索引为什么能够提高查询的效率?
首先可以将数据库的索引理解成是一本书的目录,在没有目录的时候,如果我们需要去查找数据,就需要把一本书从头到尾去找对应的资料,但是有了目录之后,就可以根据目录去进行跳转,不需要进行全表扫描的操作。
索引在MySQL当中的查询复杂度是O(logN)的,全表扫描的查询复杂度是O(N),相当于是遍历了一遍全表!因此我们说索引可以加快查询的效率
同时索引可以支持排序等操作!【加速排序、分组、连接】
项目中最常见的做法就是通过 create index 为经常用作查询条件的字段建索引
create index idx_name on students(name);
索引的分类
在这里一开始没有能够第一时间想到分类的依据 和 索引的类型有哪些?
从功能上分类的话,有主键索引、唯一索引、全文索引;
从数据结构上分类的话,有 B+ 树索引、哈希索引;
从存储内容上分类的话,有聚簇索引、非聚簇索引。
对于主键索引的了解
根据主键来进行建立索引
【补充】主键索引用于唯一标识表中的每条记录,其列值必须唯一且非空。创建主键时, MySQL 会自动生成对应的唯一索引。
每个表只能有一个主键索引,一般是表中的自增 id 字段。【一般就是我们前面提到的 聚簇索引】
唯一索引
唯一索引很容易理解就是全表当中可以唯一的确定一个元组的索引!唯一索引通常是用来进行幂等性的操作!比如为了避免重复性的消费!消息的幂等性等!
【可以避免消息队列的重复消费的问题,这里可以设计到一个场景题;】
全文索引和倒排索引的关联
全文索引针对的字段的数据类型主要是以 char,varchar,text为主的字段类型!
全文索引是一种用来加速文本内容搜索的索引类型 ,它解决的是"根据一个词快速找到包含这个词的所有文档 "这种问题。而倒排索引是实现全文索引最经典、最核心的数据结构,本质是一个词到文档列表的映射。
可以说,全文索引是"上层功能",倒排索引是"底层实现"。它们不是同一个层级的概念。像数据库的全文索引、Elasticsearch的全文搜索,内部都是基于倒排索引实现的。两者的区别主要在于:++全文索引还可能包含分词、相关性算分、高亮等完整引擎能力++,而倒排索引特指那张"单词→文档ID列表"的映射结构。
唯一索引和主键索引有什么区别?
需要意识到 唯一索引里面是可以插入 空值NULL的!
主键索引=唯一索引+非空。每个表只能有一个主键索引,但可以有多个唯一索引。【补!】
主键索引不允许插入 NULL 值,尝试插入 NULL 会报错;唯一索引允许插入多个 NULL 值。
unique key 和 unique index 有什么区别?
创建唯一键 时,MySQL 会自动生成一个同名的唯一索引 ;反之,创建唯一索引也会隐式添加唯一性约束。
可通过 UNIQUE KEY uk_name 定义或者 CONSTRAINT uk_name UNIQUE 定义唯一键。
CREATE TABLE users ( id INT PRIMARY KEY, email VARCHAR(100), -- 显式命名唯一键 CONSTRAINT uk_email UNIQUE (email) ); CREATE TABLE users3 ( id INT PRIMARY KEY, email VARCHAR(100), UNIQUE KEY uk_email (email) -- 唯一索引 );
普通索引和唯一索引有什么区别?
普通索引的作用在于可以加快检索的速度,不会对插入的数据进行唯一性的约束!比较常用于 高频写入的字段,范围查询的字段!
唯一索引的底层会对插入的数据进行唯一性的约束,会去进行唯一性的检查!适用于业务唯一性约束的字段、防止数据重复插入的字段。
什么是索引下推?
