摘要
基本上,量化任务可被视为分别为权重和输入寻找最优的低比特量化区间。为了保持注意力机制的功能性,我们在传统的量化目标中引入了一种排序损失(ranking loss),旨在量化后保持自注意力结果的相对顺序。此外,我们深入分析了不同层的量化损失与特征多样性之间的关系,并通过利用每个注意力图和输出特征的核范数,探索了一种混合精度量化方案。
文章目录
- 摘要
- Introduction
- [3 Methodology](#3 Methodology)
-
- [3.2 Optimization for Post-Training Quantization](#3.2 Optimization for Post-Training Quantization)
- [3.3 Mixed-Precision Quantization for Vision Transformer](#3.3 Mixed-Precision Quantization for Vision Transformer)
- [5 Conclusion](#5 Conclusion)
Introduction
本文研究了面向视觉Transformer模型的后训练量化方法,采用混合精度以实现更高的压缩率和加速比 。我们将Transformer中的量化过程形式化为一个优化问题,旨在寻找最优的量化区间。
具体而言,我们的目标是最大化全精度输出与量化输出之间的相似性。为了更好地保留注意力机制的功能,我们深入分析了注意力层与传统层(如多层感知机MLP)之间的差异。随后,引入了一种排序损失(ranking loss),以保持注意力值的相对顺序。
此外,我们提出根据特征多样性确定各层的位宽,即通过注意力图和输出特征计算核范数。我们交替搜索所有层中权重和输入的量化区间,以获得最佳的量化效果。此外,引入偏置校正以减少累积量化误差。在多个基准数据集上的实验结果表明,我们所提出的算法在性能上优于当前最先进的后训练量化方法。
3 Methodology
在本节中,我们详细阐述针对视觉Transformer提出的混合精度训练后量化方案。具体介绍了面向全连接层的相似度感知量化方法,以及面向自注意力层的排序感知量化方法。此外,还引入了用于优化的偏置校正方法,以及基于注意力图与输出特征核范数的混合精度量化策略。
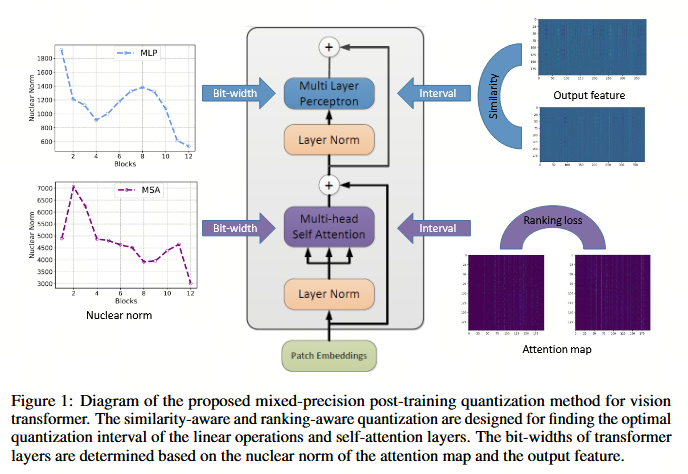
3.2 Optimization for Post-Training Quantization
第一部分:线性操作的相似度感知量化 (Similarity-Aware Quantization)
文本首先关注 Transformer 层中的线性操作(Linear Operations),这包括多头注意力中的线性投影(MSA)和前馈神经网络(MLP)。
原始输出公式为:
O l = X l W l O_l = X_l W_l Ol=XlWl
其中 X l X_l Xl 是输入, W l W_l Wl 是权重。
量化后的输出 O ^ l \hat{O}_l O^l 涉及对权重和输入进行量化和反量化操作。文本指出,量化区间( Δ \Delta Δ)实际上控制了量化过程中的截断阈值 。如果 Δ \Delta Δ 选得不好,量化后的特征图与原特征图之间的差异(相似度)就会很大。
我们的动机在于优化权重 Δ W l \Delta _W^l ΔWl 和输入 Δ X l \Delta _X^l ΔXl 的量化区间,以提升 O l O^l Ol 与其估计值 O ^ l \widehat{O}^l O l 之间的相似度,其中输入 X l X^l Xl 源自一个具有 N N N 个样本的给定校准数据集。具体而言,该校准数据集的大小远小于常规的训练数据集。在第 l l l 个 Transformer 层中,相似度感知的量化可形式化为
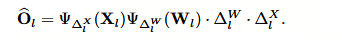
优化目标
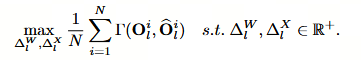
其中, Γ ( O i l , O ^ i l ) Γ(O_i^l, \hat{O}_i^l) Γ(Oil,O^il) 表示原始输出特征图与量化后输出特征图之间的相似度。在本文中,我们采用皮尔逊相关系数作为相似度的度量标准。
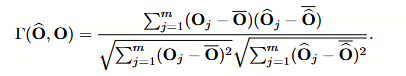
作者的目标是优化权重量化区间 Δ W l \Delta W_l ΔWl 和输入量化区间 Δ X l \Delta X_l ΔXl ,以最大化原始输出 O l O_l Ol 与量化输出 O ^ l \hat{O}_l O^l 之间的相似度。
数学表达为优化问题:
max Δ W l , Δ X l 1 N ∑ i = 1 N Γ ( O l i , O ^ l i ) \max_{\Delta W_l, \Delta X_l} \frac{1}{N} \sum_{i=1}^{N} \Gamma(O^i_l, \hat{O}^i_l) ΔWl,ΔXlmaxN1i=1∑NΓ(Oli,O^li)
