最近系统学习了一组 AI Agent 工程化相关内容,里面很多问题都非常适合出现在面试中。
这些问题看起来分散,比如:
- LangChain、LangGraph、MCP 怎么选?
- 什么是 Agent Skill?
- Agent Skill 和 MCP 有什么区别?
- 如何保证 Function Calling 的可靠性?
- Agent 调错工具怎么办?
- 独立记忆系统对 Agent 是否必要?
- 如何设计 Agent 评估体系?
- 如何管理 Agent 上下文?
- 如何量化 Agent 性能?
- 如何保证大模型稳定输出 JSON?
- 多 Agent 并行到底是好事还是风险?
但本质上,它们都指向同一个问题:
AI Agent 不是简单的大模型问答,而是一个需要规划、记忆、工具、状态、安全、评估和工程闭环支撑的复杂软件系统。
下面按照面试和工程落地的角度,系统整理一遍。
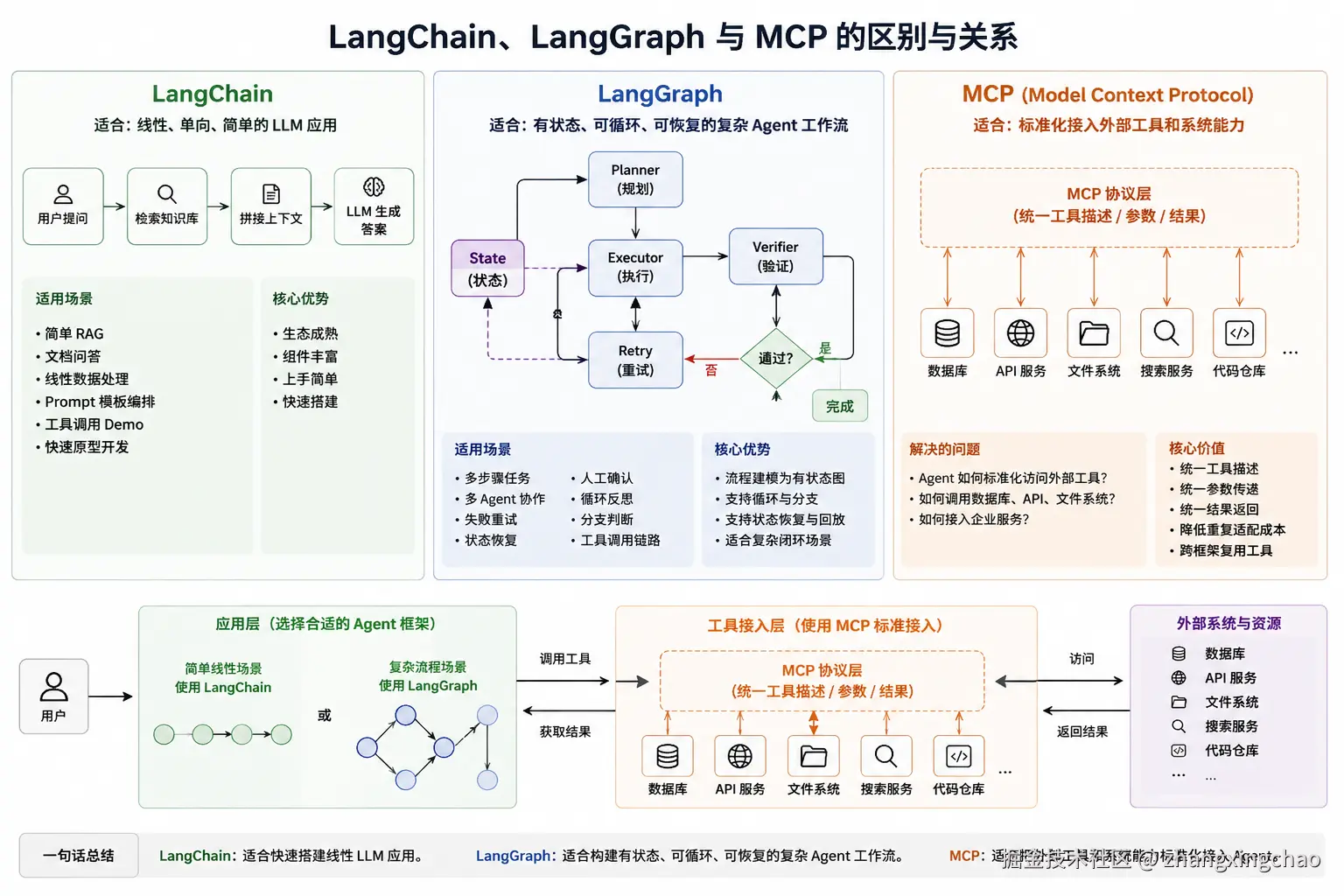
一、LangChain、LangGraph、MCP 到底怎么选?
1. 核心结论
如果业务场景是线性的、单向的数据处理,或者简单文档问答,可以优先选择 LangChain。
如果业务场景需要多轮决策、自我反思、失败重试、多角色协作,或者流程中存在明显的状态流转,可以选择 LangGraph。
如果要把企业内部数据库、API、文件系统、搜索服务、代码仓库等能力标准化暴露给上层 Agent,则可以使用 MCP。
一句话总结:
text
LangChain:适合快速搭建线性 LLM 应用。
LangGraph:适合构建有状态、可循环、可恢复的复杂 Agent 工作流。
MCP:适合把外部工具和系统能力标准化接入 Agent。2. LangChain 适合什么?
LangChain 更适合:
text
简单 RAG
文档问答
线性数据处理
Prompt 模板编排
工具调用 Demo
快速原型开发它的优势是生态成熟,封装了很多现成组件,例如:
text
文档加载
文本切分
向量检索
Prompt 模板
工具调用
输出解析
简单链式编排如果业务需求是:
text
用户提问
↓
检索知识库
↓
拼接上下文
↓
大模型生成答案这种场景用 LangChain 就比较合适。
3. LangGraph 适合什么?
LangGraph 更适合复杂 Agent 工作流。
比如:
text
多步骤任务
多 Agent 协作
失败重试
状态恢复
人工确认
循环反思
分支判断
工具调用链路LangGraph 的核心优势是把 Agent 流程建模成一个有状态图:
text
节点 Node:执行具体任务
边 Edge:决定流程跳转
状态 State:记录任务上下文
Checkpoint:支持恢复和回放所以它适合构建:
text
Planner → Executor → Verifier → Retry这种复杂闭环。
4. MCP 是什么?
MCP 不是 LangChain 或 LangGraph 的替代品。
它更像是一个工具接入协议。
MCP 解决的是:
text
Agent 如何标准化访问外部工具?
Agent 如何调用数据库?
Agent 如何访问文件系统?
Agent 如何接入企业 API?
Agent 如何连接代码仓库?可以理解为:
text
MCP = 连接器 / 管道 / 协议层它的价值在于:
text
统一工具描述
统一参数传递
统一结果返回
降低重复适配成本
让不同模型和 Agent 框架都能调用同一批工具5. 面试回答模板
如果面试官问:
LangChain、LangGraph、MCP 分别适合什么场景?
可以这样回答:
如果业务场景是比较线性的,比如简单文档问答、传统 RAG 或数据处理,我会优先选择 LangChain,因为它生态成熟,组件丰富,适合快速搭建和交付。
如果业务场景比较复杂,需要 Agent 具备多轮决策、自我反思、失败重试、多角色协作,或者需要维护长期状态,我会选择 LangGraph。它更像是把 Agent 工作流建模成一个有状态图,每个节点负责不同任务,边负责流程跳转,因此更适合构建复杂、可控、可恢复的 Agent 系统。
MCP 则不是 LangChain 或 LangGraph 的替代品。它更像是一套工具接入协议,用来把企业内部数据库、API、文件系统、业务系统等封装成标准化的 MCP Server。这样不管上层是 LangChain、LangGraph,还是其他 Agent 框架,都可以通过统一协议调用这些能力,减少重复开发和适配成本。
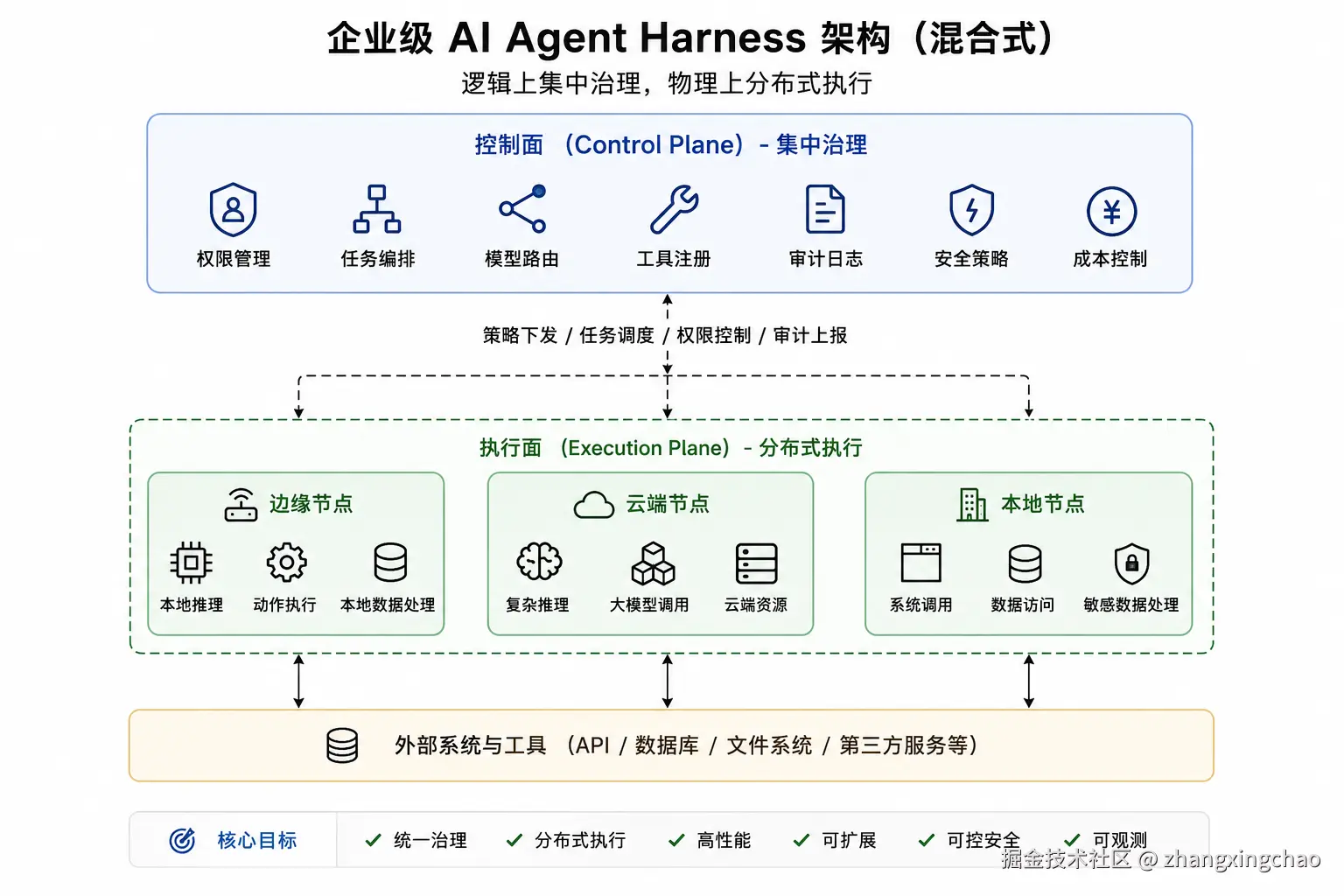
二、企业级 AI Agent Harness:集中式还是分布式?