索引下推是指:MySQL 把 WHERE 条件尽可能"下推"到索引扫描阶段,在存储引擎层提前过滤掉不符合条件的记录。

当++查询条件包含索引列但未完全匹配++ 时,ICP 会在存储引擎层过滤非索引列条件,以减少回表次数。
传统的查询流程是,储引擎通过联合索引定位到符合最左前缀条件的主键 ID;回表读取完整数据行并返回给 Server 层;Server 层对所有返回的行进行 WHERE 条件过滤。
有了 ICP 后,存储引擎在索引层直接过滤可下推的条件,仅对符合索引条件的记录回表读取数据,再返回给 Server 层进行剩余条件过滤。
既然索引的好处这么多,我们应该怎么去合理的使用索引呢?
下面就是索引的使用了!
创建索引的注意事项!
切入方向不对,这里可以暂时不用结合着业务场景!
这里顶多就想到了 合适的字段!
重点关注一下 索引的数量+最左前缀法则!
先不要谈:可以根据业务的需要来创建唯一索引,建立对应的索引。
先谈:
-
选择合适的字段来建立索引
-
比如经常出现在where,group by,join当中的字段
-
尽量将索引加在区分度比较高的字段上,比如主键ID,学号等字段上,对于性别,年龄等这样区分度不是特别高的字段,可以考虑用联合索引来提高检索的效率
-
索引是不太建议加在需要频繁写入的字段上!因为索引的维护也是一个性能开销!
-
-
控制索引的数量【单表尽量不要超过5个】
建立索引的过程中!是要消耗内存空间的!因此索引的数量不难过多
同时需要定期的
SHOW INDEX FROM table_name来查看当前表当中的索引情况,比如已经有了一个联合索引(a,b),就要及时的去删除索引(a) -
第三,联合索引的时候要遵循最左前缀原则,即在查询条件中使用联合索引的第一个字段,才能充分利用索引。【如果不遵循最左前缀法则,选择的字段再合理,索引的数量再多,都不可能发挥最大的作用!】
既然提到了++合适的字段,那你说说什么样的字段适合加索引++?
这里只能答到主键,唯一键,经常做where,join等操作的字段
字段的区分度,多个字段经常一起出现在查询条件中!
一般来说,主键、唯一键、以及经常作为查询条件的字段最适合加索引。除此之外,字段的区分度要高,这样索引才能起到过滤作用;如果字段经常用于表连接、排序或分组,也建议加索引。同时如果多个字段经常一起出现在查询条件中,也可以建立联合索引来提升性能。
哪些情况下索引会失效?
既然谈到了索引怎么规范使用的问题,那么就需要了解哪些情况下索引会失效!
通配符开头的模糊查询,使用了函数!这些都没有第一时间想到!
如果当前的索引查询不符合最左前缀法则的话,那么当前的索引就会失效!
【补】
简版:比如索引列使用了函数、使用了通配符开头的模糊查询、联合索引不满足最左前缀原则,或者使用 or 的时候部分字段无索引等。
索引不适合什么样的场景?
提到了索引会失效的情况,那么就需要进一步去想 索引不适合什么样的场景?
第一,区分度低的列,可以和其他高区分度的列组成联合索引。
第二,频繁更新的列,索引会增加更新的成本。
第三,TEXT、BLOB 等大对象类型的字段,可以使用前缀索引、全文索引替代。
第四,当表的数据量很小的时候,不超过 1000 行,全表扫描可能比使用索引更快。【面试官可能会问:全表扫描就一定比走索引慢吗?不一定,要看表的规模大小,如果表当中的行数不超过1000行,那么全表扫描的效率是要高一点的!】
既然我们已经建立了索引,是不是需要去分析一下表中每个索引的情况,然后++进行一下索引的优化++
索引的优化
这个部分我的思路是,可以定期的使用explain这个关键字来分析执行计划,看看当前的查询有没有走索引,用到了哪些索引,有没有回表,有没有排序。
接着根据字段特性设计合适的索引,如选择区分度高的字段,使用联合索引和覆盖索引,避免索引失效的写法,最后通过实测来验证优化效果。
前面提到了索引的作用:可以加快查询的速度。也提到了索引主要有哪些?按照 功能,数据结构,存储内容来进行划分,不同的索引有不同的功能和作用,底层原理也不太相同!