约束条件: Δ W l , Δ X l ∈ R + \Delta W_l, \Delta X_l \in \mathbb{R}_+ ΔWl,ΔXl∈R+(即量化区间必须为正数)。
相似度度量:皮尔逊相关系数
文本采用**皮尔逊相关系数(Pearson Correlation Coefficient)**作为相似度度量 Γ \Gamma Γ。
- 为什么用这个? 皮尔逊相关系数衡量的是两个变量之间的线性相关程度。在量化中,我们不仅希望数值接近,更希望特征图的"分布形状"和"相对关系"保持一致。相关系数为 1 表示完全正相关,即两者变化趋势完全一致。
第二部分:自注意力的排名感知量化 (Ranking-Aware Quantization)
自注意力(Self-Attention)是 Transformer 的核心,它计算序列中所有位置之间的全局相关性。
- 现象 :文本通过实验发现(参考 Fig 1),量化后,注意力图(Attention Map)中值的相对顺序(Rank)发生了改变。
- 后果:即使数值差异很小,如果关键位置(权重最大的位置)的排名变了,模型就会"看错"重点,导致性能显著下降。
解决方案:引入排名损失 (Ranking Loss)
为了解决这个问题,作者在优化目标中引入了一个排名损失项(Ranking Loss)。
新的优化目标公式:
max Δ W l , Δ X l 1 N ∑ i = 1 N Γ ( O l i , O ^ l i ) − γ ⋅ L r a n k i n g \max_{\Delta W_l, \Delta X_l} \frac{1}{N} \sum_{i=1}^{N} \Gamma(O^i_l, \hat{O}^i_l) - \gamma \cdot L_{ranking} ΔWl,ΔXlmaxN1i=1∑NΓ(Oli,O^li)−γ⋅Lranking
这里有两个竞争目标:
- 最大化相似度(第一项):保持输出特征的整体一致性。
- 最小化排名损失(第二项):保持注意力权重的相对顺序。
γ \gamma γ 是一个权衡超参数,用于平衡这两个目标的重要性。

排名损失的定义 ( L r a n k i n g L_{ranking} Lranking)
L r a n k i n g = ∑ h , k ∑ i = 1 w − 1 ∑ j = i + 1 w Φ ( ( A ^ k i − A ^ k j ) ⋅ sign ( A k i − A k j ) ) L_{ranking} = \sum_{h,k} \sum_{i=1}^{w-1} \sum_{j=i+1}^{w} \Phi((\hat{A}{ki} - \hat{A}{kj}) \cdot \text{sign}(A_{ki} - A_{kj})) Lranking=h,k∑i=1∑w−1j=i+1∑wΦ((A^ki−A^kj)⋅sign(Aki−Akj))
- 解释 :
- A A A 是原始注意力图, A ^ \hat{A} A^ 是量化后的注意力图。
- sign ( A k i − A k j ) \text{sign}(A_{ki} - A_{kj}) sign(Aki−Akj) 判断原始图中位置 i i i 和 j j j 的大小关系。
- ( A ^ k i − A ^ k j ) (\hat{A}{ki} - \hat{A}{kj}) (A^ki−A^kj) 是量化后的大小关系。
- 如果两者符号相反(即顺序颠倒了),或者差距不够大,损失函数 Φ \Phi Φ(铰链损失 Hinge Loss)就会产出正值。
- 目的:惩罚那些在量化后发生了顺序反转或排序错误的情况,强制模型保留原始注意力图的"排名结构"。
算法实现:交替搜索策略
为了求解上述复杂的优化问题,文本提出了一种简单高效的交替搜索方法(Alternating Search Method)。
-
初始化:
- Δ W l \Delta W_l ΔWl(权重区间)初始化为权重的最大值。
- Δ X l \Delta X_l ΔXl(输入区间)初始化为输入的最大值。
- 这是基于经验,因为最大值通常能覆盖大部分数据分布。
-
交替优化:
- 步骤 1 :固定输入量化区间 Δ X l \Delta X_l ΔXl,优化权重量化区间 Δ W l \Delta W_l ΔWl。
- 步骤 2 :固定权重量化区间 Δ W l \Delta W_l ΔWl,优化输入量化区间 Δ X l \Delta X_l ΔXl。
- 重复步骤 1 和 2,直到目标函数收敛或达到最大迭代次数。
-
搜索策略:
- 搜索空间被线性划分为 C C C 个候选选项,范围在 α Δ l , β Δ l \\alpha \\Delta_l, \\beta \\Delta_l αΔl,βΔl 之间( α , β \alpha, \beta α,β 是缩放系数,如 0.5 到 1.5,用于扩展原始最大值形成的区间,以寻找更好的边界)。
- 在这 C C C 个候选值中进行简单的搜索,找到使目标函数最优的那个 Δ \Delta Δ。
为什么这个方法重要?
