
目录
-
- [一、不是所有 AI 任务都需要超节点](#一、不是所有 AI 任务都需要超节点)
- [二、MoE 为什么天然需要高带宽通信](#二、MoE 为什么天然需要高带宽通信)
- [三、专家并行中的 All-to-All、Dispatch 和 Combine](#三、专家并行中的 All-to-All、Dispatch 和 Combine)
- [四、长上下文为什么放大 KV Cache 压力](#四、长上下文为什么放大 KV Cache 压力)
- [五、PD 分离为什么需要高速 KV Cache 传输](#五、PD 分离为什么需要高速 KV Cache 传输)
- 六、智能体和多智能体让推理更像集群系统
- 七、AI4S、多模态和世界模型也会推高基础设施要求
- 八、如何判断一个任务是否适合超节点
- 九、超节点不是万能加速器
- 十、总结
本文基于以下三份报告进行汇总、解释和二次整理:
- 华为《超节点发展报告
- 中兴《超节点技术白皮书
- H3C《超节点技术白皮书》
前三篇文章里,我们已经把超节点的基本概念、Scale-Up 架构和核心技术讲了一遍。
如果继续往下追问,一个更实际的问题会出现:超节点这么复杂,是不是所有 AI 任务都需要?
答案是否定的。
超节点不是"所有模型的标配",也不是简单把服务器做大。它更适合那些通信密集、内存密集、并行关系复杂,并且对延迟和吞吐都很敏感的 AI 负载。
换句话说,超节点真正要解决的不是"有没有更多卡",而是"这些卡之间能不能足够高效地协同"。
这一篇我们就从负载侧出发,看看哪些 AI 任务最容易把传统集群推到瓶颈边缘,也最容易体现超节点的价值。
一、不是所有 AI 任务都需要超节点
先把边界说清楚。
如果一个任务规模不大,单卡、单机或少量服务器 就能完成,而且通信主要是低频同步,那么超节点并不是刚需。
例如:
- 中小模型微调
- 常规文本分类、检索、排序
- 单机可承载的推理服务
- 通信不密集的离线批处理任务
这些任务更关心的是成本、稳定性、开发效率和资源利用率,不一定需要复杂的高带宽域。
但当模型和业务负载具备下面几个特征时,情况就变了。
| 负载特征 | 典型表现 | 为什么会推高超节点需求 |
|---|---|---|
| 通信密集 | TP、EP、All-to-All、All-Reduce 频繁发生 | GPU/NPU 容易等待网络 |
| 内存密集 | 参数、激活值、KV Cache 持续膨胀 | 单卡 HBM 容量和带宽不够 |
| 并行复杂 | DP、TP、PP、EP、CP 混合使用 | 调度和拓扑映射难度上升 |