接着是我们也分析了应该怎么去用索引?索引在什么情况下会失效?索引不要加在哪些字段上?索引的优化?
现在我们就去深入的探究一下,究竟是为什么索引可以加快查询的速度,进一步深入到底层去对对应的数据结构进行进一步的分析!
为什么 InnoDB 要使用 B+树作为索引?
一卷话总结:【学习一下,记一下这句话】
因为 B+ 树是一种++高度平衡的多路++ ++查找树++ ,能有效++降低磁盘的++ ++IO++ ++次数++,并且支持有序遍历和范围查询。
查询性能非常高,其结构也适合 MySQL 按照页为单位在磁盘上存储。
【追问,为什么不选择 哈希表,二叉树红黑树,B树等数据结构呢?】
像其他选项,比如说哈希表不支持范围查询,二叉树层级太深,B 树又不方便范围扫描,所以最终选择了 B+ 树。
为什么不用二叉树?
普通二叉树的每个节点最多有两个子节点。当数据按顺序递增插入时,二叉树会退化成链表,导致树的高度等于数据量。
为什么不用平衡二叉树呢?
平衡二叉树虽然解决了普通二叉树的退化问题,但每个节点最多只有两个子节点的问题依然存在。每个节点只有两个子节点,会导致这棵树的高度会比B+树要高,磁盘IO的次数也会更多!会增加性能的损耗!
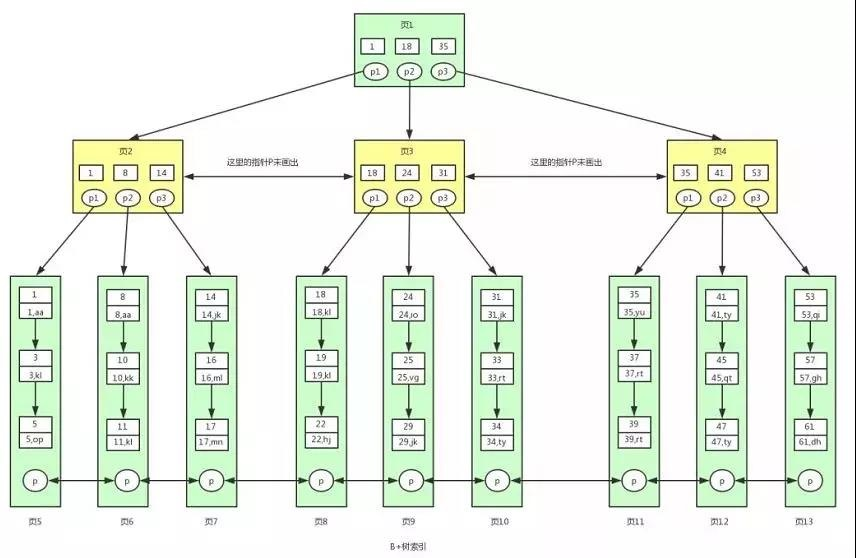
那继续谈谈你++对于++ ++B+树++ ++的了解++
B+树的叶子节点是双向链表,方便我们进行范围查询和反向遍历的操作!
在进行范围查询的时候,可以从范围的开始点或结束点开始,向前或向后遍历。
反向遍历,在需要对数据进行逆序处理时,双向链表非常有用。
你提到了范围查询的操作,那你能不能讲一讲++范围查询到底是怎么做的++?
一句话回答:
先通过++索引路径定位到第一个满足条件的++ ++叶子节点++,然后顺着叶子节点之间的链表向右/向左扫描,直到超过范围。
详细版:
B+ 树索引的范围查找++主要依赖++ ++叶子节点++ ++之间的++ ++双向链表++ ++来完成++。
第一步,从 B+ 树的根节点开始,通过索引键值逐层向下,找到第一个满足条件的叶子节点。
第二步,利用叶子节点之间的双向链表,从起始节点开始,依次向后遍历每个节点。当索引值超过查询范围,或者遍历到链表末尾时,终止查询。
后续我们就来对比一下不同的数据结构,深入了解一下他们的底层逻辑,从而进一步的分析,为什么需要选择B+树
为什么 MongoDB 的索引用 B树,而 MySQL 用 B+ 树?