1. 核心结论
如果为公司设计一套 AI Agent Harness,不应该简单选择纯集中式或纯分布式。
更合理的答案是:
逻辑上集中治理,物理上分布式执行。
也就是:
text
集中式控制面 Control Plane
+
分布式执行面 Execution Plane
=
Hybrid Mesh Architecture2. 为什么不选纯集中式?
纯集中式架构的优点是:
text
统一管理
统一鉴权
统一审计
统一监控
统一策略但问题是:
text
中心节点压力大
容易成为性能瓶颈
单点故障风险高
跨地域调用延迟高
边缘业务响应慢
业务系统接入成本高如果企业规模很小,Agent 数量少,业务流程简单,可以先用集中式。
但如果是大公司,有多个业务线、多个系统、多个模型、多个工具、多个地区,纯集中式很难长期支撑。
3. 为什么不选纯分布式?
纯分布式的优点是:
text
扩展性好
局部响应快
业务自治强
系统之间耦合低但最大问题是治理失控。
例如:
text
A 部门 Agent 能调用财务 API
B 部门 Agent 能调用用户数据
C 部门 Agent 能调用生产系统如果没有统一权限、审计、熔断、风控,就非常危险。
纯分布式的问题包括:
text
权限难统一
日志难追踪
策略难治理
安全边界不清楚
Agent 行为不可控
重复造轮子严重
不同团队实现标准不一致4. 混合式架构怎么设计?
推荐设计:
text
控制面集中化
执行面分布式控制面负责:
text
权限管理
任务编排
模型路由
工具注册
审计日志
成本控制
安全策略
风险拦截执行面负责:
text
云端复杂推理
边缘端动作执行
本地系统调用
低延迟业务处理
敏感数据本地处理这样既能保证企业级治理能力,又能兼顾性能、扩展性和业务自治。
5. 落地难点
企业级 Agent Harness 的难点主要有:
text
权限治理
状态管理
工具标准化
可观测性
安全合规
成本控制其中权限治理最关键,因为 Agent 会动态决策和动态调用工具。
权限不能只做 API Key,而要同时考虑:
text
用户权限
Agent 权限
工具权限
数据权限
场景权限
时间权限
操作权限6. 面试回答模板
如果让我设计企业级 AI Agent Harness,我不会选择纯集中式,也不会选择纯分布式,而会采用混合式架构。
具体来说,控制面集中化,执行面分布式。
控制面负责统一治理,包括权限管理、Agent 注册、工具注册、模型路由、任务编排、日志审计、成本控制和安全策略。这样可以保证企业内部 Agent 行为可控、可审计、可追踪。
执行面则采用分布式部署。云端 Agent 负责复杂推理、长文本分析和多步骤规划;边缘 Agent 部署在业务系统附近,负责低延迟动作执行、本地数据处理和敏感系统调用。
这种架构既能保证企业级治理能力,又能兼顾性能、扩展性和业务自治。

三、什么是 Agent Skill?
1. 核心定义
Agent Skill 不是一个简单工具,而是一个:
高内聚、可复用、可路由、可执行的智能体能力模块。
更简单地说:
text
Tool 是手脚;
Skill 是带说明书、经验和执行流程的能力包。2. Tool 和 Skill 的区别
| 对比项 | Tool | Agent Skill |
|---|---|---|
| 定位 | 底层工具 | 上层业务能力 |
| 粒度 | 小 | 中到大 |
| 内容 | API / 函数调用 | Prompt + SOP + 工具 + 资源 + 校验逻辑 |
| 是否有业务语义 | 弱 | 强 |
| 是否可复用 | 单点复用 | 业务模块级复用 |
| 例子 | 查询数据库 | 生成销售分析报告 |
| 例子 | 发送邮件 API | 撰写并检查商务邮件后发送 |
一句话:
Tool 解决"能不能调用某个能力",Skill 解决"如何稳定、规范、可复用地完成某类业务任务"。
3. Agent Skill 包含什么?
一个标准 Agent Skill 通常包括三部分:
text
Metadata
SOP / Instructions
Resources3.1 Metadata:元数据
告诉 Router Agent:
text
这个 Skill 是什么
适合解决什么问题
需要什么输入
会产生什么输出
适用边界是什么
不能处理什么场景
调用成本大概是多少
风险等级是什么例如合同审查 Skill:
text
名称:合同审查 Skill
输入:合同文本、审查重点、合同类型
输出:风险点、修改建议、风险等级
适用场景:采购合同、服务合同、合作协议
不适用场景:正式法律意见、诉讼策略
风险等级:中高
是否需要人工确认:是Metadata 的作用是让系统知道:
什么时候该调用这个 Skill,什么时候不该调用。
3.2 SOP / Instructions:业务指令
这部分是 Skill 的核心,相当于"执行说明书"。
包括:
text
任务拆解步骤
Prompt 模板
验证逻辑
业务规则
Few-shot 示例
错误处理策略
输出格式要求例如财务报表分析 Skill:
text
第一步:识别用户要分析的报表类型
第二步:提取收入、成本、利润、现金流等关键指标
第三步:与历史同期或预算值对比
第四步:识别异常波动
第五步:生成结构化分析结论
第六步:提示数据局限和风险3.3 Resources:资源与脚本
Resources 包括:
text
底层工具 API
数据库连接
RAG 知识库
模板文件
代码脚本
规则表
业务词典
校验器所以 Skill 不只是 Prompt,而是把 Prompt、工具、知识、模板、代码组合起来。
4. Agent Skill 的价值
Agent Skill 的核心价值包括:
text
即插即用
高复用性
执行更鲁棒
连接底层工具生态好的 Skill 不是只写一句 Prompt,而是内置:
text
执行步骤
校验逻辑
错误重试
Few-shot 示例
边界条件
异常处理
输出约束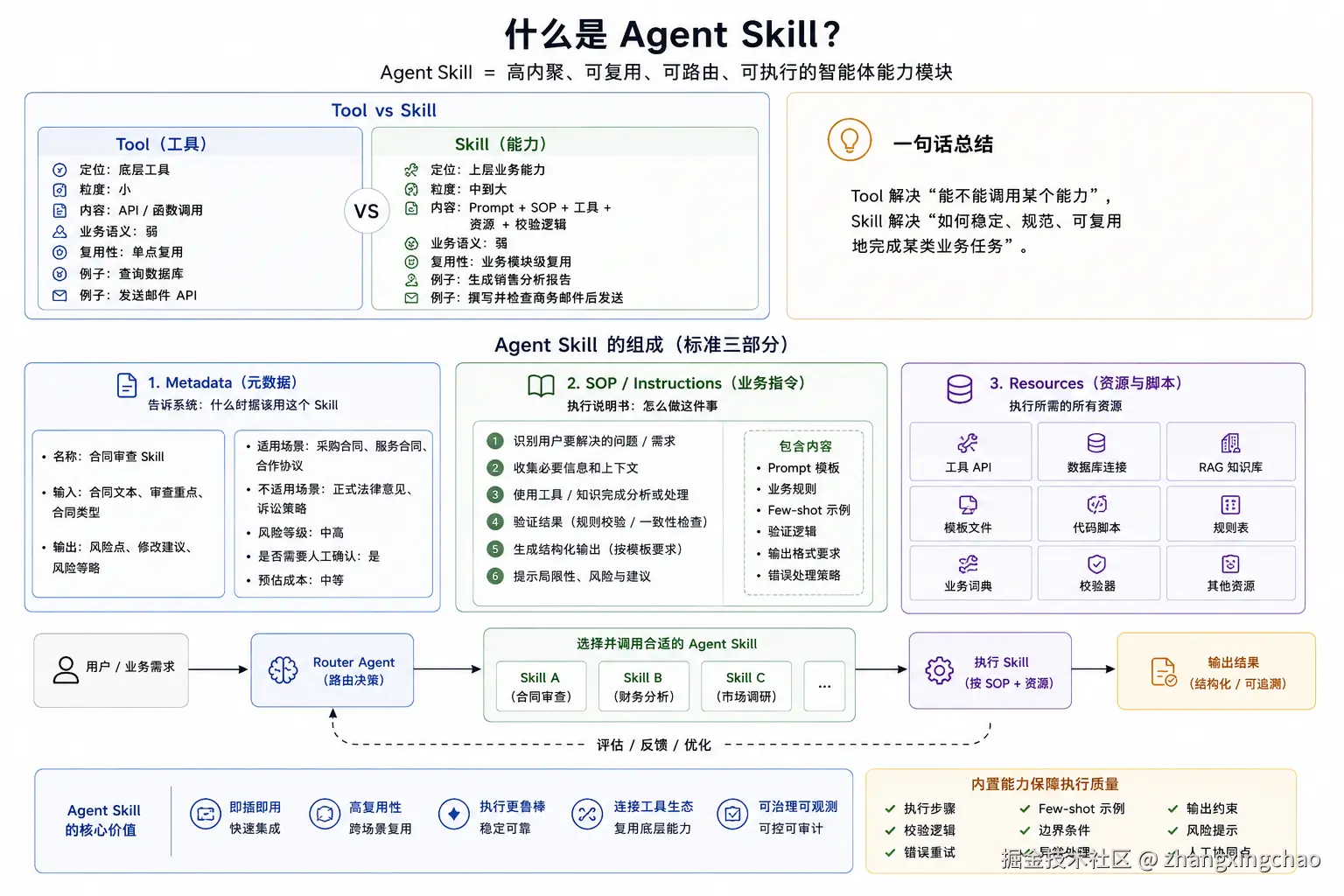
四、Agent Skill 和 MCP 的本质区别
1. 核心结论
一句话:
MCP 解决"怎么连上工具和数据"的问题;Agent Skill 解决"连上以后怎么正确完成业务任务"的问题。
2. MCP 是连接器
MCP 更偏底层协议层。
它解决的是:
text
Agent 能不能连接到外部系统?
