护栏选型表面上是技术比选,实质上是一笔安全投资------花的每一分钱、引入的每一个组件,都要能在出了事时说清楚"为什么选它、它防住了什么、没防住的部分我有预案"。
上一篇完成了安全摸底,这篇进入第一个防护动作:选护栏、配防护。
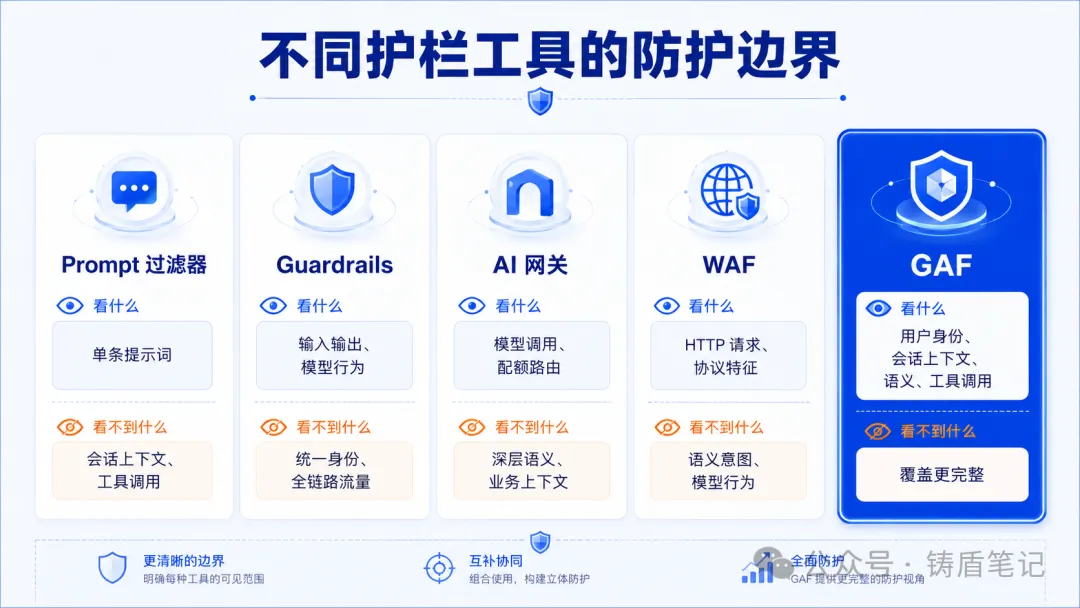
大模型护栏市场现在有一个很有意思的现象:工具越来越多,但安全团队反而越来越困惑。Prompt 过滤器、Guardrails、AI 网关、WAF 都在做安全,到底该用哪个?用了之后为什么大模型还是会被越狱?
这篇文章把这个问题讲清楚,并给出一个实操的选型框架。
一、搞清楚需求
很多团队把"护栏"当成一个笼统的概念,但实际上,当前市面上做安全的工具分属不同层面,解决的问题不一样。
| 工具类型 | 解决什么问题 | 看什么 | 看不到什么 |
|---|---|---|---|
| Prompt 过滤器 | 单条输入/输出是否有风险 | 一句话的内容 | 多轮对话的上下文、用户身份 |
| Guardrails | 约束模型"应该怎么回答" | 模型行为的合规性 | 用户身份、跨轮次行为、工具调用链 |
| AI 网关 | 管理模型调用的鉴权、限流、日志 | 谁在用什么模型、调了多少次 | 自然语言背后的真实意图 |
| WAF | 拦截 Web 层的恶意请求 | HTTP 协议层的异常 | 合法自然语言中的语义攻击 |
| GAF(生成式应用防火墙) | 统一安全执法层 | 用户身份 + 会话上下文 + 语义 + 工具调用 | --- |
问题出在哪?我们拥有大量分散的安全工具,却缺少一个能够从整体上理解生成式交互并统一执法的安全层。
WAF管不到语义层------Prompt 注入隐藏在完全合法的自然语言中,发生在"意义层"而不是"语法层"。Guardrails 不关心用户是谁,也很难理解一次回答在整段对话中的位置。AI 网关管理"怎么用模型",不管"模型在语义上做了什么"。
选型的第一步不是"买哪个产品",而是"你的系统需要覆盖哪些层"。
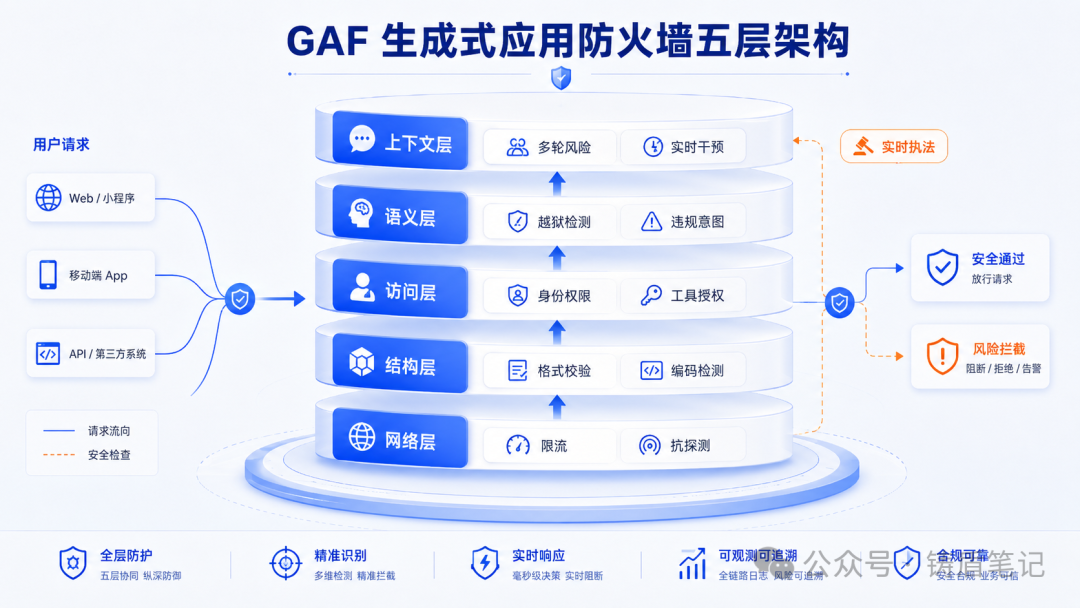
二、GAF 的五层架构
2026 年初的一篇论文提出了 GAF(Generative Application Firewall)的五层架构,提供了一种较完整的防护分层视角:
| 层级 | 名称 | 管什么 | 典型措施 |
|---|---|---|---|
| 第一层 | 网络层 | 使用行为是否合理 | 限流、抗 prompt flooding、抗自动化探测 |
| 第二层 | 结构层 | 请求结构是否安全可解析 | 编码混淆检测、格式校验、参数完整性 |
| 第三层 | 访问层 | 用户/Agent 有没有权限做这件事 | 身份验证、角色权限、工具调用授权 |
