你好,我是 Guide 。前面已经聊过好几篇 AI Coding 工具的实战了,Claude Code 接 GLM-5.1 和 DeeSeek V4、GPT5.5 + Codex 等都写过了。
最近几天一直在研究 :Agent 怎么更好地操作真实网页,比如让 Agent 去查我的 GitHub Issue、直接自动化操作页面填写表单。
技术群里的一位朋友推荐了个开源项目:browser-act/skills。
其实就是的两个 Agent Skill:browser-act 和 browser-act-skill-forge ,由 BrowserAct 开源。
在我写稿时,这个仓库已有 1.2K Stars,MIT 协议,主语言是 Python。
这个仓库没有再造一个浏览器自动化工具。它做的是把真实网页任务里最麻烦的那部分,包装成了 Agent 可以直接调用的能力:打开页面、点击按钮、填写表单、处理登录态、滚动加载、截图、捕获网络请求,再把结果整理成结构化数据。
有什么厉害的地方
用 Claude Code、Cursor 这类 Agent 跑任务时,只要步骤里出现"去某个网站查一下",就很容易卡住。
静态页面还好,curl 一下可能就能拿到内容。但现在更多网站不是这样:页面靠前端动态渲染,数据藏在 XHR / fetch 请求里,列表还要点"加载更多"或者翻页才能继续看。
这些其实还只是基础难点。
真正麻烦的是登录态和反自动化检测。很多页面必须先登录,有些还要过 2FA;session 一断,整个流程就得从头来。
更别说现在不少网站会频繁触发验证码、Cloudflare Challenge、DataDome、reCAPTCHA 这类反爬机制,一旦识别出无头浏览器或自动化环境,返回的就不再是正常页面,而是验证页、拦截页,甚至直接空白。
这时候 Agent 缺一个能稳定进入页面、复用登录态、处理真实浏览器交互的执行层。
BrowserAct 补的就是这块:让 Agent 像人一样打开网页、点击按钮、填写表单、复用登录态,尽量把一个网页任务完整跑完,而不是停在"页面进不去"这一步。
官网给过一个演示:用一句 prompt 抓取 Amazon Electronics Bestsellers 前 80 条数据,字段包括 price、rank、reviews,最后导出 bestsellers.csv,页面展示耗时是 2m 14s。
这个例子能说明它的定位:抓取、解析、导出,把网页任务执行成一个可用结果。
BrowserAct Skill 是什么
这次开源的是两个可安装的 Agent Skill。
第一个是 browser-act。
它更像浏览器执行层,适合处理临时网页任务:打开页面、点击、输入、截图、读取登录后的页面、提取结构化数据、捕获 XHR / fetch / HAR 请求,或者检查页面视觉效果。
它支持两类浏览器路径。
一种是 Stealth Browser,适合处理容易触发验证、反自动化检测的页面。另一种是 Real Chrome Control,可以接管你本地正在使用的 Chrome,把登录态、cookies、扩展都带过去。
这也是它和普通无头浏览器不太一样的地方。很多任务卡住,压根进不去:没有登录态,session 在无头环境里不延续,或者站点识别出自动化环境后,返回的内容直接变了。
另外,它不会把整页 HTML 原样塞给模型。
真实网页里有导航、广告、脚本、隐藏节点、样式代码。模型直接读这些,容易被噪音干扰,也浪费上下文。BrowserAct 让浏览器层先完成等待、筛选、截图、请求捕获和结构化提取,再把更干净的结果交给 Agent。
第二个是 browser-act-skill-forge。
它可以把重复网页任务沉淀成可复用 Skill。你描述目标网站和任务,它先探索数据来源,优先找 API endpoint,不合适再回退到 DOM,验证通过后生成 SKILL.md 和脚本。
两者的区别:browser-act 用来跑通当下这个网页任务;browser-act-skill-forge 用来把这次调通的过程记下来,下次不用重头摸索。
快速上手