Agent 能不能访问数据库?
Agent 能不能调用代码仓库?
Agent 能不能读取本地文件?
Agent 能不能调用搜索服务?MCP 更像:
text
插头
管道
适配器
连接协议3. Agent Skill 是业务 SOP
Agent Skill 更偏业务逻辑层。
它解决的是:
text
Agent 应该什么时候调用什么工具?
调用前要做什么判断?
调用后要怎么校验?
多步骤任务怎么编排?
出错后怎么恢复?
结果要怎么组织?Agent Skill 更像:
text
菜谱
说明书
业务 SOP
能力模块
执行手册4. Java 类比
可以这样类比:
text
MCP ≈ JDBC / HTTP Client / RPC 框架 / 数据源连接层
Agent Skill ≈ Service 层业务方法 / 业务流程编排 / SOP 模块例如 Java 里:
java
UserRepository.findById(userId)
PaymentClient.refund(orderId)
EmailClient.send(email)这些更像 MCP 暴露的底层工具。
而:
java
refundOrder(orderId)这个业务方法里面可能会:
text
查订单
判断是否满足退款条件
查支付记录
调用退款接口
更新订单状态
发送通知
写审计日志这就更像 Agent Skill。
5. 协作链路
完整链路可以理解为:
text
用户问题
↓
LLM Core / Router Agent
↓
识别意图、规划任务
↓
检索合适的 Agent Skill
↓
加载 Skill.md 和 Scripts
↓
Skill 按照 SOP 决定调用哪些工具
↓
通过 MCP 调用数据库、搜索、文件系统、代码仓库等外部能力
↓
返回结果
↓
Skill 校验、整理、生成最终答案一句话:
text
Agent Skill 在上层负责"怎么做";
MCP 在下层负责"怎么连"。五、Agent Skill 做知识库检索是否比传统 RAG 更好?
1. 核心结论
Agent Skills 不是替代传统 RAG,而是增强 RAG。
传统 RAG 是:
text
用户提问
↓
向量数据库语义相似度检索
↓
取 Top-K 文档片段
↓
拼接 Prompt
↓
大模型生成答案Agentic RAG 是:
text
用户复杂问题
↓
Router Agent 判断意图
↓
选择合适 Skill
↓
Skill 拆解任务
↓
按需调用检索工具、数据库工具、计算工具
↓
对结果做校验和重排
↓
必要时二次检索或反思修正
↓
生成最终答案2. 传统 RAG 的优点
传统 RAG 适合:
text
简单事实问答
FAQ
制度查询
产品说明检索
文档问答优点是:
text
链路短
成本低
延迟低
实现简单3. 传统 RAG 的局限
传统 RAG 的问题是:
text
一次检索不一定召回准
复杂问题不会主动拆解
不会判断是否需要二次检索
不会主动调用其他工具
容易被噪声文档干扰
上下文太长会 Lost in the Middle
检索不到时容易硬答4. Agent Skills 的优势
Agent Skills 可以让 RAG 从:
text
静态查询变成:
text
动态规划从:
text
一次性检索变成:
text
多步推理 + 工具调用 + 结果校验它会思考:
text
这个问题要不要拆解?
要查哪些知识库?
要不要调用数据库?
一次检索够不够?
结果是否互相矛盾?
有没有缺少关键证据?
要不要重新检索?
最终答案是否符合格式?5. 是否一定更好?
不是。
简单问题用传统 RAG 更高效。
复杂问题用 Agentic RAG 更有优势。
落地策略应该是:
text
简单问题 → Naive RAG
复杂问题 → Agentic RAG / Skill-based RAG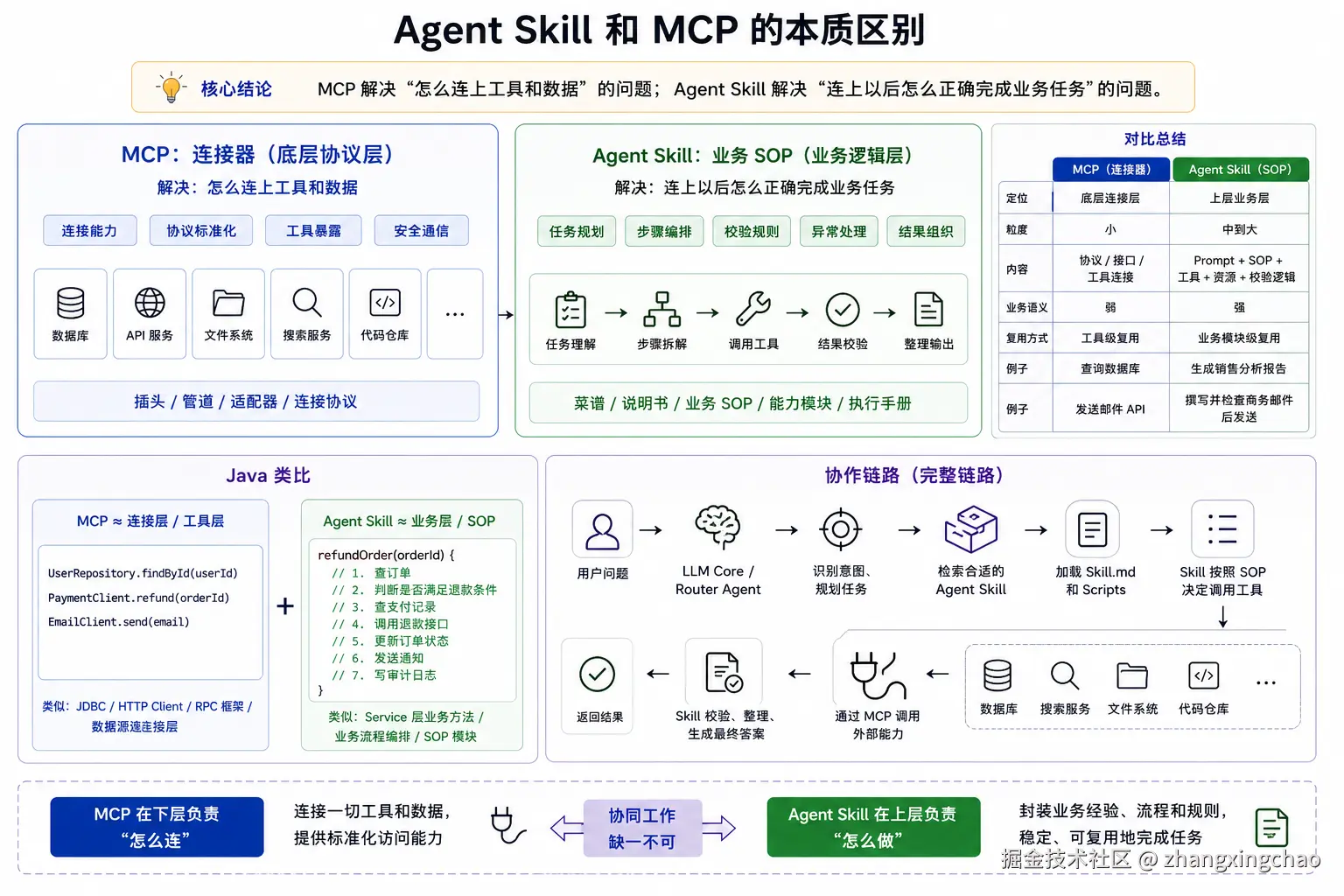
六、如何保证 Agent 工具调用的可靠性?