| 第四层 | 语义层 | 这一轮内容在语义上想干什么 | 越狱检测、违规意图识别、角色操纵拦截 |
| 第五层 | 上下文层 | 多轮交互是否正在走向失控 | 跨轮次累积风险、目标偏移检测、实时干预 |
2.1 网络层(Network Layer)
- 定位:最外围的基础流量管控层,作用于用户身份识别与会话建立之前
- 核心能力 :
- 实现请求/提示词速率限制、IP封禁、流量访问控制
- 缓解DDoS、Prompt泛洪、模型窃取、爬虫等 volumetric 攻击
- 过滤已知恶意IP流量,减少上游组件处理压力
2.2 访问层(Access Layer)
- 定位:身份与权限管控层,聚焦合法用户的权限边界控制
- 核心能力 :
- 实现用户认证、会话管理、角色权限分配
- 防御会话劫持、权限提升、敏感能力滥用等内部/授权用户风险
- 映射组织最小权限策略,对AI Agent的工具调用、RAG检索范围进行细粒度权限控制
2.3 句法层(Syntactic Layer)
- 定位:结构与格式校验层,防范下游系统的语法类攻击
- 核心能力 :
- 检查输入输出的结构合法性,识别转义序列、混淆令牌、代码注入
- 验证工具调用 schema、返回 payload 格式,执行类型/长度/编码约束
- 防御SQL注入、XSS、Prompt编码混淆、流协议异常等语法层面威胁
2.4 语义层(Semantic Layer)
- 定位:单轮交互内容检测层,识别独立请求的恶意意图
- 核心能力 :
- 基于自然语言语义理解,检测无需上下文即可判定的攻击
- 覆盖DAN、DEV模式、Best-of-N等单轮越狱、Prompt注入、敏感信息泄露风险
- 识别工具参数中的注入意图,实现内容级风险拦截
2.5 上下文层(Context Layer)
- 定位:多轮交互行为分析层,防御跨会话的复杂攻击
- 核心能力 :
- 维护会话历史与角色感知,检测Echo Chamber、Crescendo等渐进式多轮越狱攻击
- 进行行为分析与Bot检测,通过交互时序、频率特征区分真实用户与自动化探测
- 跟踪Agent规划逻辑与工具调用升级趋势,实现纵向策略执行(如重复越狱阈值、数据泄露上限)
五层架构遵循纵深防御原则,只有各层协同工作才能覆盖从传统网络攻击到复杂生成式AI攻击的全场景风险。其设计思路延伸了传统OSI网络模型,在应用层之上新增了语义理解维度,填补了传统WAF无法应对自然语言交互攻击的安全空白。
关键认知:安全不再只是事前过滤或事后兜底,而是可以在生成过程中实时执法------选择性打码、引导安全代答,甚至直接终止生成。
三、开源护栏工具对比
护栏的核心是一个分类模型,判断输入/输出是否存在风险。以下是当前主流的开源护栏模型:
| 模型 | 发布方 | 特点 | 适用场景 |
|---|---|---|---|
