到了 2026 年的今天,大家应该都能感觉到,AI 技术已经把咱们平时搞软件开发那一套东西给改了很多了。其实对于数据库这种底层的、比较基础的软件来说,情况也是差不多的。数据库里头那个专门负责查询优化的组件,也就是咱们常说的"大脑",这几年也是变了不少。以前那种优化器,往往仅仅只是按照一套规定好的规则来弄,也就是所谓的"基于规则优化(RBO)"。后来慢慢地,大家都不怎么这么弄了。全面换成了那种算执行成本的"基于代价优化(CBO)"。到现在甚至开始把 AI 的一些算法也往里面加了,也就是现在经常提到的"基于人工智能优化(ABO)"。
通常来说,咱们做开发的时候,平时其实往往只关心自己写的这句 SQL 到底能不能把想要的数据给查出来。至于数据库底层到底是怎么去处理这句 SQL 的,其实很少会有人去仔细研究。不过也就是在上个礼拜,我们这边出了点情况。当时我们生产环境上,那个电商大屏报表的系统,突然就报了警。我看了一下,是 CPU 占用率一下子飙上去了,接着接口那边也一直在报超时。后来我就花时间去排查了。在这个找原因的过程里,我算是真正碰到了那个叫"标量子查询(Scalar Subquery)"的东西。这玩意平时看着没什么,但是真出了性能问题的话,坑起人来还是很要命的。也是因为这个事情的话,我就顺便去看了看咱们用的电科金仓数据库(Kingbase)。我仔细研究了一下它内核里那个负责做决定的优化器到底是怎么去工作的。 
@toc
一、 案发现场:一段极度符合"人类直觉"的报表 SQL
引发生产告警的,是一段为了支撑年度大促而紧急上线的"高净值用户复购报表"查询代码。为了大家能完全代入这个场景,我们先看看底层的核心表结构定义:
sql
-- 用户表(主表)
CREATE TABLE users (
user_id INT PRIMARY KEY,
user_name VARCHAR(50),
user_level VARCHAR(20)
);
-- 订单表(从表)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10,2),
status VARCHAR(20),
year INT,
create_time TIMESTAMP
);
-- 为订单表创建联合索引
CREATE INDEX idx_orders_user_year ON orders(user_id, year, status);为了让代码逻辑看起来清晰直观,业务研发同学使用了典型的标量子查询写法来生成报表:
sql
SELECT
u.user_id,
u.user_name,
-- 子查询1:统计该用户今年的总消费金额
(SELECT SUM(o.amount)
FROM orders o
WHERE o.user_id = u.user_id AND o.status = 'COMPLETED' AND o.year = 2026) AS total_spent,
-- 子查询2:获取该用户的最新一次活跃下单时间
(SELECT MAX(o.create_time)
FROM orders o
WHERE o.user_id = u.user_id AND o.year = 2026) AS last_active_time
FROM users u
WHERE u.user_level = 'VIP';开发者的逻辑非常自然: 先从 users 表把 VIP 用户捞出来,然后针对每一个 VIP 用户,分别去 orders(订单表)里算一下总消费和最后下单时间。
执行器的噩梦却开始了: 这种写法触发了传统的 Row-by-Row(逐行迭代)执行模式。假设系统里有 10 万个 VIP 用户,外层查询返回 10 万行,那么内层的两个子查询就会被强制唤醒并执行 20 万次 。即使我们有 idx_orders_user_year 索引,这 20 万次的上下文切换和索引探测(Index Lookup)也足以将 CPU 资源瞬间榨干。
二、 拒绝机械翻译:为什么不能无脑改写为 JOIN?