1. 核心结论
Agent 工具调用可靠性,不能依赖模型自己"想清楚"。
需要四层体系:
text
L1:结构化定义层 Schema Rigidity
L2:推理策略层 Reasoning Strategy
L3:执行护栏层 Execution Guardrails
L4:自愈修复层 Self-Healing Loop2. L1:结构化定义层
工具必须用 JSON Schema、Pydantic、Zod 等方式定义清楚:
text
字段名是什么
字段类型是什么
是否必填
取值范围是什么
枚举值有哪些
默认值是什么
哪些字段不能同时出现工具描述也要写清楚:
text
什么时候用
什么时候不用
输入要求
输出含义
边界条件
失败情况3. L2:推理策略层
Agent 调用工具前要先做任务拆解,而不是直接拍脑袋调用。
可以加入:
text
CoT / 计划式推理
Few-shot 示例
工具检索 RAG如果工具很多,不应该把所有工具都塞给模型,而应该:
text
先根据用户意图检索相关工具
只把 Top-K 工具 Schema 注入上下文
再让模型选择调用4. L3:执行护栏层
模型生成工具参数后,不能马上执行。
要做:
text
格式校验
业务规则校验
权限校验
风险校验高风险动作必须人工确认,例如:
text
转账
退款
删除数据
修改合同
发送外部邮件
批量更新数据库
提交审批5. L4:自愈修复层
工具调用失败后,要把结构化错误返回给模型:
json
{
"error_code": "INVALID_DATE_FORMAT",
"message": "date must be YYYY-MM-DD",
"field": "start_date",
"retryable": true
}然后让 Agent 根据错误修正参数并重试。
但必须设置:
text
最大重试次数
最大工具调用次数
最大执行时长
失败降级策略
人工接管条件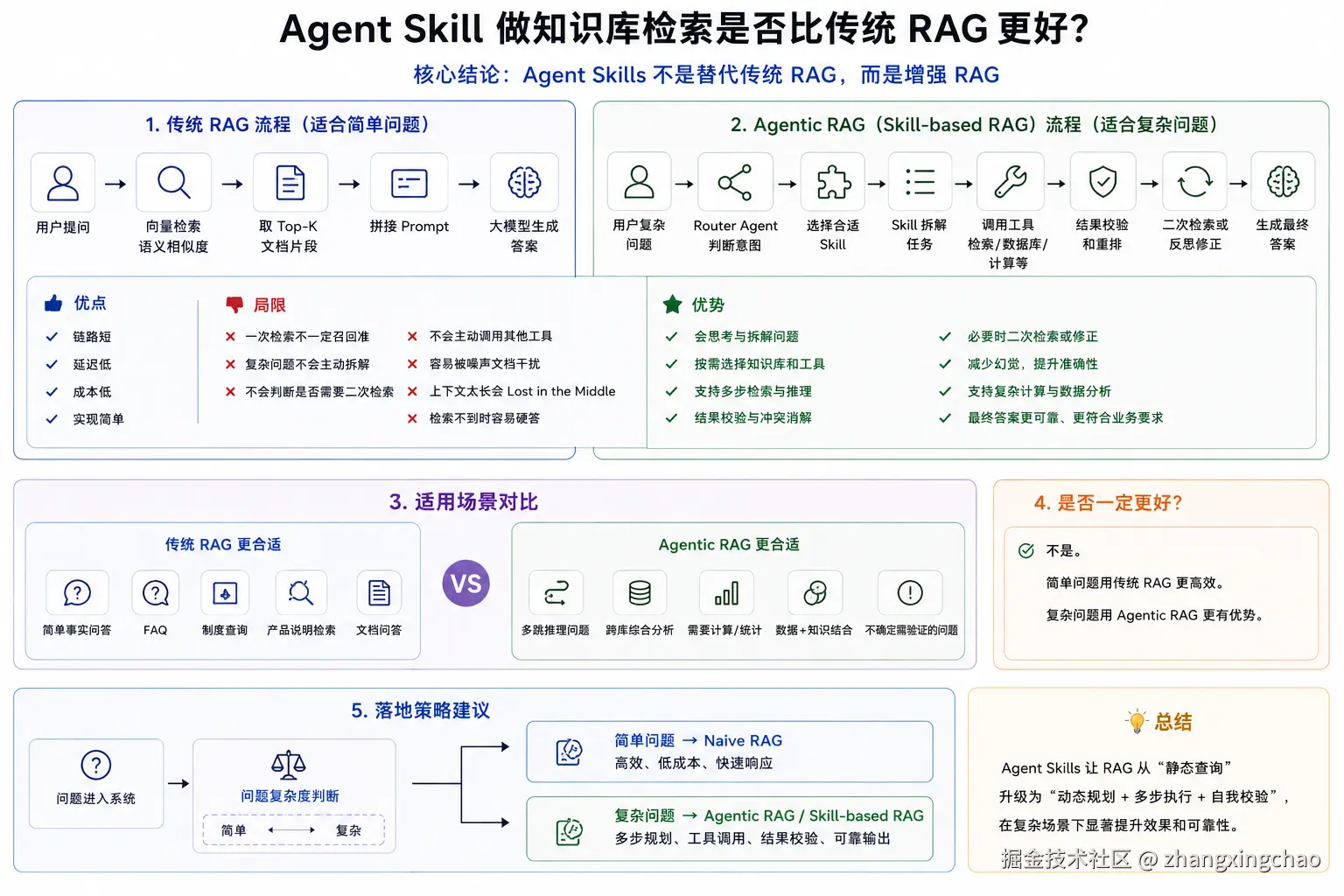
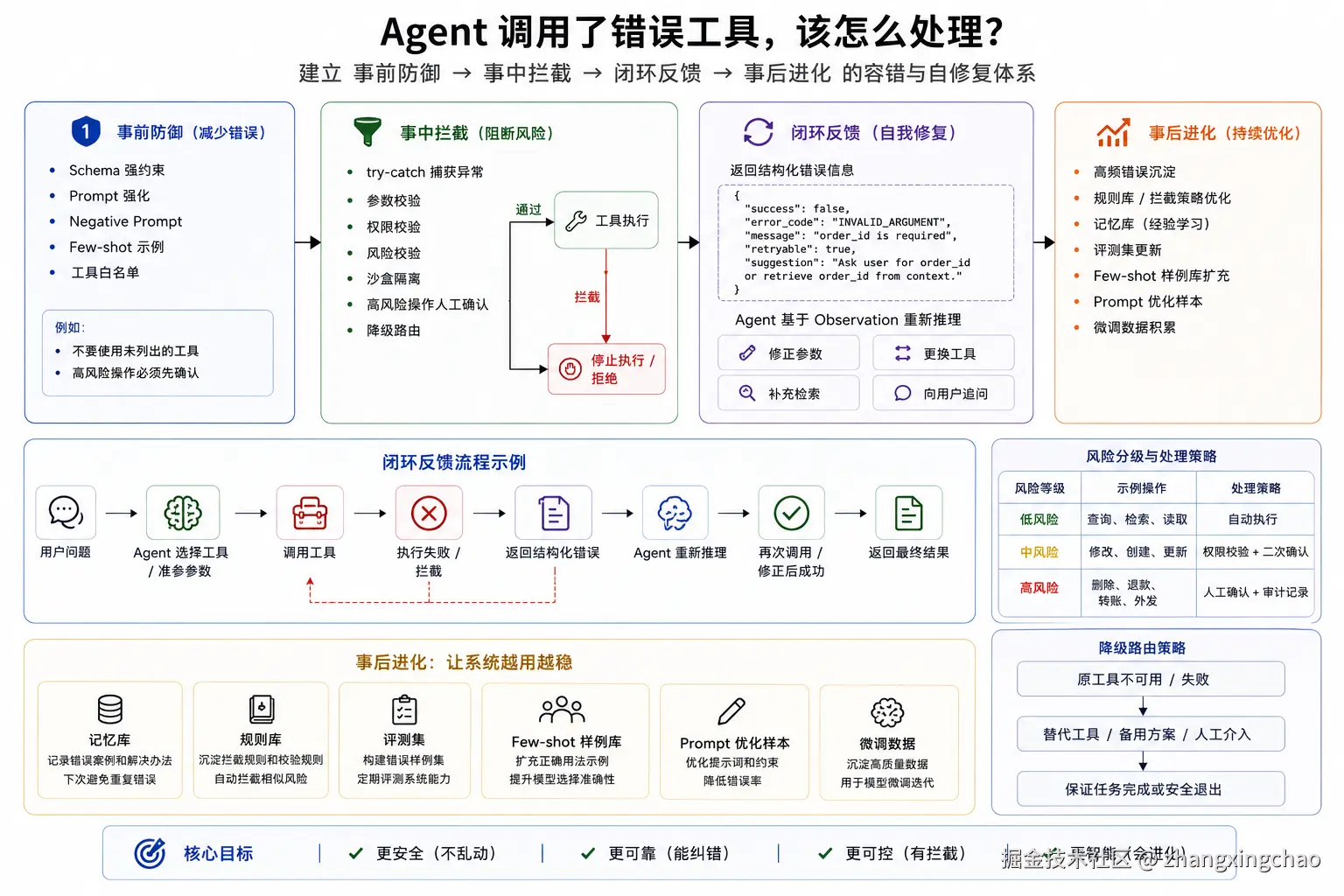
七、如果 Agent 调用了错误工具,该怎么处理?