| 时延敏感 | 在线推理、智能体、多轮交互 | 网络尾时延影响用户体验 |
| 资源动态 | Prefill/Decode 分离、多租户、多模型混部 | 需要更强资源池化和调度能力 |
所以判断一个任务是否需要超节点,不能只看模型参数量,还要看它的通信模式、内存访问模式和服务形态。
华为报告在不同并行模式下的通信特征中提到,张量并行、序列并行、上下文并行、专家并行等模式都会引入不同类型的通信。对于超大模型来说,训练效率往往不再只由单卡算力决定,而是由计算、通信和内存共同决定。
下面这张表来自华为报告,适合用来理解不同并行方式背后的通信压力。
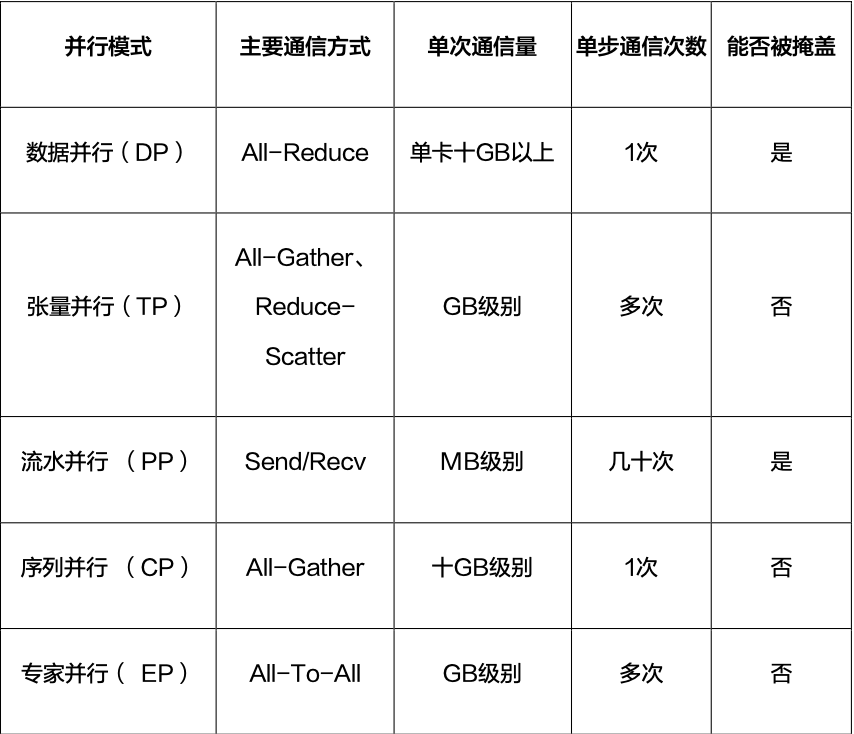
图源:华为《超节点发展报告》第 11 页,表 1。
二、MoE 为什么天然需要高带宽通信
MoE,也就是 Mixture of Experts ,中文常译为混合专家模型。
它的核心思想是:模型里有很多专家,但每个 token 不必经过所有专家,而是由路由器选择其中一部分专家参与计算。
这个设计有一个明显好处:模型总参数量可以很大,但每次实际激活的参数可以相对较少。也就是说,MoE 可以在扩展参数规模的同时控制单次计算成本。
但代价也很清楚:通信变复杂了。
在稠密模型里,一个 token 通常沿着相对固定的计算路径往前走。而在 MoE 模型里,每个 token 可能被路由到不同专家,专家又可能分布在不同 GPU/NPU 上。于是系统必须完成三件事:
- 把 token 分发到对应专家。
- 让不同专家完成计算。
- 再把结果聚合回来。
这就带来了 Dispatch、Combine 和大量 All-to-All 通信。
如果专家并行域跨服务器,通信就会从卡间互联进入跨机网络。专家越多、batch 越大、并发越高,通信压力越明显。此时 GPU/NPU 不一定缺算力,反而可能在等数据、等路由、等聚合。
这也是为什么 MoE 很容易成为超节点价值的放大器。
超节点通过更大的高带宽域,把更多专家放在更紧耦合的互联范围内。这样可以减少跨机通信比例,降低通信尾时延,并让专家分发和结果聚合更接近"节点内协同"。
中兴报告专门讨论了动态 MoE 场景中的通信问题,指出 Dispatch Multicast 和 Combine Reduce 会带来明显开销。在引入在网计算后,部分复制、分发和归约操作可以下沉到交换芯片侧完成,从而降低 GPU 端负担和网络尾时延。
三、专家并行中的 All-to-All、Dispatch 和 Combine
把 MoE 的通信拆开看,会更容易理解超节点为什么有用。
| 阶段 | 做什么 | 主要压力 |
|---|---|---|
| Router | 判断每个 token 应该去哪些专家 | 路由计算和负载均衡 |
| Dispatch | 把 token 分发到对应专家 | All-to-All、Multicast、跨卡数据搬运 |
| Expert Compute | 专家执行前向或反向计算 | 算力和显存 |
| Combine | 把专家输出聚合回来 | Reduce、All-to-All、尾时延 |
| Load Balance | 避免部分专家过热、部分专家空闲 | 调度和动态均衡 |
这里最容易被低估的是 All-to-All。
All-Reduce 的通信模式相对规整,优化路径比较成熟。但 All-to-All 更像很多设备之间同时互相交换数据,流量分布更复杂,也更容易出现热点。
在 MoE 里,如果某些专家被路由到的 token 特别多,就会造成专家负载不均衡。即使平均带宽看起来足够,局部热点和尾时延也可能拖慢整个 step。
这也是中兴报告强调在网计算的原因。交换芯片不只是转发数据,如果能参与 Multicast、Reduce、Combine 等操作,就有机会减少 GPU 端重复搬运,也能减少部分链路上的无效流量。
下面这张图来自中兴报告,用 MoE MMA 算子算力强度展示不同场景下的性能特征。它适合放在文章中解释:MoE 的瓶颈并不总是纯计算,通信和算子形态也会显著影响整体效率。
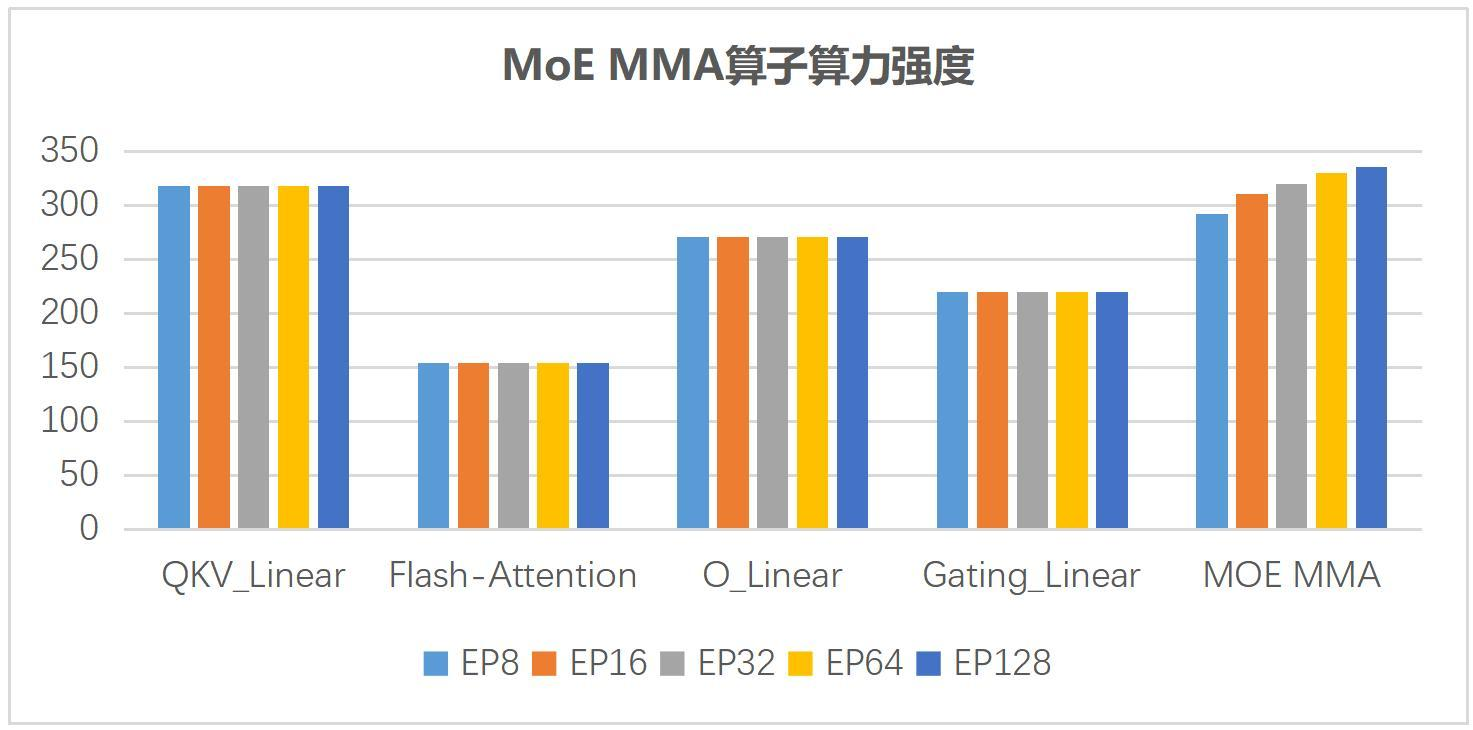
图源:中兴《超节点技术白皮书》第 33 页,图 3-2。
中兴报告还给出了 Qwen3-235B 在不同超节点形态下的仿真分析。报告指出,随着超节点形态增大,单卡训练性能逐渐提升,收益主要来自 MoE 算子性能改善,但收益也存在边际效应。
这点很关键:超节点不是越大越一定越好。它也有成本、拓扑、功耗、调度和边际收益问题。
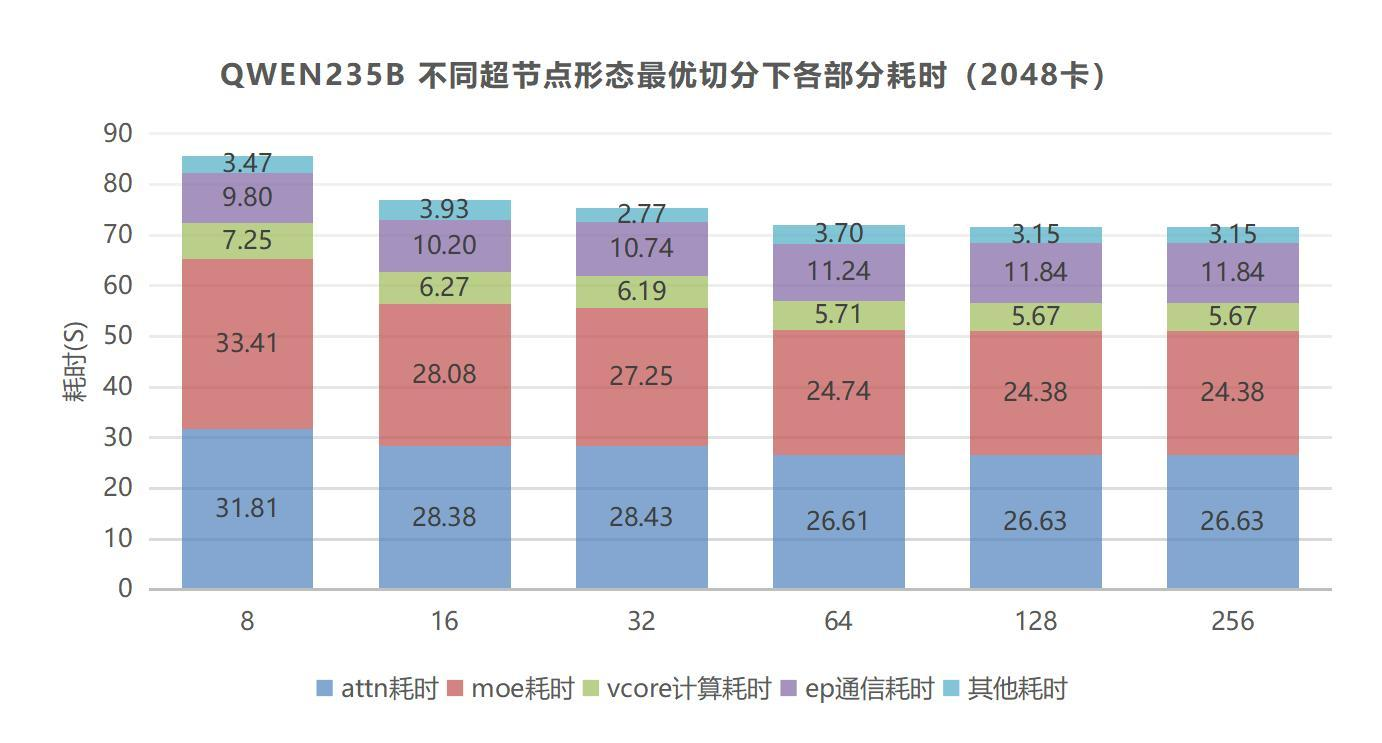
图源:中兴《超节点技术白皮书》第 33 页,图 3-3。
四、长上下文为什么放大 KV Cache 压力
除了 MoE,另一个典型场景是长上下文。
过去很多模型的上下文长度是 4K、8K、16K。现在越来越多模型开始支持 32K、128K,甚至更长上下文。上下文变长后,推理系统面对的不只是"多读一点输入",而是 KV Cache 快速膨胀。
KV Cache 可以简单理解为模型在生成过程中保存下来的中间状态。它的作用是避免每生成一个新 token 都重新计算全部历史上下文。