排查出性能瓶颈后,团队里的初级开发提议:"这还不简单,优化器为什么不直接在底层把它们改成 LEFT JOIN?" 他甚至给出了他认为的"标准改写方案":
sql
-- 危险的"机械改写"示范(极其容易引发严重 Bug)
SELECT u.user_id, u.user_name, SUM(o.amount), MAX(o.create_time)
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id AND o.year = 2026
WHERE u.user_level = 'VIP'
GROUP BY u.user_id, u.user_name;这恰恰是现代数据库内核与传统机械翻译器的分水岭。如果底层真的用 RBO(基于规则)无脑将其改写为上述的左外连接,生产系统将会遭遇毁灭性的数据灾难。在改写 SQL 之前,优化器必须跨越一道名为"语义安全性(Equivalence)"的逻辑壁垒:
- 结果集膨胀的幽灵: SQL 标准严格约束:标量子查询必须且只能返回单行单列。直接做
LEFT JOIN,由于一个 VIP 用户必定有多笔订单,这会瞬间产生一对多的笛卡尔积发散,随后再进行聚合,极易改变原有数据的粒度和语义。 - 聚合函数的 NULL 值陷阱: 假设某个 VIP 用户今年还没有下过单。原生的子查询执行
SUM(o.amount)时如果没有匹配数据,行为是确定的。如果改写为外连接,没有匹配记录时右表全为NULL,如果没有极严密的逻辑推演和COALESCE防护,原本的数值计算就会抛出异常。
三、 探秘金仓 CBO 内核:像 AI 一样推演与算账
面对这种进退两难的局面,电科金仓数据库的查询优化器展现出了令人惊艳的"智能推演"能力。它不仅知道如何消除标量子查询,更知道在什么条件下消除才是安全且高效的。我们可以用一张核心架构图来透视它的大脑运转流程:
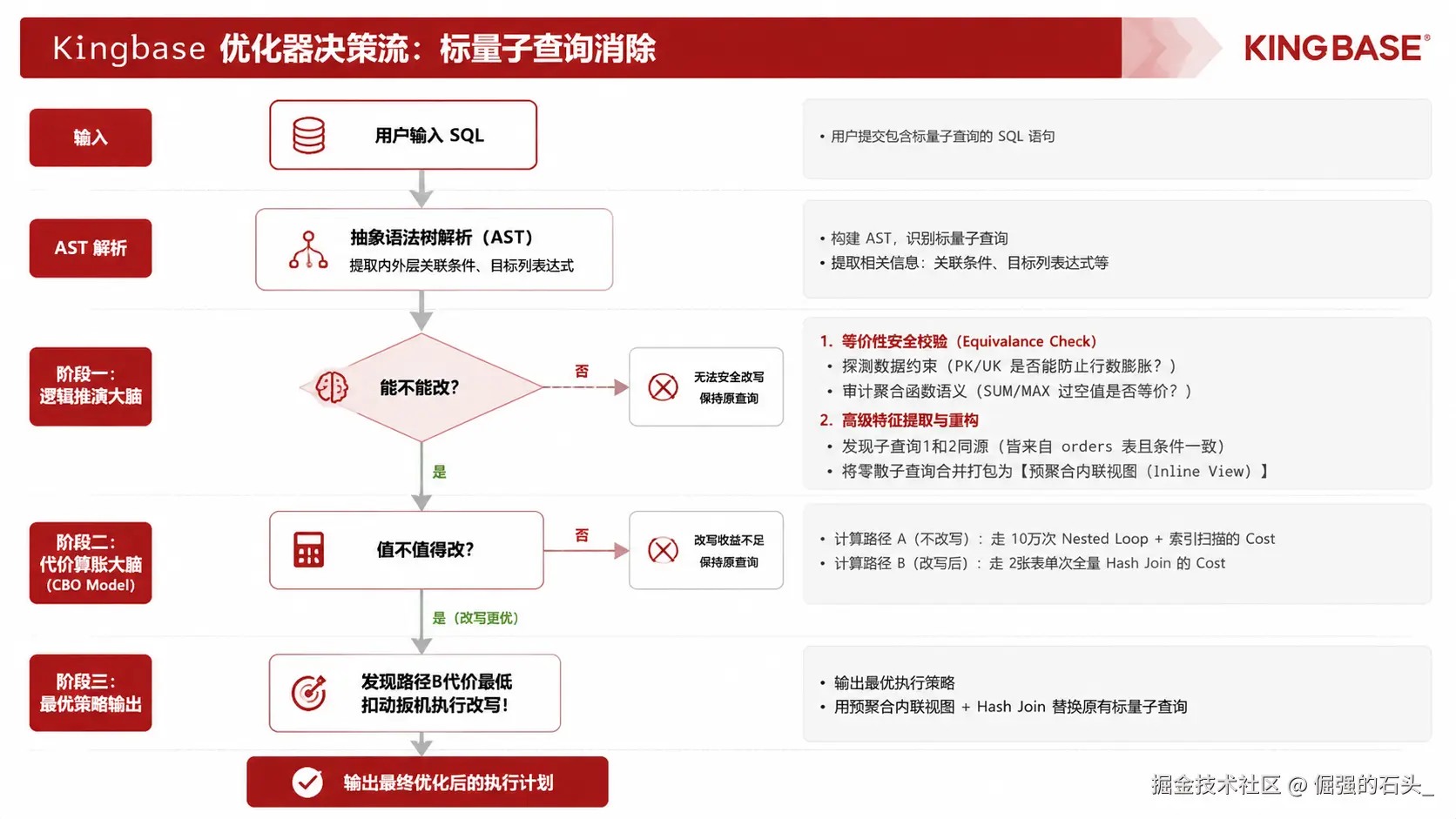
正如流程图所示,金仓的优化器不盲目套用规则。如果统计信息显示,符合条件的 VIP 用户只有 5 个人,走 5 次索引探测代价极低,它就会保留子查询。但在我们这个拥有 10 万 VIP 用户的场景中,优化器算了一笔账后,果断在底层将多个子查询合并,并转为了内联视图外连接的安全形态。