1. 核心结论
不能只做 try-catch。
应该建立一套:
text
事前防御
事中拦截
闭环反馈
事后进化的容错与自修复体系。
2. 事前防御
包括:
text
Schema 强约束
Prompt 强化
Negative Prompt
Few-shot 示例
工具白名单例如 Prompt 中明确:
text
不要使用未列出的工具。
如果用户意图不明确,先澄清,不要直接调用工具。
如果涉及删除、退款、转账、发邮件等高风险动作,必须先请求确认。
如果没有足够参数,不要猜测参数。3. 事中拦截
工具执行层要做:
text
try-catch
参数校验
权限校验
风险校验
沙盒隔离
高风险操作人工确认
降级路由查询类工具可以自动执行。
写操作、资金操作、删除操作、外发操作必须进入权限校验和人工确认流程。
4. 闭环反馈
工具调用失败后,不要只返回"失败",而要返回结构化错误:
json
{
"success": false,
"error_code": "INVALID_ARGUMENT",
"message": "order_id is required",
"retryable": true,
"suggestion": "Ask user for order_id or retrieve order_id from context."
}Agent 基于 Observation 重新推理:
text
修正参数
更换工具
补充检索
向用户追问5. 事后进化
高频错误要沉淀到:
text
记忆库
规则库
评测集
Few-shot 样例库
Prompt 优化样本
微调数据这样系统会越用越稳。
八、独立记忆系统对 Agent 是否必要?
1. 核心结论
独立记忆系统对复杂 Agent 非常必要。
它不是为了简单保存聊天记录,而是为了让 Agent 具备:
text
长期状态管理
个性化偏好
任务连续性
经验沉淀
跨会话恢复2. 为什么不能只靠上下文窗口?
因为上下文窗口有物理限制。
即使模型支持长上下文,也会带来:
text
Token 成本高
响应延迟高
关键信息被淹没
模型注意力分散
Lost in the Middle
旧信息干扰新判断所以长期记忆不能只靠 Prompt。
3. Agent 应该记什么?
可以分成四类:
text
用户记忆
任务记忆
业务记忆
反思记忆用户记忆
例如:
text
用户偏好的输出格式
常用技术栈
常见业务场景
写作风格偏好
长期项目背景任务记忆
例如:
text
当前任务目标
已经完成哪些步骤
下一步计划
中间产物
失败原因
待确认事项业务记忆
例如:
text
客户画像
订单历史
项目背景
合同条款
知识库条目
产品规则
组织结构反思记忆
例如:
text
哪些调用路径成功率高
哪些错误经常出现
用户更认可哪种答案
哪些工具容易失败
哪些规则需要优先检查4. 底层存储怎么设计?
可以采用异构存储:
text
向量库:做语义检索
图数据库:存实体关系和复杂关联
SQL 数据库:存结构化用户画像、任务状态、业务记录
KV / 文档库:存会话摘要、状态快照、Checkpoint5. Memory 和 RAG 的区别
text
RAG 更偏知识检索;
Memory 更偏状态管理和经验沉淀。RAG 查的是:
text
文档知识
制度规则
产品说明
资料片段Memory 记的是:
text
用户偏好
任务进度
历史决策
交互习惯
长期上下文
反思经验
九、如何从 0 到 1 设计 Agent 自动化评估体系?
1. 核心结论
Agent 是概率系统,不能只靠单元测试或人工体验。
需要构建一套:
text
可测
可控
可追踪
可回归
可持续优化的自动化评估体系。
2. 四层架构
完整评估体系可以分为:
text
输入层
执行层
产出层
阅卷层输入层:Task + Suite
准备标准测试集:
text
正常样例
边界样例
异常样例
攻击样例
历史故障样例
高频业务样例每个 Case 包含:
text
用户输入
期望行为
允许工具
禁止工具
评分标准
风险等级
标准答案或参考答案执行层:Trial + Transcript
同一个任务不要只跑一次,要多次运行。
记录:
text
每次模型输出
每次工具调用
每次参数
每次中间状态
每次错误
每次耗时
每次 token 成本并保存完整 Transcript:
text
用户输入
Agent 规划
工具调用
工具返回
中间推理摘要
最终输出