需要了解到 MongoDB 本身的数据是以JSON格式来存储文档的!查询主要是以单键查询为主!对于范围查询和反向遍历用的就相对比较少一点!【这个功能用的不多】
因此我们可以考虑用B树,B树的节点上存储键值的同时也存储了数据,如果能查到对应的数据直接终止即可!从而减少了I/O次数
在MySQL当中,对于范围查询,排序,连接操作用的比较多,而且B+树的底层是双向链表,因此我们可以考虑用B+树来代替之前的B树!
MongoDB 通常以 JSON 格式存储文档,查询以单键查询(如 find({_id: 123}))为主。B 树的"节点既存键又存数据"的特性允许查询在非叶子节点提前终止,从而减少 I/O 次数。
MySQL 的查询通常涉及范围(WHERE id > 100)、排序(ORDER BY)、连接(JOIN)等操作。B+ 树的叶子节点是链表 结构 ,天然支持顺序遍历,无需回溯至根节点或中序遍历,效率远高于 B 树。
这里涉及到一个知识点就是++B+树++ ++和++ ++B树++ ++的对比++了【包重点的】
B+ 树相比 B 树有 3 个显著优势:
第一,B 树的每个节点既存储键值,又存储数据和指针,导致单节点存储的键值数量较少。【键值问题】
一个 16KB 的 InnoDB 页,如果数据较大,B 树的非叶子节点只能容纳几十个键值,而 B+ 树的非叶子节点可以容纳上千个键值。
第二,B 树的++范围查询++ 需要通过中序遍历逐层回溯;而 B+ 树的叶子节点通过双向链表顺序连接,范围查询只需定位起始点后顺序遍历链表即可,没有回溯开销。【范围查询】
第三,B 树的数据可能存储在任意节点,假如目标数据恰好位于根节点或上层节点,查询仅需 1-2 次 I/O;但如果数据位于底层节点,则需多次 I/O,导致查询时间波动较大。
而 B+ 树的所有数据都存储在叶子节点,查询路径的长度是固定的,时间稳定为 O(logN),对 MySQL 在高并发场景下的稳定性至关重要。【查询时间的稳定性问题】
那你既然提到了B+树的树高相对比较矮,那++为什么不用++ ++跳表++呢?跳表应该也差不多吧?
跳表本质上还是++链表++ ++结构++ ,只不过++把某些节点抽到上层做了索引++。
一条数据一个节点,如果需要存放 2000 万条数据,且每次查询都要能达到二分查找的效果,那么跳表的高度大约为 24 层(2 的 24 次方)。
在最坏的情况下,这 24 层数据分散在不同的数据页,查找一次数据就需要 24 次磁盘 I/O。
而 2000 万条数据在 B+树中只需要 3 层就可以了。
【这里需要重点强调 跳表的数据结构 + 查询次数的问题】
++B+树++ ++索引和 Hash 索引有什么区别?++
B+ 树索引支持范围查询、有序扫描,是 InnoDB 的默认索引结构。
Hash 索引只支持等值查找,速度快但功能弱,常见于 Memory 引擎。
如果再接着往下问,++一棵++ ++B+树++ ++最多可以存储多少的数据呢++ ?【考察对于数据结构本身的理解】
一句话回复:
一棵 B+ 树能存多少数据,取决于它的分支因子和高度。在 InnoDB 中,页的默认大小为 16KB,当主键为 bigint 时,3 层 B+ 树通常可以存储约 2000 万条数据。
那每个叶子节点能存放多少条数据?
如果单行数据大小为 1KB,那么每页可存储约 16 行(16KB/1KB)数据。【页的大小是固定的16KB】