但这个缓存会随着下面几个因素增长:
- 上下文长度更长
- batch size 更大
- 并发请求更多
- 模型层数和隐藏维度更大
- 多轮对话和智能体工作流更复杂
当KV Cache变大,显存就会变成关键资源。单卡 HBM 再快,也有容量上限。单机 8 卡可以缓解一部分问题,但在百万 token、多会话、高并发推理场景下,缓存管理会越来越接近一个分布式系统问题。
这时超节点的价值主要体现在三个方面。
第一,扩大可用显存和内存范围 。
通过统一内存编址、资源池化、远程内存访问等能力,系统可以把更多内存资源组织起来,而不是被单机边界卡住。
第二,降低KV Cache迁移成本 。
当请求被调度到不同设备,或者 Prefill 和 Decode 被拆分到不同资源池时,KV Cache 需要在设备之间传输。高带宽、低时延互联会直接影响端到端延迟。
第三,提升推理资源利用率 。
不同请求的上下文长度差异很大,如果没有资源池化,容易出现有的设备显存紧张、有的设备空闲的情况。超节点提供的是更细粒度的资源组织能力。
华为报告提到,多级存储资源池化可以把 KV Cache 从单机显存限制中释放出来,为百万 token 级长上下文和高并发推理提供支撑。H3C 报告则进一步把 KV Cache 池化、CXL、远程内存访问和 AI Factory 里的"内存即服务"联系起来。
五、PD 分离为什么需要高速 KV Cache 传输
推理阶段还有一个越来越重要的架构变化:PD 分离。
P 指 Prefill,D 指 Decode。
Prefill 阶段主要处理用户输入 ,把上下文一次性编码成 KV Cache。这个阶段偏计算密集,适合使用吞吐更高的资源。
Decode 阶段则是逐 token 生成输出 。这个阶段往往更受内存带宽、调度延迟和并发管理影响。
把 Prefill 和 Decode 分离,可以让两类任务使用不同资源,从而提高整体效率。比如 Prefill 用一组计算资源,Decode 用另一组更适合高并发生成的资源。
但分离之后会带来一个新问题:Prefill 生成的 KV Cache 要传给 Decode。
如果这段传输慢,PD 分离带来的收益就会被抵消。尤其在长上下文场景下,KV Cache 本身很大,跨节点传输会直接影响首 token 延迟和整体吞吐。
H3C 报告强调,vLLM、Mooncake、Dynamo 等推理框架已经支持或探索 PD 分离,Prefill 与 Decode 之间需要高速网络和优化传输。超节点相比普通服务器集群的优势,正是在于它可以提供更强的高带宽域和更统一的资源抽象。