异常信息产出层:Outcome
保存最终业务结果,包括:
text
最终答案
结构化输出
工具执行结果
业务动作结果
是否成功
失败原因
耗时
成本阅卷层:Scorer
Scorer 可以分三层:
text
L1 规则层
L2 语义层
L3 智能层L1 规则层判断:
text
JSON 是否合法
字段是否完整
代码能否运行
是否调用禁止工具
是否触发人工确认
金额是否超过限制L2 语义层判断:
text
Embedding 相似度
关键词覆盖率
事实点命中率
Rerank 判断L3 智能层使用:
text
LLM-as-a-Judge
专家评审
人工抽检3. 三个核心难点
随机性
解决方案:
text
多次 Trial
Pass@k
成功率
置信区间
固定 temperature
固定模型版本结果判定模糊
解决方案:
text
分层 Scorer
规则评分
语义评分
智能评分
人工抽检复杂归因链路
解决方案:
text
结构化 Transcript
Trace 可视化
工具调用日志
Prompt 日志
状态快照
错误码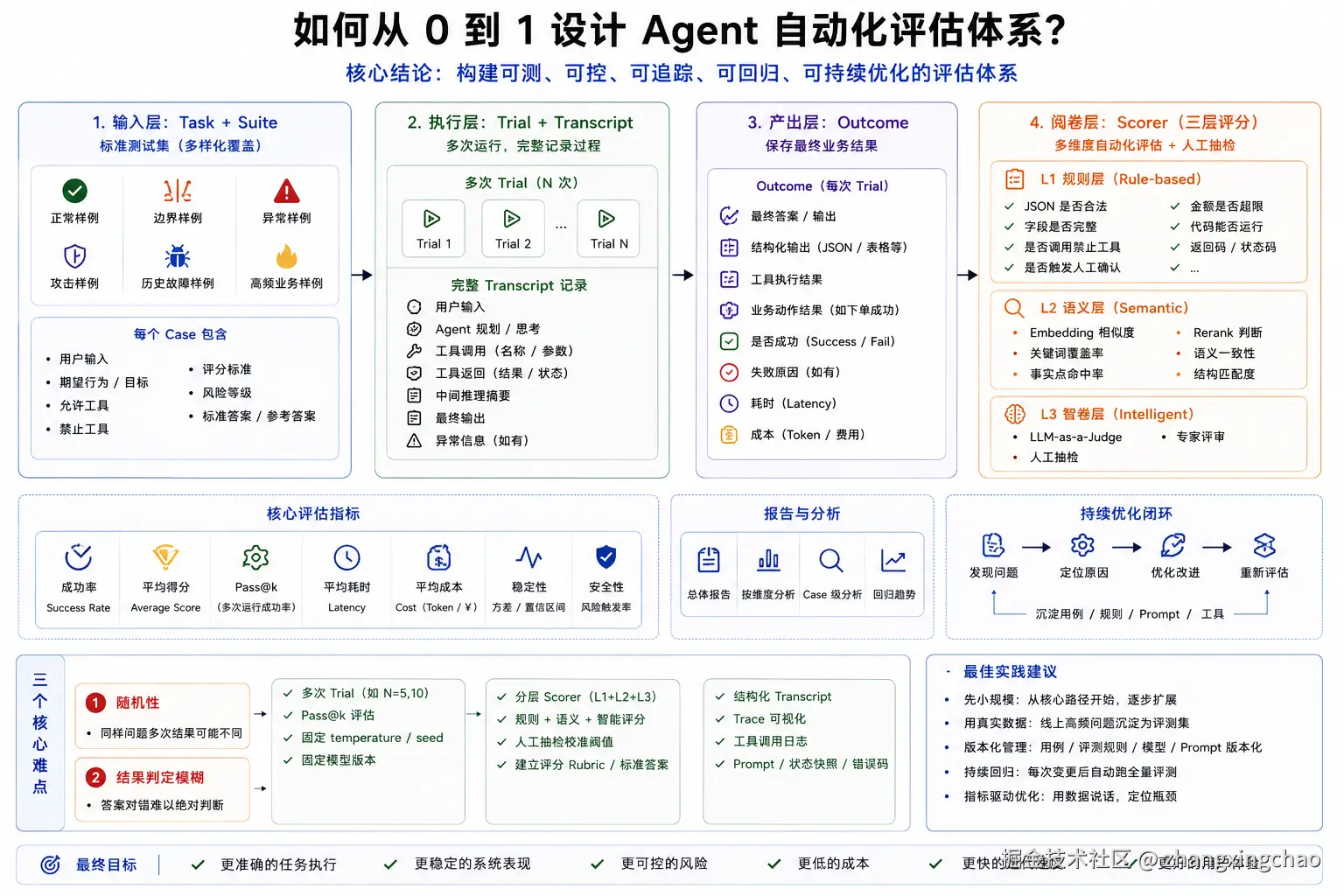
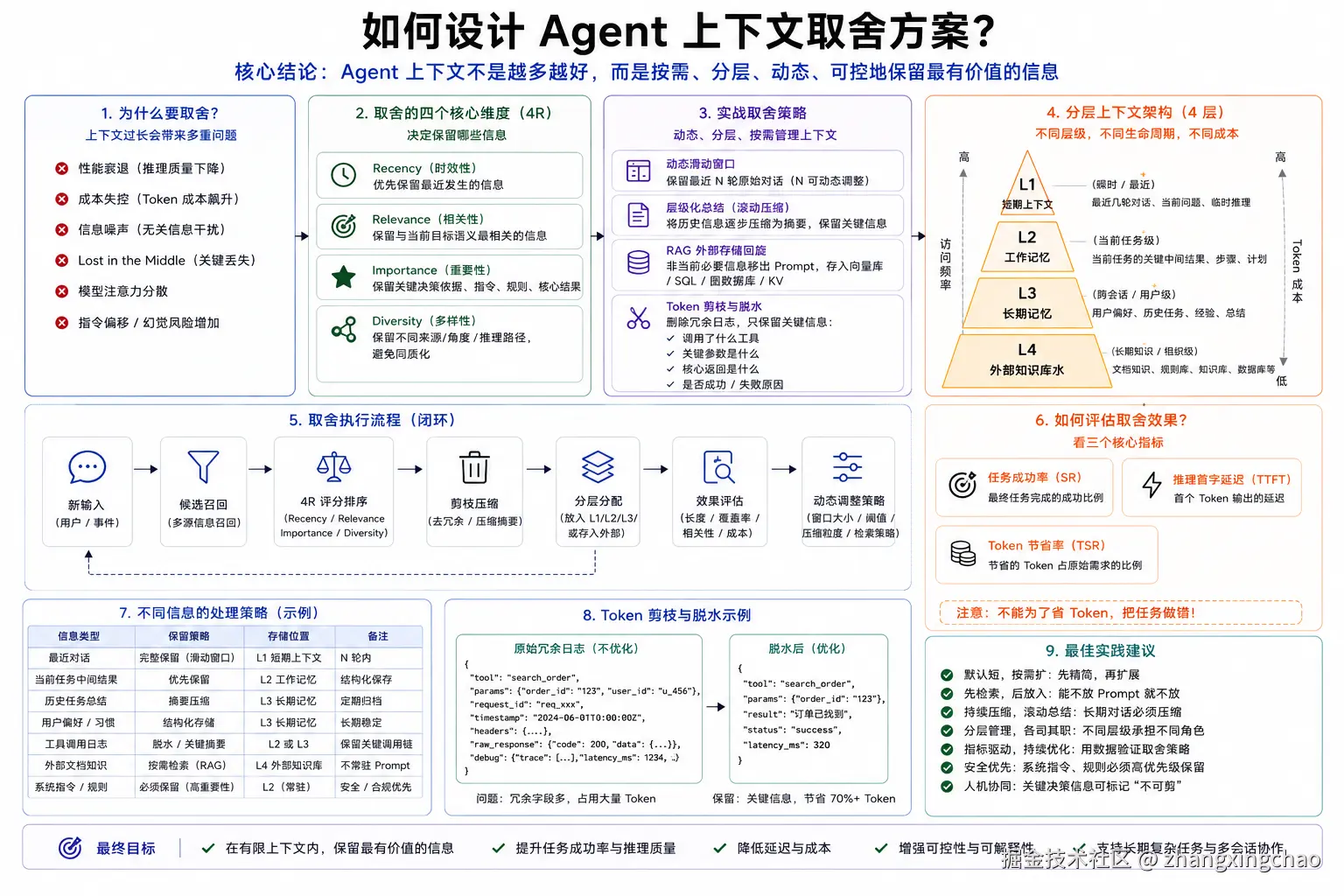
十、如何设计 Agent 上下文取舍方案?
1. 核心结论
Agent 上下文不是越多越好。
上下文是一种有限资源,需要:
text
分层管理
动态压缩
按需检索
持续评估2. 为什么要取舍?
上下文过长会带来:
text
性能衰退
成本失控
信息噪声
Lost in the Middle
模型注意力分散
指令偏移3. 取舍的四个维度
text
Recency:时效性
Relevance:相关性
Importance:重要性
Diversity:多样性时效性
优先保留最近发生的信息。
相关性
保留和当前目标语义最接近的信息。
重要性
保留关键决策依据、系统指令、安全规则、工具核心结果。
多样性
保留不同推理路径的信息,避免上下文只剩同质内容。
4. 实战策略
动态滑动窗口
保留最近 N 轮原始对话。
层级化总结
把历史信息滚动压缩成摘要。
RAG 外部存储回旋
非当前必要的信息移出 Prompt,存入向量库、SQL、图数据库或 KV。
Token 剪枝与脱水
删除 Tool Call 的冗余日志,只保留:
text
调用了什么工具
关键参数是什么
核心返回是什么
是否成功
失败原因是什么5. 分层上下文架构
可以分四层:
text
L1:短期上下文
L2:工作记忆
L3:长期记忆
L4:外部知识库6. 如何评估取舍效果?
看三个指标:
text
任务成功率 SR
推理首字延迟
Token 节省率注意:
不能为了省 Token,把任务做错。
十一、如何量化一个 Agent 的性能?
1. 核心结论
Agent 的性能不是一个准确率,而是:
text
结果质量
过程质量
工具调用质量
系统效率
业务安全的综合评估。
2. 三层指标体系
text
结果维度 Task-Level
过程维度 Trajectory
系统维度 System-Level结果维度
关注 Agent 是否完成任务。
指标包括:
text
任务成功率 Task Success Rate
环境终态匹配度 State Matching
答案准确率
业务目标完成率过程维度
关注 Agent 完成任务的路径是否合理。
指标包括:
text
工具调用准确率 API Precision
参数构造准确率
规划效率
自我纠错率
错误恢复率
非法工具调用率
重复动作率系统维度
关注成本和性能。
指标包括:
text
端到端延迟
P95 / P99 响应时间
Token 消耗量
API 调用成本
平均交互轮数
工具调用次数
任务平均成本
并发吞吐量
失败重试次数3. 主流评估方法
text
基于规则与代码断言
基于环境状态机
LLM-as-a-Judge
人工抽检规则与代码断言适合:
text
JSON 格式
字段完整性
权限规则
代码运行
SQL 执行
禁止工具调用环境状态机适合:
text
数据库状态是否符合预期
文件是否正确生成
网页表单是否成功提交
订单状态是否正确更新LLM-as-a-Judge 适合:
text
开放式回答质量
推理合理性
业务完整性
幻觉风险
语气是否合适
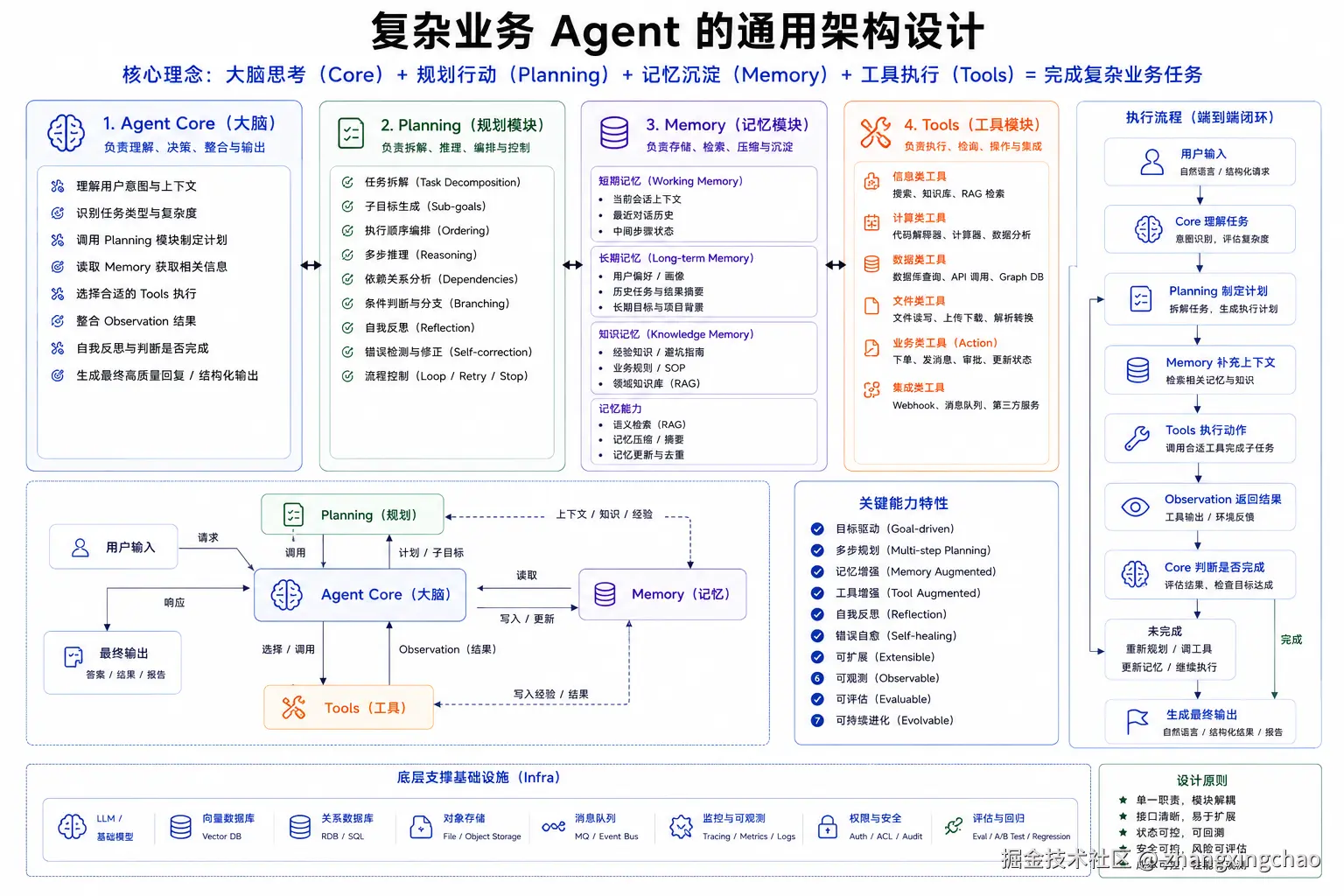
十二、如何让大模型稳定输出 JSON?