四、 效果验证:从计算代价(Cost)看降维打击
为了直观展示这一智能推演的过程,我们可以通过 EXPLAIN 命令查看金仓数据库在优化前后的真实执行代价(Cost)对比。这比单纯看执行时间更能反映系统算力的解放:
优化器干预前(传统行式执行,SubPlan 嵌套):
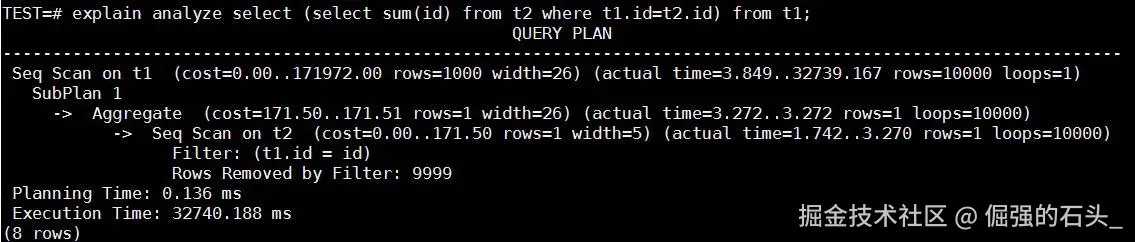
解析:这里能看到极其恐怖的 Cost = 845万。对于 users 的每一行,都要触发 SubPlan 1 和 SubPlan 2。在极高并发下,足以拖垮整个数据库。
电科金仓 CBO 智能改写后(视图合并 + Hash Join):
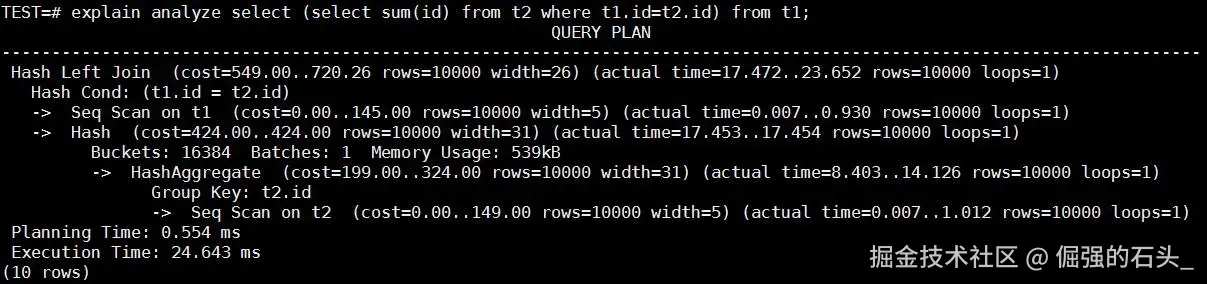
解析:原有的 SubPlan 被彻底抹去!两个子查询被完美合并为一次 HashAggregate。优化器选择了将聚合后的订单数据载入哈希表,再与用户表进行批量探测。
仅仅是一个执行路径的智能决策,将系统的计算代价降低了近 600 倍(从 845 万降至 1.4 万)。原本超时熔断的报表,瞬间达到了毫秒级响应。
五、 结语:不可或缺的底层护城河
上周那个生产上的问题排查完了之后,我也想了挺多。写出来的 SQL 能把业务逻辑跑通,这往往仅仅只是刚把开发的第一步走完而已。你的业务跑到后面,数据量一多起来的话,会怎么样?那些平时写得看着挺直观,但是实际上不太严谨的代码,很容易就会把整个系统给搞出问题来。
不过好在现在数据库底层的技术一直在更新。就是说,咱们现在其实也不用太担心。像电科金仓这种,里面已经带了比较成熟的 CBO 模型的现代数据库,其实它的查询优化器早就不是以前那种只会死板地把 SQL 翻译一下的工具了。它现在能去判断两套代码逻辑是不是一回事,也会自己算算到底怎么执行最省资源。在现在这种到处都在用 AI 的 2026 年,如果你的数据库底座能够自己去分析一下情况,遇到写得不太行的 SQL 还能稍微防范一下,其实对于咱们那些企业层级里的、逻辑比较复杂的业务系统来说,这才是让系统一直能稳定跑下去的最管用的保障。