- 针对性强 :传统的量化方法通常只关注数值误差(如 MSE),但 Transformer 对结构信息(如注意力的排名)非常敏感。该方法明确指出了这一点并加以解决。
- 双管齐下 :
- 对于线性层 ,关注整体特征的相关性(Similarity)。
- 对于注意力层 ,关注决策依据的顺序(Ranking)。
- 计算效率高:提出的交替搜索策略避免了复杂的梯度下降,仅需简单的搜索和固定变量优化,适合在实际部署中进行离线量化校准。
潜在疑问解答
-
Q: 为什么不用梯度下降直接优化 Δ \Delta Δ?
- A: 量化操作(Quants/Dequants)通常是不可微的(非连续),导致梯度无法直接回传。因此,作者采用了基于搜索(Search-based)的方法,这在量化领域是一种常见且有效的技巧(如 QDrop, SmartQuant 等思路类似)。
-
Q: 校准数据集很少怎么办?
- A: 文本提到校准数据集 D D D 远小于训练数据集。由于使用的是基于统计特性的相似度相关系数和排名损失,少量的代表性数据通常足以捕捉分布特征,不需要全量数据。
-
Q: γ \gamma γ 参数怎么调?
- A: γ \gamma γ 控制排名损失的权重。如果 γ \gamma γ 太大,模型可能过于关注顺序而忽略数值精度;如果太小,则无法纠正注意力顺序错误。通常需要通过验证集进行超参数搜索。
这段文字描述了一种先进的 Transformer 量化框架。它不再盲目地最小化量化误差,而是语义驱动地优化量化参数:
- 在数值层面,通过最大化皮尔逊相关系数,保证特征图的统计相似性。
- 在结构层面,通过最小化排名损失,保证注意力机制中关键信息的相对顺序不被破坏。
这种方法通过交替优化权重和输入的量化区间,能够在保持极低精度的同时,最大限度地保留 Transformer 模型的性能。
3.3 Mixed-Precision Quantization for Vision Transformer
我们探索混合精度量化,其中为更敏感的层分配更多的位,以保留性能。考虑到变换器层的独特结构,我们为 MSA 或 MLP 模块中的所有操作分配相同的位宽。这也有利于硬件实现,因为权重和输入都被分配了相同的位宽。
奇异值分解 (Singular value decomposition, SVD) 是线性代数中一种重要的矩阵分解方法。它处理一个基因表达数据的矩形矩阵,其表述可以写为: M = U Σ V M = UΣV M=UΣV
其中,Σ 的对角线元素 σ i = Σ i i σ_i = Σ_{ii} σi=Σii 被称为矩阵 M 的奇异值。核范数是奇异值之和,反映了矩阵的数据相关性。
在本文中,我们提出通过 MSA 模块中注意力图以及 MLP 模块中输出特征的核范数来估计 Transformer 层的敏感度。
核范数可用于缩减混合精度设置的搜索空间,从而为对模型更敏感的层分配更高的位宽,反之则为对模型较不敏感的层分配更低的位宽。
受文献 10 中方法的启发,我们采用帕累托前沿方法Pareto frontier来确定位宽。其主要思想是依据以下指标,根据各候选位宽配置所引起的总二阶扰动大小,对每个候选位宽配置进行排序:
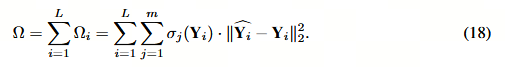
给定目标模型规模,我们根据候选位宽配置的 Ω 值对其进行排序,并选择具有最小 Ω 值的位宽配置。各 Transformer 层中注意力图和输出特征的核范数如图 1 所示。可以看出,它们在不同 Transformer 层中呈现出多样性。
5 Conclusion
在本文中,我们提出了一种针对视觉Transformer的新型训练后量化方案,其中:
- (1)各层的位宽基于Transformer层中注意力图的核范数和输出特征而动态变化。
- (2)为解决量化带来的优化问题,我们提出搜索最优量化区间,以在量化特征图与原始特征图之间保持相似度。
- (3)此外,我们深入分析了注意力层与传统卷积层之间的差异,并引入排序损失,以保持注意力值的相对顺序。