1. 核心结论
不能只靠 Prompt。
应该使用:
text
提示词约束
API 原生约束
解码约束
工程校验与自修复四层防线。
2. 第一层:Prompt 控制
在 Prompt 中明确:
text
JSON Schema
字段含义
字段类型
Few-shot 示例
输出规则同时把格式要求放在 Prompt 末尾,利用末尾锚定效应。
3. 第二层:API 原生约束
优先使用:
text
JSON Mode
Structured OutputsJSON Mode 保证基本 JSON 语法。
Structured Outputs 进一步保证:
text
字段名正确
字段类型正确
必填字段存在
枚举值合法
数组 / 对象层级匹配4. 第三层:解码约束
高稳定场景可以使用:
text
CFG
Constrained Decoding
Logit Masking在 token 生成阶段限制非法格式。
5. 第四层:工程校验与自修复
使用:
text
Pydantic
Zod
JSON Schema Validator
Ajv校验:
text
JSON 是否合法
字段是否完整
类型是否正确
枚举是否合法
数值是否越界
业务规则是否满足失败后,把错误信息回传给模型定向修复。
十三、复杂业务 Agent 的通用架构怎么设计?
1. 核心结论
一个复杂业务 Agent 应该由四个核心模块组成:
text
Core
Planning
Memory
Tools2. Agent Core:大脑
Core 负责:
text
理解用户意图
识别任务类型
调用规划模块
读取相关记忆
选择合适工具
整合工具结果
最终推理输出3. Planning:规划模块
Planning 负责:
text
任务拆解
子目标规划
执行顺序编排
多步推理
自我反思
错误修正
流程控制4. Memory:记忆模块
Memory 负责:
text
短期上下文
长期用户偏好
历史任务摘要
经验知识
RAG 检索
记忆压缩5. Tools:工具模块
Tools 负责:
text
联网搜索
代码解释器
API 调用
数据库查询
文件系统操作
业务 Action6. 四者关系
一句话:
text
Core 负责"如何思考";
Planning 负责"怎么做";
Memory 负责"以前说过啥、现在做到哪";
Tools 负责"模型自己做不到的事"。执行流程:
text
用户输入
↓
Core 理解任务
↓
Planning 制定计划
↓
Memory 补充上下文
↓
Tools 执行动作
↓
Observation 返回结果
↓
Core 判断是否完成
↓
未完成则重新规划 / 调工具 / 更新记忆
↓
完成后输出结果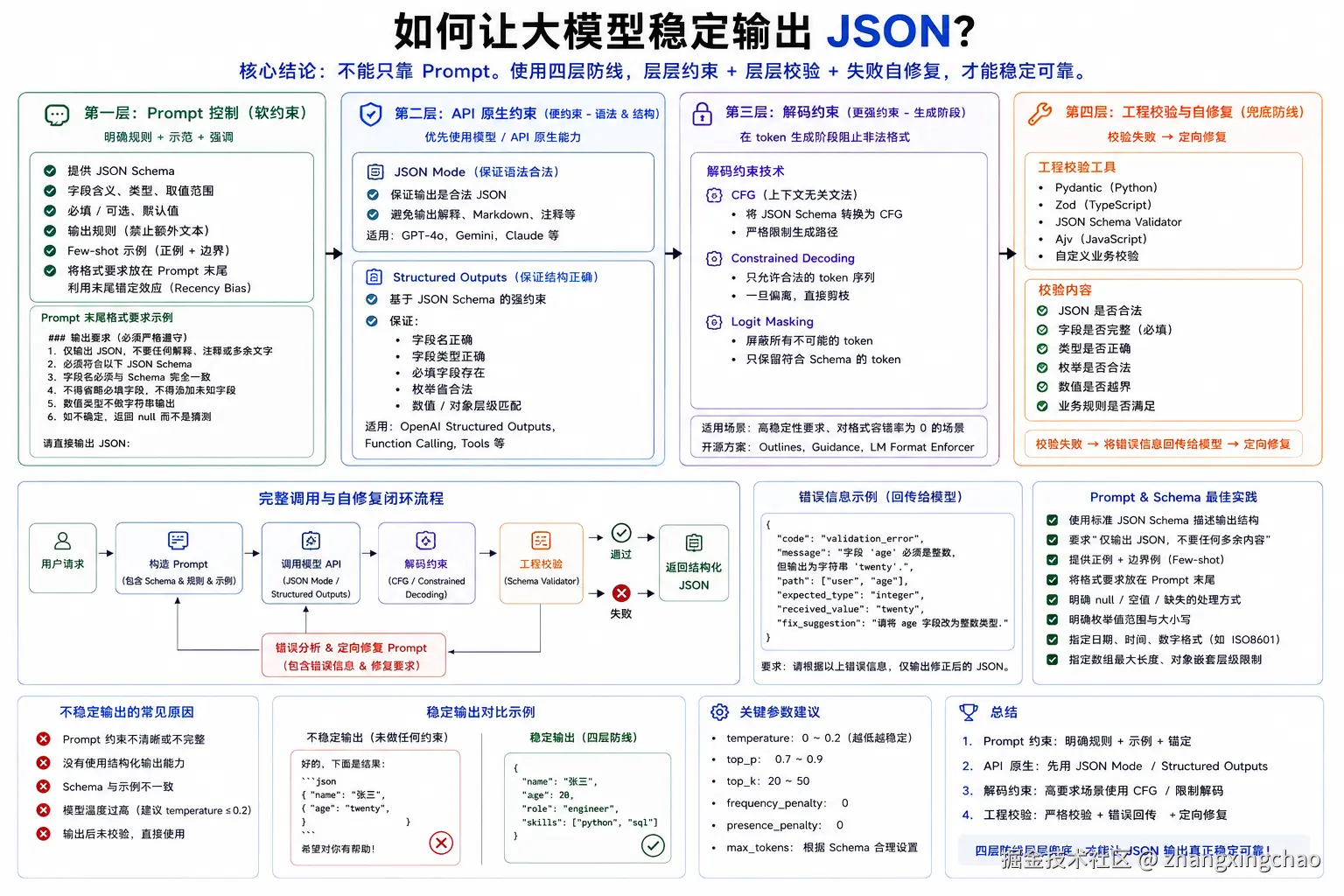
十四、并行效率和逻辑可信,应该追求哪个?
1. 核心结论
不能盲目追求极致并行。
生产级 Agent 架构应该遵循:
text
读操作可以并行,写操作必须串行。
信息收集可以并行,最终决策必须统一。
工具可以很多,但决策中心只能有一个。2. 为什么不能盲目多 Agent 并行?
多个 Agent 并行做事,如果没有统一上下文和统一决策中心,很容易出现:
text
隐性假设冲突
风格割裂
逻辑不兼容
上下文不一致
集成失败
返工成本更高例如多个 Agent 同时改代码:
text
Agent A 修改接口参数
Agent B 按旧接口写调用方
Agent C 修改数据库字段
Agent D 修改测试用例最后可能导致:
text
接口定义不一致
类型不匹配
测试全挂
业务语义断裂
代码冲突
难以归因3. 什么适合并行?
弱耦合任务适合并行:
text
独立翻译
信息搜集
竞品调研
日志聚类
候选方案生成
测试用例草拟
多文档摘要
代码库静态扫描这些任务特点是:
text
读多写少
结果可合并
失败可丢弃
彼此依赖低
不直接改变核心系统状态4. 什么必须串行?
强耦合任务必须串行:
text
核心代码生成
系统重构
数据库迁移
线上配置变更
支付 / 退款 / 转账
复杂业务流程执行
长篇推理和方案设计
多步骤 Agent 决策链这类任务特点是:
text
前一步决定后一步
上下文必须连续
状态变更不可随意并发
错误会级联放大
最终结果需要语义一致5. 推荐架构:One Brain, One Stream
即:
text
一个核心决策脑
一条主执行链
多个工具按需调用
状态写入统一管理流程是:
text
并行阶段:多个 Agent / 工具收集信息
↓
汇总阶段:统一压缩和去重
↓
决策阶段:一个 Core 做最终判断
↓
执行阶段:按计划串行写操作
↓
验证阶段:自动测试和人工确认
十五、最终总结
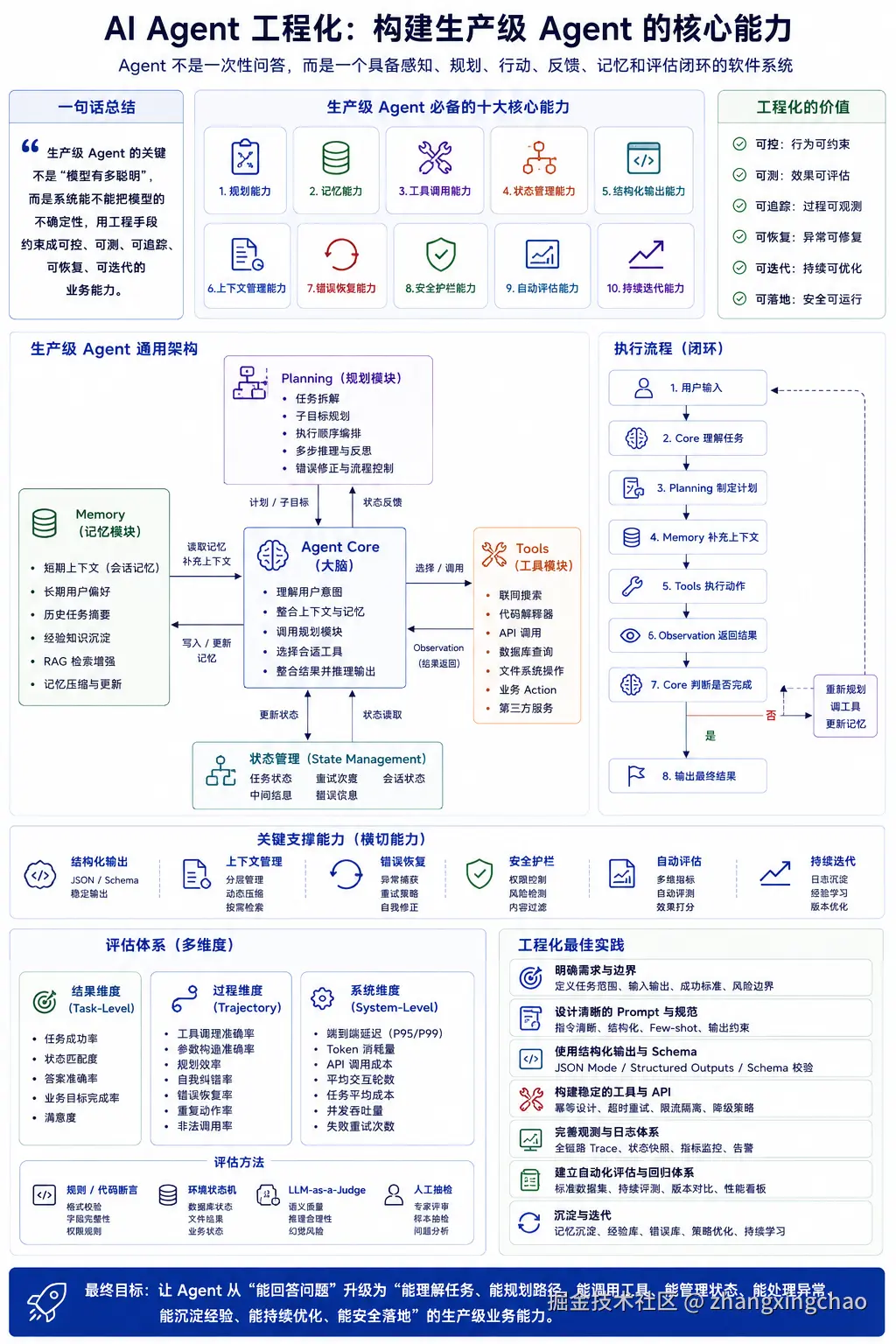
AI Agent 工程化的核心,不是简单接入一个大模型,也不是让模型自由调用几个工具。
真正的生产级 Agent,需要同时具备:
text
规划能力
记忆能力
工具调用能力
状态管理能力
结构化输出能力
上下文管理能力
错误恢复能力
安全护栏能力
自动评估能力
持续迭代能力可以用一句话总结:
Agent 不是一次性问答,而是一个具备感知、规划、行动、反馈、记忆和评估闭环的软件系统。
再进一步说:
生产级 Agent 的关键不是"模型有多聪明",而是系统能不能把模型的不确定性,用工程手段约束成可控、可测、可追踪、可恢复、可迭代的业务能力。
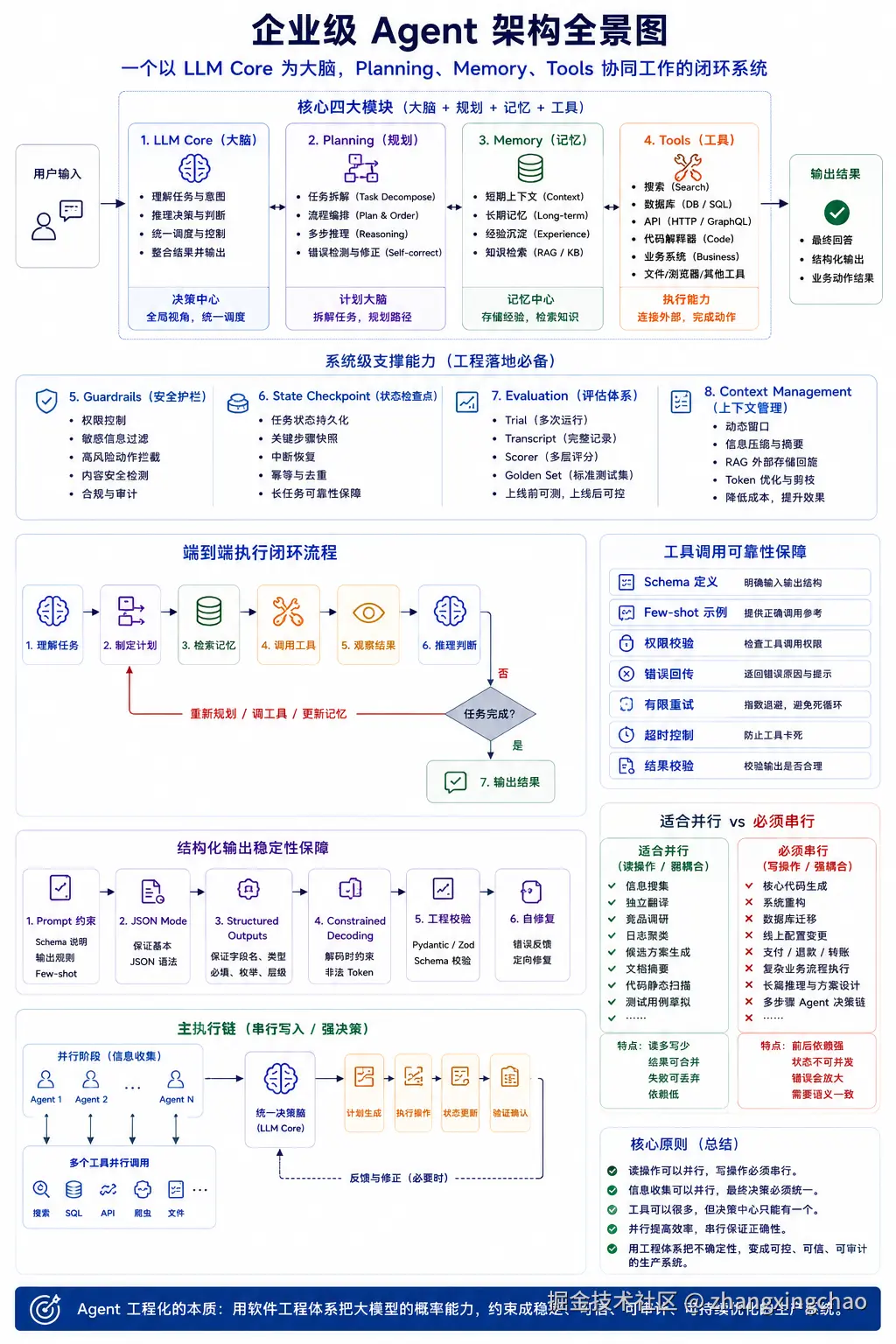
十六、总结
企业级 Agent,不是简单的大模型问答,而是一个以 LLM Core 为大脑,Planning、Memory、Tools 协同工作的闭环系统。
Core 负责理解任务、推理决策和统一调度;Planning 负责任务拆解、流程编排和错误修正;Memory 负责短期上下文、长期记忆和经验沉淀;Tools 负责调用搜索、数据库、API、代码解释器和业务系统。
在工程落地中,还需要 Guardrails、State Checkpoint、Evaluation 和 Context Management。Guardrails 解决权限、安全和高风险动作拦截;Checkpoint 解决长任务中断恢复;Evaluation 解决 Agent 上线前可测、上线后可控;Context Management 解决上下文膨胀、Token 成本和信息噪声。
对于工具调用,要用 Schema、Few-shot、权限校验、错误回传和有限重试保证可靠性;对于结构化输出,要用 Prompt、JSON Mode、Structured Outputs、Constrained Decoding 和 Pydantic / Zod 校验;对于评估,要用 Trial、Transcript、Scorer 和 Golden Set 构建闭环。
最后,在架构选型上,不能盲目追求多 Agent 并行。读操作和信息收集可以并行,但写操作和强耦合决策必须串行。核心原则是:工具可以很多,但决策中心只能有一个;信息可以并行收集,但最终决策必须统一。
所以,Agent 工程化的本质,是用软件工程体系把大模型的概率能力,约束成稳定、可信、可审计、可持续优化的生产系统。