| Llama Guard v4 | Meta | 多模态(图文),最成熟的护栏基线 | 需要图文一体防护的团队 |
| Qwen3Guard | 阿里通义 | 0.6B/4B/8B 三档,Stream 版支持流式审核 | 对算力/延迟敏感的场景 |
| WildGuard | 学术 | 提示有害/回复有害/拒答检测三合一 | 需要细粒度分析的研究场景 |
| PolyGuard | 学术 | 17 语种,原语直判优于翻译再判 | 多语言业务 |
| ShieldGemma 2 | 文本+图像安全分类 | Google 生态 | |
| gpt-oss-safeguard | OpenAI | OpenAI 首个开源护栏模型 | 需要 OpenAI 兼容方案 |
| NemoGuard | NVIDIA | 生态落地好,可复用积木 | NVIDIA 生态用户 |
一个重要趋势:开源护栏模型正在走向免费。基础能力(分类模型 + 规则模板)开源就够了,但"实时 × 多模态 × 合规 × SLA"的工程化能力依然是付费层------就像 MySQL 免费,但企业为 Aurora 的高可用、备份、审计买单。
四、护栏效果的真实数据
选护栏不能只看产品文档,要看实测数据。
护栏确实能显著降低越狱攻击成功率。
CISPA 与南方科技大学联合完成的一项研究,第一次系统性地测量了"当模型被套上护栏之后,主流越狱攻击的真实危害程度"。
核心结论:与"裸模型"相比,所有护栏都能在不同程度上降低越狱攻击的攻击成功率(ASR)。 其中表现最好的护栏在多数攻击场景下都最为稳健。
这意味着:在真实部署环境中,越狱攻击的实际威胁强度,明显低于许多基于裸模型得出的结论。
来源:CISPA & 南方科技大学,arXiv:2512.24044
但固定模板攻击会大幅低估风险
AVISE 框架的实测数据揭示了一个重要发现:
| 模型 | 固定模板攻击失败率 | 自适应攻击失败率 | 差异倍数 |
|---|---|---|---|
| Llama 3.1 8B | 0.16 | 0.68 | 4.3× |
| Llama 3.2 3B | 0.08 | 0.68 | 8.5× |
| Ministral 3 14B | --- | 0.84 | 最高 |
结论:只测固定攻击模板的护栏评测不可信。必须用自适应攻击验证护栏面对未知攻击时的表现。
来源:AVISE 论文,arXiv:2604.20833
五、选型决策框架
不要上来就比产品。按这个顺序决策:
第一步:按风险场景列需求
| 你的业务场景 | 必须覆盖的风险 | 需要的护栏层级 |
|---|---|---|
| 客服机器人 | 违规输出、敏感信息泄露 | 语义层 + 上下文层 |
| 企业知识库问答 | 数据越权访问、间接注入 | 访问层 + 语义层 + 上下文层 |
| Agent 自动化 | 工具滥用、权限越级、级联失败 | 全五层 |