如果你是在 Claude Code、Cursor、OpenClaw 这类 Agent 环境里使用,最省事的方式是直接让 Agent 帮你安装。
比如可以这样说:
sql
请帮我安装 BrowserAct Skill,并检查运行环境。
安装完成后,执行 browser-act get-skills core --skill-version 2.0.0如果还想使用 Skill Forge,可以继续让 Agent 安装:
r
请继续安装 browser-act-skill-forge,并确认它可以正常读取 Skill 说明。实际执行时,Agent 通常会完成这些步骤:
sql
npx skills add browser-act/skills --skill browser-act
npx skills add browser-act/skills --skill browser-act-skill-forge
browser-act get-skills core --skill-version 2.0.0BrowserAct 不只是一个命令行工具,它还涉及浏览器选择、登录态处理、安全确认和执行流程。
Agent 必须先读完整 Skill 指令,才知道哪些动作可以直接做,哪些动作必须停下来让用户确认。
仓库里也不只有这两个基础 Skill,还放了一批现成场景,比如 Amazon ASIN 查询、Amazon Best Selling Products、Google News、Google Maps、YouTube Transcript Extractor 等。

实战一:读取登录后的 GitHub Issue
第一个任务我直接让 BrowserAct 进入我已经登录的 GitHub 仓库,读取最近的 open issue。
提示词如下:
bash
使用 browser-act 进入我已登录的 GitHub 仓库,读取最近 10 个 open issue,
按 bug / feature / question 分类,输出:
1. 标题
2. 关键上下文
3. 可能涉及的模块
4. 建议优先级
5. 是否需要我进一步确认这个场景很贴近日常开源维护。
我平时会收到读者反馈、Issue、PR 和配置问题。很多 Issue 是文档改进、使用疑问、部署问题、错误提示不清楚、PR 关联讨论混在一起。
普通搜索工具处理不了这类任务。它没有我的登录态,也不知道我在仓库里能看到什么。
BrowserAct 解决的是这个断点:复用本地 Chrome 登录状态,让 Agent 读取我本来就有权限访问的页面。
实际执行时,它先列出本地 Chrome Profile,并说明接下来的操作:创建一个 Chrome 浏览器环境,导入我的 GitHub 登录态,然后打开 Snailclimb/interview-guide 的 Issues 页面。
确认后,它才继续执行,并导入本地 Chrome 的 cookies 和 localStorage。
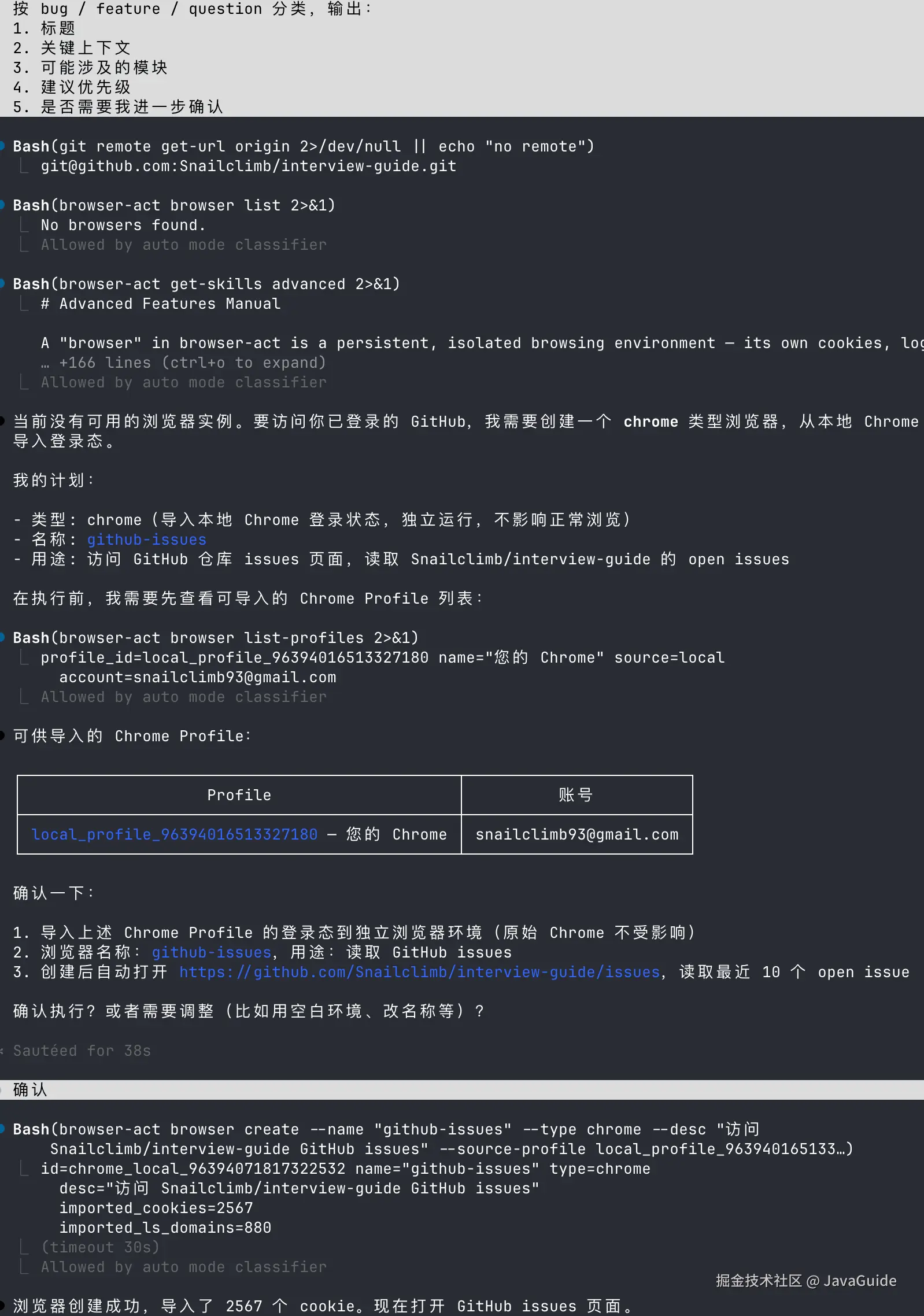
随后它打开 Issue 页面,发现当前有 6 个 open issue,于是逐个进入详情页读取上下文。最后输出了一份分类报告:3 个 Feature、2 个 Bug、1 个 Question。
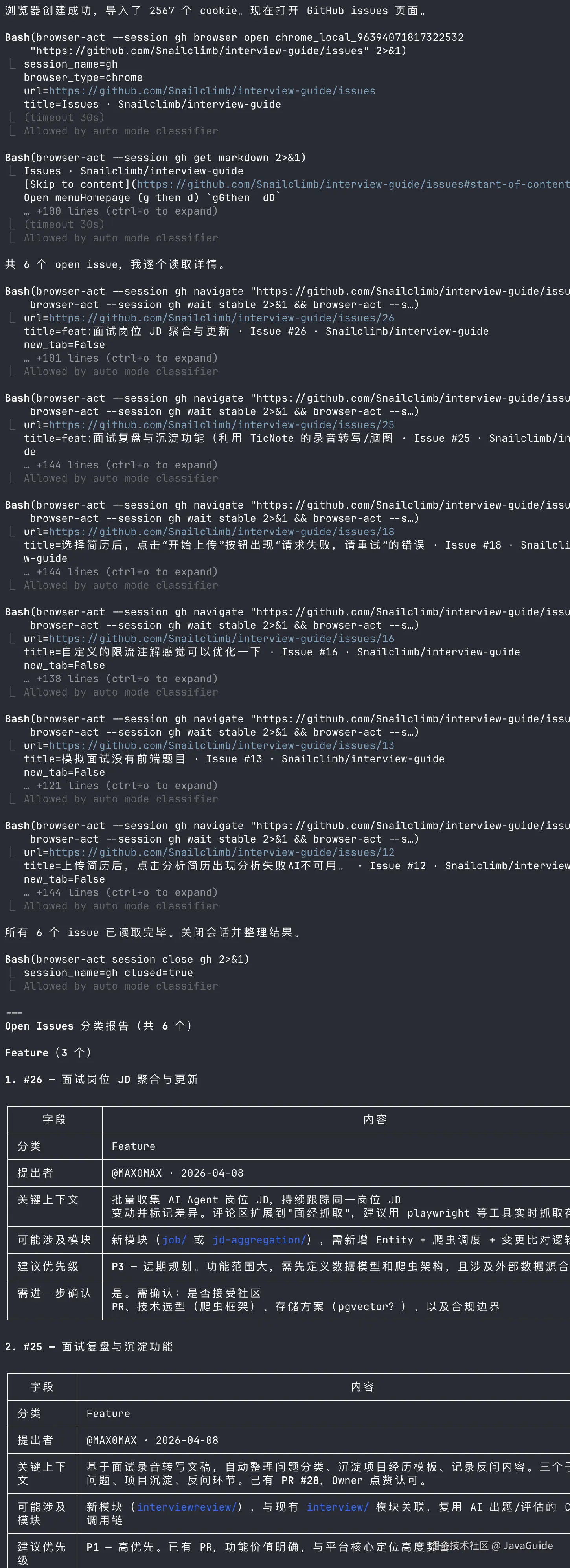
这个任务的麻烦点在它必须进入登录后的协作页面,还要读 Issue 详情里的上下文。
哪个 Issue 已经有 PR,需要优先 Review;哪个问题已经修复,可以直接关闭;哪些 Issue 都和自部署配置、错误提示不清晰有关,可以合并处理。这些信息只扫列表看不出来,得点进详情页看讨论。
以前也能做,只是要人自己点开每个 Issue,看完上下文,再手动归类。现在 Agent 可以先做第一轮整理,我再决定哪些要处理、哪些要追问、哪些要关闭。
边界也要说清楚:读取、整理、归类可以交给 Agent,关闭 Issue、合并 PR、删除数据、提交审批这类状态变更,必须让人确认。
实战二:Agent 改完页面后,直接做一轮冒烟验收
第二个场景更贴近 AI Coding。
