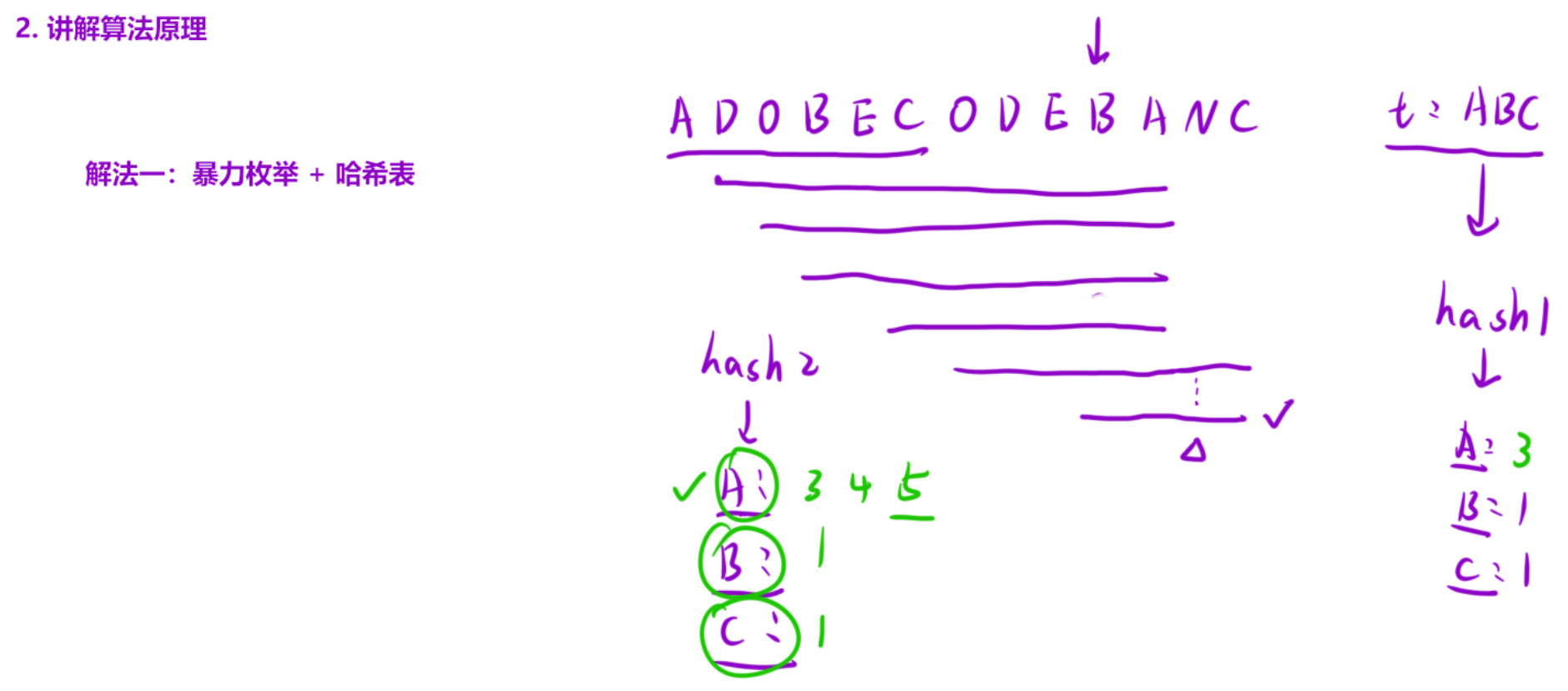
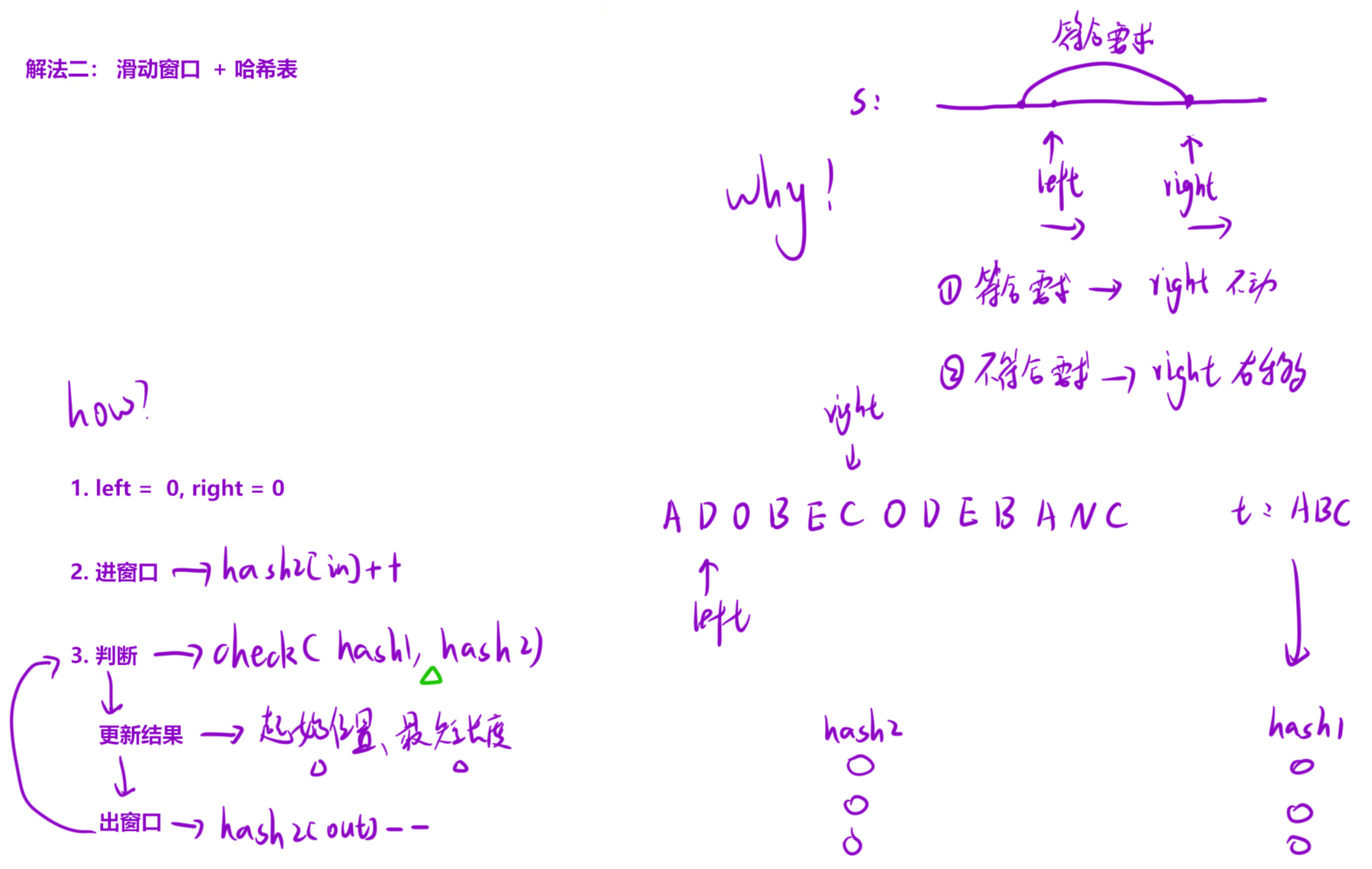
解题思路(滑动窗口双指针):
- 预处理 :用hash1统计字符串t的字符频次,kinds记录t中不同字符的种类数;
- 滑动窗口遍历 :右指针right遍历s,将字符加入窗口(hash2统计窗口内字符频次),字符频次达标时count++;
- 窗口收缩优化 :当**
count == kinds**(窗口已包含t所有字符,合法),更新最短子串 ,然后左指针left右移收缩窗口,字符不达标时count--,直到窗口不合法; - 返回结果:最终返回记录的最短子串,无合法子串则返回空串。
cpp
class Solution {
public:
string minWindow(string s, string t) {
int n = s.size(), m = t.size(), kinds = 0;
int hash1[128] = { 0 }, hash2[128] = { 0 };
for(auto& ch : t)
if(hash1[ch]++ == 0) kinds++;
int minlen = INT_MAX, begin = -1;
for(int left = 0, right = 0, count = 0; right < n; right++)
{
char in = s[right];
//进窗口
if(++hash2[in] == hash1[in]) count++;
//判断
while(count == kinds)
{
//更新结果
int len = right - left + 1;
if(len < minlen)
{
minlen = len;
begin = left;
}
char out = s[left++];
//出窗口
if(hash2[out]-- == hash1[out])
count--;
}
}
if(begin == -1) return "";
else return s.substr(begin, minlen);
}
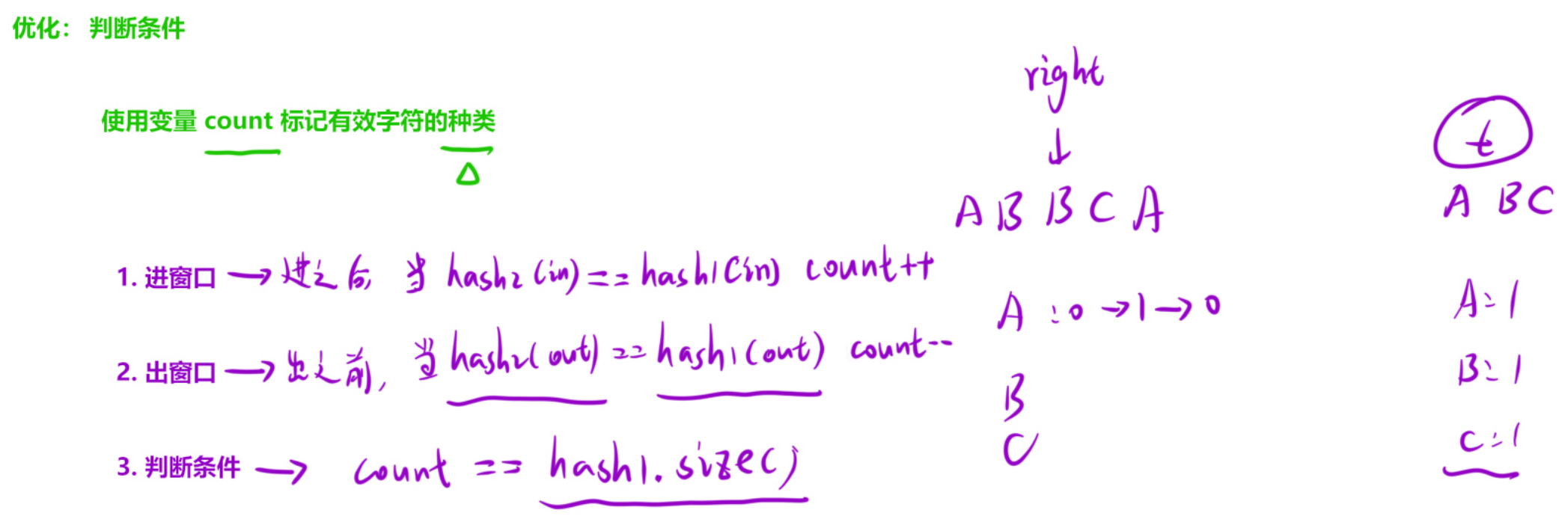
};要点补充:
-
128 对应完整的标准 ASCII 码范围:0 ~ 127,正好覆盖所有英文字母(大写 + 小写),题目里只有英文字母,开 int128 完全够用
-
count = 当前滑动窗口中,已经满足「出现次数 ≥ t 中该字符所需次数」的字符种类数量 ,只有窗口里某一个字符的数量刚好达到 t 的要求 ,count 才 +1
尤其注意这里 count 记录的是「达标字符的种类数」,不是像前面一样标记有效字符的总个数
结语