可以把 PD 分离理解成推理系统里的"专业分工"。专业分工能提高效率,但前提是分工之间的交接足够快。KV Cache 就是这个交接物,超节点则是在优化交接通道。
六、智能体和多智能体让推理更像集群系统
智能体应用会进一步放大推理侧的基础设施压力。
传统问答更像一次请求、一次回复。智能体则可能包含规划、工具调用、检索、代码执行、多轮反思、多模型协同等步骤。
这会带来几个变化。
第一,请求链路变长 。
一次用户请求可能拆成多个子任务,每个子任务又会触发模型调用、检索调用或工具调用。
第二,上下文状态变多 。
智能体需要保存任务历史、工具结果、环境状态和中间推理过程,KV Cache 和外部记忆都会增长。
第三,模型调用更不规则 。
不同任务的 token 长度、模型选择、工具调用次数都不一样,推理平台需要更强的动态调度能力。
第四,多智能体会引入协同通信 。
多个智能体之间可能需要交换中间结论、分工执行、互相校验,推理服务就不再只是单模型的串行生成。
在这种场景下,超节点不一定只是在加速某一次模型前向计算,更是在支撑一个更复杂的在线 AI 系统。
它需要同时解决计算、缓存、网络、调度和可靠性问题。
七、AI4S、多模态和世界模型也会推高基础设施要求
除了语言模型,AI4S、多模态和世界模型也会带来类似趋势。
AI4S,也就是 AI for Science,常见于蛋白质结构、材料模拟、气象预测、药物设计等场景。这类任务往往需要处理大规模科学数据,并把 AI 模型和仿真计算结合起来。
多模态模型则要同时处理文本、图像、音频、视频等数据。视频理解、实时语音交互、机器人感知等场景,会让输入数据量和中间特征显著增大。
世界模型和具身智能场景更进一步,它们不只是回答问题,而是要理解环境、预测状态、规划动作。这类任务对低时延推理、多模态融合和长时序记忆都有更高要求。
这些负载不一定都以 MoE 形式出现,但它们有共同点:
- 数据量更大
- 上下文更长
- 并行关系更复杂
- 在线交互更多
- 系统稳定性要求更高
这正是超节点适合发挥作用的地方。
八、如何判断一个任务是否适合超节点
工程上,不应该一看到大模型就直接上超节点。更合理的方式,是从负载画像出发。
可以用下面这张表做初步判断。
| 判断问题 | 如果答案是"是" | 对超节点需求的影响 |
|---|---|---|
| 是否存在大规模 TP/EP/CP? | 高频通信会跨越多卡甚至多机 | 更需要高带宽 Scale-Up 域 |
| 是否有大量 All-to-All? | MoE 专家分发和聚合压力大 | 更需要优化拓扑和在网计算 |
| KV Cache 是否成为显存瓶颈? | 长上下文、高并发推理占用显存 | 更需要内存池化和高速迁移 |
| 是否采用 PD 分离? | Prefill 与 Decode 之间要传缓存 | 更需要高速 KV Cache 通道 |
| 是否对尾时延敏感? | 在线服务体验受慢请求影响 | 更需要稳定低时延互联 |
| 是否存在多模型、多租户混部? | 资源碎片和调度复杂度上升 | 更需要逻辑超节点和资源池化 |
如果一个任务只满足其中一两项,未必马上需要超节点。但如果同时满足通信密集、缓存巨大、在线低时延、资源动态调度这些条件,超节点的价值就会明显上升。
九、超节点不是万能加速器
这一点也值得强调。
超节点可以改善很多 AI 负载的通信和资源组织效率,但它不是万能加速器。
至少有几个边界需要注意。
第一,超节点不能消除算法本身的复杂度 。
如果模型并行策略设计不合理,或者专家负载严重不均衡,硬件互联再强也只能缓解一部分问题。
第二,超节点不能替代软件栈优化 。
通信库、推理框架、调度器、编译器、内存管理都要适配底层拓扑,否则硬件能力无法充分释放。
第三,超节点也有边际收益 。
中兴报告的仿真分析已经提示,超节点形态扩大后,性能会提升,但收益并不是无限线性增长。规模越大,拓扑、功耗、散热、可靠性和调度问题越复杂。
第四,超节点需要匹配业务负载 。
如果业务主要是小模型、短上下文、低并发,或者通信不密集,那么更简单的集群方案可能反而更经济。
所以真正合理的判断不是"要不要超节点",而是"哪些负载、哪些并行域、哪些服务阶段应该放进超节点"。
十、总结
从负载角度看,超节点最适合三类 AI 任务。
第一类是通信密集型任务 。
典型代表是 MoE、专家并行、All-to-All、All-Reduce 密集训练。它们需要更大的高带宽域和更低的网络尾时延。
第二类是内存密集型任务 。
典型代表是长上下文推理、百万 token、多轮对话和 KV Cache 池化。它们需要更大的显存/内存资源池,以及更高效的缓存迁移能力。
第三类是协同复杂型任务 。
典型代表是 PD 分离、智能体、多智能体、多模态和 AI4S。它们不只是需要算力,还需要计算、通信、内存、调度和运维共同协同。
所以,超节点不是为了让所有任务都"堆更多卡",而是为了让最复杂、最通信密集、最内存敏感的 AI 负载,能够在更大的计算单元里高效运行。
下一篇文章,我们会回到报告本身,对华为、中兴、H3C 三份超节点报告做一次横向对比:它们分别如何定义超节点?各自强调什么技术路线?共同指向了什么产业趋势?