现在很多人会用 Claude Code、Cursor、Codex 改前端页面。问题是,Agent 改完代码后,经常会告诉你"已完成",但页面到底能不能跑通,还得人自己打开浏览器确认。
按钮能不能点?下拉框能不能选?默认值是否合理?错误提示是不是人话?提交后有没有真的生效?
这些问题光读代码不一定看得出来。
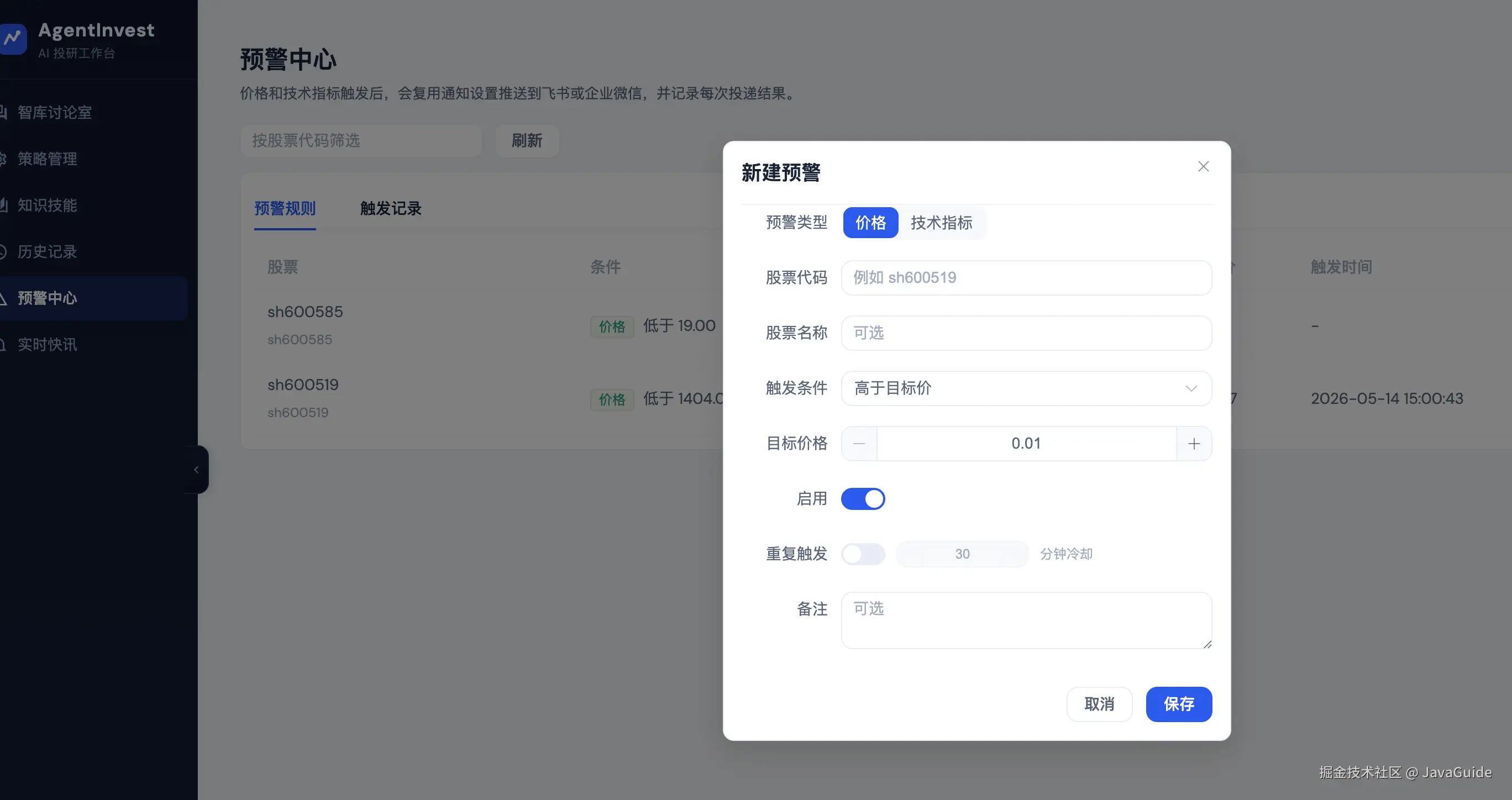
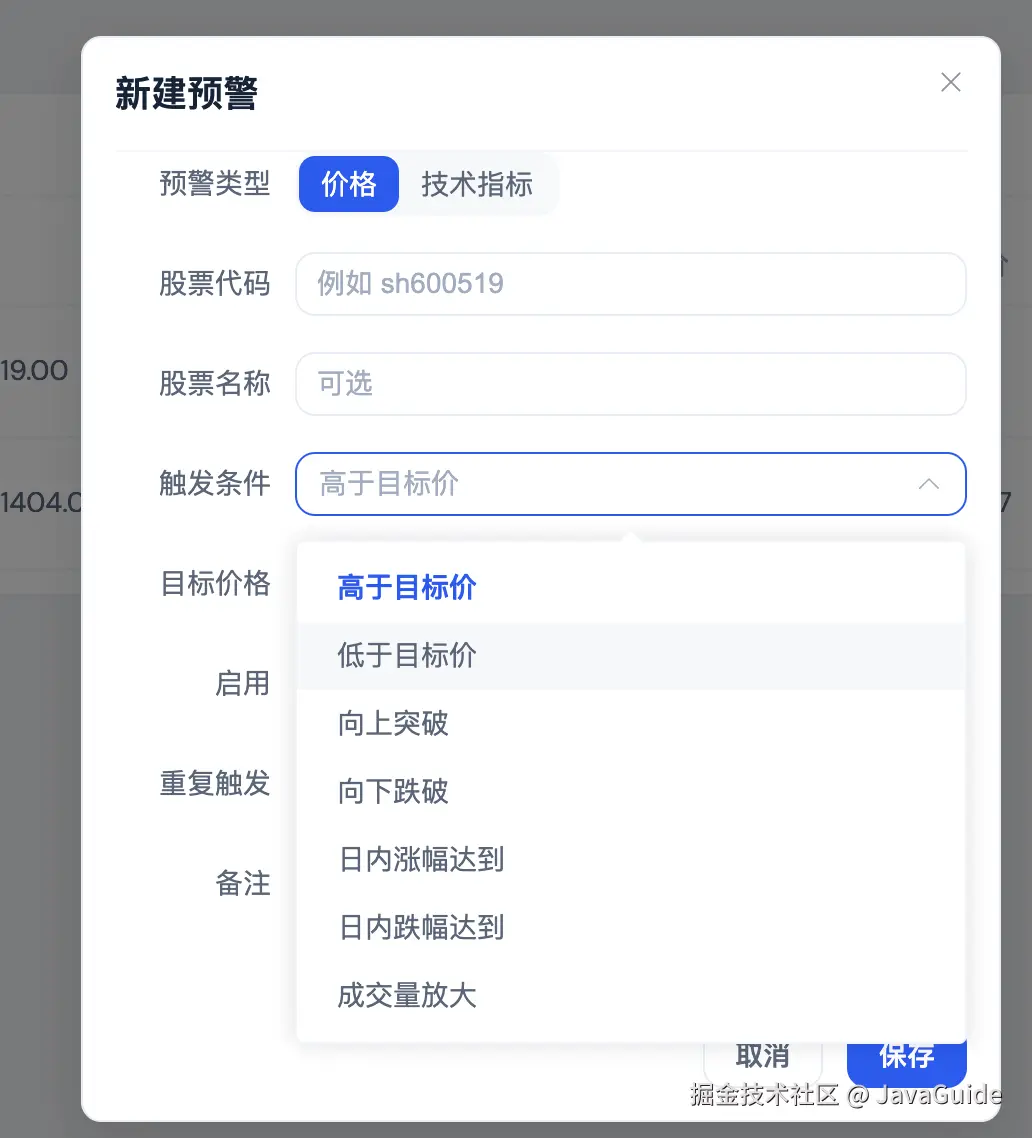
所以我让 BrowserAct 打开本地项目的预警中心页面,跑一遍新增预警流程:
bash
打开 http://localhost:3000/alerts
新增一个价格预警:
股票代码:sh600585
股票名称:海螺水泥
条件:价格低于 19
记录页面中出现的问题,包括字段校验、枚举文案、按钮状态、错误提示和截图。这个例子要验证的是:Agent 改完前端页面后,能不能自己打开本地页面,把关键流程点一遍。
BrowserAct 打开 http://localhost:3000/alerts 后,识别到这是 AgentInvest 的预警中心。随后它点击"新建预警",输入股票代码 sh600585,把触发条件切换成"低于目标价",再把目标价格填成 19。整个过程中,它保存了初始页面、空表单、填写完成后、提交后等多张截图。
这次跑的是一段完整操作序列:打开页面,找到新建按钮,填写表单,切换枚举值,提交,截图,最后清理掉测试数据。
它也发现了几个具体问题。
比如目标价格默认值是 0.01,对 A 股价格预警来说不太合适。更合理的方式是默认留空,让用户主动填写;或者在输入股票代码后,自动拉取当前价格作为参考。
再比如触发条件文案不够清楚。"高于目标价""低于目标价"容易理解,但"向上突破""向下跌破""成交量放大"缺少参照物。用户不知道是突破均线、前高,还是某个技术指标。这里应该在选择不同条件后,动态提示参数含义。
最后,BrowserAct 删除了刚才创建的测试预警,恢复了现场。
这类能力对 AI Coding 的价值:Agent 不再只停留在"代码看起来没问题",而是能把页面打开、流程跑一遍、截图留证据。
它不能替代完整 E2E 测试,也不能保证覆盖所有异常分支。但承担一轮轻量冒烟验收是够用的。尤其是按钮状态、表单文案、错误提示、空状态、截图记录这些偏体验的问题,很多时候比单纯读代码更容易暴露出来。
实战三:用 Skill Forge 沉淀一个 GitHub 项目调研 Skill
前两个例子都是 browser-act 在直接执行网页操作。第三个例子要说的是另一个 Skill:browser-act-skill-forge。
它适合把反复出现的网页任务沉淀成可复用 Skill。
写 AI Agent、MCP、Skill 相关内容前,我经常要调研一批 GitHub 项目。
我会看 Star、Fork、最近更新时间、License、README 安装方式、有没有 examples,是否提到 Skill / MCP / CLI,最后再判断这个项目适不适合写进文章。
这个任务不难,但很烦。
如果只查一两个仓库,手动打开 GitHub 就行。但如果一次看 10 个、20 个项目,每次都让 Agent 重新打开仓库、重新找 README、重新判断字段,就会浪费很多时间,也容易漏信息。
这类任务适合用 Skill Forge。
先安装:
bash
npx skills add browser-act/skills --skill browser-act-skill-forge然后给它一个明确的 Forge 任务:
bash
请使用 browser-act-skill-forge,帮我 Forge 一个 GitHub 项目调研 Skill。
Skill 名称:github-repo-research
输入:
一个 GitHub repo URL 列表,例如:
- https://github.com/browser-act/skills
- https://github.com/microsoft/playwright
- https://github.com/modelcontextprotocol/servers
输出字段:
1. 项目名称
2. GitHub URL
3. Star 数
4. Fork 数
5. 最近更新时间
6. License
7. README 里的安装方式
8. 是否有 examples / demos
9. 是否提到 Skill / MCP / CLI
10. 是否适合 Claude Code / Cursor / Codex 这类 Agent 使用
11. 适合写进文章的亮点
12. 不确定或需要人工确认的信息
要求:
- 优先探索稳定数据来源,能用 API 就不要硬扒页面
- README 没写的信息标记为"未确认",不要猜
- 输出 Markdown 表格,同时保存 JSON
- 先用上面 3 个公开仓库跑通端到端测试,再生成可复用 Skill这个例子跑出来以后,Skill Forge 没有强行走浏览器页面,而是选择了更稳定的 GitHub API。
GitHub 仓库数据本来就有结构化 API,走 API 比从 DOM 扒快多了,稳定性也更好。
Skill Forge 这次的选择说明它会先判断哪条路径更可靠,再决定怎么实现。
最后生成的是一个本地 Skill:
text
.agents/skills/github-repo-research/
├── SKILL.md
└── scripts/
└── research-repos.py后续再用时,就不需要重新 Forge 了,直接调用这个 Skill:
text
使用 github-repo-research Skill,调研下面这些仓库,并输出 Markdown + JSON:
- https://github.com/xxx/xxx
- https://github.com/yyy/yyy
- https://github.com/zzz/zzz
重点关注:
1. 是否适合写进 AI Agent 工具盘点文章
2. 是否有清晰安装方式
3. 是否能和 Claude Code / Cursor / Codex 组合使用
4. 哪些信息不确定,需要我人工确认输出如下:
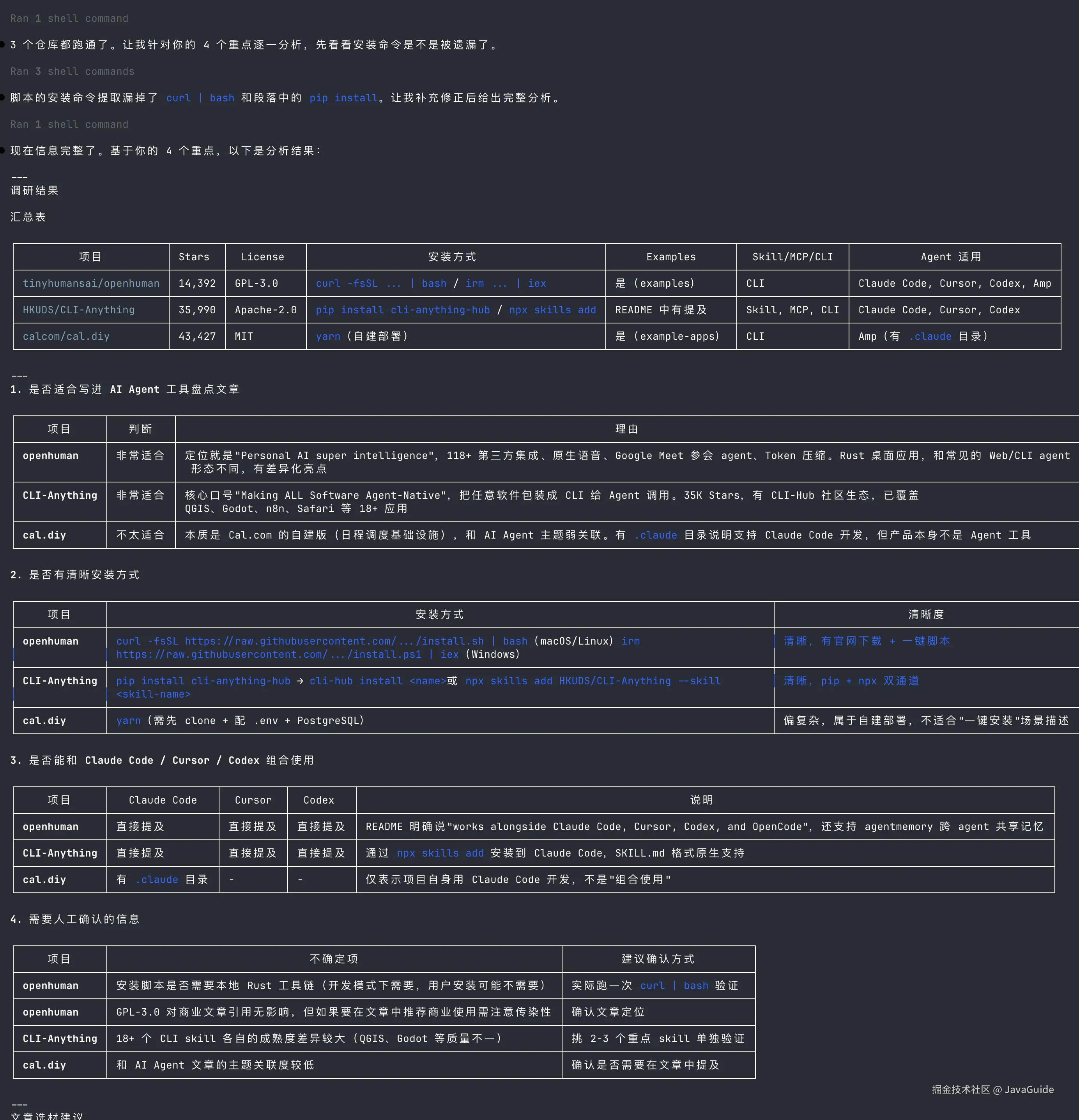
这里真正有用的不是那个 Python 脚本本身,而是它记录了怎么拿到数据的过程。下次换一批仓库,可以直接复用这个过程。
Skill Forge 并不是唯一能写 Skill 的方式。目标网站很熟、数据源也清楚的话,开发者自己写脚本再补一个 SKILL.md,效果一样。
它更适合不确定性高的任务:数据源在哪不清楚,先得探一遍;探完了写脚本,脚本跑起来还得验证一次。这个过程手动做一遍挺费时间,Skill Forge 能把第一次摸索过程压缩掉一部分。
所以,Skill Forge 省的是第一次摸索的时间:第一次找到数据源,第一次调通请求,第一次跑通脚本。这个过程做完之后存下来,下次换一批 URL 直接跑。
API Key 适合放在哪些任务里
这几个实战都没用到 API Key,本地 browser-act 就能跑起来,不需要额外账号。
临时网页任务直接用本地 browser-act;需要登录态的任务,用 Real Chrome 复用本地会话;任务稳定后,再用 Skill Forge 沉淀成可复用 Skill。
API Key 主要用在更重的场景:批量网页抽取、跨页面搜索、长期监控,或者页面频繁触发验证码、Cloudflare、DataDome、reCAPTCHA 等反爬机制时。
你可以在 BrowserAct 官网创建 Key,完全免费:
写在最后
这几天用下来,BrowserAct Skill 做的事情可以概括成一句话:把浏览器操作变成 Agent 可以调用的一层工具。自动打开页面、填写表单、复用登录态、捕获请求、截图记录,最后把结果交给上层处理。
接入日常开发和工作流之后,真的能够省事不少。
而且,它并不是直接让 Agent 在网页里乱点,像创建浏览器、导入本地 Chrome 登录态、提交表单、删除数据等敏感操作,会先停下来让你确认,确保出现问题。
这点其实还蛮重要的:Agent 可以帮你操作网页,但要不要把动作真正执行下去,还是得人来拍板。
GitHub 地址 :github.com/browser-act...