| 内容生成 | 内容合规、AIGC 标识 | 语义层 + 结构层 |
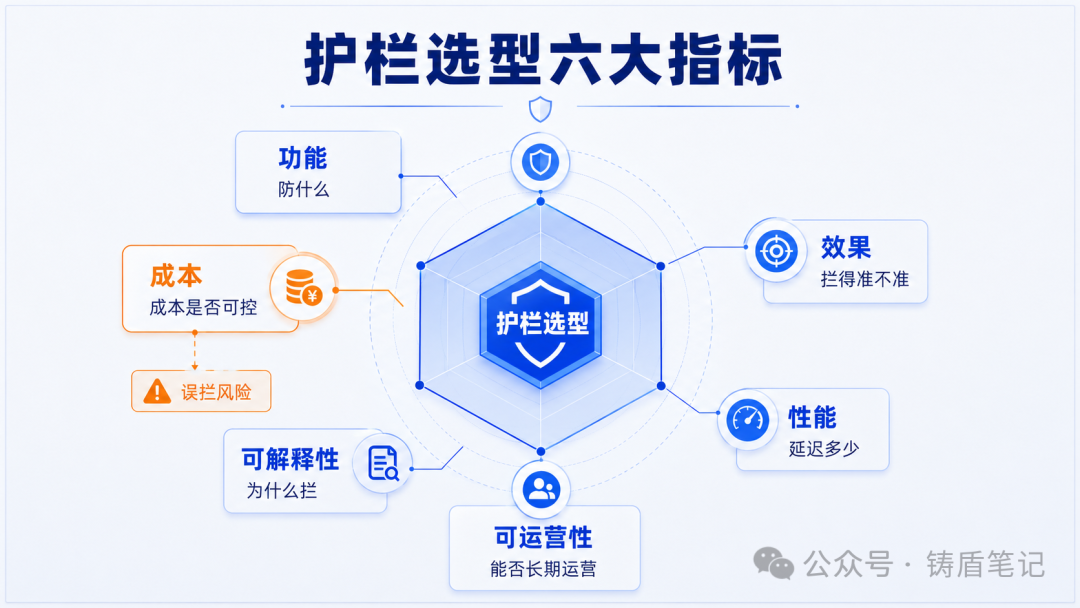
第二步:用六大类指标做系统评估
| 指标类别 | 核心问题 | 必看指标 |
|---|---|---|
| 功能 | 能不能防、防什么 | 覆盖的风险类型、多模态支持 |
| 效果 | 拦得准不准 | 召回率、F1、MCC(极度不均衡场景) |
| 性能 | 会不会拖慢系统 | P95 延迟、QPS、超时率 |
| 可运营性 | 能不能长期跑 | 策略配置灵活度、生效时延、灰度发布 |
| 可解释性 | 能不能说清为什么拦 | 命中原因追溯、风险标签粒度、审计日志 |
| 成本 | 值不值 | 单请求成本、扩容成本曲线、是否绑定单一模型 |
安全负责人决策点:护栏选型的核心判断不是"哪个最好",而是"哪个最适合当前阶段"。先用开源工具验证效果,再决定是否投入商业方案。
第三步:先 MVP,再迭代
-
先用一个开源护栏模型(如 Qwen3Guard 或 Llama Guard)做 MVP
-
用真实业务数据跑一次效果评测
-
记录误拦率和漏拦率,调整阈值
-
如果开源模型在 PoC 和低风险场景中效果够用,可以先用于试点;生产高并发、高合规、高审计场景仍需评估商业产品、云能力或自建工程体系。
六、输入防护实操
单纯靠一个分类模型做输入过滤是不够的。推荐三层组合方案:
第一层:规则过滤
-
关键词黑名单(国标要求 ≥ 10,000 个)
-
格式校验(长度、编码、特殊字符)
-
正则匹配(URL、邮箱、IP 地址等)
第二层:分类模型
-
用护栏模型判断语义风险
-
支持多模态(文本、图像、文件)
第三层:上下文分析
-
跨轮次累积风险评估
-
检测逐步升级的多轮攻击
七、输出防护实操
输出防护不是简单的"有风险就拦",而是需要一个分级处置策略:
| 风险等级 | 处置方式 | 示例 |
|---|---|---|
| 低风险 | 正常输出 | 普通问答 |
| 中风险 | 脱敏后输出 | 自动遮挡身份证号、手机号 |
| 高风险 | 安全改写/代答 | 用预设的安全回复替代原始输出 |
| 严重风险 | 拦截 + 告警 | 违法内容直接拒答,触发安全告警 |
Google 在 AI Protection 中把这套机制叫"Model Armor":合规内容正常返回,不合规内容经安全改写后返回。这个思路比"一刀切拒答"要好得多------既保住了安全底线,又减少了用户体验损失。
八、小结
护栏选型的核心不是"买哪个产品",而是"你的系统需要覆盖哪些安全层"。
-
用 GAF 五层架构理解防护全景
-
用六大类指标做系统评估
-
先 MVP(开源模型 + 规则过滤),再迭代
-
输入防护用三层组合 ,输出防护用分级处置
-
必须用自适应攻击验证效果,不能只测固定模板
参考文献: