Apache Iceberg 数据湖表格式中的核心术语
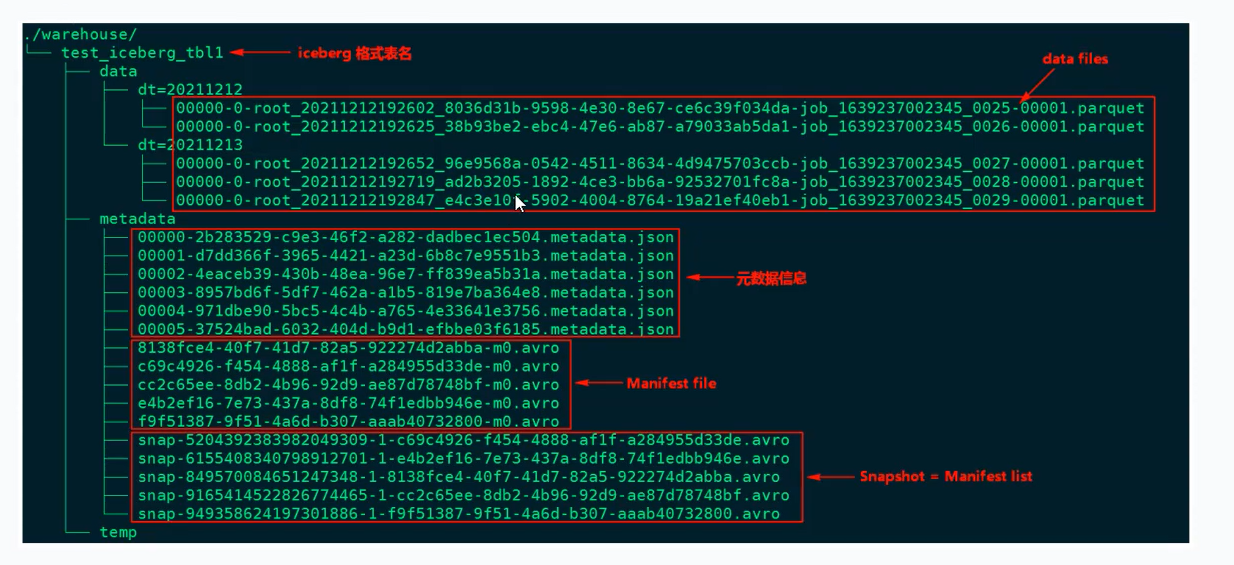
- Data Files (数据文件)
定义:这是 Iceberg 表中实际存储业务数据的文件。
位置:通常位于表的数据存储目录下的 data目录中。
格式:常见的格式是 Parquet(以 .parquet结尾),例如图片中的例子 00000-0-root_..._0025-00001.parquet。
特性:每次对表进行更新(如插入、删除、修改)操作,都会产生新的数据文件。
- Snapshot (表快照)
定义:快照代表了表在某个特定时刻的完整状态。
内容:每个快照包含一个清单列表(Manifest List),这个清单列出了当时表所包含的所有数据文件(Data Files)。
作用:就像是数据库在某个时间点的备份视图,查询引擎可以通过快照确定要读取哪些数据文件。
- Manifest List (清单列表)
定义:这是一个元数据文件,它列出了构建当前快照(Snapshot)所需的所有清单文件(Manifest File)。
存储内容:
每个 Manifest File 的路径。
每个 Manifest File 存储的数据文件的分区范围。
增加或删除了多少个数据文件等信息。
作用:在查询时,它可以帮助快速过滤掉不需要扫描的文件,从而加速查询。
- Manifest File (清单文件)
定义:这也是一个元数据文件,它列出了组成快照(Snapshot)的具体数据文件(Data Files)的详细信息。
存储内容(每行描述一个数据文件):
数据文件的状态(新增、删除等)。
文件路径。
分区信息。
列级别的统计信息(如每列的最大值、最小值、空值数等)------这是 Iceberg 高效剪枝(Pruning)的关键。
文件大小和行数。
格式:通常以 Avro 格式存储(以 .avro结尾),例如图片中的例子 8138fce4-40f7-41d7-82a5-922274d2abba-m0.avro。
作用:查询引擎在扫描表时,会利用这里的列统计信息跳过不相关的数据文件(例如,查询条件要求年龄>30,而某文件统计显示年龄最大值25,则该文件可直接跳过)。
总结关系链
这四个术语构成了一个自下而上的层级结构,用于管理表的版本和数据:
Data Files (数据文件) →被记录在 Manifest File (清单文件) 中 →多个 Manifest File 被记录在 Manifest List (清单列表) 中 →最终构成 Snapshot (表快照)。